Recognition: 2 theorem links
· Lean TheoremAdaptive Data Compression and Reconstruction for Memory-Bounded EEG Continual Learning
Pith reviewed 2026-05-08 18:31 UTC · model grok-4.3
The pith
A morphology-aware compression pipeline lets EEG models adapt to new subjects with far less memory than storing full samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
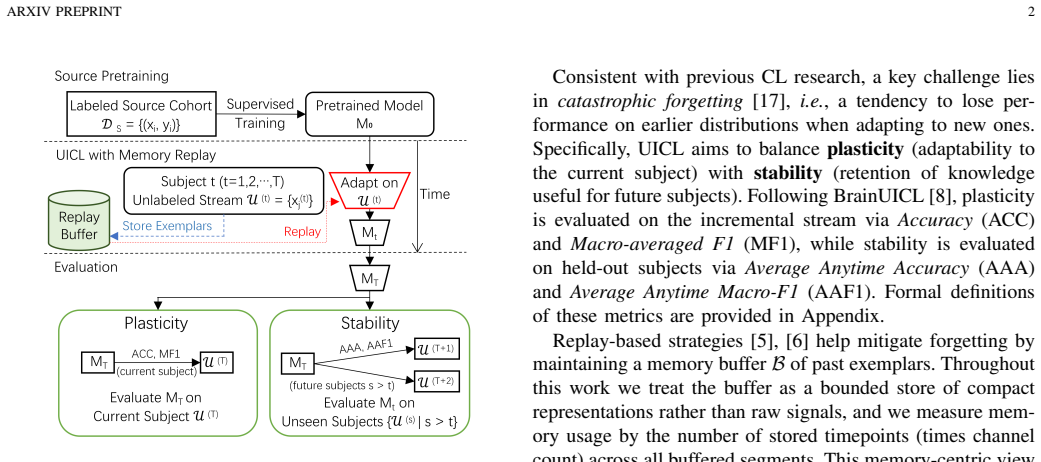
ADaCoRe is a memory-efficient pipeline for unsupervised individual continual learning that performs saliency-driven keyframe protection, rational polyphase compression, adjoint reconstruction with verbatim overwrite on protected indices, and prototype-confidence selection for adaptive exemplar maintenance. Across three representative benchmarks the method consistently outperforms recent strong baselines when buffer capacity is tightly constrained, delivering accuracy gains of at least 2.7 points on ISRUC and 15.3 points on FACED.
What carries the argument
The ADaCoRe pipeline, which combines saliency-driven keyframe protection with rational polyphase compression and adjoint reconstruction to preserve EEG morphology while reducing stored data volume.
If this is right
- Models can maintain higher accuracy while using substantially smaller replay buffers than methods that store complete past samples.
- Key morphological features of EEG waveforms survive the compression-reconstruction cycle, as confirmed by the reported visualizations.
- Each pipeline stage contributes measurably, according to the ablation results on compression-fidelity trade-offs.
- The same compression strategy supports online adaptation to new unlabeled subjects without violating memory limits.
Where Pith is reading between the lines
- The same selective-compression logic could be tested on other physiological time series that exhibit repeatable morphological patterns.
- Reducing stored sample size may also lower the computational cost of replay during adaptation, an effect not quantified in the current experiments.
- The approach suggests a general design pattern for continual learning on any data modality where structure can be exploited for lossy but task-preserving compression.
Load-bearing premise
EEG signals contain well-structured morphologies that can be identified, compressed, and reconstructed without discarding information essential to the continual-learning task.
What would settle it
Running the same tight-buffer protocol on a collection of highly irregular or unstructured EEG recordings where the morphology-aware steps no longer preserve task-relevant features would show whether accuracy gains disappear or reverse.
Figures




read the original abstract
Electroencephalography (EEG) signals provide millisecond-level temporal resolution but their analysis is limited by remarkable noise and inter-subject variability, making robust personalization difficult under limited annotations. Unsupervised Individual Continual Learning (UICL) has been proposed to address this practical challenge, where a model pretrained on a labeled cohort must adapt online to unlabeled subject streams under strict memory constraints. However, existing UICL methods typically store full past samples, which undermine the continual learning goal of avoiding retraining. Observing that EEG signals exhibit well-structured morphologies to be exploited via morphology-aware selection, compression, and reconstruction, here we propose Adaptive Data Compression and Reconstruction (ADaCoRe) for UICL. This is a memory-efficient pipeline composed of saliency-driven keyframe protection, rational polyphase compression, adjoint reconstruction with verbatim overwrite on protected indices, and prototype-confidence selection for adaptive exemplar maintenance. Across three representative benchmarks, ADaCoRe consistently outperforms recent strong baselines under tight buffer regimes (eg., the performance gains are at least +2.7 and +15.3 ACC on ISRUC and FACED datasets, respectively). Ablation studies quantify compression-fidelity trade-offs and highlight the contribution of each design, while visualizations confirm the preservation of key EEG morphology during compression and reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Adaptive Data Compression and Reconstruction (ADaCoRe), a memory-efficient pipeline for unsupervised individual continual learning (UICL) on EEG signals. It combines saliency-driven keyframe protection, rational polyphase compression, adjoint reconstruction with verbatim overwrite on protected indices, and prototype-confidence selection for exemplar maintenance. The central claim is that this approach exploits well-structured EEG morphologies to store more exemplars under tight buffer constraints without losing task-critical information, leading to consistent outperformance over recent baselines on three benchmarks (e.g., gains of at least +2.7 ACC on ISRUC and +15.3 on FACED), supported by ablation studies on compression-fidelity trade-offs and visualizations of morphology preservation.
Significance. If the empirical claims hold, the work addresses a practical bottleneck in deploying continual learning for EEG personalization under memory limits and limited annotations, potentially enabling more robust online adaptation in noisy, variable signals. The morphology-aware design and explicit ablations quantifying each component's contribution represent strengths that could inform similar compression strategies in other time-series continual learning settings. The paper provides reproducible empirical validation on external benchmarks and highlights design contributions via ablations and visualizations.
major comments (2)
- [Ablation studies and results sections] Ablation studies and results sections: The central claim that saliency-protected keyframes, rational polyphase compression, and adjoint reconstruction preserve task-critical EEG morphology relies on visualizations and compression-fidelity ablations, but lacks a direct quantitative metric (e.g., class-conditional feature distance between original and reconstructed streams, or accuracy of a frozen classifier trained on originals vs. reconstructions). This is load-bearing for the memory-efficiency premise, as the method deliberately discards information to increase exemplar count; without such a metric, reported ACC gains could arise from unquantified distortions amplified by the prototype-confidence selector.
- [Method pipeline description] Method pipeline description: The adjoint reconstruction with verbatim overwrite on protected indices is presented as preserving key features, yet no formal bound or analysis is given on reconstruction error relative to the downstream UICL model's feature space or decision boundaries. This omission weakens the justification for why the approach retains information critical to online adaptation under the reported tight buffer regimes.
minor comments (2)
- [Abstract] Abstract: The reported performance gains ('at least +2.7 and +15.3 ACC') would be clearer if the exact values, corresponding baselines, and buffer sizes were specified for each dataset rather than using 'eg.'
- [Results] Results: The manuscript mentions 'three representative benchmarks' but does not explicitly list all three or provide full baseline specifications and statistical test details (e.g., number of runs, significance tests) to support the 'consistent outperformance' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the quantitative support for morphology preservation in ADaCoRe. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: Ablation studies and results sections: The central claim that saliency-protected keyframes, rational polyphase compression, and adjoint reconstruction preserve task-critical EEG morphology relies on visualizations and compression-fidelity ablations, but lacks a direct quantitative metric (e.g., class-conditional feature distance between original and reconstructed streams, or accuracy of a frozen classifier trained on originals vs. reconstructions). This is load-bearing for the memory-efficiency premise, as the method deliberately discards information to increase exemplar count; without such a metric, reported ACC gains could arise from unquantified distortions amplified by the prototype-confidence selector.
Authors: We agree that a direct metric such as frozen-classifier accuracy on original versus reconstructed streams would more rigorously quantify preservation of task-critical information. Our current ablations already report compression-fidelity trade-offs via downstream UICL performance, and visualizations demonstrate morphology retention, but these are indirect. To address the concern, we will add an explicit experiment measuring a frozen pre-trained classifier's accuracy on reconstructed signals in the revised results and ablation sections. This will help confirm that ACC gains arise from retained information rather than selector-amplified artifacts. revision: yes
-
Referee: Method pipeline description: The adjoint reconstruction with verbatim overwrite on protected indices is presented as preserving key features, yet no formal bound or analysis is given on reconstruction error relative to the downstream UICL model's feature space or decision boundaries. This omission weakens the justification for why the approach retains information critical to online adaptation under the reported tight buffer regimes.
Authors: A formal mathematical bound on reconstruction error in the UICL feature space is difficult to derive given the non-linear model and data-adaptive compression. We therefore rely on empirical validation. In the revision we will add quantitative analysis of embedding-space distances (e.g., cosine distance in the UICL feature extractor) between original and reconstructed streams, together with per-class error statistics, to better link reconstruction fidelity to the model's decision boundaries under the reported buffer constraints. revision: partial
Circularity Check
No significant circularity; empirical pipeline with external validation
full rationale
The paper presents ADaCoRe as an algorithmic pipeline (saliency-driven keyframe protection, rational polyphase compression, adjoint reconstruction with verbatim overwrite, prototype-confidence selection) motivated by the observation of EEG morphologies. Central claims consist of empirical outperformance on external benchmarks (ISRUC, FACED) under tight buffers, supported by ablations and visualizations. No equations, fitted parameters, or self-citations are shown that reduce the reported ACC gains to quantities defined by construction within the work. The derivation chain remains self-contained against external data and does not collapse to tautological inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption EEG signals exhibit well-structured morphologies to be exploited via morphology-aware selection, compression, and reconstruction
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J-cost calibration)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
τ = Med(S) + κ·1.4826·MAD(S), with κ ∈ [2,3]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
At home eeg monitoring technologies for people with epilepsy and intellectual disabilities: A scoping review,
M. Milne-Ives, J. Duun-Henriksen, L. Blaabjerg, B. Mclean, R. Shankar, and E. Meinert, “At home eeg monitoring technologies for people with epilepsy and intellectual disabilities: A scoping review,”Seizure, vol. 110, pp. 11–20, 2023
2023
-
[2]
Ultra-long-term subcutaneous home mon- itoring of epilepsy—490 days of eeg from nine patients,
S. Weisdorf, J. Duun-Henriksen, M. J. Kjeldsen, F. R. Poulsen, S. W. Gangstad, and T. W. Kjær, “Ultra-long-term subcutaneous home mon- itoring of epilepsy—490 days of eeg from nine patients,”Epilepsia, vol. 60, no. 11, pp. 2204–2214, 2019
2019
-
[3]
Eeg-based brain–computer inter- faces,
D. J. McFarland and J. R. Wolpaw, “Eeg-based brain–computer inter- faces,”Current Opinion in Biomedical Engineering, vol. 4, pp. 194–200, 2017
2017
-
[4]
U-time: A fully convolutional network for time series segmentation applied to sleep staging,
M. Perslev, M. Jensen, S. Darkner, P. J. r. Jennum, and C. Igel, “U-time: A fully convolutional network for time series segmentation applied to sleep staging,” inNeurIPS, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019. [Online]. Available: https://proceedings.neurips.cc/pap...
2019
-
[5]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inCVPR, 2017, pp. 2001–2010
2017
-
[6]
Gradient episodic memory for continual learning,
D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for continual learning,” inNeurIPS, vol. 30, 2017
2017
-
[7]
AASM, 2007
American Academy of Sleep Medicine,The AASM Manual for the Scor- ing of Sleep and Associated Events: Rules, Terminology and Technical Specifications. AASM, 2007
2007
-
[8]
BrainUICL: An unsupervised individual continual learning framework for EEG applications,
Y . Zhou, S. Zhao, J. Wang, H. Jiang, S. Li, T. Li, and G. Pan, “BrainUICL: An unsupervised individual continual learning framework for EEG applications,” inICLR, 2025. [Online]. Available: https://openreview.net/forum?id=6jjAYmppGQ
2025
-
[9]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska- Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,”PNAS, vol. 114, no. 13, pp. 3521–3526, 2017. [Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas.1611835114
-
[10]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inICML, 2017, pp. 3987–3995
2017
-
[11]
Learning without forgetting,
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE TPAMI, vol. 40, no. 12, pp. 2935–2947, 2018
2018
-
[12]
Deep Domain Confusion: Maximizing for Domain Invariance
E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell, “Deep domain confusion: Maximizing for domain invariance,” 2014, arXiv:1412.3474 [cs.CV]
work page Pith review arXiv 2014
-
[13]
Unsupervised domain adaptation by backpropagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by backpropagation,” inICML, vol. 37, 2015, pp. 1180–1189
2015
-
[14]
Continual test-time domain adaptation,
Q. Wang, O. Fink, L. Van Gool, and D. Dai, “Continual test-time domain adaptation,” inCVPR, 2022, pp. 7201–7211
2022
-
[15]
Bci2000: A general-purpose brain-computer interface (bci) system,
G. Schalk, D. J. McFarland, T. Hinterberger, N. Birbaumer, and J. R. Wolpaw, “Bci2000: A general-purpose brain-computer interface (bci) system,”IEEE TBE, vol. 51, no. 6, pp. 1034–1043, 2004
2004
-
[16]
Time-series representation learning via temporal and contextual con- trasting,
E. Eldele, M. Ragab, Z. Chen, M. Wu, C. K. Kwoh, X. Li, and C. Guan, “Time-series representation learning via temporal and contextual con- trasting,” inIJCAI, 2021, pp. 2352–2359
2021
-
[17]
The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects,
M. Mermillod, A. Bugaiska, and P. Bonin, “The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects,”Frontiers in Psychology, vol. 4, p. 54654, 2013
2013
-
[18]
Representation learning with contrastive predictive coding,
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” 2018
2018
-
[19]
Oppenheim, R
A. Oppenheim, R. Schafer, and J. Buck,Discrete-time Signal Processing, ser. Prentice Hall International Editions Series. Prentice Hall, 1999. [Online]. Available: https://books.google.co.jp/books?id= cR3CQgAACAAJ
1999
-
[20]
Teager–kaiser energy methods for signal and image analysis: A review,
A. Boudraa and F. Salzenstein, “Teager–kaiser energy methods for signal and image analysis: A review,”Digital Signal Processing, vol. 78, pp. 338–375, 2018
2018
-
[21]
Alternatives to the median absolute deviation,
P. J. Rousseeuw and C. Croux, “Alternatives to the median absolute deviation,”JASA, vol. 88, no. 424, pp. 1273–1283, 1993. [Online]. Available: http://www.jstor.org/stable/2291267
-
[22]
Energy separation in signal modulations with application to speech analysis,
P. Maragos, J. Kaiser, and T. Quatieri, “Energy separation in signal modulations with application to speech analysis,”IEEE TSP, vol. 41, no. 10, pp. 3024–3051, 1993
1993
-
[23]
On amplitude and frequency demodulation using energy opera- tors,
——, “On amplitude and frequency demodulation using energy opera- tors,”IEEE TSP, vol. 41, no. 4, pp. 1532–1550, 1993
1993
-
[24]
Isruc-sleep: A comprehensive public dataset for sleep researchers,
S. Khalighi, T. Sousa, J. M. Santos, and U. Nunes, “Isruc-sleep: A comprehensive public dataset for sleep researchers,”Computer Methods and Programs in Biomedicine, vol. 124, pp. 180–192, 2016. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0169260715002734
2016
-
[25]
A large finer-grained affective computing eeg dataset,
J. Chen, X. Wang, C. Huang, X. Hu, X. Shen, and D. Zhang, “A large finer-grained affective computing eeg dataset,”Scientific Data, vol. 10, no. 1, p. 740, 2023
2023
-
[26]
A kernel method for the two-sample-problem,
A. Gretton, K. Borgwardt, M. Rasch, B. Sch ¨olkopf, and A. Smola, “A kernel method for the two-sample-problem,” inNeurIPS, B. Sch ¨olkopf, J. Platt, and T. Hoffman, Eds., vol. 19. MIT Press, 2006. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2006/file/e9fb2eda3d9c55a0d89c98d6c54b5b3e-Paper.pdf
2006
-
[27]
Unsupervised continual learning for gradually varying domains,
A. M. N. Taufique, C. S. Jahan, and A. Savakis, “Unsupervised continual learning for gradually varying domains,” inCVPRW, 2022, pp. 3739– 3749
2022
-
[28]
Conda: Continual unsupervised domain adaptation,
——, “Conda: Continual unsupervised domain adaptation,”arXiv preprint arXiv:2103.11056, 2021
-
[29]
Replay with stochastic neural transformation for online continual eeg classifi- cation,
T. Duan, Z. Wang, G. Doretto, F. Li, C. Tao, and D. Adjeroh, “Replay with stochastic neural transformation for online continual eeg classifi- cation,” inBIBM, 2023, pp. 1874–1879
2023
-
[30]
Nonrecursive digital filter design usingI 0-sinh window function,
J. F. Kaiser, “Nonrecursive digital filter design usingI 0-sinh window function,” inProc. IEEE Int. Symp. Circuits and Systems (ISCAS’74), 1974, pp. 20–23
1974
-
[31]
Crochiere and L
R. Crochiere and L. Rabiner,Multirate Digital Signal Processing, ser. Prentice-Hall Signal Processing Series: Advanced monographs. Prentice-Hall, 1983. [Online]. Available: https://books.google.co.jp/ books?id=X NSAAAAMAAJ ARXIV PREPRINT 8 APPENDIXA SIGNALPROCESSINGDETAILS This supplement details the discrete-time model and signal- processing operators th...
1983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.