Recognition: unknown
Learning Dynamics of Zeroth-Order Optimization: A Kernel Perspective
Pith reviewed 2026-05-07 17:26 UTC · model grok-4.3
The pith
Zeroth-order SGD produces an empirical neural tangent kernel whose approximation error depends on output dimension and perturbation count rather than parameter count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive the one-step learning dynamics of ZO SGD, where the empirical Neural Tangent Kernel emerges naturally as the key term. Inspection shows that each element of the ZO eNTK is the inner product of neural tangent vectors projected onto a random low-dimensional subspace. Invoking the Johnson-Lindenstrauss Lemma establishes that the fidelity of this approximation is governed primarily by the number of perturbations, with the error depending on model output size rather than parameter dimension. This dimension-free property supplies a theoretical account for the observed success of ZO methods on LLM fine-tuning.
What carries the argument
The zeroth-order empirical neural tangent kernel (ZO eNTK), formed by inner products of neural tangent vectors after random projection via the perturbation directions, which directly controls the one-step parameter update in ZO SGD.
If this is right
- ZO optimization can scale to models with arbitrarily many parameters without incurring the classical dimension-dependent slowdown.
- The accuracy of the kernel approximation improves directly with the number of perturbations, independent of model width.
- The error bound depends on output dimension, so ZO methods remain practical even when the parameter space is enormous.
- The same kernel perspective can be used to analyze other zeroth-order variants or to compare them with first-order methods.
Where Pith is reading between the lines
- If the one-step picture extends to many steps, ZO fine-tuning should produce similar feature evolution to first-order training in wide networks.
- Perturbation distributions other than the standard Gaussian could be tuned to reduce the number of samples needed while preserving the same JL guarantee.
- Direct numerical checks of the projected tangent vectors on moderate-sized models would provide an immediate empirical test of the derived bound.
Load-bearing premise
The analysis assumes the one-step dynamics capture the dominant learning behavior and that the network is wide enough for the empirical neural tangent kernel to remain a faithful descriptor throughout training.
What would settle it
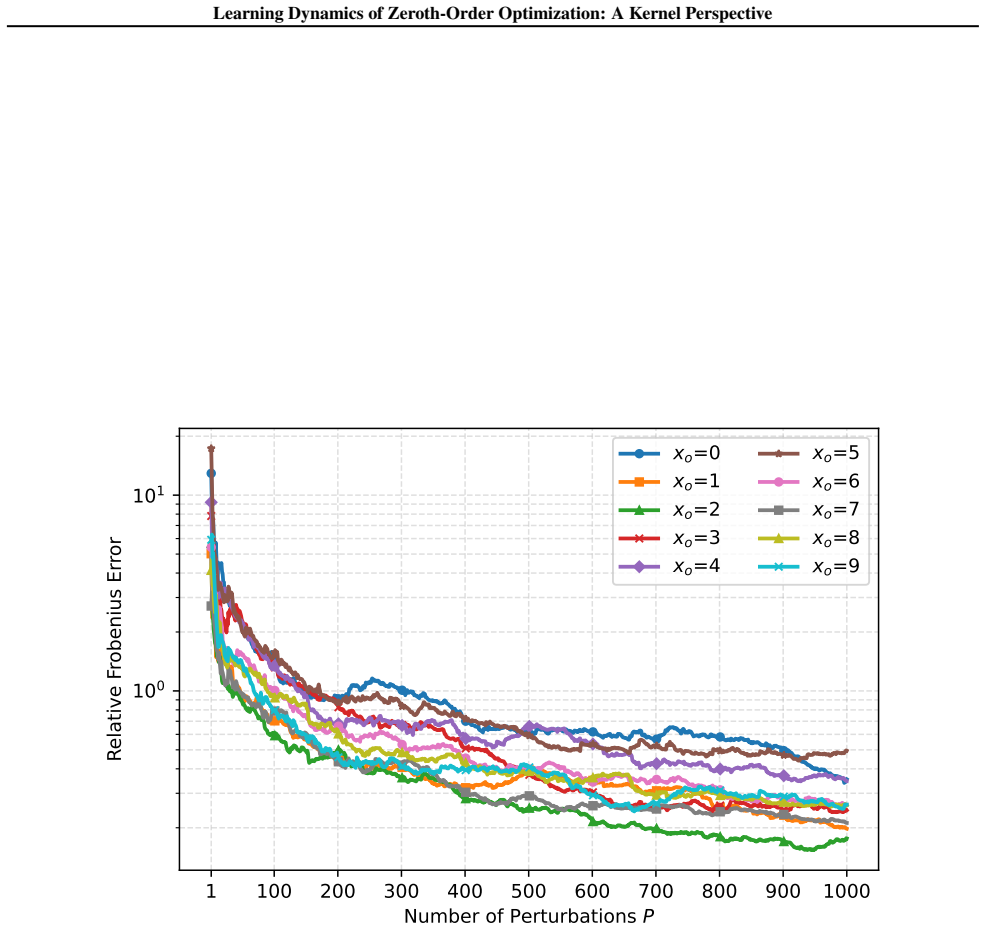
Compute the full empirical NTK on a small wide network, run ZO SGD with increasing numbers of perturbations, and measure how closely the observed loss trajectory matches the kernel-regression prediction; the gap should shrink with more perturbations while remaining insensitive to further increases in parameter count.
Figures












read the original abstract
Classical optimization theory establishes that zeroth-order (ZO) algorithms suffer from a dimension-dependent slowdown, with convergence rates typically scaling with the model dimension compared to first-order methods. However, in contrast to these theoretical expectations, a growing body of recent work demonstrates the successful application of ZO methods to fine-tuning Large Language Models (LLMs) with billions of parameters. To explain this paradox, we derive the one-step learning dynamics of ZO SGD, where the empirical Neural Tangent Kernel (eNTK) naturally emerges as the key term governing the learning behavior. Inspection of the eNTK produced by ZO SGD reveals that each element corresponds to the inner product of neural tangent vectors projected onto a random low-dimensional subspace. Thus, by invoking the Johnson-Lindenstrauss Lemma, our analysis shows that the fidelity of the ZO eNTK is governed primarily by the number of perturbations. Crucially, the approximation error depends on the model output size rather than the massive parameter dimension. This dimension-free property provides a theoretical justification for the scalability of ZO methods to LLMs finetuning tasks. We believe that this kernel-based framework offers a novel perspective for understanding ZO methods within the context of learning dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives the one-step learning dynamics of zeroth-order SGD, in which the empirical Neural Tangent Kernel (eNTK) appears as the governing operator. It observes that each entry of the ZO eNTK is an inner product of tangent vectors projected onto the random subspace spanned by the perturbation directions, and invokes the Johnson-Lindenstrauss lemma to bound the deviation from the full eNTK. The resulting error bound depends on the number of perturbations and the output dimension but is independent of the parameter dimension, thereby supplying a theoretical account for the observed scalability of ZO methods to LLM fine-tuning.
Significance. If the derivation is correct, the work supplies a kernel-theoretic explanation for the practical success of zeroth-order optimization in regimes where classical dimension-dependent rates would predict failure. The dimension-free character of the JL-based bound, obtained from standard one-step linearization and the distributional properties of the perturbations, is a clear strength and offers a concrete link between ZO methods and the NTK literature.
minor comments (3)
- The manuscript should explicitly enumerate the assumptions required for the one-step expansion to capture the dominant dynamics (e.g., sufficiently wide networks or specific initialization regimes) and for the JL lemma to apply without additional data-dependent restrictions.
- A brief discussion of the higher-order remainder terms omitted by the one-step analysis, together with a statement of the regime in which they remain negligible, would strengthen the claim that the derived dynamics are representative.
- Notation for the random perturbation vectors and the precise definition of the ZO eNTK (including how the low-dimensional projections are formed) should be introduced with a dedicated display equation early in the derivation section.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and the recommendation for minor revision. The summary accurately captures the core technical contribution.
read point-by-point responses
-
Referee: The paper derives the one-step learning dynamics of zeroth-order SGD, in which the empirical Neural Tangent Kernel (eNTK) appears as the governing operator. It observes that each entry of the ZO eNTK is an inner product of tangent vectors projected onto the random subspace spanned by the perturbation directions, and invokes the Johnson-Lindenstrauss lemma to bound the deviation from the full eNTK. The resulting error bound depends on the number of perturbations and the output dimension but is independent of the parameter dimension, thereby supplying a theoretical account for the observed scalability of ZO methods to LLM fine-tuning.
Authors: We appreciate the referee's concise and accurate summary of the derivation and its implications. The one-step analysis begins from the ZO gradient estimator and directly yields the projected eNTK as the effective operator; the JL bound then follows from the sub-Gaussian concentration of the random projections, with the error scaling in output dimension rather than parameter dimension as stated. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs the ZO eNTK directly from the model outputs and random perturbation directions in the one-step ZO SGD dynamics, then applies the external Johnson-Lindenstrauss Lemma to bound the approximation error of the projected tangent vectors. The error bound depends on the number of perturbations and output dimension (not parameter dimension d), which follows from the standard JL concentration result applied to the fixed collection of tangent vectors. No equation reduces to a fitted parameter renamed as a prediction, no self-citation chain justifies a uniqueness claim, and the central dimension-free property is not smuggled via ansatz or renaming. The derivation remains self-contained against the external lemma and standard NTK linearization.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Johnson-Lindenstrauss Lemma applies to the random low-dimensional projections of the tangent vectors
Reference graph
Works this paper leans on
-
[1]
Random Structures & Algorithms , volume=
An elementary proof of a theorem of Johnson and Lindenstrauss , author=. Random Structures & Algorithms , volume=. 2003 , publisher=
2003
-
[2]
Contemporary Mathematics , volume=
Extensions of Lipschitz mappings into a Hilbert space , author=. Contemporary Mathematics , volume=
-
[3]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[4]
International Conference on Machine Learning , pages=
Generalizing gaussian smoothing for random search , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[5]
Advances in Neural Information Processing Systems , volume=
On exact computation with an infinitely wide neural net , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Advances in Neural Information Processing Systems , volume=
Zeroth-order stochastic variance reduction for nonconvex optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2505.13954 , year=
VAMO: Efficient Large-Scale Nonconvex Optimization via Adaptive Zeroth Order Variance Reduction , author=. arXiv preprint arXiv:2505.13954 , year=
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
MUZO: Leveraging Multiple Queries and Momentum for Zeroth-Order Fine-Tuning of Large Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[9]
The Fourteenth International Conference on Learning Representations , year=
Converge Faster, Talk Less: Hessian-Informed Federated Zeroth-Order Optimization , author=. The Fourteenth International Conference on Learning Representations , year=
-
[10]
Journal of computer and System Sciences , volume=
Database-friendly random projections: Johnson-Lindenstrauss with binary coins , author=. Journal of computer and System Sciences , volume=. 2003 , publisher=
2003
-
[11]
and Yin, Wotao and Hong, Mingyi and Wang, Zhangyang and Liu, Sijia and Chen, Tianlong , booktitle =
Zhang, Yihua and Li, Pingzhi and Hong, Junyuan and Li, Jiaxiang and Zhang, Yimeng and Zheng, Wenqing and Chen, Pin-Yu and Lee, Jason D. and Yin, Wotao and Hong, Mingyi and Wang, Zhangyang and Liu, Sijia and Chen, Tianlong , booktitle =. Revisiting Zeroth-Order Optimization for Memory-Efficient. 2024 , volume =
2024
-
[12]
The Thirteenth International Conference on Learning Representations , year=
Revisiting Zeroth-Order Optimization: Minimum-Variance Two-Point Estimators and Directionally Aligned Perturbations , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
arXiv preprint arXiv:2505.18886 , year=
KerZOO: Kernel Function Informed Zeroth-Order Optimization for Accurate and Accelerated LLM Fine-Tuning , author=. arXiv preprint arXiv:2505.18886 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Localized zeroth-order prompt optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
International Conference on Machine Learning , pages=
Tensor programs iv: Feature learning in infinite-width neural networks , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[16]
International Conference on Learning Representations , year=
Finite Depth and Width Corrections to the Neural Tangent Kernel , author=. International Conference on Learning Representations , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , pages=
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , pages=
2018
-
[19]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review arXiv
-
[20]
Forty-Second International Conference on Machine Learning , year=
Natural Perturbations for Black-box Training of Neural Networks by Zeroth-Order Optimization , author=. Forty-Second International Conference on Machine Learning , year=
-
[21]
International Conference on Machine Learning , pages=
Guided evolutionary strategies: Augmenting random search with surrogate gradients , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[22]
arXiv preprint arXiv:2404.11893 , year=
Derivative-free optimization via adaptive sampling strategies , author=. arXiv preprint arXiv:2404.11893 , year=
-
[23]
The Thirteenth International Conference on Learning Representations , year=
Achieving Dimension-Free Communication in Federated Learning via Zeroth-Order Optimization , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
IEEE Signal Processing Magazine , volume=
A primer on zeroth-order optimization in signal processing and machine learning: Principals, recent advances, and applications , author=. IEEE Signal Processing Magazine , volume=. 2020 , publisher=
2020
-
[25]
International Conference on Machine Learning , pages=
A kernel-based view of language model fine-tuning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[26]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Fine-Tuning Language Models with Just Forward Passes , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[27]
2009 , publisher=
Introduction to derivative-free optimization , author=. 2009 , publisher=
2009
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Zeroth-order fine-tuning of llms in random subspaces , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
arXiv preprint arXiv:2601.05501 , year=
Hi-ZFO: Hierarchical Zeroth-and First-Order LLM Fine-Tuning via Importance-Guided Tensor Selection , author=. arXiv preprint arXiv:2601.05501 , year=
-
[30]
Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages=
2013
-
[31]
International Conference on Learning Representations , year=
Understanding deep learning requires rethinking generalization , author=. International Conference on Learning Representations , year=
-
[32]
Proceedings of the National Academy of Sciences , volume=
Reconciling modern machine-learning practice and the classical bias--variance trade-off , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[33]
International Conference on Learning Representations , year=
Measuring the Intrinsic Dimension of Objective Landscapes , author=. International Conference on Learning Representations , year=
-
[34]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (volume 1: long papers) , pages=
-
[35]
Journal of Machine Learning Research , volume=
Traces of class/cross-class structure pervade deep learning spectra , author=. Journal of Machine Learning Research , volume=
-
[36]
Second-Order Fine-Tuning without Pain for
Yanjun Zhao and Sizhe Dang and Haishan Ye and Guang Dai and Yi Qian and Ivor Tsang , booktitle=. Second-Order Fine-Tuning without Pain for. 2025 , url=
2025
-
[37]
Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security , pages=
Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models , author=. Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security , pages=
-
[38]
2020 IEEE International Conference on Big Data , pages=
Pyhessian: Neural networks through the lens of the hessian , author=. 2020 IEEE International Conference on Big Data , pages=. 2020 , organization=
2020
-
[39]
The Twelfth International Conference on Learning Representations , year=
DeepZero: Scaling Up Zeroth-Order Optimization for Deep Model Training , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
Journal of Machine Learning Research , volume=
An optimal algorithm for bandit and zero-order convex optimization with two-point feedback , author=. Journal of Machine Learning Research , volume=
-
[41]
IEEE Transactions on Information Theory , volume=
Optimal rates for zero-order convex optimization: The power of two function evaluations , author=. IEEE Transactions on Information Theory , volume=. 2015 , publisher=
2015
-
[42]
International Conference on Learning Representations , year=
Gradientless Descent: High-Dimensional Zeroth-Order Optimization , author=. International Conference on Learning Representations , year=
-
[43]
The Thirteenth International Conference on Learning Representations , year=
Enhancing Zeroth-order Fine-tuning for Language Models with Low-rank Structures , author=. The Thirteenth International Conference on Learning Representations , year=
-
[44]
Forty-first International Conference on Machine Learning , year=
Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes , author=. Forty-first International Conference on Machine Learning , year=
-
[45]
Sutherland , booktitle=
Yi Ren and Danica J. Sutherland , booktitle=. Learning Dynamics of. 2025 , url=
2025
-
[46]
IEEE Transactions on Automatic Control , volume=
Multivariate stochastic approximation using a simultaneous perturbation gradient approximation , author=. IEEE Transactions on Automatic Control , volume=. 2002 , publisher=
2002
-
[47]
http://yann
The MNIST database of handwritten digits , author=. http://yann. lecun. com/exdb/mnist/ , year=
-
[48]
IEEE Transactions on Automatic Control , volume=
Optimal random perturbations for stochastic approximation using a simultaneous perturbation gradient approximation , author=. IEEE Transactions on Automatic Control , volume=. 2002 , publisher=
2002
-
[49]
2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD) , pages=
Perturbation-efficient zeroth-order optimization for hardware-friendly on-device training , author=. 2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD) , pages=. 2025 , organization=
2025
-
[50]
Foundations of Computational Mathematics , volume=
Random gradient-free minimization of convex functions , author=. Foundations of Computational Mathematics , volume=. 2017 , publisher=
2017
-
[51]
and Kalai, Adam Tauman and McMahan, H
Flaxman, Abraham D. and Kalai, Adam Tauman and McMahan, H. Brendan , title =. Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages =. 2005 , isbn =
2005
-
[52]
SIAM Journal on Optimization , author =
Stochastic first-and zeroth-order methods for nonconvex stochastic programming , volume =. SIAM Journal on Optimization , author =. 2013 , pages =
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.