Recognition: 2 theorem links
· Lean TheoremPairwise matrices for sparse autoencoders: single-feature inspection mislabels causal axes
Pith reviewed 2026-05-08 18:46 UTC · model grok-4.3
The pith
Single-feature inspection of sparse autoencoder features mislabels the causal axes they steer in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
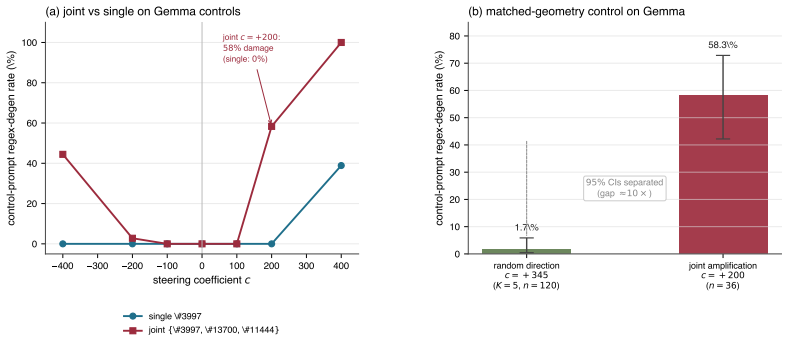
The paper claims that single-feature inspection mislabels causal axes because joint suppression of three near-orthogonal cluster-specific features at c=-500 damages grounded composition on recipes and engine explanations as well as introspective prompts, while single-feature suppression at the same magnitude leaves controls intact. A feature labeled AI self-disclaimer produces an inverted U-shape under coefficient sweep, substituting a contemplative-philosopher voice at c=+500. Matched-geometry comparisons of single-feature, joint, and random-direction perturbations of norm ~1.55 and cosine ~0.64 produce three distinct output regimes, with coherence loss depending on direction pattern rather
What carries the argument
The pairwise matrix protocol, which co-varies the steering coefficient with the joint condition across multiple features to expose interaction effects missed by one-at-a-time tests.
If this is right
- Joint suppression can produce placeholder text and coherence loss where single-feature suppression substitutes only strategy filler.
- The protocol identifies a top causally responsible feature in Llama-3.1-8B-Instruct in addition to the Qwen and Gemma results.
- Coherence loss under steering is direction-pattern-dependent rather than magnitude-dependent.
- All three findings reproduce on Gemma-2-2B-it with model-specific damage signatures and CI separation of ~10x on the matched-geometry control.
Where Pith is reading between the lines
- This approach could be extended to test whether other common SAE features in safety or capability editing also show hidden joint effects that single steering misses.
- It suggests that feature editing pipelines may need to include pairwise or higher-order checks to avoid side effects on unrelated tasks.
- Neighbouring interpretability methods that rely on feature isolation might similarly benefit from systematic joint perturbation tests.
Load-bearing premise
That observed differences in output regimes between single-feature, joint, and random-direction perturbations of matched norm and cosine similarity are caused by mislabeled causal axes rather than other uncontrolled factors in the steering process or model-specific artifacts.
What would settle it
If joint suppression of the three features at c=-500 produces no greater damage to grounded composition than single-feature suppression of matched magnitude, or if the three perturbation regimes collapse to identical outputs under the matched-geometry controls.
Figures

read the original abstract
The standard sparse-autoencoder (SAE) interpretability protocol labels each feature from its top-activating contexts and validates by single-feature steering. We propose the pairwise matrix protocol, co-varying steering coefficient with joint condition, and report three findings the standard one-corner protocol misses on Qwen3-1.7B-Instruct, replicated on Gemma-2-2B-it. First, a feature labelled "AI self-disclaimer" from its top contexts produces an inverted U-shape under a coefficient sweep: at c=+500 the model substitutes a fluent contemplative-philosopher voice for the disclaimer. Two further features anchor the criterion (one monotonic, one pure breakdown). Second, three near-orthogonal cluster-specific features that individually steer a philosophy-of-mind register, jointly suppressed at c=-500, damage grounded composition on recipes and engine explanations as well as introspective prompts; single-feature suppression at the same magnitude leaves controls intact. Third, a matched-geometry comparison of single-feature, joint, and random-direction perturbations (norm ~1.55, cosine ~0.64) yields three distinct output regimes: single-feature substitutes strategy filler, random direction substitutes diverse content, joint suppression alone produces placeholder text. Coherence loss is direction-pattern-dependent, not magnitude-dependent. All three findings reproduce on Gemma with model-specific damage signatures; the matched-geometry control is CI-separated by ~10x. The pipeline also locates a top causally responsible feature in Llama-3.1-8B-Instruct.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a pairwise matrix protocol for sparse autoencoders that co-varies steering coefficients with joint feature conditions. It claims that single-feature inspection mislabels causal axes, as shown by three findings replicated on Qwen3-1.7B-Instruct and Gemma-2-2B-it: an inverted U-shape under coefficient sweep for a feature labeled 'AI self-disclaimer'; joint suppression at c=-500 of three near-orthogonal cluster-specific features damaging grounded composition on recipes, engine explanations, and introspective prompts while single-feature suppression at the same magnitude leaves controls intact; and distinct output regimes (single-feature substitutes strategy filler, random direction substitutes diverse content, joint produces placeholder text) in a matched-geometry comparison (norm ~1.55, cosine ~0.64) where coherence loss is direction-pattern-dependent rather than magnitude-dependent. A pipeline also identifies a top causally responsible feature in Llama-3.1-8B-Instruct.
Significance. If the results hold, this work is significant for mechanistic interpretability because it provides concrete evidence that standard top-context labeling plus single-feature steering can miss causal structure, and it demonstrates the utility of joint analysis via explicit controls (random directions, single vs. joint, coefficient sweeps) and cross-model replication with CI separation by ~10x on the matched-geometry control. The direction-pattern dependence of coherence loss offers a falsifiable distinction that could improve steering experiment design.
major comments (2)
- [matched-geometry comparison] The central claim that distinct output regimes demonstrate mislabeling of causal axes rests on the matched-geometry comparison of single-feature, joint, and random-direction perturbations. This control matches only first-order geometry (norm ~1.55, cosine ~0.64) but does not report higher-order statistics of the joint vector or test survival of the effect under a different SAE dictionary on the same model, so the observed differences could arise from SAE-model interactions or residual correlations rather than mislabeled axes.
- [Abstract and replication statements] The abstract states that replication across Qwen3-1.7B-Instruct and Gemma-2-2B-it plus a pipeline result on Llama-3.1-8B-Instruct shows CI separation on the matched-geometry control, yet no methods, data, error bars, or exclusion criteria are visible. This absence is load-bearing for evaluating whether the three findings (inverted U-shape, joint-damage effect, and regime separation) are robust.
minor comments (1)
- [Abstract] The exact construction of the 'pairwise matrices' (how coefficients are co-varied with joint conditions) is referenced but not formalized in the abstract, which may hinder immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for strengthening the evidence on the limitations of single-feature SAE inspection. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [matched-geometry comparison] The central claim that distinct output regimes demonstrate mislabeling of causal axes rests on the matched-geometry comparison of single-feature, joint, and random-direction perturbations. This control matches only first-order geometry (norm ~1.55, cosine ~0.64) but does not report higher-order statistics of the joint vector or test survival of the effect under a different SAE dictionary on the same model, so the observed differences could arise from SAE-model interactions or residual correlations rather than mislabeled axes.
Authors: We agree that matching only first-order geometry leaves room for alternative explanations such as residual correlations or SAE-specific interactions. However, the observed regimes are qualitatively distinct (strategy-filler substitution for single-feature, diverse content for random, placeholder text for joint) and the coherence loss is explicitly pattern-dependent rather than magnitude-dependent, which is harder to attribute to first-order residuals alone. The ~10x CI separation on the matched-geometry control and replication on Gemma-2-2B-it (different model and SAE) provide additional support. We will add higher-order statistics of the joint vector (e.g., kurtosis, pairwise feature correlations within the cluster) and a limitations paragraph discussing the absence of a same-model different-SAE test. We did not perform the latter because our design prioritized cross-model replication. revision: partial
-
Referee: [Abstract and replication statements] The abstract states that replication across Qwen3-1.7B-Instruct and Gemma-2-2B-it plus a pipeline result on Llama-3.1-8B-Instruct shows CI separation on the matched-geometry control, yet no methods, data, error bars, or exclusion criteria are visible. This absence is load-bearing for evaluating whether the three findings (inverted U-shape, joint-damage effect, and regime separation) are robust.
Authors: We accept that the current manuscript does not make the replication methods, raw data summaries, error bars, and exclusion criteria sufficiently explicit. The abstract condenses results that appear in the main text and figures, but we will expand the Methods section with a dedicated replication subsection, include tables reporting per-model CI values and sample sizes, specify exclusion criteria for prompt sets, and add error bars to all relevant plots. The Llama pipeline will also receive expanded description. These changes will be incorporated in the revision. revision: yes
Circularity Check
No significant circularity: empirical protocol with independent controls
full rationale
The paper reports direct experimental measurements of steering effects under single-feature, joint, and random-direction perturbations on Qwen3-1.7B-Instruct (replicated on Gemma-2-2B-it and Llama-3.1-8B-Instruct). All load-bearing claims rest on observed output regime differences at matched norm ~1.55 and cosine ~0.64, with CI separation and coefficient sweeps. No equations, fitted parameters, or self-citations are invoked to derive the reported effects; the pairwise matrix protocol is presented as a new measurement procedure whose results are compared against explicit controls rather than reduced to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation steering with scalar coefficients on SAE features produces measurable and interpretable changes in model output.
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J-cost) / Constants (φ-ladder)washburn_uniqueness_aczel unclearmatched-geometry random-direction control (norm ≈1.55, cosine ≈0.64)
Reference graph
Works this paper leans on
-
[1]
Language models as agent models
Jacob Andreas. Language models as agent models. InFindings of the Association for Computational Linguistics: EMNLP 2022,
2022
-
[2]
Language models as agent models
URLhttps://arxiv.org/abs/2212.01681. Anthropic. Claude’s character. Anthropic research blog,
-
[4]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
URLhttps://arxiv.org/abs/2507.21509. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review arXiv
-
[5]
URLhttps://arxiv.org/abs/2309.08600. Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposi- tion. Transformer Circuits Thread,
-
[6]
Representation Engineering: A Top-Down Approach to AI Transparency
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023. URL https://arxiv.org/abs/2310. 01405. A Detailed tables for §4–5 coef−1500−1000−500 0 +500 +1000 cluster on intros (n=36) 0 % 0...
work page internal anchor Pith review arXiv 2023
-
[7]
Scaling and evaluating sparse autoencoders
URLhttps://arxiv.org/abs/2406.04093. Goodfire AI. Understanding and steering Llama 3 with sparse autoencoders. Goodfire research blog,
work page internal anchor Pith review arXiv
-
[9]
Stefan Heimersheim and Neel Nanda
URLhttps://arxiv.org/abs/2410.20526. Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems,
-
[10]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , shorttitle =
URLhttps://arxiv.org/abs/2306.03341. Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on Gemma 2.arXiv preprint arXiv:2408.05147,
-
[11]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on
URL https://arxiv.org/abs/2408.05147. Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InProceedings of the 41st International Conference on Machine Learning,
-
[12]
URLhttps://arxiv.org/abs/2311.03658. Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, Andy Jones, Anna Chen, Ben Mann, Brian Israel, Bryan Seethor, Cameron McKinnon, Christopher Olah, Da Yan, Daniela Amodei, Dario Amodei, Dawn Drain, Dustin Li, Eli Tran-Joh...
work page internal anchor Pith review arXiv
-
[13]
arXiv preprint arXiv:2212.09251 , year =
URL https://arxiv.org/ abs/2212.09251. Qwen Team. Qwen-Scope: Open-source sparse autoencoders for the Qwen3 and Qwen3.5 families. Hugging Face model collection,
-
[14]
URL https://aclanthology.org/2024.acl-long.828/
Association for Computational Linguistics. URL https://aclanthology.org/2024.acl-long.828/. Nishant Subramani, Nivedita Suresh, and Matthew E. Peters. Extracting latent steering vectors from pretrained language models. InFindings of the Association for Computational Linguistics: ACL 2022,
2024
-
[15]
arXiv preprint arXiv:2205.05124 , year=
URLhttps://arxiv.org/abs/2205.05124. Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L. Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tristan Hume, Francesco Mosconi, C. Daniel Freeman, Theodore R. Sumers, Edw...
-
[17]
Steering Language Models With Activation Engineering
URLhttps://arxiv.org/abs/2308.10248. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation ...
work page internal anchor Pith review arXiv
-
[18]
TIGHTER TAN (TIGHTER TAN)
Table 7: Rate on introspective prompts, Qwen3-1.7B-Base (raw prompts) versus Qwen3-1.7B-Instruct (chat-formatted prompts). The philosophy-of-mind lemmas are below the ∼9% noise floor in the base; after post-training they reach 25–34%. The broader meta-cognitive lemmas are present at 15–16%in the base, consistent with post-training amplifying rather than i...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.