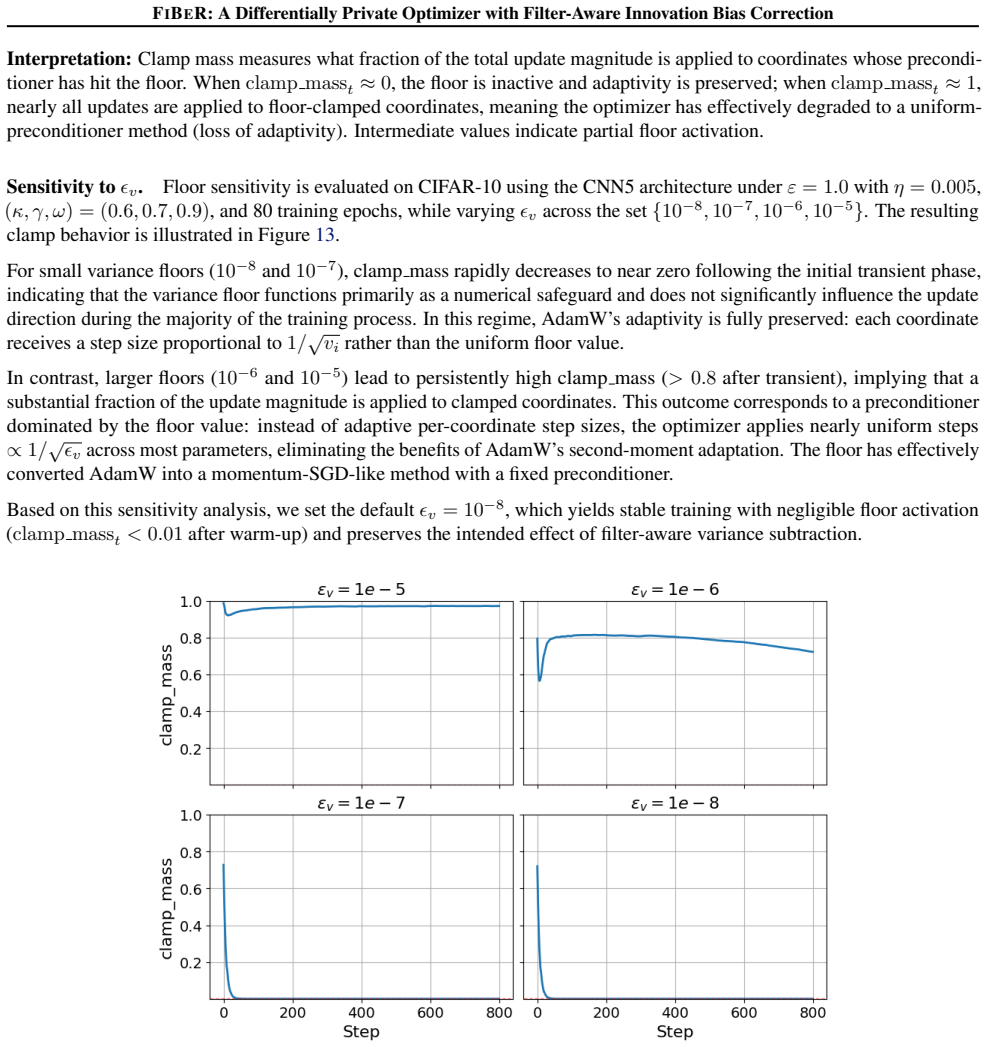
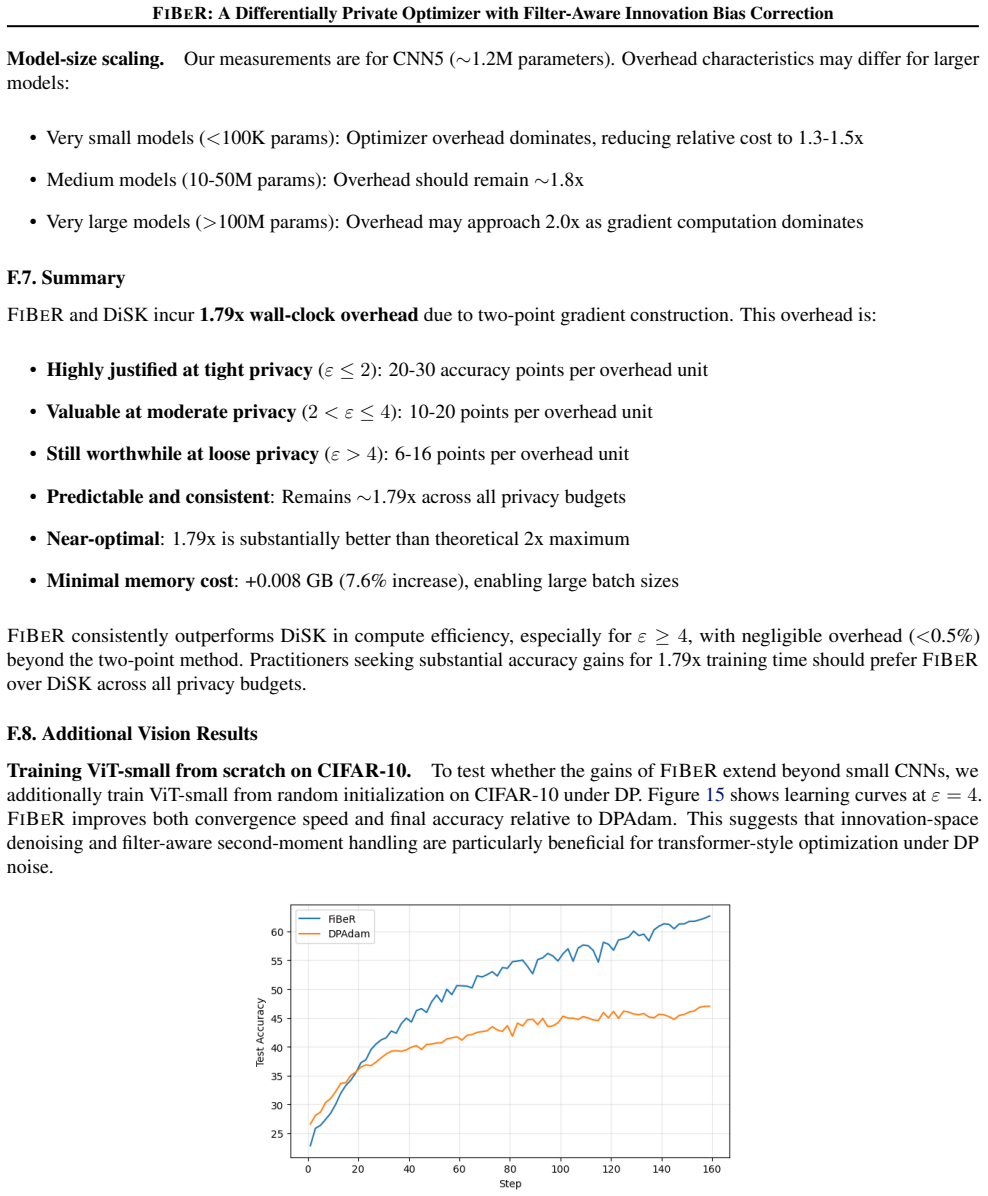
Recognition: unknown
FIBER: A Differentially Private Optimizer with Filter-Aware Innovation Bias Correction
Pith reviewed 2026-05-07 04:09 UTC · model grok-4.3
The pith
FiBeR recalibrates AdamW's second-moment accumulator for filtered DP gradients by subtracting a closed-form attenuated noise term A(ω)σ_w².
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
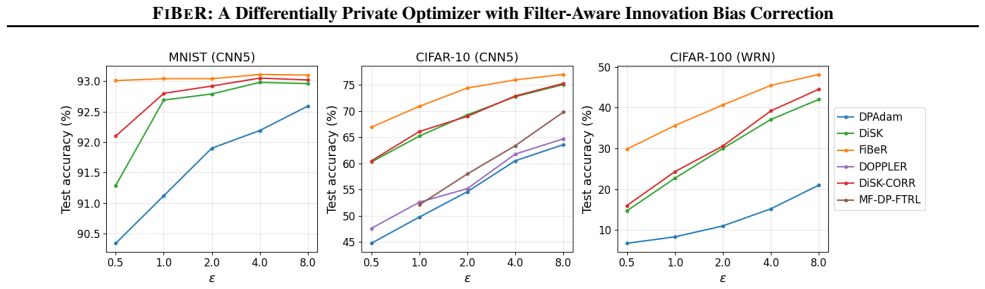
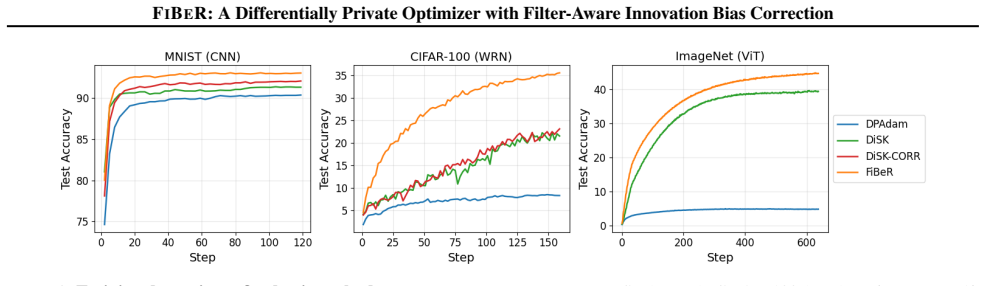
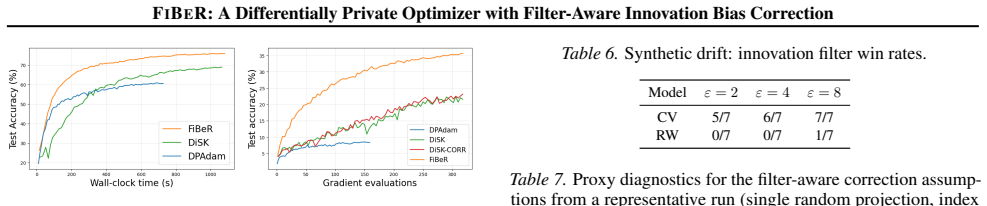
FiBeR is a DP optimizer that denoises in innovation space by filtering the residual stream and integrating to obtain the filtered gradient estimate. It decouples the two-point observation geometry from the innovation gain to permit independent tuning. Its central contribution is a filter-aware second-moment calibration that subtracts the attenuated DP noise contribution A(ω)σ_w², where A(ω) is derived in closed form for the innovation filter and can be computed for general stable linear filters. The method is shown to produce substantial performance improvements over prior DP optimizers across vision and language benchmarks under equivalent privacy constraints.
What carries the argument
The closed-form noise attenuation factor A(ω) for the innovation filter, which supplies the exact amount to subtract from the second-moment accumulator so that the bias correction matches the filtered noise statistics.
If this is right
- The calibration extends to any stable linear filter for which the attenuation factor can be computed.
- Decoupling observation geometry from innovation gain allows separate hyper-parameter tuning without affecting the noise correction.
- The approach produces measurable gains on both vision and language benchmarks while preserving the same privacy budget.
- The method can be applied inside existing DP training pipelines that already employ temporal filtering.
Where Pith is reading between the lines
- The same attenuation derivation could be applied to other second-moment-based optimizers beyond AdamW.
- Filter selection might be automated by minimizing the effective post-correction noise variance expressed through A(ω).
- The technique could reduce hyper-parameter search effort in DP-SGD by making the second-moment estimate more predictable.
Load-bearing premise
The closed-form derivation of A(ω) accurately captures the actual noise attenuation experienced by the second-moment accumulator for the filters used in the reported experiments.
What would settle it
Running identical training runs with and without the A(ω) subtraction term while holding all other implementation details fixed; if performance gains vanish when the term is removed, the calibration is the operative mechanism.
Figures



read the original abstract
Differentially private (DP) training protects individual examples by adding noise to gradients, but the injected noise interacts nontrivially with adaptive optimizers. Recent DP methods temporally filter privatized gradients to reduce variance; however, filtering also changes the DP noise statistics seen by AdamW's second-moment accumulator. As a result, bias corrections derived for unfiltered DP noise, such as subtracting sigma_w squared, can become miscalibrated when filtering is present. We propose FiBeR, a DP optimizer designed for temporally filtered privatized gradients. FiBeR (i) performs denoising in innovation space by filtering the residual stream and integrating it to form the filtered gradient estimate, (ii) decouples the two-point observation geometry from the innovation gain to enable independent tuning, and (iii) introduces a filter-aware second-moment calibration that subtracts the attenuated DP noise contribution A(omega) sigma_w squared, where A(omega) is derived in closed form for the innovation filter and can be computed for general stable linear filters. Across vision and language benchmarks, FiBeR consistently demonstrates substantial improvements in the performance of DP optimizers, surpassing state-of-the-art results under equivalent privacy constraints on multiple tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FiBeR, a differentially private optimizer for temporally filtered privatized gradients. It introduces three components: (i) denoising performed in innovation space by filtering the residual stream and integrating to obtain the filtered gradient estimate, (ii) decoupling of the two-point observation geometry from the innovation gain to allow independent tuning, and (iii) a filter-aware second-moment calibration that subtracts the attenuated DP noise contribution A(ω) σ_w², where A(ω) is stated to be derived in closed form for the innovation filter and extensible to general stable linear filters. The authors claim that FiBeR yields substantial performance gains over prior DP optimizers on vision and language benchmarks while respecting equivalent privacy constraints.
Significance. If the closed-form derivation of A(ω) correctly computes the attenuated noise variance reaching the second-moment accumulator and the reported gains are attributable to this calibration, the work would address a genuine gap in how temporal filtering interacts with adaptive DP optimizers. The generality to arbitrary stable linear filters and the innovation-space formulation are potentially useful strengths. However, the absence of algebraic verification steps, machine-checked confirmation, or isolating ablations currently prevents a firm assessment of whether the central technical contribution drives the observed improvements.
major comments (3)
- [Experimental evaluation (assumed §4–5)] The central performance claim rests on the filter-aware bias correction. The manuscript provides no ablation that applies only the A(ω) subtraction (with all other FiBeR components held fixed) to a baseline filtered DP optimizer; without this isolation it is impossible to attribute gains specifically to the closed-form calibration rather than to innovation-space denoising or the decoupled geometry.
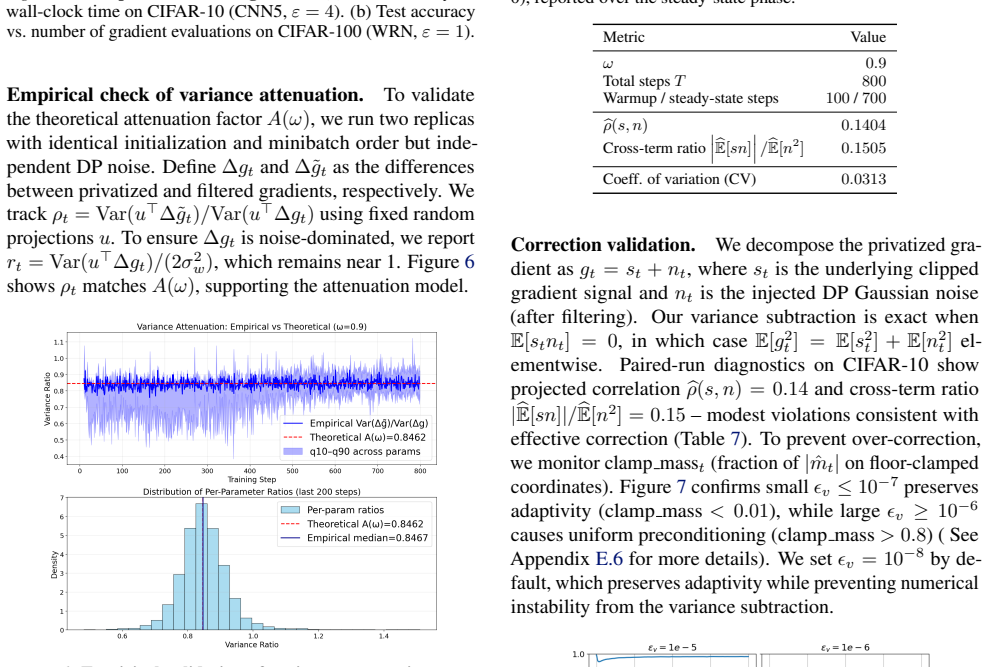
- [Method section describing the second-moment calibration (assumed §3.3)] The derivation of A(ω) is described as closed-form for the innovation filter, yet the text supplies neither the intermediate algebraic steps that produce the expression nor a direct numerical check (e.g., Monte-Carlo estimation of attenuated variance versus the formula) for the concrete filters employed in the experiments. This verification is load-bearing for the third design choice.
- [Tables and figures in the experimental section] Reported results lack error bars, multiple random seeds, or statistical significance tests. Given that DP training variance is high, the absence of these elements weakens the claim that FiBeR “consistently demonstrates substantial improvements” and “surpasses state-of-the-art results.”
minor comments (3)
- [Abstract] The abstract states the three design choices and the performance claim but does not quantify the improvements (e.g., accuracy deltas or privacy-utility curves), making it difficult for readers to gauge the magnitude of the advance before reading the full experiments.
- [Preliminaries and method sections] Notation for the innovation filter, the two-point observation geometry, and the precise definition of A(ω) should be introduced with a single consolidated table or diagram to improve readability.
- [Introduction and related work] The manuscript should explicitly cite the prior filtered-DP-gradient works whose noise statistics are being corrected, so that the novelty of the A(ω) term is immediately clear.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We appreciate the identification of areas where the manuscript can be strengthened, particularly regarding empirical isolation of contributions, verification of the central derivation, and statistical reporting. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental evaluation (assumed §4–5)] The central performance claim rests on the filter-aware bias correction. The manuscript provides no ablation that applies only the A(ω) subtraction (with all other FiBeR components held fixed) to a baseline filtered DP optimizer; without this isolation it is impossible to attribute gains specifically to the closed-form calibration rather than to innovation-space denoising or the decoupled geometry.
Authors: We agree that an isolating ablation would strengthen attribution of gains specifically to the filter-aware calibration. Although the three components of FiBeR are designed to operate synergistically, we will add a new ablation in the revised experimental section. This ablation will apply only the A(ω) subtraction to a baseline temporally filtered DP optimizer (holding innovation-space denoising and decoupled geometry fixed) and compare it against the full FiBeR and the baseline without the correction. The results will be reported in an updated table or figure to clarify the contribution of the closed-form bias correction. revision: yes
-
Referee: [Method section describing the second-moment calibration (assumed §3.3)] The derivation of A(ω) is described as closed-form for the innovation filter, yet the text supplies neither the intermediate algebraic steps that produce the expression nor a direct numerical check (e.g., Monte-Carlo estimation of attenuated variance versus the formula) for the concrete filters employed in the experiments. This verification is load-bearing for the third design choice.
Authors: We apologize for the omission of the intermediate steps in the original submission. We will expand Section 3.3 to include the complete algebraic derivation of A(ω), beginning from the transfer function of the innovation filter, through the computation of the steady-state filtered noise variance, and arriving at the closed-form expression A(ω)σ_w². We will also add a numerical verification (via Monte-Carlo simulation of the attenuated DP noise variance) for the specific filters used in the experiments, either in the main text or as a dedicated appendix subsection. This will provide the requested verification for the third design choice. revision: yes
-
Referee: [Tables and figures in the experimental section] Reported results lack error bars, multiple random seeds, or statistical significance tests. Given that DP training variance is high, the absence of these elements weakens the claim that FiBeR “consistently demonstrates substantial improvements” and “surpasses state-of-the-art results.”
Authors: We acknowledge that the stochasticity of DP training makes robust statistical reporting essential. In the revised manuscript, we will rerun the key experiments across multiple random seeds (at least five seeds per configuration) and report mean performance with standard deviation error bars in all tables and figures. We will also include appropriate statistical significance tests (such as paired t-tests) between FiBeR and the baselines to support the claims of consistent improvements. These updates will be reflected in the experimental section and associated tables/figures. revision: yes
Circularity Check
No circularity: A(ω) derivation is an independent closed-form calculation from filter transfer function.
full rationale
The paper's central technical step is the closed-form derivation of the attenuation factor A(ω) for the innovation filter, which is then used to subtract the attenuated noise variance A(ω)σ_w² from AdamW's second-moment accumulator. This step is presented as a direct algebraic consequence of the linear filter's frequency response applied to white DP noise; it does not rely on fitting to target performance, self-referential definitions, or load-bearing self-citations. No equations reduce the claimed result to its own inputs by construction, and the derivation is independent of the reported benchmark gains. The manuscript therefore remains self-contained against external benchmarks for the purpose of circularity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The temporal filter applied to privatized gradients is a stable linear filter.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DP-AdamBC: Your DP-Adam Is Actually DP-SGD (Unless You Apply Bias Correction) , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[2]
arXiv preprint arXiv:2410.03883 , year=
DiSK: Differentially Private Optimizer with Simplified Kalman Filter for Noise Reduction , author=. arXiv preprint arXiv:2410.03883 , year=
-
[3]
Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
Deep Learning with Differential Privacy , author=. Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
2016
-
[4]
Journal of Privacy and Confidentiality , volume=
Differentially private fine-tuning of language models , author=. Journal of Privacy and Confidentiality , volume=
-
[5]
USENIX Security Symposium , pages=
Evaluating differentially private machine learning in practice , author=. USENIX Security Symposium , pages=
-
[7]
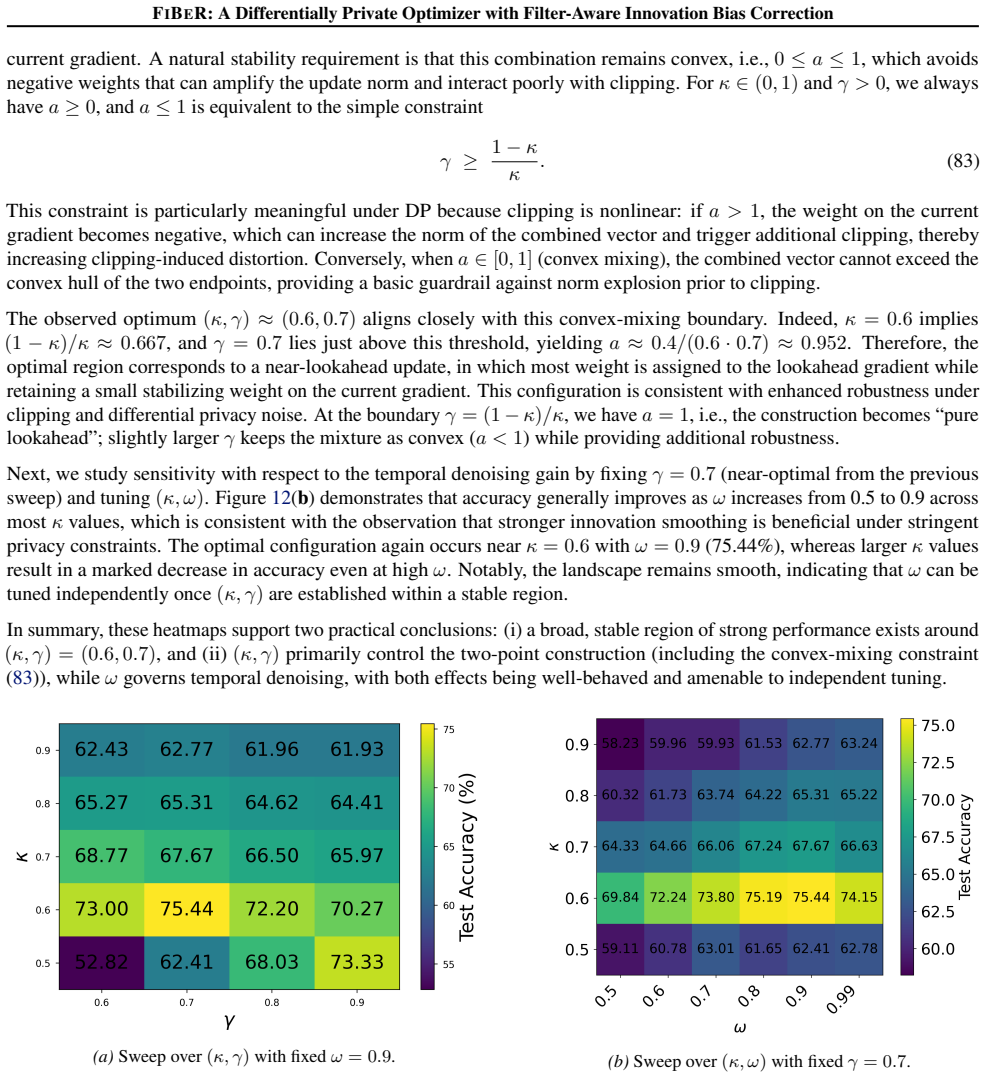
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Differentially private learning with per-sample adaptive clipping , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Automatic clipping: Differentially private deep learning made easier and stronger , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
International Conference on Machine Learning , pages=
Differentially private optimization on large model at small cost , author=. International Conference on Machine Learning , pages=
-
[10]
Transactions on Machine Learning Research , year=
Towards large scale transfer learning for differentially private image classification , author=. Transactions on Machine Learning Research , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
DOPPLER: Differentially private optimizers with low-pass filter for privacy noise reduction , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Gradient descent with linearly correlated noise: Theory and applications to differential privacy , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
International Conference on Learning Representations , year=
Correlated noise provably beats independent noise for differentially private learning , author=. International Conference on Learning Representations , year=
-
[14]
International Conference on Machine Learning , pages=
Practical and private (deep) learning without sampling or shuffling , author=. International Conference on Machine Learning , pages=
-
[15]
International Conference on Learning Representations , year=
Differentially private SGD without clipping bias: An error-feedback approach , author=. International Conference on Learning Representations , year=
-
[16]
Mathematical and Scientific Machine Learning , pages=
DP-LSSGD: A stochastic optimization method to lift the utility in privacy-preserving ERM , author=. Mathematical and Scientific Machine Learning , pages=. 2020 , organization=
2020
-
[17]
Proceedings on Privacy Enhancing Technologies , volume=
DPlis: Boosting utility of differentially private deep learning via randomized smoothing , author=. Proceedings on Privacy Enhancing Technologies , volume=
-
[18]
IEEE Transactions on Information Forensics and Security , volume=
Laplacian smoothing stochastic ADMMs with differential privacy guarantees , author=. IEEE Transactions on Information Forensics and Security , volume=
-
[19]
arXiv preprint arXiv:1810.12273 , year=
Kalman gradient descent: Adaptive variance reduction in stochastic optimization , author=. arXiv preprint arXiv:1810.12273 , year=
-
[20]
Foundations and Trends in Theoretical Computer Science , volume=
The algorithmic foundations of differential privacy , author=. Foundations and Trends in Theoretical Computer Science , volume=
-
[21]
Subsampled r
Wang, Yu-Xiang and Balle, Borja and Kasiviswanathan, Shiva Prasad , booktitle=. Subsampled r. 2019 , organization=
2019
-
[22]
arXiv preprint arXiv:2011.11660 , year=
Differentially private learning needs better features (or much more data) , author=. arXiv preprint arXiv:2011.11660 , year=
-
[23]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R. Transformers: State-of-the-Art Natural Language Processing , booktitle =. 2020 , url =. doi:10.18653/V1/2020.EMNLP-DEMOS.6 , timestamp =
-
[24]
Automatic Clipping: Differentially Private Deep Learning Made Easier and Stronger , booktitle =
Zhiqi Bu and Yu. Automatic Clipping: Differentially Private Deep Learning Made Easier and Stronger , booktitle =. 2023 , timestamp =
2023
-
[25]
Li Deng , title =. 2012 , url =. doi:10.1109/MSP.2012.2211477 , timestamp =
-
[26]
International Conference on Learning Representations , year=
Differentially Private Fine-tuning of Language Models , author=. International Conference on Learning Representations , year=
-
[27]
International Conference on Learning Representations , year=
Large Language Models Can Be Strong Differentially Private Learners , author=. International Conference on Learning Representations , year=
-
[28]
International Conference on Machine Learning , year=
Differentially Private Bias-Term Fine-tuning of Foundation Models , author=. International Conference on Machine Learning , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Scalable and Efficient Training of Large Convolutional Neural Networks with Differential Privacy , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[30]
arXiv preprint arXiv:2205.06720 , year=
On the Importance of Architecture and Feature Selection in Differentially Private Machine Learning , author=. arXiv preprint arXiv:2205.06720 , year=
-
[31]
arXiv preprint arXiv:2204.13650 , year=
Unlocking High-Accuracy Differentially Private Image Classification through Scale , author=. arXiv preprint arXiv:2204.13650 , year=
-
[32]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 1998 , publisher=
1998
-
[33]
Learning multiple layers of features from tiny images , author=
-
[34]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
ImageNet: A large-scale hierarchical image database , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2009 , publisher=
2009
-
[35]
, journal=
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R. , journal=
-
[36]
Novikova, Jekaterina and Du. The. Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue , pages=. 2017 , address=
2017
-
[37]
2021 , publisher=
Nan, Linyong and Radev, Dragomir and Zhang, Rui and Rau, Amrit and Sivaprasad, Abhinand and Hsieh, Chiachun and Tang, Xiangru and Vyas, Aadit and Verma, Neha and Krishna, Pranav and Liu, Yangxiaokang and Irwanto, Nadia and Pan, Jessica and Rahman, Faiaz and Zaidi, Ahmad and Mutuma, Mutethia and Tarabar, Yasin and Gupta, Ankit and Yu, Tao and Tan, Yi Chern...
2021
-
[38]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review arXiv 2010
-
[39]
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , journal=
-
[40]
Language models are unsupervised multitask learners , author=
-
[41]
Transformers:
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Cl. Transformers:. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=. 2020 , publisher=
2020
-
[42]
Transactions on Machine Learning Research , year=
Large scale transfer learning for differentially private image classification , author=. Transactions on Machine Learning Research , year=
-
[43]
arXiv preprint arXiv:2204.13650 , year=
Soham De and Leonard Berrada and Jamie Hayes and Samuel L. Smith and Borja Balle , title =. CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2204.13650 , eprinttype =. 2204.13650 , timestamp =
-
[44]
Atefeh Gilani and Naima Tasnim and Lalitha Sankar and Oliver Kosut , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.06549 , eprinttype =. 2506.06549 , timestamp =
-
[45]
On the convergence of adam and beyond.arXiv preprint arXiv:1904.09237, 2019
On the convergence of adam and beyond , author=. arXiv preprint arXiv:1904.09237 , year=
-
[46]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , booktitle =
Adam Paszke and Sam Gross and Francisco Massa and Adam Lerer and James Bradbury and Gregory Chanan and Trevor Killeen and Zeming Lin and Natalia Gimelshein and Luca Antiga and Alban Desmaison and Andreas K. PyTorch: An Imperative Style, High-Performance Deep Learning Library , booktitle =. 2019 , timestamp =
2019
-
[47]
Ashkan Yousefpour and Igor Shilov and Alexandre Sablayrolles and Davide Testuggine and Karthik Prasad and Mani Malek and John Nguyen and Sayan Ghosh and Akash Bharadwaj and Jessica Zhao and Graham Cormode and Ilya Mironov , title =. CoRR , volume =. 2021 , url =. 2109.12298 , timestamp =
-
[48]
Pre-training Differentially Private Models with Limited Public Data , booktitle =
Zhiqi Bu and Xinwei Zhang and Sheng Zha and Mingyi Hong and George Karypis , editor =. Pre-training Differentially Private Models with Limited Public Data , booktitle =. 2024 , timestamp =
2024
-
[49]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[50]
The Tenth International Conference on Learning Representations,
Nicolas Papernot and Thomas Steinke , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
2022
-
[51]
Frank McSherry and Kunal Talwar , title =. 48th Annual. 2007 , url =. doi:10.1109/FOCS.2007.66 , timestamp =
-
[52]
Choquette
Christopher A. Choquette. (Amplified) Banded Matrix Factorization:. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
2023
-
[53]
Tran Thi Phuong and Le Trieu Phong , title =. 2019 , url =. doi:10.1109/ACCESS.2019.2916341 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.