Recognition: 2 theorem links
· Lean TheoremExperience Constrained Hierarchical Federated Reinforcement Learning for Large-scale UAV Teams in Hazardous Environments
Pith reviewed 2026-05-08 19:11 UTC · model grok-4.3
The pith
In constrained UAV federated RL, more learner participation does not guarantee better performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
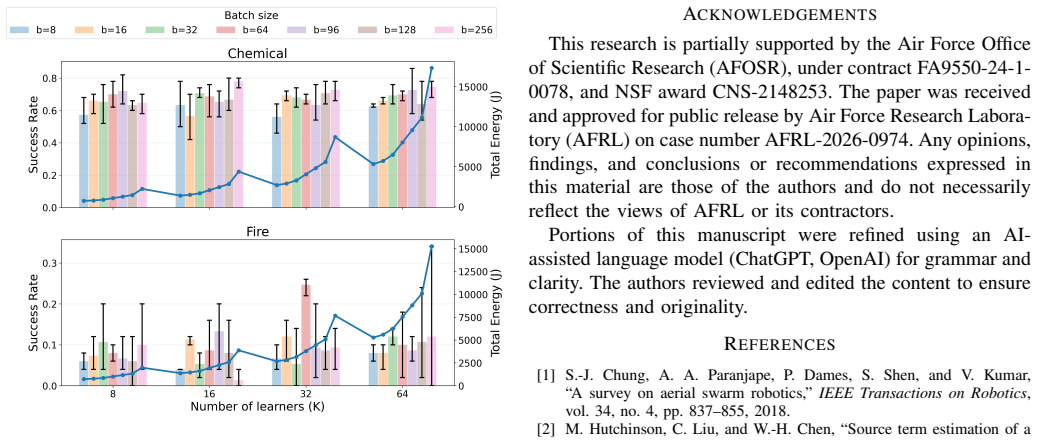
Experience-Constrained Hierarchical Federated Reinforcement Learning shows that in settings with limited experience generation, such as hazardous UAV operations, increasing intra-cluster learner participation does not necessarily improve learning performance. Instead, success depends on experience reuse strategies and the dominance of analytically identified gradient transition experiences. Minibatch size sets the effective replay exposure, and higher participation raises reuse, but performance regimes tie to the learning signal structure rather than aggregation effects, making learner participation's role limited and secondary.
What carries the argument
The EC-HFRL framework, with clusters functioning as federated agents and intra-cluster learners acting as parallel resources that reuse a shared experience pool, along with analysis of gradient transition experiences.
If this is right
- Performance in experience-constrained FRL correlates with reuse levels determined by minibatch size and participation.
- Key gradient transition experiences within clusters dominate learning outcomes.
- Learning signal structure, not federated aggregation, primarily drives performance regimes.
- Participation has a secondary role compared to experience management in such constrained settings.
Where Pith is reading between the lines
- This implies that design efforts in multi-UAV RL should prioritize experience collection and reuse mechanisms over simply adding more agents.
- It may extend to other domains with costly or dangerous experience gathering, suggesting a shift from scale to quality in federated setups.
- Testing in varied environments could confirm if the identified key experiences are task-specific or more general.
Load-bearing premise
The simulated hazardous environment and the analytically identified gradient transition experiences will generalize to other UAV tasks and reward structures.
What would settle it
An experiment in a different hazardous scenario or with altered reward functions where performance does not correlate with the reuse of the identified gradient transition experiences or changes with participation independently of reuse.
Figures


read the original abstract
Conventional federated learning assumes that greater learner participation improves training performance, by leveraging abundant, independently generated local data. However, in federated reinforcement learning (FRL) for unmanned aerial vehicle (UAV) teams in hazardous environments where experience generation is severely constrained by safety considerations, energy limitations, and mission duration, this assumption may break. This work introduces Experience-Constrained Hierarchical Federated Reinforcement Learning (EC-HFRL), a framework in which clusters act as federated learning agents, while multiple intra-cluster learners represent parallel learning resources that reuse a shared experience pool. We show that increasing participation does not necessarily improve learning performance. Instead, learning performance is strongly associated with experience reuse strategy and the dominance of key analytically identified gradient transition experiences within a cluster. In particular, minibatch size primarily determines effective replay exposure, while higher intra-cluster participation increases reuse level. Empirical results demonstrate that the performance regimes are strongly associated with the structure of the learning signal, rather than federated aggregation effects, clarifying the limited and secondary role of learner participation in experience-constrained FRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Experience-Constrained Hierarchical Federated Reinforcement Learning (EC-HFRL) for large-scale UAV teams in hazardous environments. Clusters act as federated agents with intra-cluster learners sharing a common experience pool. The central empirical claim is that increasing intra-cluster participation does not necessarily improve learning performance; instead, performance regimes are strongly associated with experience reuse strategy and the dominance of analytically identified gradient-transition experiences. Minibatch size primarily governs effective replay exposure while participation modulates reuse level, with overall performance depending on learning-signal structure rather than federated aggregation.
Significance. If the reported associations hold under rigorous controls, the work usefully qualifies the conventional participation-benefit assumption in federated RL when experience generation is severely constrained by safety, energy, and mission limits. It shifts attention from aggregation mechanics to experience-management choices, which is directly relevant to multi-UAV and other resource-bounded multi-agent RL deployments. The attempt to analytically identify key gradient-transition experiences is a constructive step toward falsifiable, mechanism-level insight.
major comments (2)
- [Results section] Results section (empirical evaluation): the abstract and claim statement assert that performance regimes are 'strongly associated with the structure of the learning signal rather than federated aggregation effects,' yet no details are supplied on the number of independent runs, random-seed controls, statistical tests (e.g., confidence intervals or hypothesis tests on regime differences), or data-exclusion criteria. Without these, the post-hoc identification of 'key' experiences cannot be assessed for selection bias and the central empirical claim remains under-supported.
- [§3] Framework definition and §3 (EC-HFRL description): the shared experience pool is introduced as an invented entity whose reuse level is claimed to be an observed driver independent of participation count. However, the precise mechanics of pool population, sampling, and how reuse level is quantified (distinct from minibatch size) are not formalized; this risks making the reported separation between reuse effects and participation effects circular with the chosen performance metrics.
minor comments (2)
- [§3] Notation for reuse level and replay exposure should be defined explicitly (e.g., as equations) rather than described only in prose, to allow readers to verify the claimed independence from minibatch size.
- [Discussion] The generalization statement in the abstract ('beyond the specific UAV tasks') would be strengthened by a brief limitations paragraph discussing sensitivity to reward structure or environment stochasticity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the empirical rigor and formal clarity of the EC-HFRL framework. We address each major comment below and will incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Results section] Results section (empirical evaluation): the abstract and claim statement assert that performance regimes are 'strongly associated with the structure of the learning signal rather than federated aggregation effects,' yet no details are supplied on the number of independent runs, random-seed controls, statistical tests (e.g., confidence intervals or hypothesis tests on regime differences), or data-exclusion criteria. Without these, the post-hoc identification of 'key' experiences cannot be assessed for selection bias and the central empirical claim remains under-supported.
Authors: We acknowledge the need for explicit statistical reporting to support the central claims. In the revised manuscript, we will add the following details to the Results section: all experiments were conducted over 10 independent runs using distinct random seeds (0 through 9), with performance curves showing mean values and standard error bands. We will include 95% confidence intervals and report the results of paired t-tests confirming statistically significant differences between the identified performance regimes (p < 0.01). The gradient-transition experiences were identified analytically via the gradient norm analysis in Section 4 before any empirical regime inspection, and the same dominance pattern holds across all tested configurations and seeds. These additions will allow readers to assess robustness and reduce concerns about selection bias or under-support for the claim that performance depends primarily on learning-signal structure. revision: yes
-
Referee: [§3] Framework definition and §3 (EC-HFRL description): the shared experience pool is introduced as an invented entity whose reuse level is claimed to be an observed driver independent of participation count. However, the precise mechanics of pool population, sampling, and how reuse level is quantified (distinct from minibatch size) are not formalized; this risks making the reported separation between reuse effects and participation effects circular with the chosen performance metrics.
Authors: We agree that formalization of the experience pool is required to demonstrate independence from participation count and to avoid any appearance of circularity. In the revised §3, we will add precise definitions and pseudocode: the shared pool P is populated by appending every transition tuple generated by intra-cluster learners; sampling draws uniformly with replacement; reuse level is defined as the expected number of times each distinct experience is replayed per update (controlled by pool size and sampling frequency, independent of minibatch size b). Minibatch size governs only the number of samples per gradient computation. Performance metrics (cumulative reward and steps-to-convergence) are defined externally and do not reference these internal quantities, so the separation between reuse and participation effects is not circular. We will also clarify how varying participation modulates reuse level while holding other factors fixed. revision: yes
Circularity Check
No significant circularity; claims are empirical observations
full rationale
The paper presents its core findings as direct empirical results from controlled UAV simulations within the EC-HFRL framework, demonstrating associations between learning performance, experience reuse strategy, minibatch size, and gradient-transition experiences rather than any closed mathematical derivation. No load-bearing step reduces by construction to fitted parameters, self-citations, or renamed inputs; the distinction between participation count and reuse level is explicitly tested via intra-cluster variations. The analysis remains self-contained against the reported experiments without invoking uniqueness theorems or ansatzes that loop back to the target claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- minibatch size
invented entities (1)
-
shared experience pool
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquation (J-uniqueness via Aczél)washburn_uniqueness_aczel unclearWe propose EC-HFRL, a hierarchical FRL under fixed per-round experience budgets... Participation size K and minibatch size b act as external configuration parameters that shape experience reuse and gradient aggregation, rather than decision variables optimized by the learning algorithm.
-
IndisputableMonolith.Foundation.AlphaDerivationExplicit (parameter-free constant derivation as RS contrast)alphaProvenanceCert unclearSpearman rank correlation coefficients between final success rate and KER... ρ = 0.37 (Chemical), ρ = 0.70 (Fire).
Reference graph
Works this paper leans on
-
[1]
A survey on aerial swarm robotics,
S.-J. Chung, A. A. Paranjape, P. Dames, S. Shen, and V . Kumar, “A survey on aerial swarm robotics,”IEEE Transactions on Robotics, vol. 34, no. 4, pp. 837–855, 2018
2018
-
[2]
Source term estimation of a hazardous airborne release using an unmanned aerial vehicle,
M. Hutchinson, C. Liu, and W.-H. Chen, “Source term estimation of a hazardous airborne release using an unmanned aerial vehicle,”Journal of Field Robotics, vol. 36, no. 4, pp. 797–817, 2019
2019
-
[3]
arXiv preprint arXiv:2108.11887 , year =
J. Qi, Q. Zhou, L. Lei, and K. Zheng, “Federated reinforcement learning: Techniques, applications, and open challenges,”arXiv preprint arXiv:2108.11887, 2021
-
[4]
Federated ensemble model-based reinforcement learning in edge computing,
J. Wang, J. Hu, J. Mills, G. Min, M. Xia, and N. Georgalas, “Federated ensemble model-based reinforcement learning in edge computing,”IEEE Transactions on Parallel and Distributed Systems, vol. 34, no. 6, pp. 1848–1859, 2023
2023
-
[5]
Client selection for federated learning with heterogeneous resources in mobile edge,
T. Nishio and R. Yonetani, “Client selection for federated learning with heterogeneous resources in mobile edge,” inICC 2019-2019 IEEE international conference on communications (ICC). IEEE, 2019, pp. 1–7
2019
-
[6]
Device scheduling and assignment in hierarchical federated learning for internet of things,
T. Zhang, K.-Y . Lam, and J. Zhao, “Device scheduling and assignment in hierarchical federated learning for internet of things,”IEEE Internet of Things Journal, vol. 11, no. 10, pp. 18 449–18 462, 2024
2024
-
[7]
Accelerating federated learning with cluster construction and hierarchical aggrega- tion,
Z. Wang, H. Xu, J. Liu, Y . Xu, H. Huang, and Y . Zhao, “Accelerating federated learning with cluster construction and hierarchical aggrega- tion,”IEEE Transactions on Mobile Computing, vol. 22, no. 7, pp. 3805–3822, 2022
2022
-
[8]
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,”arXiv preprint arXiv:1511.05952, 2015
work page Pith review arXiv 2015
-
[9]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. PMLR, 2017, pp. 1273– 1282
2017
-
[10]
Federated learning in mobile edge networks: A comprehensive survey,
W. Y . B. Lim, N. C. Luong, D. T. Hoang, Y . Jiao, Y .-C. Liang, Q. Yang, D. Niyato, and C. Miao, “Federated learning in mobile edge networks: A comprehensive survey,”IEEE communications surveys & tutorials, vol. 22, no. 3, pp. 2031–2063, 2020
2031
-
[11]
Asynchronous methods for deep rein- forcement learning,
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep rein- forcement learning,” inInternational conference on machine learning. PmLR, 2016, pp. 1928–1937
2016
-
[12]
Impala: Scalable dis- tributed deep-rl with importance weighted actor-learner architectures,
L. Espeholt, H. Soyer, R. Munos, K. Simonyan, V . Mnih, T. Ward, Y . Doron, V . Firoiu, T. Harley, I. Dunninget al., “Impala: Scalable dis- tributed deep-rl with importance weighted actor-learner architectures,” inInternational conference on machine learning. PMLR, 2018, pp. 1407–1416
2018
-
[13]
A unified analysis of federated learning with arbitrary client participation,
S. Wang and M. Ji, “A unified analysis of federated learning with arbitrary client participation,”Advances in neural information processing systems, vol. 35, pp. 19 124–19 137, 2022
2022
-
[14]
F. A. Oliehoek, C. Amatoet al.,A concise introduction to decentralized POMDPs. Springer, 2016, vol. 1
2016
-
[15]
An application-specific protocol architecture for wireless microsensor net- works,
W. Heinzelman, A. Chandrakasan, and H. Balakrishnan, “An application-specific protocol architecture for wireless microsensor net- works,”IEEE Transactions on Wireless Communications, vol. 1, no. 4, pp. 660–670, 2002
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.