Recognition: unknown
Visual Latents Know More Than They Say: Unsilencing Latent Reasoning in MLLMs
Pith reviewed 2026-05-09 15:44 UTC · model grok-4.3
The pith
Visual latents in multimodal models contain richer reasoning than they contribute because training suppresses their role in favor of direct visual shortcuts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
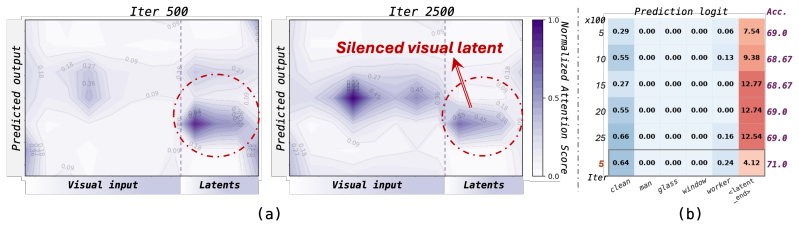
Although visual latents grow semantically rich during training, the autoregressive objective systematically suppresses their contribution to answer prediction by driving them toward transition-like states rather than informative content. Disentangling the objectives at inference time through two stages—query-guided contrastive latent-visual alignment followed by confidence-progression reward optimization—routes predictions through the latent reasoning path instead of bypassing it, unleashing suppressed capacity without any parameter updates.
What carries the argument
The Silenced Visual Latents phenomenon, in which training dynamics suppress latent reasoning contribution, addressed by inference-time two-stage optimization of the latent tokens themselves.
If this is right
- Latent reasoning becomes a compact high-dimensional alternative to textual chain-of-thought for integrating visual evidence.
- Performance improves across eight benchmarks and four model backbones with no weight updates required.
- Predictions can be systematically routed through enriched visual latents instead of direct input pathways.
- Conflicting objectives of semantic enrichment and prediction contribution can be separated by freezing the backbone and tuning only latents.
Where Pith is reading between the lines
- Similar suppression of internal states may occur in non-visual reasoning paths within the same models or in pure language models.
- The approach could be tested on other multimodal tasks such as visual captioning to check if latent routing yields more coherent outputs.
- Combining inference-time latent tuning with lightweight adapters might amplify gains while keeping most parameters fixed.
- If the effect is general, current inference practices in multimodal systems may routinely underuse available internal representations.
Load-bearing premise
The autoregressive training objective pushes latent tokens into uninformative states, and the two inference stages can reliably force the model to route its prediction through those latents rather than falling back to direct visual input.
What would settle it
Applying the two-stage inference optimization to a standard visual reasoning benchmark and observing neither accuracy gains nor measurable increases in progressive token confidence along the latent span would show the suppression cannot be unsilenced this way.
Figures






read the original abstract
Continuous latent-space reasoning offers a compact alternative to textual chain-of-thought for multimodal models, enabling high-dimensional visual evidence to be integrated without explicit reasoning tokens. However, we identify a previously overlooked optimization pathology in existing latent visual reasoning methods: although visual latents become semantically enriched during training, their contribution to final answer prediction is systematically suppressed. Within the shared parameter space, the autoregressive objective favors shortcut reliance on direct visual input, driving latent tokens toward transition-like states rather than informative reasoning content. We term this phenomenon Silenced Visual Latents. To address it, we disentangle the two conflicting objectives by directly optimizing the latent reasoning at inference time, keeping backbone parameters frozen. In Stage I, visual latents are warmed up via query-guided contrastive latent--visual alignment, improving semantic quality while preventing latent collapse. In Stage II, the latent reasoning is further optimized via a confidence-progression reward, which incentivizes predicted token distributions along the latent span to become progressively more concentrated, routing predictions through the latent reasoning rather than bypassing it. Experiments across eight benchmarks and four model backbones show that inference-time latent optimization, without any parameter updates, effectively unleashes the suppressed reasoning capacity of visual latents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual latents in MLLMs are systematically suppressed ('Silenced Visual Latents') by the autoregressive objective during training, which favors direct visual shortcuts and drives latents to transition-like states. It proposes a parameter-free, inference-time two-stage optimization—Stage I (query-guided contrastive latent-visual alignment) and Stage II (confidence-progression reward)—to improve latent semantic quality and route predictions through the latent span. Experiments across eight benchmarks and four model backbones show performance gains without any parameter updates, arguing that this unleashes suppressed reasoning capacity in visual latents.
Significance. If the results and mechanistic interpretation hold, the work would be significant for multimodal learning by demonstrating a practical inference-time method to enhance latent reasoning without retraining. It identifies a potential optimization pathology in existing latent visual reasoning approaches and reports gains on multiple benchmarks and backbones, offering an efficient alternative to textual chain-of-thought or full fine-tuning.
major comments (2)
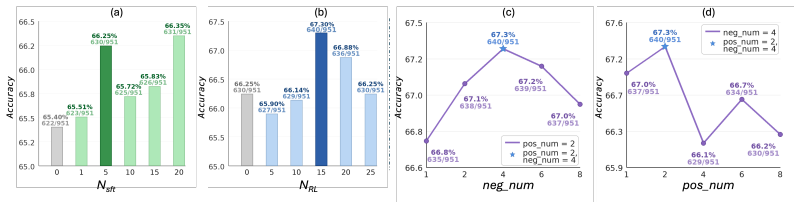
- [§5] The central claim that gains arise specifically from routing predictions through the latent span (rather than improved visual-query alignment alone) is load-bearing but unsupported by isolating evidence. No attention/gradient attribution to latent tokens, intervention experiments, or comparison against equivalent optimization applied only to visual features is described, leaving alternative explanations for the benchmark lifts unaddressed.
- [Abstract and §5] The abstract and results report gains on eight benchmarks but provide no quantitative values, error bars, ablation controls on Stage I vs. Stage II, or data exclusion rules. This prevents assessment of effect sizes and robustness, which is necessary to substantiate the claim that the stages reverse the silencing pathology.
minor comments (2)
- [§1] The introduction of 'Silenced Visual Latents' as a new term would benefit from a formal mathematical characterization or precise definition early in the paper to distinguish it from related concepts like latent collapse.
- Figure and table captions should explicitly state the number of runs, random seeds, and statistical tests used to support the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the evidence and presentation of our results. We address each major comment below and commit to revisions that improve the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§5] The central claim that gains arise specifically from routing predictions through the latent span (rather than improved visual-query alignment alone) is load-bearing but unsupported by isolating evidence. No attention/gradient attribution to latent tokens, intervention experiments, or comparison against equivalent optimization applied only to visual features is described, leaving alternative explanations for the benchmark lifts unaddressed.
Authors: We agree that isolating the contribution of latent-span routing is essential to support the silencing pathology interpretation. The two-stage design separates query-guided alignment (Stage I) from the confidence-progression reward (Stage II), and the manuscript reports incremental gains from adding Stage II. However, we did not include intervention experiments, gradient attributions on latent tokens, or direct comparisons to equivalent optimization applied only to visual features. In the revision we will add these ablations and analyses to provide the requested isolating evidence. revision: yes
-
Referee: [Abstract and §5] The abstract and results report gains on eight benchmarks but provide no quantitative values, error bars, ablation controls on Stage I vs. Stage II, or data exclusion rules. This prevents assessment of effect sizes and robustness, which is necessary to substantiate the claim that the stages reverse the silencing pathology.
Authors: We acknowledge that the abstract summarizes gains at a high level without specific numbers or error bars, and that clearer presentation of ablations and data rules would aid assessment. The full experiments section contains tables with performance metrics across the eight benchmarks and four backbones, along with Stage I vs. Stage II ablations; however, we will revise the abstract to include representative quantitative results with error bars, ensure all ablations are explicitly labeled with data exclusion criteria, and add any missing robustness details. revision: partial
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper's central contribution is an empirical inference-time procedure (Stage I query-guided contrastive alignment followed by Stage II confidence-progression reward) applied to frozen backbones. These stages are defined directly from the stated objectives of alignment and progressive concentration of token distributions, without any equations that reduce reported benchmark gains to quantities fitted on the same test data or to self-referential definitions of the 'silenced' phenomenon. The identification of the autoregressive pathology is presented as an observational claim rather than a derived theorem, and no load-bearing self-citations or uniqueness results are invoked in the provided text to force the method. Experiments on external benchmarks therefore stand as independent measurements rather than tautological outputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Silenced Visual Latents
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report, 2025.URL https://arxiv. org/abs/2502.13923, 6:13–23, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
2025
-
[3]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. Univg-r1: Reasoning guided universal visual grounding with reinforcement learning.arXiv preprint arXiv:2505.14231, 2025
-
[4]
Sft or rl? an early investigation into training r1-like reasoning large vision-language models, 2025
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models, 2025
2025
-
[5]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
Think with 3d: Geometric imagination grounded spatial reasoning from limited views
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geometric imagination grounded spatial reasoning from limited views. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
2026
-
[7]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
2024
-
[8]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive.arXiv preprint arXiv:2404.12390, 2024
-
[9]
Refocus: Visual editing as a chain of thought for structured image understanding
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Richard Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding. InInternational Conference on Machine Learning, pages 17783–17805. PMLR, 2025
2025
-
[10]
Omni-MATH: A universal olympiad level mathematic benchmark for large language models
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang. Omni-MATH: A universal olympiad level mathematic benchmark for large language models. InThe Thirteenth ...
2025
-
[11]
Interleaved-modal chain-of-thought, 2025
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought, 2025
2025
-
[12]
Hallusion- bench: An advanced diagnostic suite for entangled language hallucination & visual illusion in large vision-language models, 2023
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusion- bench: An advanced diagnostic suite for entangled language hallucination & visual illusion in large vision-language models, 2023
2023
-
[13]
Training large language models to reason in a continuous latent space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling
-
[14]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Information Processing Systems, 37:139348–139379, 2024
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Information Processing Systems, 37:139348–139379, 2024. 11
2024
-
[15]
Latent visual reasoning
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning. InInternational Conference on Learning Representations, 2026
2026
-
[16]
Reasoning Within the Mind: Dynamic Multimodal Interleaving in Latent Space
Chengzhi Liu, Yuzhe Yang, Yue Fan, Qingyue Wei, Sheng Liu, and Xin Eric Wang. Rea- soning within the mind: Dynamic multimodal interleaving in latent space.arXiv preprint arXiv:2512.12623, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Deliberation in latent space via differentiable cache augmentation
Luyang Liu, Jonas Pfeiffer, Jiaxing Wu, Jun Xie, and Arthur Szlam. Deliberation in latent space via differentiable cache augmentation. InF orty-second International Conference on Machine Learning
-
[18]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[19]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. InThe 36th Conference on Neural Information Process- ing Systems (NeurIPS), 2022
2022
-
[20]
A survey on latent reasoning.arxiv, 2025
M-A-P. A survey on latent reasoning.arxiv, 2025
2025
-
[21]
Jizheng Ma, Xiaofei Zhou, Geyuan Zhang, Yanlong Song, and Han Yan. Multimodal reasoning via latent refocusing.arXiv preprint arXiv:2511.02360, 2025
-
[22]
Compositional chain-of- thought prompting for large multimodal models
Chancharik Mitra, Brandon Huang, Trevor Darrell, and Roei Herzig. Compositional chain-of- thought prompting for large multimodal models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14420–14431, June 2024
2024
-
[23]
Yiming Qin, Bomin Wei, Jiaxin Ge, Konstantinos Kallidromitis, Stephanie Fu, Trevor Darrell, and XuDong Wang. Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens.arXiv preprint arXiv:2511.19418, 2025
-
[24]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning.Advances in Neural Information Processing Systems, 37:8612–8642, 2024
2024
-
[25]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025
2025
-
[26]
Swireasoning: Switch-thinking in latent and explicit for pareto-superior reasoning LLMs
Dachuan Shi, Abedelkadir Asi, Keying Li, Xiangchi Yuan, Leyan Pan, Wenke Lee, and Wen Xiao. Swireasoning: Switch-thinking in latent and explicit for pareto-superior reasoning LLMs. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[27]
Think silently, think fast: Dynamic latent compression of llm reasoning chains.Advances in Neural Information Processing Systems, 2025
Wenhui Tan, Jiaze Li, Jianzhong Ju, Zhenbo Luo, Jian Luan, and Ruihua Song. Think silently, think fast: Dynamic latent compression of llm reasoning chains.Advances in Neural Information Processing Systems, 2025
2025
-
[28]
Visual position prompt for mllm based visual grounding.IEEE Transactions on Multimedia, 2026
Wei Tang, Yanpeng Sun, Qinying Gu, and Zechao Li. Visual position prompt for mllm based visual grounding.IEEE Transactions on Multimedia, 2026
2026
-
[29]
Eyes wide shut? exploring the visual shortcomings of multimodal llms, 2024
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms, 2024
2024
-
[30]
MLLM can see? dynamic correction decoding for hallucination mitigation
Chenxi Wang, Xiang Chen, Ningyu Zhang, Bozhong Tian, Haoming Xu, Shumin Deng, and Huajun Chen. MLLM can see? dynamic correction decoding for hallucination mitigation. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[31]
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language.arXiv preprint arXiv:2511.21395, 2025. 12
-
[32]
Weixing Wang, Zifeng Ding, Jindong Gu, Rui Cao, Christoph Meinel, Gerard de Melo, and Haojin Yang. Image tokens matter: Mitigating hallucination in discrete tokenizer-based large vision-language models via latent editing.arXiv preprint arXiv:2505.21547, 2025
-
[33]
Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
-
[34]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[35]
Deepscientist: Advancing frontier-pushing scientific findings progressively
Yixuan Weng, Minjun Zhu, Qiujie Xie, QiYao Sun, Zhen Lin, Sifan Liu, and Yue Zhang. Deepscientist: Advancing frontier-pushing scientific findings progressively. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[36]
Mind’s eye of llms: visualization-of-thought elicits spatial reasoning in large language models
Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, and Furu Wei. Mind’s eye of llms: visualization-of-thought elicits spatial reasoning in large language models. Advances in Neural Information Processing Systems, 37:90277–90317, 2024
2024
-
[37]
Mini-omni-reasoner: Token-level thinking-in-speaking in large speech models.arXiv preprint, 2025
Zhifei Xie, Ziyang Ma, Zihang Liu, Kaiyu Pang, Hongyu Li, Jialin Zhang, Yue Liao, Deheng Ye, Chunyan Miao, and Shuicheng Yan. Mini-omni-reasoner: Token-level thinking-in-speaking in large speech models.arXiv preprint, 2025
2025
-
[38]
Zhongxing Xu, Zhonghua Wang, Zhe Qian, Dachuan Shi, Feilong Tang, Ming Hu, Shiyan Su, Xiaocheng Zou, Wei Feng, Dwarikanath Mahapatra, Yifan Peng, Mingquan Lin, and Zongyuan Ge. Thinking in uncertainty: Mitigating hallucinations in mlrms with latent entropy-aware decoding.arXiv preprint arXiv:2603.13366, 2026
-
[39]
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization, 2025
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, Bo Zhang, and Wei Chen. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization, 2025
2025
-
[40]
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine men- tal imagery: Empower multimodal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025
-
[41]
Diffusion of thought: Chain-of-thought reasoning in diffusion language models.Advances in Neural Information Processing Systems, 37:105345–105374, 2024
Jiacheng Ye, Shansan Gong, Liheng Chen, Lin Zheng, Jiahui Gao, Han Shi, Chuan Wu, Xin Jiang, Zhenguo Li, Wei Bi, et al. Diffusion of thought: Chain-of-thought reasoning in diffusion language models.Advances in Neural Information Processing Systems, 37:105345–105374, 2024
2024
-
[42]
A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
2024
-
[43]
Jusheng Zhang, Kaitong Cai, Xiaoyang Guo, Sidi Liu, Qinhan Lv, Ruiqi Chen, Jing Yang, Yijia Fan, Xiaofei Sun, Jian Wang, et al. Mm-cot: a benchmark for probing visual chain-of-thought reasoning in multimodal models.arXiv preprint arXiv:2512.08228, 2025
-
[44]
Multi- modal chain-of-thought reasoning in language models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multi- modal chain-of-thought reasoning in language models. 2024
2024
-
[45]
Promptcot: Synthesizing olympiad- level problems for mathematical reasoning in large language models
Xueliang Zhao, Wei Wu, Jian Guan, and Lingpeng Kong. Promptcot: Synthesizing olympiad- level problems for mathematical reasoning in large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 18167–18188, 2025
2025
-
[46]
Qiji Zhou, Ruochen Zhou, Zike Hu, Panzhong Lu, Siyang Gao, and Yue Zhang. Image-of- thought prompting for visual reasoning refinement in multimodal large language models.arXiv preprint arXiv:2405.13872, 2024
-
[47]
Intern-s1-pro: Scientific multimodal foundation model at trillion scale, 2026
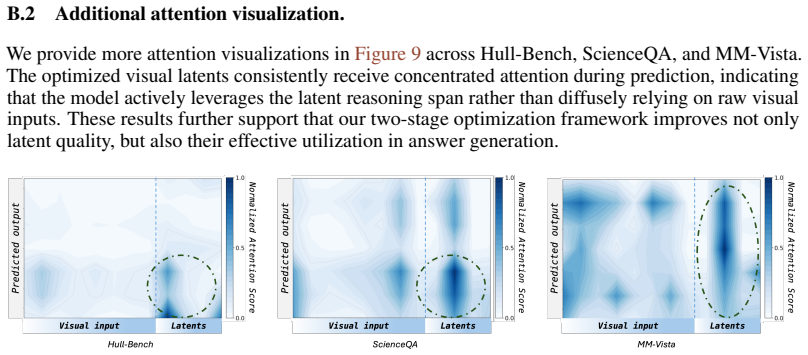
Yicheng Zou, Dongsheng Zhu, Lin Zhu, Tong Zhu, Yunhua Zhou, Peiheng Zhou, Xinyu Zhou, Dongzhan Zhou, Zhiwang Zhou, Yuhao Zhou, et al. Intern-s1-pro: Scientific multimodal foundation model at trillion scale.arXiv preprint arXiv:2603.25040, 2026. 13 A Detailed Experiments Setting A.1 Benchmarks Counting[ 8]. This benchmark evaluates the MLLM abilities in de...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.