Recognition: unknown
LUMINA: A Grid Foundation Model for Benchmarking AC Optimal Power Flow Surrogate Learning
Pith reviewed 2026-05-09 16:41 UTC · model grok-4.3
The pith
LUMINA-Bench supplies a standardized suite for testing whether AC optimal power flow surrogate models generalize to network topologies absent from training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce LUMINA-Bench, a comprehensive benchmark suite for ACOPF surrogate learning covering multi-topology pretraining, transfer, and adaptation. The benchmark evaluates homogeneous and heterogeneous architectures under single- and multi-topology learning settings using unified metrics that capture both predictive accuracy and physics-informed constraint violations. We additionally compare constraint-aware training objectives, including MSE, augmented Lagrangian, and violation-based Lagrangian losses, to characterize accuracy-robustness trade-offs across settings.
What carries the argument
LUMINA-Bench, the open-sourced benchmark that standardizes data handling, model training, and evaluation for AC optimal power flow surrogates across multiple network topologies with metrics for both accuracy and constraint violations.
If this is right
- Multi-topology pretraining followed by adaptation produces surrogates that maintain higher feasibility on new networks than single-topology training.
- Violation-based Lagrangian losses reduce the rate of constraint violations at a modest cost in prediction accuracy compared with plain MSE.
- Unified metrics that jointly track error and feasibility allow direct comparison of homogeneous and heterogeneous neural architectures across learning regimes.
- Open release of the data pipelines and evaluation code removes a major barrier to reproducible progress on feasible OPF surrogates.
Where Pith is reading between the lines
- The benchmark could serve as a testbed for developing grid foundation models that treat topology variation as a core input rather than a distribution shift.
- Results from the suite might guide selection of loss functions for surrogates deployed in day-ahead market clearing or contingency analysis where constraint satisfaction is non-negotiable.
- Extending the framework to include time-varying loads or stochastic renewable injections would expose whether current architectures also generalize along the time dimension.
Load-bearing premise
That the selected accuracy metrics and constraint-aware losses will reliably flag models capable of producing feasible solutions on real grids whose topologies were never seen during training.
What would settle it
A surrogate that ranks highest on all LUMINA-Bench scores yet yields power-flow solutions that violate voltage or line limits when applied to an actual grid topology drawn from operating records outside the benchmark's dataset collection.
Figures




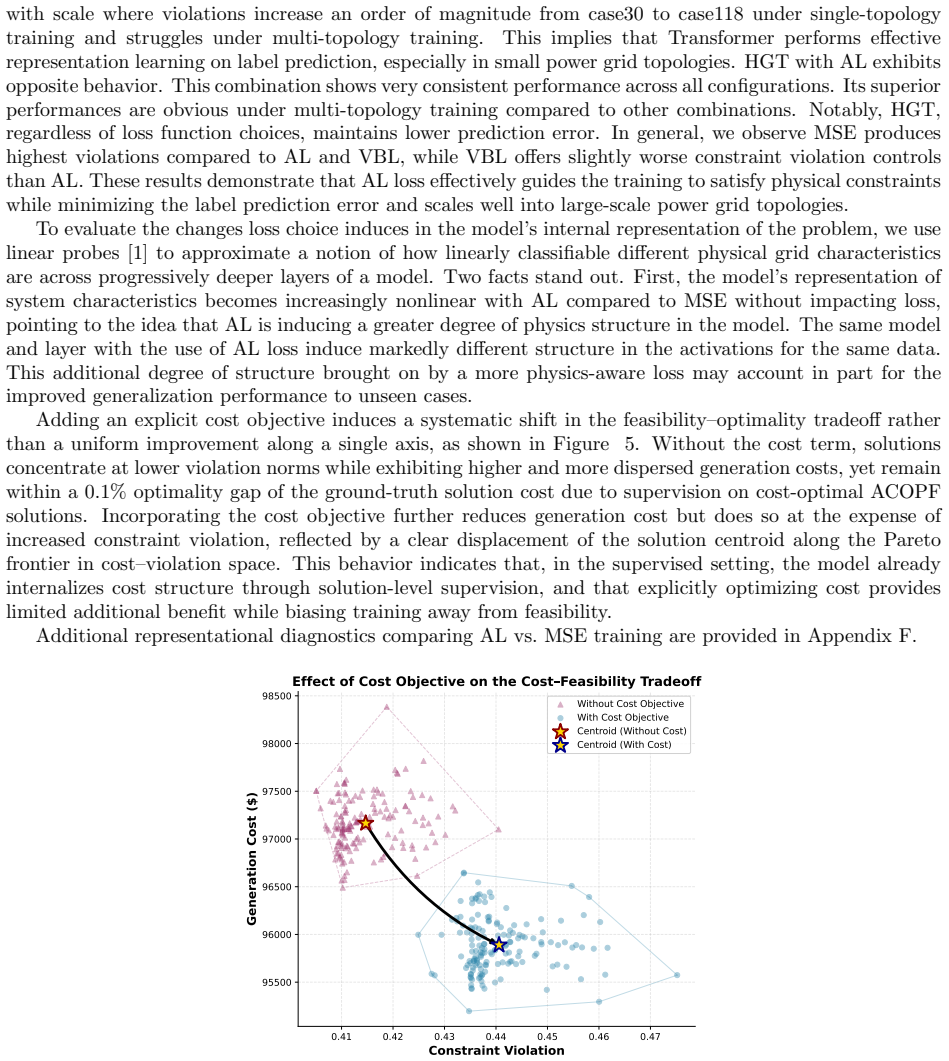

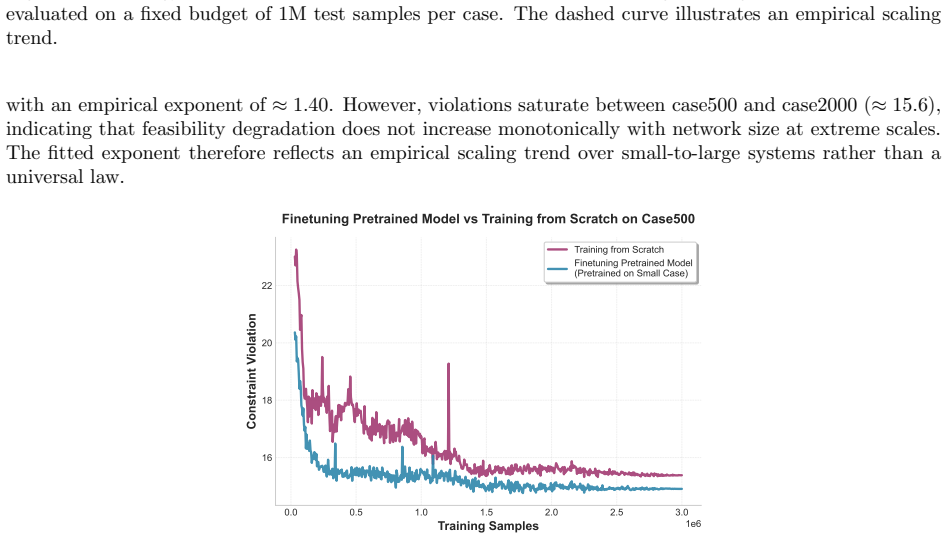
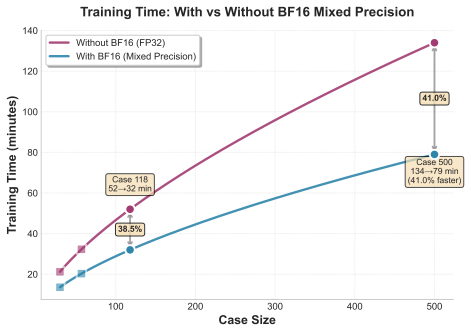
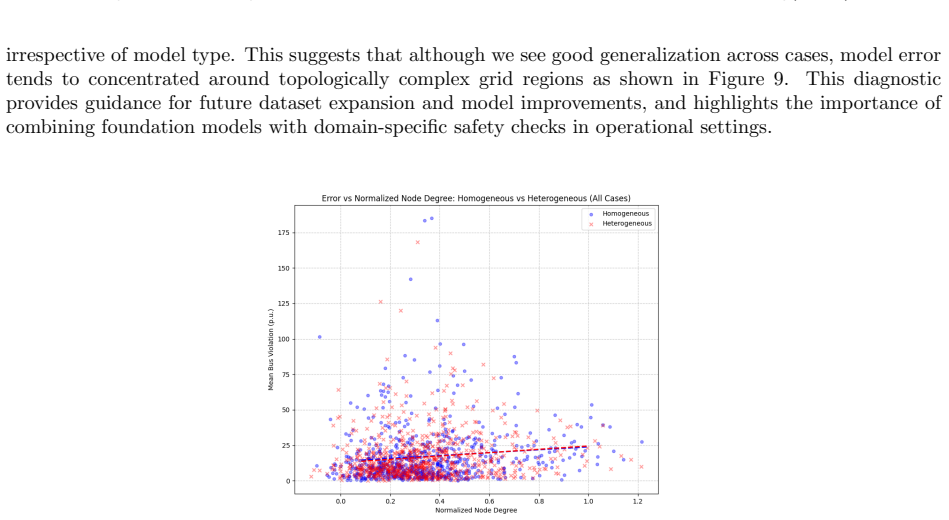




read the original abstract
AC optimal power flow (ACOPF) is foundational yet computationally expensive in power grid operations, driving learning-based surrogates for large-scale grid analysis. These surrogates, however, often fail to generalize across network topologies, a critical gap for deployment on grids not seen during training and for routine operational what-if studies. We introduce LUMINA-Bench, a comprehensive benchmark suite for ACOPF surrogate learning covering multi-topology pretraining, transfer, and adaptation. The benchmark evaluates homogeneous and heterogeneous architectures under single- and multi-topology learning settings using unified metrics that capture both predictive accuracy and physics-informed constraint violations. We additionally compare constraint-aware training objectives, including MSE, augmented Lagrangian, and violation-based Lagrangian losses, to characterize accuracy-robustness trade-offs across settings. Data processing, training, and evaluation frameworks are open-sourced as the LUMINA suite to support reproducibility and accelerate future research on feasibility-aware OPF surrogates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LUMINA-Bench, a benchmark suite for AC optimal power flow (ACOPF) surrogate learning. It covers multi-topology pretraining, transfer, and adaptation scenarios; evaluates homogeneous and heterogeneous neural architectures under single- and multi-topology settings; employs unified metrics capturing both predictive accuracy and physics-informed constraint violations; compares constraint-aware training objectives (MSE, augmented Lagrangian, and violation-based Lagrangian losses) to characterize accuracy-robustness trade-offs; and open-sources the associated data processing, training, and evaluation frameworks as the LUMINA suite.
Significance. If the benchmark construction and reported characterizations hold, the work is significant for the field of learning-based power system surrogates. Standardized multi-topology evaluation with explicit constraint-violation metrics addresses a recognized deployment barrier (generalization to unseen grids), while the open-sourced suite and loss-function comparisons can accelerate reproducible research on feasibility-aware models.
minor comments (3)
- Abstract and title: the phrasing 'LUMINA: A Grid Foundation Model for Benchmarking' risks conflating a benchmark suite with a foundation model; explicit clarification of scope (benchmark definition and characterization rather than a new pretrained model) would improve precision.
- Evaluation sections: while the abstract states that data splits, topology selection, and statistical significance are described, the manuscript would benefit from a dedicated subsection summarizing the exact criteria used for topology diversity (size, connectivity, load patterns) and the number of random seeds or statistical tests supporting the accuracy-robustness trade-off claims.
- Metrics and losses: the unified metrics are described at a high level; adding a short table or pseudocode box that shows how constraint violations are aggregated across buses and time periods would aid reproducibility for readers implementing the benchmark.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of LUMINA-Bench, its significance for learning-based power system surrogates, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; benchmark definition is self-contained
full rationale
The manuscript introduces LUMINA-Bench as a benchmark suite for ACOPF surrogate learning, including multi-topology pretraining, transfer, adaptation, unified metrics (accuracy and constraint violations), and comparisons of loss functions (MSE, augmented Lagrangian, violation-based). No derivations, first-principles predictions, fitted parameters renamed as outputs, or load-bearing self-citations appear. The central claim is the construction and open-sourcing of the benchmark itself, which does not reduce to its own inputs by definition or equation. This is a standard benchmark paper with independent content in data processing, evaluation frameworks, and empirical characterization of trade-offs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644, 2016
work page Pith review arXiv 2016
-
[2]
Strong np-hardness of ac power flows feasibility.Operations Research Letters, 47(6):494–501, 2019
Daniel Bienstock and Abhinav Verma. Strong np-hardness of ac power flows feasibility.Operations Research Letters, 47(6):494–501, 2019
2019
-
[3]
Grid structural characteristics as validation criteria for synthetic networks.IEEE Transactions on power systems, 32(4):3258–3265, 2016
Adam B Birchfield, Ti Xu, Kathleen M Gegner, Komal S Shetye, and Thomas J Overbye. Grid structural characteristics as validation criteria for synthetic networks.IEEE Transactions on power systems, 32(4):3258–3265, 2016
2016
-
[4]
Aug- mented lagrangian guided learning for the optimal power flow problem.IFAC-PapersOnLine, 58(13):50– 55, 2024
Sarra Bouchkati, Philipp Lutat, Luis B¨ ottcher, Florian Klein-Helmkamp, and Andreas Ulbig. Aug- mented lagrangian guided learning for the optimal power flow problem.IFAC-PapersOnLine, 58(13):50– 55, 2024
2024
-
[5]
Hammerla
Dan Busbridge, Dane Sherburn, Pietro Cavallo, and Nils Y. Hammerla. Relational graph attention networks, 2019
2019
-
[6]
Carpentier
J. Carpentier. Contribution ` a l’´ etude du dispatching ´ economique.Bulletin de la Soci´ et´ e Fran¸ caise des ´Electriciens, 3(8):431–447, 1962
1962
-
[7]
Physics-informed gradient estimation for accelerating deep learning-based ac-opf.IEEE Transactions on Industrial Informatics, 2025
Kejun Chen, Shourya Bose, and Yu Zhang. Physics-informed gradient estimation for accelerating deep learning-based ac-opf.IEEE Transactions on Industrial Informatics, 2025
2025
-
[8]
Initial estimate of AC optimal power flow with graph neural networks.Electric Power Systems Research, 234:110782, 2024
Amir Deihim, Despina Apostolopoulou, and Eduardo Alonso. Initial estimate of AC optimal power flow with graph neural networks.Electric Power Systems Research, 234:110782, 2024. 14
2024
-
[9]
Predicting AC optimal power flows: Combining deep learning and lagrangian dual methods
Ferdinando Fioretto, Terrence WK Mak, and Pascal Van Hentenryck. Predicting AC optimal power flows: Combining deep learning and lagrangian dual methods. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 630–637, 2020
2020
-
[10]
Optimal power flow: A bibliographic survey i: Formulations and deterministic methods.Energy systems, 3(3):221–258, 2012
Stephen Frank, Ingrida Steponavice, and Steffen Rebennack. Optimal power flow: A bibliographic survey i: Formulations and deterministic methods.Energy systems, 3(3):221–258, 2012
2012
-
[11]
Optimal power flow: A bibliographic survey ii: Non-deterministic and hybrid methods.Energy systems, 3(3):259–289, 2012
Stephen Frank, Ingrida Steponavice, and Steffen Rebennack. Optimal power flow: A bibliographic survey ii: Non-deterministic and hybrid methods.Energy systems, 3(3):259–289, 2012
2012
-
[12]
A physics-guided graph convolution neural network for optimal power flow.IEEE Transactions on Power Systems, 39(1):380–390, 2023
Maosheng Gao, Juan Yu, Zhifang Yang, and Junbo Zhao. A physics-guided graph convolution neural network for optimal power flow.IEEE Transactions on Power Systems, 39(1):380–390, 2023
2023
-
[13]
Foun- dation models for the electric power grid.Joule, 8(12):3245–3258, 2024
Hendrik F Hamann, Blazhe Gjorgiev, Thomas Brunschwiler, Leonardo SA Martins, Alban Puech, Anna Varbella, Jonas Weiss, Juan Bernabe-Moreno, Alexandre Blondin Mass´ e, Seong Lok Choi, et al. Foun- dation models for the electric power grid.Joule, 8(12):3245–3258, 2024
2024
-
[14]
Alternative learning architecture for solving ac-opf via supervised relaxation and cross encoder
Doan Thanh Hien, Keunju Song, Kibaek Kim, and Hongseok Kim. Alternative learning architecture for solving ac-opf via supervised relaxation and cross encoder. InNeurIPS Workshop on GPU-Accelerated and Scalable Optimization, 2025
2025
-
[15]
Heterogeneous graph transformer
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. Heterogeneous graph transformer. InPro- ceedings of the web conference 2020, pages 2704–2710, 2020
2020
-
[16]
Wanjun Huang, Xiang Pan, Minghua Chen, and Steven H. Low. DeepOPF-V: Solving AC-OPF problems efficiently.IEEE Transactions on Power Systems, 37(1):800–803, 2022
2022
-
[17]
Accelerated computation and tracking of ac optimal power flow solu- tions using gpus
Youngdae Kim and Kibaek Kim. Accelerated computation and tracking of ac optimal power flow solu- tions using gpus. InWorkshop Proceedings of the 51st International Conference on Parallel Processing, pages 1–8, 2022
2022
-
[18]
Semi-Supervised Classification with Graph Convolutional Networks
TN Kipf. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review arXiv 2016
-
[19]
Gpu-accelerated sequential quadratic programming algorithm for solving acopf
Bowen Li and Kibaek Kim. Gpu-accelerated sequential quadratic programming algorithm for solving acopf. In2024 IEEE 63rd Conference on Decision and Control (CDC), 2024
2024
-
[20]
Topology-aware graph neural networks for learning feasible and adaptive ac-opf solutions.IEEE Transactions on Power Systems, 38(6):5660–5670, 2022
Shaohui Liu, Chengyang Wu, and Hao Zhu. Topology-aware graph neural networks for learning feasible and adaptive ac-opf solutions.IEEE Transactions on Power Systems, 38(6):5660–5670, 2022
2022
-
[21]
Sean Lovett, Miha Zgubic, Sofia Liguori, Sephora Madjiheurem, Hamish Tomlinson, Sophie Elster, Chris Apps, Sims Witherspoon, and Luis Piloto. Opfdata: Large-scale datasets for ac optimal power flow with topological perturbations.arXiv preprint arXiv:2406.07234, 2024
-
[22]
Multi-agent trajectory prediction with het- erogeneous edge-enhanced graph attention network.IEEE Transactions on Intelligent Transportation Systems, 23(7):9554–9567, 2022
Xiaoyu Mo, Zhuyu Huang, Yang Xing, and Chen Lv. Multi-agent trajectory prediction with het- erogeneous edge-enhanced graph attention network.IEEE Transactions on Intelligent Transportation Systems, 23(7):9554–9567, 2022
2022
-
[23]
Momoh, R
J.A. Momoh, R. Adapa, and M.E. El-Hawary. A review of selected optimal power flow literature to
-
[24]
nonlinear and quadratic programming approaches.IEEE Transactions on Power Systems, 14(1):96–104, 1999
i. nonlinear and quadratic programming approaches.IEEE Transactions on Power Systems, 14(1):96–104, 1999
1999
-
[25]
Alexis Montoison, Fran¸ cois Pacaud, Michael Saunders, Sungho Shin, and Dominique Orban. Madncl: a gpu implementation of algorithm ncl for large-scale, degenerate nonlinear programs.arXiv preprint arXiv:2510.05885, 2025
-
[26]
Physics-informed neural networks for ac optimal power flow.Electric Power Systems Research, 212:108412, 2022
Rahul Nellikkath and Spyros Chatzivasileiadis. Physics-informed neural networks for ac optimal power flow.Electric Power Systems Research, 212:108412, 2022. 15
2022
-
[27]
Optimal power flow using graph neural net- works
Damian Owerko, Fernando Gama, and Alejandro Ribeiro. Optimal power flow using graph neural net- works. InProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5930–5934, Barcelona, Spain, 2020
2020
-
[28]
Fran¸ cois Pacaud, Armin Nurkanovi´ c, Anton Pozharskiy, Alexis Montoison, and Sungho Shin. An aug- mented lagrangian method on gpu for security-constrained ac optimal power flow.arXiv preprint arXiv:2510.13333, 2025
-
[29]
Xiang Pan, Minghua Chen, Tianyu Zhao, and Steven H. Low. DeepOPF: A feasibility-optimized deep neural network approach for AC optimal power flow problems.IEEE Systems Journal, 17(1):673–683, 2023
2023
-
[30]
Xiang Pan, Wanjun Huang, Minghua Chen, and Steven H. Low. DeepOPF-AL: Augmented learning for solving AC-OPF problems with a multi-valued load-solution mapping. InThe 14th ACM International Conference on Future Energy Systems (e-Energy ’23), pages 391–396, Orlando, FL, USA, 2023
2023
-
[31]
CANOS : A fast and scalable neural AC - OPF solver robust to N-1 perturbations
Luis Piloto, Sofia Liguori, Sephora Madjiheurem, Miha Zgubic, Sean Lovett, Hamish Tomlinson, Sophie Elster, Chris Apps, and Sims Witherspoon. Canos: A fast and scalable neural ac-opf solver robust to n-1 perturbations.arXiv preprint arXiv:2403.17660, 2024
-
[32]
Accelerating optimal power flow with gpus: Simd abstraction of nonlinear programs and condensed-space interior-point methods.Electric Power Systems Research, 236:110651, 2024
Sungho Shin, Mihai Anitescu, and Fran¸ cois Pacaud. Accelerating optimal power flow with gpus: Simd abstraction of nonlinear programs and condensed-space interior-point methods.Electric Power Systems Research, 236:110651, 2024
2024
-
[33]
Scalable multi- period ac optimal power flow utilizing gpus with high memory capacities
Sungho Shin, Vishwas Rao, Michel Schanen, D Adrian Maldonado, and Mihai Anitescu. Scalable multi- period ac optimal power flow utilizing gpus with high memory capacities. In2024 Open Source Modelling and Simulation of Energy Systems (OSMSES), pages 1–6. IEEE, 2024
2024
-
[34]
Petar Veliˇ ckovi´ c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review arXiv 2017
-
[35]
Data-driven ac optimal power flow with physics-informed learning and calibrations, 2024
Junfei Wang and Pirathayini Srikantha. Data-driven ac optimal power flow with physics-informed learning and calibrations, 2024
2024
-
[36]
How Powerful are Graph Neural Networks?
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018
work page internal anchor Pith review arXiv 2018
-
[37]
Topology-transferable physics-guided graph neural network for real-time optimal power flow
Mei Yang, Gao Qiu, Junyong Liu, Youbo Liu, Tingjian Liu, Zhiyuan Tang, Lijie Ding, Yue Shui, and Kai Liu. Topology-transferable physics-guided graph neural network for real-time optimal power flow. IEEE Transactions on Industrial Informatics, 20(9):10857–10872, 2024
2024
-
[38]
Graph transformer networks.Advances in neural information processing systems, 32, 2019
Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim. Graph transformer networks.Advances in neural information processing systems, 32, 2019
2019
-
[39]
Qcqp-net: Reliably learning feasible alternating current optimal power flow solutions under constraints
Sihan Zeng, Youngdae Kim, Yuxuan Ren, and Kibaek Kim. Qcqp-net: Reliably learning feasible alternating current optimal power flow solutions under constraints. In6th Annual Learning for Dynamics & Control Conference, volume 242, 2024
2024
-
[40]
Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V. Chawla. Heterogeneous graph neural network. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), pages 793–803, 2019. The submitted manuscript has been created by UChicago Argonne, LLC, Operator of Argonne Na- tional Laboratory (“Argo...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.