Recognition: 2 theorem links
· Lean TheoremGradient-Discrepancy Acquisition for Pool-Based Active Learning
Pith reviewed 2026-05-08 18:41 UTC · model grok-4.3
The pith
A gradient-based acquisition criterion derived from a generalization bound can guide the selection of informative points in active learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The core discovery is that the gradient of the generalization bound with respect to the model parameters yields a discrepancy measure that serves as an effective acquisition function, allowing the identification of points whose labels would most contribute to better generalization performance in the active learning process.
What carries the argument
The gradient-discrepancy acquisition criterion, which derives scores for unlabeled points from the gradient of the generalization bound to quantify their potential impact on model parameters.
If this is right
- This criterion can replace uncertainty measures when performing uncertainty sampling.
- It can be added to diversity-based selection methods that also consider how sampled points are spread out.
- Theoretical justification supports the use of this gradient signal for informativeness.
- Empirical tests confirm better results than standard baselines in active learning scenarios.
Where Pith is reading between the lines
- If the approach holds, it may apply across different model types and data domains beyond the evaluated cases.
- Computing these gradients could be optimized for scalability in large-scale applications.
- Combining this with other acquisition strategies might yield hybrid methods with further gains.
- Similar gradient-based ideas could influence data selection in related areas like semi-supervised learning.
Load-bearing premise
The generalization bound from which the criterion is derived gives a signal whose gradient accurately highlights the most informative points for the given model and data.
What would settle it
A direct comparison on benchmark datasets where using the proposed criterion leads to no measurable improvement in final model accuracy or convergence speed over conventional uncertainty or random selection methods.
Figures




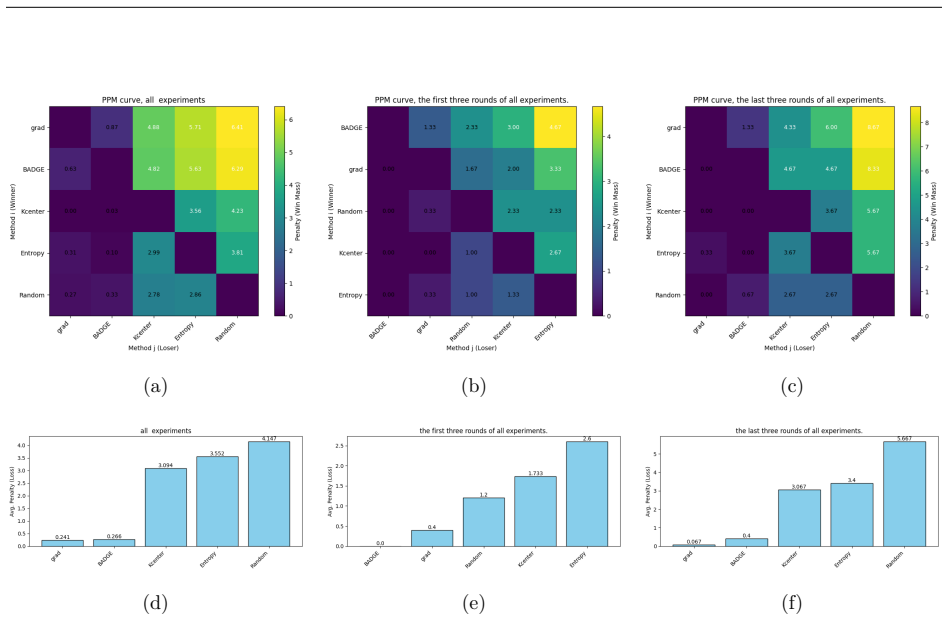



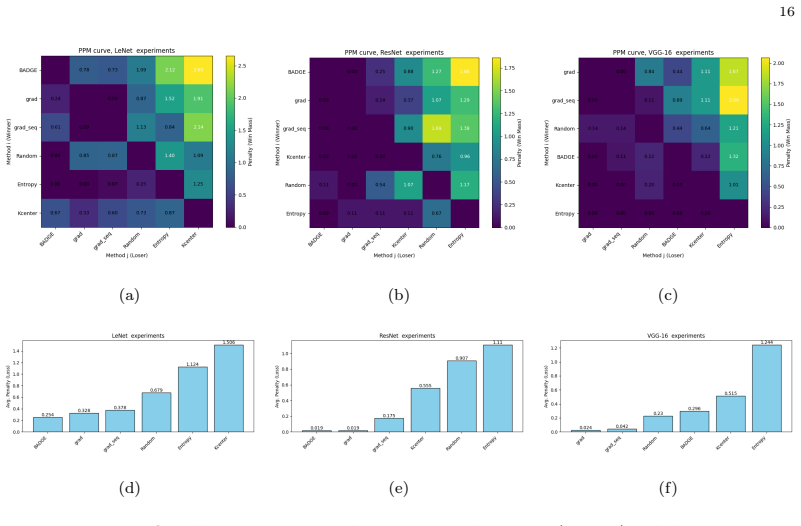



read the original abstract
The effectiveness of active learning hinges on the choice of the acquisition criterion by which a learning algorithm selects potentially informative data points whose label is subsequently queried. This paper proposes a novel gradient-based acquisition criterion, derived from a generalization bound introduced by Luo et al. (2022). This criterion can be applied in lieu of uncertainty measures in uncertainty sampling, or incorporated into diversity-based methods that consider the spread of sampled points in addition to the uncertainty of their labels. We provide a theoretical justification of the proposed acquisition criterion, and demonstrate its effectiveness in an empirical evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel gradient-based acquisition criterion for pool-based active learning, obtained by differentiating a generalization bound from Luo et al. (2022) with respect to model parameters. The resulting gradient-discrepancy serves as an informativeness score that can replace uncertainty sampling or be combined with diversity-based selection. The authors claim a theoretical justification for this criterion and demonstrate its effectiveness through empirical evaluation.
Significance. If the gradient signal from the bound reliably identifies points that improve generalization, the method would supply a principled, bound-derived alternative to heuristic acquisition functions. This could strengthen the theoretical grounding of active learning and allow seamless integration into existing uncertainty or diversity pipelines.
major comments (1)
- The load-bearing step is the claim that the gradient of the Luo et al. (2022) generalization bound w.r.t. model parameters yields an informative acquisition score. Because the bound is an upper bound whose value is typically dominated by worst-case terms (covering numbers, Lipschitz constants, Rademacher factors), its gradient need not correlate with actual test-error reduction on the concrete data distribution; the manuscript does not supply a concrete argument or auxiliary result showing that this gradient is sensitive to label information rather than to those constant factors.
minor comments (2)
- The abstract states that empirical results are shown, yet provides no information on the datasets, baselines, or evaluation metrics; this information should be added for completeness.
- Notation distinguishing the proposed gradient-discrepancy score from standard uncertainty measures should be introduced early and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the paper's potential contribution. We address the major comment below and will revise the manuscript to strengthen the theoretical exposition.
read point-by-point responses
-
Referee: The load-bearing step is the claim that the gradient of the Luo et al. (2022) generalization bound w.r.t. model parameters yields an informative acquisition score. Because the bound is an upper bound whose value is typically dominated by worst-case terms (covering numbers, Lipschitz constants, Rademacher factors), its gradient need not correlate with actual test-error reduction on the concrete data distribution; the manuscript does not supply a concrete argument or auxiliary result showing that this gradient is sensitive to label information rather than to those constant factors.
Authors: We appreciate this precise observation. The generalization bound from Luo et al. (2022) decomposes into parameter-independent terms (covering numbers, Lipschitz constants, and Rademacher factors, which are fixed for a given hypothesis class and do not depend on the specific model parameters θ) and parameter-dependent terms that involve the empirical risk. Differentiating the entire bound with respect to θ therefore cancels the constant terms and produces a gradient driven solely by the θ-dependent component, which is the gradient of the loss evaluated on labeled points. Because this loss gradient explicitly incorporates the queried label y, the resulting gradient-discrepancy score is sensitive to label information. We will revise the manuscript to include an explicit decomposition of the bound and a short auxiliary derivation showing that the acquisition function depends on label-sensitive gradients rather than on the constant factors. This clarification directly addresses the concern while preserving the original derivation. revision: yes
Circularity Check
Derivation from external Luo et al. (2022) bound introduces no self-referential reduction or fitted-input prediction.
full rationale
The paper's central acquisition function is obtained by differentiating the generalization bound of Luo et al. (2022) with respect to model parameters. This step is independent of any quantities fitted or defined inside the present manuscript; the bound itself is an external result whose validity is not presupposed by the current work. No self-citation is load-bearing, no ansatz is smuggled, and no prediction reduces by construction to an input parameter. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The generalization bound introduced by Luo et al. (2022) holds for the neural network models and data distributions used in the active learning experiments.
Lean theorems connected to this paper
-
Cost/FunctionalEquation (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DF_θ(S, T) = ∇f(θ;S) − ∇f(θ;T) ... we use the bound-motivated quantity as a practical scoring rule.
-
Foundation/ArrowOfTime (Berry-phase monotonicity) — only superficial analogy; mechanism is unrelatedz_monotone_absolute unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition A.1 (Sufficient conditions for eventual contraction of gradient discrepancy) ... ρ := L_Δ q / μ_Δ < 1 ⇒ ∥∇Δ(θ_{t+1})∥ ≤ ρ ∥∇Δ(θ_t)∥.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Active learning literature survey
B. Settles. “Active learning literature survey”. In: (2009)
2009
-
[2]
Deep bayesian active learning with image data
Y. Gal, R. Islam, and Z. Ghahramani. “Deep bayesian active learning with image data”. In: International conference on machine learning. PMLR. 2017, pp. 1183–1192
2017
-
[3]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
O. Sener and S. Savarese. “Active learning for convolutional neural networks: A core-set approach”. In:arXiv preprint arXiv:1708.00489(2017)
work page Pith review arXiv 2017
-
[4]
Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift
Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. V. Dillon, B. Lakshmi- narayanan, and J. Snoek. “Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift”. In:Advances in Neural Information Processing Systems. 2019
2019
-
[5]
Practical Obstacles to Deploying Active Learn- ing
D. Lowell, Z. C. Lipton, and B. C. Wallace. “Practical Obstacles to Deploying Active Learn- ing”. In:Proceedings of the 2019 Conference on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP). 2019, pp. 21–30
2019
-
[6]
Multiple-Instance Active Learning
B. Settles, M. Craven, and S. Ray. “Multiple-Instance Active Learning”. In:Advances in Neural Information Processing Systems. Ed. by J. Platt, D. Koller, Y. Singer, and S. Roweis. Vol. 20. Curran Associates, Inc., 2007.url:https : / / proceedings . neurips . cc / paper _ files/paper/2007/file/a1519de5b5d44b31a01de013b9b51a80-Paper.pdf. 18 LeNet-SVHN VGG-S...
2007
-
[7]
Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds
J. T. Ash, C. Zhang, A. Krishnamurthy, J. Langford, and A. Agarwal. “Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds”. In:Proceedings of the International Conference on Learning Representations (ICLR). 2020.url:https : / / openreview . net / forum?id=ryghZJBKPS
2020
-
[8]
Grad-match: Gradient matching based data subset selection for efficient deep model training, 2021
K. Killamsetty, D. Sivasubramanian, B. Mirzasoleiman, G. Ramakrishnan, A. De, and R. K. Iyer. “GRAD-MATCH: AGradientMatchingBased DataSubsetSelectionforEfficientLearn- ing”. In:CoRRabs/2103.00123 (2021). arXiv:2103.00123.url:https://arxiv.org/abs/ 2103.00123
-
[9]
Deep Learning on a Data Diet: Finding Important Examples Early in Training
M. Paul, S. Ganguli, and G. K. Dziugaite. “Deep Learning on a Data Diet: Finding Important Examples Early in Training”. In:CoRRabs/2107.07075 (2021). arXiv:2107 . 07075.url: https://arxiv.org/abs/2107.07075
-
[10]
Generalization bounds for gradient methods via discrete and con- tinuous prior
X. Luo, B. Luo, and J. Li. “Generalization bounds for gradient methods via discrete and con- tinuous prior”. In:Advances in Neural Information Processing Systems35 (2022), pp. 10600– 10614
2022
-
[11]
NewsWeeder: Learning to Filter Netnews
K. Lang. “NewsWeeder: Learning to Filter Netnews”. In:Proceedings of the Twelfth Interna- tional Conference on Machine Learning (ICML). 1995, pp. 331–339. [12]20 Newsgroups Data Set.https://qwone.com/~jason/20Newsgroups/. Accessed 2025-12-15
1995
-
[12]
R. Cole and M. Fanty.ISOLET [Dataset]. UCI Machine Learning Repository. Accessed 2025- 12-15. 1991.doi:10.24432/C51G69.url:https://archive.ics.uci.edu/ml/datasets/ isolet. [14]pokerhand-normalized (OpenML Dataset 155). OpenML. Accessed 2025-12-15.url:https: //www.openml.org/d/155
work page doi:10.24432/c51g69.url:https://archive.ics.uci.edu/ml/datasets/ 2025
-
[13]
R. Cattral and F. Oppacher.Poker Hand [Dataset]. UCI Machine Learning Repository. Ac- cessed 2025-12-15. 2002.doi:10.24432/C5KW38.url:https://archive.ics.uci.edu/ml/ datasets/poker+hand
work page doi:10.24432/c5kw38.url:https://archive.ics.uci.edu/ml/ 2025
-
[14]
OpenML: Networked Science in Machine Learning
J. Vanschoren, J. N. van Rijn, B. Bischl, and L. Torgo. “OpenML: Networked Science in Machine Learning”. In:SIGKDD Explorations15.2 (2013), pp. 49–60.doi:10.1145/2641190. 2641198
-
[15]
Krizhevsky.Learning multiple layers of features from tiny images
A. Krizhevsky.Learning multiple layers of features from tiny images. Tech. rep. University of Toronto, 2009. 19
2009
-
[16]
Coates.STL-10 Dataset
A. Coates.STL-10 Dataset. Stanford University. Accessed 2025-12-15.url:http : / / cs . stanford.edu/~acoates/stl10
2025
-
[17]
L. N. Darlow, E. J. Crowley, A. Antoniou, and A. Storkey.CINIC-10 Is Not ImageNet or CIFAR-10 [Dataset]. Accessed 2025-12-15. 2018.doi:10 . 7488 / ds / 2448.url:https : //datashare.ed.ac.uk/handle/10283/3192
2025
-
[18]
computer: Bench- marking machine learning algorithms for traffic sign recognition
J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel. “Man vs. Computer: Benchmarking Machine Learning Algorithms for Traffic Sign Recognition”. In:Neural Networks32 (2012), pp. 323–332.doi:10.1016/j.neunet.2012.02.016
-
[19]
Reading Digits in Natural Images with Unsupervised Feature Learning
Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng. “Reading Digits in Natural Images with Unsupervised Feature Learning”. In:NIPS Workshop on Deep Learning and Unsupervised Feature Learning. 2011.url:http://ufldl.stanford.edu/housenumbers/
2011
-
[20]
Learning representations by back- propagating errors
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. “Learning representations by back- propagating errors”. In:Nature323 (1986), pp. 533–536.doi:10.1038/323533a0.url:https: //www.nature.com/articles/323533a0
-
[21]
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren, and J. Sun. “Deep Residual Learning for Image Recognition”. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016, pp. 770– 778.doi:10.1109/CVPR.2016.90.url:https://www.cv- foundation.org/openaccess/ content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
-
[22]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition”. In:International Conference on Learning Representations (ICLR). 2015.url: https://arxiv.org/abs/1409.1556
work page Pith review arXiv 2015
-
[23]
Gradient-based learning applied to docu- ment recognition
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. “Gradient-based learning applied to docu- ment recognition”. In:Proceedings of the IEEE86.11 (1998), pp. 2278–2324
1998
-
[24]
Statistical Comparisons of Classifiers over Multiple Data Sets
J. Demšar. “Statistical Comparisons of Classifiers over Multiple Data Sets”. In:Journal of Machine Learning Research7 (2006), pp. 1–30
2006
-
[25]
An Extension on “Statistical Comparisons of Classifiers over Mul- tiple Data Sets
S. García and F. Herrera. “An Extension on “Statistical Comparisons of Classifiers over Mul- tiple Data Sets” for all Pairwise Comparisons”. In:Journal of Machine Learning Research9 (2008), pp. 2677–2694
2008
-
[26]
Benchmarking Optimization Software with Performance Profiles
E. D. Dolan and J. J. Moré. “Benchmarking Optimization Software with Performance Pro- files”. In:Mathematical Programming91.2 (2002), pp. 201–213.doi:10.1007/s101070100263
-
[27]
Herding Dynamical Weights to Learn
M. Welling. “Herding Dynamical Weights to Learn”. In:Proceedings of the 26th International Conference on Machine Learning (ICML). 2009
2009
-
[28]
Super-Samples from Kernel Herding
Y. Chen, M. Welling, and A. Smola. “Super-Samples from Kernel Herding”. In:Proceedings of the 26th Conference on Uncertainty in Artificial Intelligence (UAI). 2010
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.