Recognition: unknown
Neural networks as fuzzy logic formulas
Pith reviewed 2026-05-08 17:26 UTC · model grok-4.3
The pith
Rational-weight ReLU neural networks can be represented exactly as formulas in Rational Pavelka Logic and fragments of LΠ1/2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We provide fuzzy logic characterisations of rational-weight ReLU-activated neural networks via two well-established fuzzy logics: Rational Pavelka Logic RPL (and extensions thereof) and (fragments of) LΠ1/2. The activation values of the neural networks are allowed to be arbitrary real numbers. We also provide fuzzy logic characterisations of a generalised polynomial ring over Q in countably many variables where the use of the ReLU-function is permitted.
What carries the argument
Exact correspondence between ReLU network computations with rational weights and formula evaluations in Rational Pavelka Logic together with fragments of LΠ1/2.
Load-bearing premise
The weights are required to be rational numbers and the chosen logics must be expressive enough to capture every possible composition of ReLU functions exactly.
What would settle it
A concrete rational-weight ReLU network and input vector whose output value cannot be obtained as the truth value of any formula in RPL or the relevant LΠ1/2 fragment.
Figures


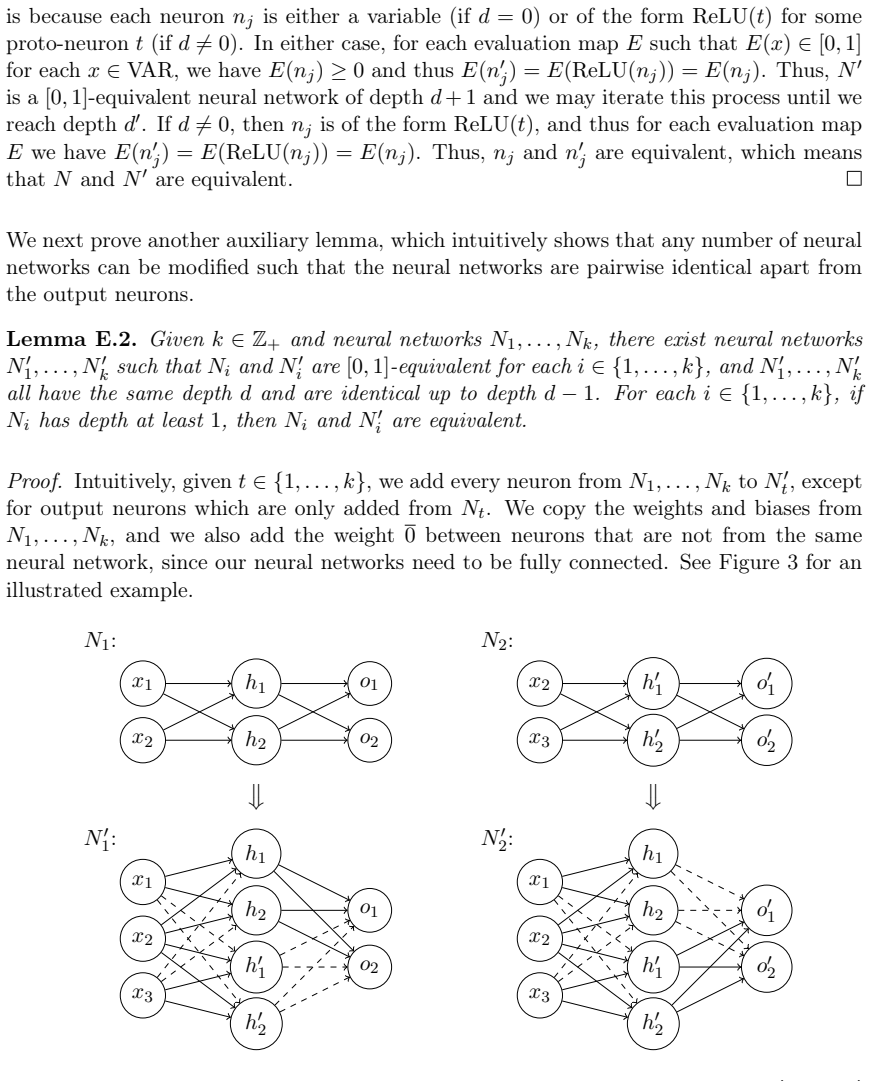
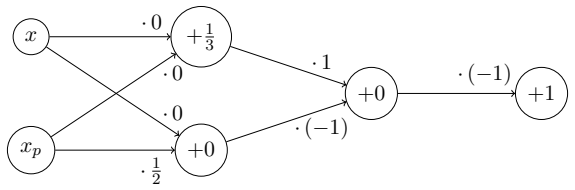

read the original abstract
Neural networks are a fundamental aspect of modern artificial intelligence, playing a key role in various important machine learning architectures including transformers and graph neural networks. Recently, logical characterisations have been used to study the expressive power of many machine learning architectures, but logical characterisations of plain neural networks have received less attention. In this paper, we provide fuzzy logic characterisations of rational-weight ReLU-activated neural networks via two well-established fuzzy logics: Rational Pavelka Logic RPL (and extensions thereof) and (fragments of) $\mathit{L \Pi} \frac{1}{2}$. The activation values of the neural networks are allowed to be arbitrary real numbers. We also provide fuzzy logic characterisations of a generalised polynomial ring over $\mathbb{Q}$ in countably many variables where the use of the ReLU-function is permitted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to provide fuzzy logic characterizations of rational-weight ReLU-activated neural networks (with arbitrary real activations) via Rational Pavelka Logic (RPL) and extensions, as well as fragments of LΠ1/2; it also claims characterizations of a generalized polynomial ring over Q in countably many variables that permits ReLU.
Significance. If the claimed exact equivalences hold, the result would link the expressive power of ReLU networks directly to established fuzzy logics, offering a logical semantics for networks with rational weights and real-valued activations. This could support formal analysis of neural network behavior beyond the unit interval.
major comments (1)
- [Abstract] Abstract: the central claim requires exact equivalence between rational-weight ReLU networks (activations in all of R) and formulas of RPL/LΠ1/2. Standard semantics for these logics are defined on [0,1] with continuous t-norms; the abstract supplies no derivation, embedding, affine rescaling, or domain extension that recovers ReLU(max(0,·)) exactly for inputs outside [0,1] while preserving rational weights and arbitrary reals. Without this mechanism the claimed characterization cannot hold.
minor comments (1)
- The abstract is terse on the technical route to the characterizations (e.g., how the polynomial ring is encoded or which fragments of LΠ1/2 are used); a short outline would improve readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting the need for greater clarity in the abstract regarding the domain extension. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim requires exact equivalence between rational-weight ReLU networks (activations in all of R) and formulas of RPL/LΠ1/2. Standard semantics for these logics are defined on [0,1] with continuous t-norms; the abstract supplies no derivation, embedding, affine rescaling, or domain extension that recovers ReLU(max(0,·)) exactly for inputs outside [0,1] while preserving rational weights and arbitrary reals. Without this mechanism the claimed characterization cannot hold.
Authors: The abstract is intentionally concise and therefore omits the technical details of the embedding. The full manuscript supplies the required mechanism: an affine rescaling that maps arbitrary real activations to the unit interval while preserving rational weights and the exact action of ReLU. This construction is introduced in Section 2.3 and used to establish the equivalence theorems in Sections 3 and 4 for both RPL and the relevant fragments of LΠ1/2. Under the rescaling, every rational-weight ReLU network computes precisely the same function as a corresponding RPL formula (and vice versa) on all of R. We will revise the abstract to include a single sentence referencing this affine embedding, thereby making the domain extension explicit without altering the length or style of the abstract. revision: partial
Circularity Check
Derivation self-contained; no reductions to inputs by construction
full rationale
The paper constructs explicit translations from rational-weight ReLU networks (with activations in ℝ) to formulas in RPL (and extensions) and fragments of LΠ1/2, then proves equivalence using the standard semantics of those logics together with the algebraic definition of ReLU. No step equates a derived quantity to a fitted parameter, renames a known result, or invokes a uniqueness theorem whose only support is a self-citation chain. The central claim therefore rests on independent semantic arguments rather than on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
VeetiAhvonen, DamianHeiman, andAnttiKuusisto. Descriptivecomplexityforneural networks via Boolean networks.Journal of Logic and Computation, 36(3):exag011, 03 2026.doi:10.1093/logcom/exag011
-
[3]
Logical Charac- terizations of Recurrent Graph Neural Networks with Reals and Floats.Advances in Neural Information Processing Systems, 37:104205–104249, 2024
Veeti Ahvonen, Damian Heiman, Antti Kuusisto, and Carsten Lutz. Logical Charac- terizations of Recurrent Graph Neural Networks with Reals and Floats.Advances in Neural Information Processing Systems, 37:104205–104249, 2024
2024
-
[4]
Neural Networks and Rational McNaughton Functions.Journal of Multiple-Valued Logic and Soft Computing, 11(1- 2):95–110, 2005
Paolo Amato, Antonio Di Nola, and Brunella Gerla. Neural Networks and Rational McNaughton Functions.Journal of Multiple-Valued Logic and Soft Computing, 11(1- 2):95–110, 2005
2005
-
[5]
Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, and Juan Pablo Silva
Pablo Barceló, Egor V. Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, and Juan Pablo Silva. The Logical Expressiveness of Graph Neural Networks. InIn- ternational conference on learning representations, 2020
2020
-
[6]
Michael Benedikt, Chia-Hsuan Lu, Boris Motik, and Tony Tan. Decidabil- ity of Graph Neural Networks via Logical Characterizations. In Karl Bring- mann, Martin Grohe, Gabriele Puppis, and Ola Svensson, editors,51st Interna- tional Colloquium on Automata, Languages, and Programming (ICALP 2024), vol- ume 297 ofLeibniz International Proceedings in Informatic...
-
[7]
The Logic of Neural Networks.Mathware and Soft Computing, 5:23–37, 1998
Juan Luis Castro and Enric Trillas. The Logic of Neural Networks.Mathware and Soft Computing, 5:23–37, 1998
1998
-
[8]
Algebraic Analysis of Many Valued Logics.Transactions of the American Mathematical society, 88(2):467–490, 1958
Chen Chung Chang. Algebraic Analysis of Many Valued Logics.Transactions of the American Mathematical society, 88(2):467–490, 1958
1958
-
[9]
Adding real coefficients to Łukasiewicz logic: An application to neural networks
Antonio Di Nola, Brunella Gerla, and Ioana Leustean. Adding real coefficients to Łukasiewicz logic: An application to neural networks. InInternational Workshop on Fuzzy Logic and Applications, pages 77–85. Springer, 2013
2013
-
[10]
Residuated fuzzy logics with an involutive negation.Archive for mathematical logic, 39(2):103–124, 2000
Francesc Esteva, Lluís Godo, Petr Hájek, and Mirko Navara. Residuated fuzzy logics with an involutive negation.Archive for mathematical logic, 39(2):103–124, 2000
2000
-
[11]
TheLΠandLΠ 1 2 logics: two complete fuzzy systems joining Łukasiewicz and Product Logics.Archive for Mathe- matical Logic, 40(1):39–67, 2001
Francesc Esteva, Lluís Godo, and Franco Montagna. TheLΠandLΠ 1 2 logics: two complete fuzzy systems joining Łukasiewicz and Product Logics.Archive for Mathe- matical Logic, 40(1):39–67, 2001
2001
-
[12]
First-ordert-normbasedfuzzylogics with truth-constants: distinguished semantics and completeness properties.Annals of Pure and Applied Logic, 161(2):185–202, 2009
FrancescEsteva, LluísGodo, andCarlesNoguera. First-ordert-normbasedfuzzylogics with truth-constants: distinguished semantics and completeness properties.Annals of Pure and Applied Logic, 161(2):185–202, 2009. 17
2009
-
[13]
The Correspon- dence Between Bounded Graph Neural Networks and Fragments of First-Order Logic
Bernardo Cuenca Grau, Eva Feng, and Przemysław Andrzej Wałęga. The Correspon- dence Between Bounded Graph Neural Networks and Fragments of First-Order Logic. Proceedings of the AAAI Conference on Artificial Intelligence, 40(23):19135–19142, Mar. 2026. URL:https://ojs.aaai.org/index.php/AAAI/article/view/38987, doi:10.1609/aaai.v40i23.38987
-
[14]
The Descriptive Complexity of Graph Neural Networks.TheoretiCS, 3, 2024
Martin Grohe. The Descriptive Complexity of Graph Neural Networks.TheoretiCS, 3, 2024
2024
-
[15]
Fuzzy logic and arithmetical hierarchy.Fuzzy sets and Systems, 73(3):359– 363, 1995
Petr Hájek. Fuzzy logic and arithmetical hierarchy.Fuzzy sets and Systems, 73(3):359– 363, 1995
1995
-
[16]
doi: 10.1007/978-94-011-5300-3
Petr Hájek.Metamathematics of Fuzzy Logic, volume 4 ofTrends in Logic. Kluwer, 1998.doi:10.1007/978-94-011-5300-3
-
[17]
Stan P Hauke and Przemysław Andrzej Wałęga. Aggregate-Combine-Readout GNNs Can Express Logical Classifiers Beyond the Logic C2.Proceedings of the AAAI Con- ference on Artificial Intelligence, 40(26):21594–21601, Mar. 2026. URL:https:// ojs.aaai.org/index.php/AAAI/article/view/39308,doi:10.1609/aaai.v40i26. 39308
-
[18]
Product Łukasiewicz Logic.Archive for Mathe- matical Logic, 43(4):477–503, 2004
Rostislav Horčík and Petr Cintula. Product Łukasiewicz Logic.Archive for Mathe- matical Logic, 43(4):477–503, 2004
2004
-
[19]
Untersuchungen über den Aussagenkalküls
Jan Łukasiewicz and Alfred Tarski. Untersuchungen über den Aussagenkalküls. Comptes rendus de la Société des Sciences et des Lettres de Varsovie, 23:1–21, 1930
1930
-
[20]
Unifying approach to uniform expressivity of graph neu- ral networks, 2026
Huan Luo and Jonni Virtema. Unifying approach to uniform expressivity of graph neu- ral networks, 2026. URL:https://arxiv.org/abs/2602.18409,arXiv:2602.18409
-
[21]
Complexity and Definability Issues in ŁΠ1 2
Enrico Marchioni and Franco Montagna. Complexity and Definability Issues in ŁΠ1 2. Journal of Logic and Computation, 17(2):311–331, 2007. URL:https://doi.org/10. 1093/logcom/exl044,doi:10.1093/LOGCOM/EXL044
-
[22]
McCulloch and Walter Pitts
Warren S. McCulloch and Walter Pitts. A logical calculus of the ideas immanent in nervous activity.The bulletin of mathematical biophysics, 5(4):115–133, 1943
1943
-
[23]
A Theorem About Infinite-Valued Sentential Logic.The Journal of Symbolic Logic, 16(1):1–13, 1951
Robert McNaughton. A Theorem About Infinite-Valued Sentential Logic.The Journal of Symbolic Logic, 16(1):1–13, 1951
1951
-
[24]
Springer Science & Business Media, 2011
DanieleMundici.Advanced Łukasiewicz calculus and MV-algebras, volume35. Springer Science & Business Media, 2011
2011
-
[25]
A Logic for Reasoning about Aggregate-Combine Graph Neural Networks
Pierre Nunn, Marco Sälzer, François Schwarzentruber, and Nicolas Troquard. A Logic for Reasoning about Aggregate-Combine Graph Neural Networks. In Kate Larson, editor,Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pages 3532–3540. International Joint Conferences on Artificial Intelligence Organization,...
-
[26]
Jan Pavelka. On Fuzzy Logic I. Many-valued rules of inference.Mathematical Logic Quarterly, 25(3-6):45–52, 1979. URL:https://doi.org/10.1002/malq.19790250304, doi:10.1002/MALQ.19790250304
-
[27]
Jan Pavelka. On Fuzzy Logic II. Enriched residuated lattices and semantics of propositional calculi.Mathematical Logic Quarterly, 25(7-12):119–134, 1979. URL: https://doi.org/10.1002/malq.19790250706,doi:10.1002/MALQ.19790250706. 18
-
[28]
Jan Pavelka. On Fuzzy Logic III. Semantical completeness of some many-valued propositional calculi.Mathematical Logic Quarterly, 25(25-29):447–464, 1979. URL: https://doi.org/10.1002/malq.19790252510,doi:10.1002/MALQ.19790252510
-
[29]
Kostylev
Maximilian Pflueger, David Tena Cucala, and Egor V. Kostylev. Recurrent Graph Neural Networks and Their Connections to Bisimulation and Logic. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14608–14616, 2024
2024
-
[30]
On Product Logic with Truth-constants.Journal of Logic and Computation, 16(2):205– 225, 2006
Petr Savický, Roberto Cignoli, Francesc Esteva, Lluís Godo, and Carles Noguera. On Product Logic with Truth-constants.Journal of Logic and Computation, 16(2):205– 225, 2006
2006
-
[31]
MoritzSchönherrandCarstenLutz. LogicalCharacterizationsofGNNswithMeanAg- gregation.Proceedings of the AAAI Conference on Artificial Intelligence, 40(30):25218– 25225, Mar. 2026. URL:https://ojs.aaai.org/index.php/AAAI/article/view/ 39713,doi:10.1609/aaai.v40i30.39713
-
[32]
Descriptive Complexity and Graph Neural Networks
Matias Selin. Descriptive Complexity and Graph Neural Networks. Master’s thesis, Tampere University, 2025. URL:https://trepo.tuni.fi/handle/10024/232168
2025
-
[33]
Przemysław Andrzej Wałęga and Bernardo Cuenca Grau. Preservation Theorems for Unravelling-Invariant Classes: A Uniform Approach for Modal Logics and Graph Neural Networks.arXiv preprint arXiv:2602.01856, 2026. A Proof of Lemma 2.3 We recall Lemma 2.3: Lemma2.3.For all termstofQ[ReLU, x i]i∈N,tis a proto-neuron if and only ifdeg(t)≤1. Proof.We prove the cl...
-
[34]
Next, we cover the case wherer= k 2j ∈]0,1[for somek, j∈Z + such thatk <2 j
Second, we define1 :=¬ L0. Next, we cover the case wherer= k 2j ∈]0,1[for somek, j∈Z + such thatk <2 j. Ifk=j= 1, thenr= 1 2, and thusr is already defined. Next, assume thatj >1and we have defined k′ 2j−1 for each k′ ∈Z + such thatk ′ <2 j−1. Ifk= 1, then we define 1 2j := 1 2j−1 ⊙ 1 2 . Next, assume thatk >1and we have defined k′ 2j for eachk ′ ∈Z + such...
-
[35]
While we already have the connectives⊕and⊙whose semantics are similar to the sum and multiplication of real numbers, this does not yet suffice for our characterisations
The goal with these auxiliary connectives is to simulate real arithmetic from some arbitrary interval[−k, k]in the interval [0,1]. While we already have the connectives⊕and⊙whose semantics are similar to the sum and multiplication of real numbers, this does not yet suffice for our characterisations. Consider for example the multiplication of two real numb...
-
[36]
Proof.We cover the case whereLisRPL(⊙)as the case whereLisLΠ 1 2 is analogous
For all valuationsV, allk∈R + and all formulae φandψofL: ifV(φ) = scale k(ℓ)andV(ψ) = scale k(ℓ′)for someℓ, ℓ ′ ∈ − k 2 , k 2 , then V(φ⊕ ′ ψ) = scalek(ℓ+ℓ ′). Proof.We cover the case whereLisRPL(⊙)as the case whereLisLΠ 1 2 is analogous. By the semantics of⊖, we haveV φ⊖ 1 4 = max n 0, V(φ)−V 1 4 o . BecauseV 1 4 = 1 4 and V(φ) = scale k(ℓ)≥scale k(− k
-
[37]
Thus, we haveV φ⊖ 1 4 =V(φ)− 1
= k− k 2 2k = 1 4 , we haveV(φ)−V 1 4 ≥ 1 4 − 1 4 = 0. Thus, we haveV φ⊖ 1 4 =V(φ)− 1
-
[38]
Now, by the semantics of⊕we haveV(φ⊕′ ψ) = min n 1, V φ⊖ 1 4 +V ψ⊖ 1 4 o
Analogously, we see thatV ψ⊖ 1 4 =V(ψ)− 1 4. Now, by the semantics of⊕we haveV(φ⊕′ ψ) = min n 1, V φ⊖ 1 4 +V ψ⊖ 1 4 o . By the above, we haveV φ⊖ 1 4 +V ψ⊖ 1 4 = V(φ)− 1 4 + V(ψ)− 1 4 =V(φ) +V(ψ)− 1 2, which impliesV(φ⊕ ′ ψ) = min 1, V(φ) +V(ψ)− 1 2 . Becauseℓ, ℓ ′ ≤ k 2, we have V(φ), V(ψ)≤scale k k 2 = k+ k 2 2k = 3 4 , which means that V(φ) +V(ψ)− 1 2 ...
-
[39]
ThenV( J′ n φ) = scalek(nℓ)
Letn∈N,k∈R +, letVbe a valuation andφa formula ofLsuch thatV(φ) = scale k(ℓ)for someℓ∈ − k 2j , k 2j wherej∈Nis the smallest integer such thatn≤2 j. ThenV( J′ n φ) = scalek(nℓ). Proof.We prove the claim by induction overn. Ifn= 0, then J′ 0 φ= 1 2 and therefore V(J′ 0 φ) = 1 2 = scalek(0ℓ). Ifn= 1, then J′ 1 φ=φandV( J′ 1 φ) =V(φ) = scale k(1ℓ). Next, ass...
-
[40]
Proof.We show the case whereLisRPL(⊙)as the case whereLisLΠ 1 2 is analogous
For all integersk≥8, valuationsVand formulae φandψofL: ifV(φ) = scale k(ℓ)andV(ψ) = scale k(ℓ′)for someℓ, ℓ ′ ∈ − √ k, √ k , then V(φ⊙ k ψ) = scalek(ℓℓ′). Proof.We show the case whereLisRPL(⊙)as the case whereLisLΠ 1 2 is analogous. For convenience, we letθleft := J 2(φ⊙ψ)⊕ 1 2k andθ right :=φ⊕ ′ ψ. This means that φ⊙k ψ= J k(θleft⊖θright). We start by ca...
-
[41]
Becausemax{a, b}+c= max{a+c, b+c}for alla, b, c∈R, we get V(φ s) = min 1,max 1 2 , V(φ t′)
By the semantics of⊕,⊖and 1 2, we have V(φ s) =V φt′ ⊖ 1 2 ⊕ 1 2 = min n 1, V φt′ ⊖ 1 2 + 1 2 o = min 1,max 0, V(φ t′)− 1 2 + 1 2 . Becausemax{a, b}+c= max{a+c, b+c}for alla, b, c∈R, we get V(φ s) = min 1,max 1 2 , V(φ t′) . By the induction hypothesis, we haveV(φt′) = scalek(E(t′))and thus V(φ s)= min 1,max 1 2 ,scale k(E(t′)) . There are two cases to ex...
-
[42]
IfE(t ′)<0, thenscale k(E(t′))< 1 2 and thusmax 1 2 ,scale k(E(t′)) = 1 2 and V(φ s) = min 1, 1 2 = 1
-
[43]
BecauseE(t ′)<0, we haveE(s) =E(ReLU(t ′)) = 0, which finally gives us V(φ s) = scalek(E(s))
Because 1 2 = scale k(0), we haveV(φ s) = scale k(0). BecauseE(t ′)<0, we haveE(s) =E(ReLU(t ′)) = 0, which finally gives us V(φ s) = scalek(E(s)). 25
-
[44]
For alld∈N, if deg(t)≤d, thenφ t is a formula ofL ≤d
IfE(t ′)≥0, thenscale k(E(t′))≥ 1 2 andmax 1 2 ,scale k(E(t′)) = scalek(E(t′)), and thusV(φ s) = min{1,scale k(E(t′))}. BecauseE(t ′)∈[−k, k], we know that scalek(E(t′))∈[0,1], which means thatmin{1,scale k(E(t′))}= scale k(E(t′)) and thusV(φ s) = scale k(E(t′)). Furhtermore, becauseE(t ′)≥0, we have E(s) =E(ReLU(t ′)) =E(t ′)and thereforeV(φ s) = scalek(...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.