Recognition: 3 theorem links
· Lean TheoremEntropic Strict Minimum Message Length and Its Connections to PAC-Bayes and NML
Pith reviewed 2026-05-08 18:36 UTC · model grok-4.3
The pith
Entropic SMML generalizes strict minimum message length into a tunable family that interpolates between Bayesian and minimax coding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Entropic SMML replaces expected two-part codelength under the prior predictive distribution with an exponential certainty equivalent, thereby defining a one-parameter family of coding rules that interpolates between Bayesian average-case coding and worst-case minimax coding. Ordinary SMML is recovered in the risk-neutral limit, while the extreme risk-sensitive limit yields a minimax codelength criterion that coincides with the normalized maximum likelihood minimax-regret principle when centered by the oracle maximum likelihood codelength. Entropic SMML admits a variational characterization as a Kullback-Leibler-regularized worst-case expected codelength and, for regular exponential families,
What carries the argument
The exponential certainty equivalent applied to two-part codelength, which defines the risk-sensitive objective and enables the variational PAC-Bayes form.
Load-bearing premise
The joint asymptotic theory and the affine partition property hold only under regular parametric models and regular exponential families.
What would settle it
Compute entropic SMML partitions and code lengths for increasing sample sizes n in a regular Gaussian model while varying the risk parameter τ, and check whether the shift from Bayesian to minimax behavior occurs at the logarithmic rate predicted by the joint asymptotics.
Figures
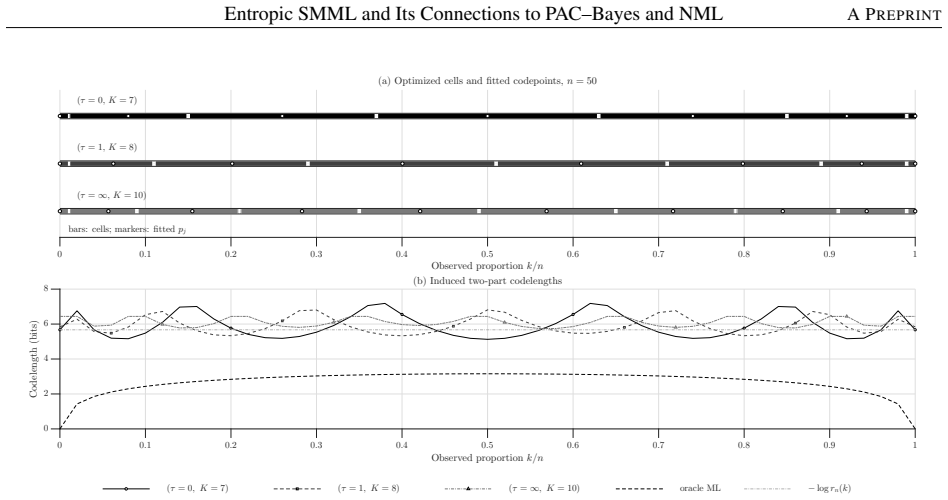
read the original abstract
We introduce entropic strict minimum message length (SMML), a risk-sensitive generalization of strict minimum message length coding. The proposed criterion replaces expected two-part codelength under the prior predictive distribution with an exponential certainty equivalent, thereby defining a one-parameter family of coding rules that interpolates between Bayesian average-case coding and worst-case minimax coding. We show that ordinary SMML is recovered in the risk-neutral limit, while the extreme risk-sensitive limit yields a minimax codelength criterion; when centered by the oracle maximum likelihood codelength, this criterion coincides with the normalized maximum likelihood (NML) minimax-regret principle. We further prove that entropic SMML admits a variational characterization as a Kullback--Leibler-regularized worst-case expected codelength, giving it a PAC--Bayes-type interpretation. We establish a joint asymptotic theory linking the sample size $n$ and the risk parameter $\tau$, showing that in regular parametric models the transition between Bayesian, robust, and minimax coding regimes occurs on a logarithmic scale. For regular exponential families, the fixed-codebook partition remains affine in sufficient-statistic space, while the codepoints satisfy a tilted moment-matching condition and admit an interpretation as tilted Bregman centroids. These results position entropic SMML as an information-theoretic bridge between MML, PAC--Bayes, and MDL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces entropic strict minimum message length (SMML), a risk-sensitive generalization of strict MML coding. It replaces the expected two-part codelength with an exponential certainty equivalent, yielding a one-parameter family that interpolates between Bayesian average-case coding and worst-case minimax coding. The manuscript claims that ordinary SMML is recovered in the risk-neutral limit, that the extreme risk-sensitive limit (centered by the oracle MLE codelength) coincides with the normalized maximum likelihood (NML) minimax-regret principle, and that entropic SMML admits a variational characterization as a KL-regularized worst-case expected codelength with a PAC-Bayes interpretation. It further establishes a joint asymptotic theory in sample size n and risk parameter τ, showing logarithmic-scale transitions between regimes in regular parametric models, and proves that for regular exponential families the fixed-codebook partition is affine in sufficient-statistic space with codepoints satisfying a tilted moment-matching condition interpretable as tilted Bregman centroids.
Significance. If the derivations hold, the work supplies a clean information-theoretic bridge between MML, PAC-Bayes, and MDL by deriving the characterizations explicitly from the new definition rather than by parameter fitting. The logarithmic-scale transition result and the tilted Bregman-centroid interpretation for exponential families are noteworthy strengths that could inform robust coding and asymptotic analysis in learning theory.
major comments (1)
- [Abstract and joint asymptotic theory] Abstract and joint asymptotic theory: The claim that the transition between Bayesian, robust, and minimax coding regimes occurs on a logarithmic scale (and that the affine partition property holds) is stated to require regular parametric models and regular exponential families. No rates of convergence, no counter-examples, and no analysis of degradation when the Fisher information degenerates, the model is misspecified, or the exponential-family assumption fails are supplied. Because the variational characterization and the n–τ joint asymptotics are derived under these conditions, the omission is load-bearing for the asserted connections to PAC-Bayes and NML.
minor comments (2)
- [Abstract] The risk parameter τ is introduced in the abstract without an explicit statement of its range or scaling; a brief clarifying sentence would improve readability for readers unfamiliar with certainty-equivalent formulations.
- [Notation] Notation for the certainty equivalent, the partition, and the tilted centroids is used throughout; a short dedicated notation table or definition list would reduce the risk of confusion between the risk-neutral and risk-sensitive limits.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment, as well as for identifying an important point regarding the scope of our asymptotic results. We respond to the major comment below.
read point-by-point responses
-
Referee: The claim that the transition between Bayesian, robust, and minimax coding regimes occurs on a logarithmic scale (and that the affine partition property holds) is stated to require regular parametric models and regular exponential families. No rates of convergence, no counter-examples, and no analysis of degradation when the Fisher information degenerates, the model is misspecified, or the exponential-family assumption fails are supplied. Because the variational characterization and the n–τ joint asymptotics are derived under these conditions, the omission is load-bearing for the asserted connections to PAC-Bayes and NML.
Authors: We agree that the joint asymptotic theory, including the logarithmic-scale transitions and the affine partition property for exponential families, is derived under the regularity conditions stated in the manuscript (regular parametric models and regular exponential families). The abstract and relevant sections already qualify the claims with these conditions, and the variational characterization is obtained exactly from the entropic SMML definition without relying on asymptotics. We acknowledge that the paper does not supply explicit rates of convergence, counterexamples for degenerate Fisher information, or analysis under misspecification or non-exponential-family models. Such extensions would require substantial further technical development. In the revised version we will (i) make the regularity assumptions more prominent in the abstract and introduction, (ii) add a short discussion paragraph noting the scope of the current results and the potential for degradation outside the regular setting, and (iii) clarify that the PAC-Bayes and NML connections rest on the exact variational and limiting characterizations rather than solely on the asymptotics. This addresses the load-bearing concern by tightening the statement of scope while preserving the core derivations. revision: partial
Circularity Check
No circularity: derivations follow from new definition and explicit centering
full rationale
The paper defines entropic SMML via an exponential certainty equivalent applied to the two-part codelength and then derives the variational KL-regularized form, the PAC-Bayes interpretation, the n–τ joint asymptotics, and the affine partition property for regular exponential families directly from that definition and standard regularity conditions. The NML coincidence is obtained by subtracting the oracle MLE codelength (explicit centering), not by forcing equality. No step reduces a claimed prediction or uniqueness result to a fitted parameter, a self-citation chain, or an ansatz smuggled from prior work by the same authors. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Regular parametric models
- domain assumption Regular exponential families
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J = ½(x+x⁻¹)−1, Aczél-class uniqueness)washburn_uniqueness_aczel unclearWe introduce entropic strict minimum message length (SMML)... replaces expected two-part codelength under the prior predictive distribution with an exponential certainty equivalent, thereby defining a one-parameter family of coding rules that interpolates between Bayesian average-case coding and worst-case minimax coding.
-
Foundation/BranchSelection.lean (RCL combiner, bilinear vs additive branch)branch_selection unclearFor regular exponential families, the fixed-codebook partition remains affine in sufficient-statistic space, while the codepoints satisfy a tilted moment-matching condition and admit an interpretation as tilted Bregman centroids.
-
Foundation/ArithmeticFromLogic.lean (orbit/embedding via log of generator)embed_strictMono_of_one_lt unclearthe transition between Bayesian, robust, and minimax coding regimes occurs on a logarithmic scale
Reference graph
Works this paper leans on
-
[1]
Wallace and David M
Chris S. Wallace and David M. Boulton. An information measure for classification.Computer Journal, 11(2):185– 194, August 1968
1968
-
[2]
Wallace and David M
Chris S. Wallace and David M. Boulton. An invariant Bayes method for point estimation.Classification Society Bulletin, 3(3):11–34, 1975
1975
-
[3]
Wallace and Peter R
Chris S. Wallace and Peter R. Freeman. Estimation and inference by compact coding.Journal of the Royal Statistical Society (Series B), 49(3):240–252, 1987
1987
-
[4]
Wallace.Statistical and inductive inference by minimum message length
Chris S. Wallace.Statistical and inductive inference by minimum message length. Information Science and Statistics. Springer, first edition, 2005
2005
-
[5]
Modeling by shortest data description.Automatica, 14(5):465–471, September 1978
Jorma Rissanen. Modeling by shortest data description.Automatica, 14(5):465–471, September 1978
1978
-
[6]
Universal coding, information, prediction, and estimation.IEEE Transactions on Information Theory, 30(4):629–636, July 1984
Jorma Rissanen. Universal coding, information, prediction, and estimation.IEEE Transactions on Information Theory, 30(4):629–636, July 1984
1984
-
[7]
Fisher information and stochastic complexity.IEEE Transactions on Information Theory, 42(1):40–47, January 1996
Jorma Rissanen. Fisher information and stochastic complexity.IEEE Transactions on Information Theory, 42(1):40–47, January 1996
1996
-
[8]
Strong optimality of the normalized ML models as universal codes and information in data
Jorma Rissanen. Strong optimality of the normalized ML models as universal codes and information in data. IEEE Transactions on Information Theory, 47(5):1712–1717, July 2001
2001
-
[9]
Information Science and Statistics
Jorma Rissanen.Information and Complexity in Statistical Modeling. Information Science and Statistics. Springer, first edition, 2007
2007
-
[10]
Grünwald.The Minimum Description Length Principle
Peter D. Grünwald.The Minimum Description Length Principle. Adaptive Communication and Machine Learning. The MIT Press, 2007
2007
-
[11]
Minimum description length revisited.International Journal of Mathematics for Industry, 11(01), December 2019
Peter Grünwald and Teemu Roos. Minimum description length revisited.International Journal of Mathematics for Industry, 11(01), December 2019
2019
-
[12]
M. D. Donsker and S. R. S. Varadhan. Asymptotic evaluation of certain markov process expectations for large time, i.Communications on Pure and Applied Mathematics, 28(1):1–47, January 1975
1975
-
[13]
Entropic risk measures: Coherence vs
Hans Föllmer and Thomas Knispel. Entropic risk measures: Coherence vs. convexity, model ambiguity and robust large deviations.Stochastics and Dynamics, 11(02n03):333–351, 2011
2011
-
[14]
Kullback and R
S. Kullback and R. A. Leibler. On information and sufficiency.The Annals of Mathematical Statistics, 22(1):79–86, March 1951
1951
-
[15]
Pac-Bayesian supervised classification: The thermodynamics of statistical learning.IMS Lecture Notes Monograph Series, 56:1–163, 2007
Olivier Catoni. Pac-Bayesian supervised classification: The thermodynamics of statistical learning.IMS Lecture Notes Monograph Series, 56:1–163, 2007
2007
-
[16]
Enes Makalic and Daniel F. Schmidt. Information geometry and asymptotic theory for SMML estimators. arXiv:2604.05241, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Dhillon, and Joydeep Ghosh
Arindam Banerjee, Srujana Merugu, Inderjit S. Dhillon, and Joydeep Ghosh. Clustering with bregman divergences. Journal of Machine Learning Research, 6(58):1705–1749, 2005
2005
-
[18]
Berger.Statistical Decision Theory and Bayesian Analysis
James O. Berger.Statistical Decision Theory and Bayesian Analysis. Springer New York, 1985
1985
-
[19]
Y . M. Shtarkov. Universal sequential coding of single messages.Probl. Inform. Transm., 23(3):3–17, 1987
1987
-
[20]
Normalized maximum likelihood with luckiness for multivariate normal distributions, 2017
Kohei Miyaguchi. Normalized maximum likelihood with luckiness for multivariate normal distributions, 2017
2017
-
[21]
American Mathematical Society, 2000
Shun’ichi Amari and Hiroshi Nagaoka.Methods of Information Geometry, volume 191 ofTranslations of mathematical monographs. American Mathematical Society, 2000
2000
- [22]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.