Recognition: unknown
Scale-Dependent Input Representation and Confidence Estimation for LLMs in Materials Property Prediction
Pith reviewed 2026-05-07 15:59 UTC · model grok-4.3
The pith
Fine-tuned LLMs predict crystal formation energies and bandgaps more accurately with space-group-inclusive summaries, and mean negative log-likelihood acts as a built-in confidence indicator after fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
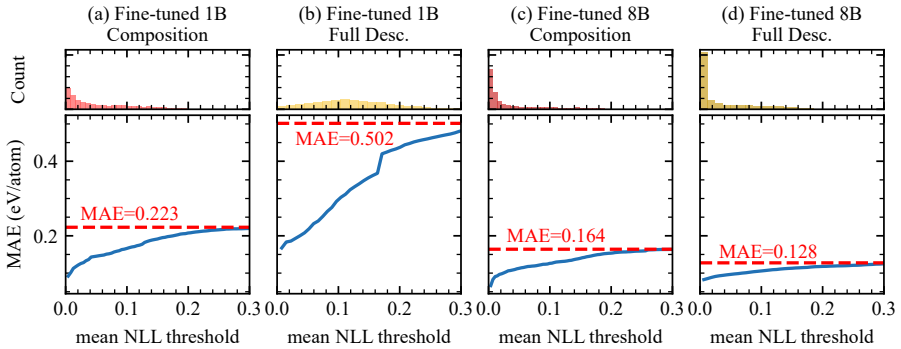
We fine-tune Llama models of 1B and 8B parameters on an inorganic crystal structure dataset and compare five input representations for formation energy and bandgap prediction. The optimal representation depends on model scale, with the 1B model favoring compact forms and the 8B model maintaining accuracy on longer descriptions and CIF files. Crystal summaries that include space-group information consistently outperform composition-only inputs at both scales. Fine-tuned models show a clear trend in which lower mean negative log-likelihood of the numerical output tokens corresponds to smaller prediction errors, indicating that mean NLL can serve as a practical confidence measure without added
What carries the argument
Comparison of five input representations (chemical composition, crystal summary with space group, local environment description, full text description, and CIF) across two model scales, together with mean negative log-likelihood of the numerical output tokens as a post-fine-tuning confidence signal.
If this is right
- Input representation must be chosen according to model scale to reach best accuracy in crystal property tasks.
- Space-group symmetry supplies reliable structural features that improve predictions regardless of model size.
- Mean NLL of numerical tokens provides an efficient, training-free way to flag low-confidence outputs in materials LLM applications.
- Larger models can accept richer textual or file-based crystal descriptions while retaining predictive performance.
Where Pith is reading between the lines
- The scale-dependent behavior suggests that future materials LLMs may benefit from adaptive input pipelines that grow in detail with model capacity.
- Mean NLL confidence could be combined with existing uncertainty methods to prioritize which predictions warrant expensive follow-up calculations or experiments.
- Testing whether the same input and NLL patterns appear when predicting other properties such as elastic moduli or thermal conductivity would clarify how general the findings are.
Load-bearing premise
The observed link between lower mean NLL and smaller prediction error on the test set will continue to hold for crystal compositions and symmetries never seen during fine-tuning and for models trained on different data or with different random seeds.
What would settle it
Running the same fine-tuned models on a fresh collection of crystal structures whose compositions and space groups lie outside the original training distribution and checking whether the inverse relationship between mean NLL and actual error still appears.
Figures



read the original abstract
Large language models (LLMs) are increasingly applied to materials science. However, the relationship between prediction accuracy, input representation, and model scale remains unclear, and reliable methods for assessing prediction confidence have not yet been established. In this study, we fine-tune two Llama models of different scales (1B and 8B) using low-rank adaptation (LoRA) on an inorganic crystal structure dataset. We systematically evaluate five input representations, namely chemical composition, crystal summary, local environment description, full text description, and crystallographic information files (CIF), for formation energy and bandgap prediction. Our results show that the optimal input representation depends on model scale. The 1B model performs better with compact representations, whereas the 8B model maintains high accuracy even with longer natural-language descriptions and CIF inputs. Across both model scales, crystal summaries that include space-group information consistently outperform composition-only inputs, indicating that symmetry information serves as a robust and informative feature. We further analyze the relationship between prediction error and the mean negative log-likelihood (mean NLL) of tokens corresponding to predicted numerical values. While no clear correlation is observed in base models, fine-tuned models exhibit a consistent trend in which lower mean NLL corresponds to smaller prediction errors. This result suggests that mean NLL can serve as a practical confidence indicator without requiring additional training. These findings demonstrate that both input representation and model scale play critical roles in LLM-based materials property prediction, and that mean NLL provides an effective and computationally efficient measure of prediction confidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper fine-tunes Llama-1B and Llama-8B models with LoRA on an inorganic crystal dataset to predict formation energy and bandgap. It systematically compares five input representations (composition-only, crystal summary, local environment, full text description, and CIF) and reports that optimal representation is scale-dependent: compact inputs suit the 1B model while the 8B model tolerates longer descriptions and CIF files. Crystal summaries that incorporate space-group information outperform composition-only inputs across both scales. In fine-tuned models, lower mean negative log-likelihood (NLL) of the numerical tokens in the output correlates with smaller prediction errors on the held-out test set, leading the authors to propose mean NLL as a training-free confidence indicator.
Significance. If the empirical trends hold, the work supplies practical guidance on input engineering for LLM-based materials property prediction and demonstrates a computationally cheap way to obtain per-prediction confidence scores. The consistent behavior across two model scales and multiple input formats strengthens the applicability of the findings to real materials-informatics workflows.
major comments (1)
- [Results on confidence estimation] Results section on mean NLL as confidence indicator: the reported correlation between mean NLL and absolute prediction error is shown exclusively on the in-distribution held-out test split. No out-of-distribution test sets (different elemental ranges, space-group families, or synthesis-condition shifts) or cross-setup experiments (varied random seeds, LoRA ranks, or training datasets) are presented. This leaves open whether mean NLL captures genuine epistemic uncertainty or merely dataset-specific token-probability artifacts, directly weakening the central claim that it constitutes a practical, general-purpose confidence indicator.
minor comments (2)
- [Abstract] Abstract: the phrase 'crystal summary' is used without a one-sentence definition of its content; a brief parenthetical description would improve immediate readability.
- [Methods] Methods: explicit reporting of train/validation/test split sizes, exact number of unique compositions, and the procedure used to guarantee the test set is strictly held-out would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed review and valuable suggestions. The feedback on the confidence estimation section is particularly helpful in refining our claims. We provide a point-by-point response below.
read point-by-point responses
-
Referee: Results section on mean NLL as confidence indicator: the reported correlation between mean NLL and absolute prediction error is shown exclusively on the in-distribution held-out test split. No out-of-distribution test sets (different elemental ranges, space-group families, or synthesis-condition shifts) or cross-setup experiments (varied random seeds, LoRA ranks, or training datasets) are presented. This leaves open whether mean NLL captures genuine epistemic uncertainty or merely dataset-specific token-probability artifacts, directly weakening the central claim that it constitutes a practical, general-purpose confidence indicator.
Authors: We appreciate the referee's point regarding the scope of our experiments on the mean NLL confidence indicator. It is correct that our analysis is performed on the held-out test split from the same dataset distribution. We did not include out-of-distribution evaluations or variations in training setups such as different seeds or LoRA ranks. This limitation means that while we observe a consistent correlation in fine-tuned models across scales and input types, we cannot yet claim that mean NLL fully captures epistemic uncertainty in all scenarios. In response, we will revise the manuscript to explicitly state that the proposed confidence indicator is validated within the in-distribution setting and to include a discussion of its potential limitations. We will also suggest that future work could explore OOD tests to further validate its generality. This revision clarifies the claims without overstating the current evidence. We believe this addresses the concern while preserving the practical utility demonstrated in our results. revision: partial
Circularity Check
No circularity: purely empirical evaluation on held-out data
full rationale
The paper reports experimental results from fine-tuning Llama models on a crystal dataset and measuring performance across input representations plus the correlation of mean NLL with error. No mathematical derivations, first-principles claims, or predictions are made that could reduce to fitted parameters or self-referential definitions by construction. All reported trends are direct computations from model outputs on held-out splits; the NLL metric requires no additional fitting. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided text, so the central claims remain independent of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LoRA fine-tuning on the chosen dataset is sufficient to adapt the base LLM to the regression task without catastrophic forgetting of general capabilities.
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
T. B. Brown, B. Mann, N. Ryderet al., “Language models are few-shot learners,”arXiv [cs.CL], 28 May 2020, arXiv:2005.14165
work page internal anchor Pith review arXiv 2020
-
[2]
A. Grattafiori, A. Dubey, A. Jauhriet al., “The llama 3 herd of models,”arXiv [cs.AI], 31 Jul. 2024, arXiv:2407.21783
work page internal anchor Pith review arXiv 2024
-
[3]
LLMatDesign: Autonomous materials discovery with large language models,
S. Jia, C. Zhang, and V. Fung, “LLMatDesign: Autonomous materials discovery with large language models,”arXiv [cond-mat.mtrl-sci], 18 Jun. 2024, arXiv:2406.13163
-
[4]
Accelerated inorganic materials design with generative AI agents,
I. Takahara, T. Mizoguchi, and B. Liu, “Accelerated inorganic materials design with generative AI agents,”Cell Rep. Phys. Sci., vol. 6, no. 12, p. 103019, 17 Dec. 2025
2025
-
[5]
MatKG: An autonomously generated knowledge graph in material science,
V. Venugopal and E. Olivetti, “MatKG: An autonomously generated knowledge graph in material science,”Sci. Data, vol. 11, no. 1, p. 217, 17 Feb. 2024. 11
2024
-
[6]
A general-purpose material property data ex- traction pipeline from large polymer corpora using natural language processing,
P. Shetty, A. C. Rajan, C. Kuennethet al., “A general-purpose material property data ex- traction pipeline from large polymer corpora using natural language processing,”Npj Comput. Mater., vol. 9, no. 1, p. 52, 5 Apr. 2023
2023
-
[7]
LLM-prop: predicting the properties of crystalline materials using large language models,
A. Niyongabo Rubungo, C. Arnold, B. P. Randet al., “LLM-prop: predicting the properties of crystalline materials using large language models,”Npj Comput. Mater., vol. 11, no. 1, pp. 1–13, 18 Jun. 2025
2025
-
[8]
MatterChat: A multi-modal LLM for material science,
Y. Tang, W. Xu, J. Caoet al., “MatterChat: A multi-modal LLM for material science,”arXiv [cs.AI], 18 Feb. 2025, arXiv:2502.13107
-
[9]
Domain-specific large language model for predicting band gap and formation energy of III-VIIIB and III-IVA nitrides based on fine-tuned GPT-3.5-turbo,
L. Hu and G. Jia, “Domain-specific large language model for predicting band gap and formation energy of III-VIIIB and III-IVA nitrides based on fine-tuned GPT-3.5-turbo,”Mach. Learn. Sci. Technol., vol. 6, no. 3, p. 035019, 30 Sep. 2025
2025
-
[10]
LLM4Mat-bench: benchmarking large language models for materials property prediction,
A. Niyongabo Rubungo, K. Li, J. Hattrick-Simperset al., “LLM4Mat-bench: benchmarking large language models for materials property prediction,”Mach. Learn. Sci. Technol., vol. 6, no. 2, p. 020501, 30 Jun. 2025
2025
-
[11]
MatSciBERT: A materials domain language model for text mining and information extraction,
T. Gupta, M. Zaki, N. M. A. Krishnanet al., “MatSciBERT: A materials domain language model for text mining and information extraction,”Npj Comput. Mater., vol. 8, no. 1, pp. 1–11, 3 May 2022
2022
-
[12]
Galactica: A Large Language Model for Science
R. Taylor, M. Kardas, G. Cucurullet al., “Galactica: A large language model for science,” arXiv [cs.CL], 16 Nov. 2022, arXiv:2211.09085
work page internal anchor Pith review arXiv 2022
-
[13]
Foundational large language models for materials research,
V. Mishra, S. Singh, D. Ahlawatet al., “Foundational large language models for materials research,”arXiv [cond-mat.mtrl-sci], 12 Dec. 2024, arXiv:2412.09560
-
[14]
Accurate, interpretable predictions of materials properties within transformer language models,
V. Korolev and P. Protsenko, “Accurate, interpretable predictions of materials properties within transformer language models,”Patterns (N. Y.), vol. 4, no. 10, p. 100803, 13 Oct. 2023
2023
-
[15]
Regression with Large Language Models for Materials and Molecular Property Prediction
R. Jacobs, M. P. Polak, L. E. Schultzet al., “Regression with large language models for materials and molecular property prediction,”arXiv [cond-mat.mtrl-sci], 9 Sep. 2024, arXiv:2409.06080
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Less can be more for predicting properties with large language models,
N. Alampara, S. Miret, and K. M. Jablonka, “Less can be more for predicting properties with large language models,”arXiv [cond-mat.mtrl-sci], 9 Jul. 2025, arXiv:2406.17295
-
[17]
Predicting materials properties without crystal structure: deep representation learning from stoichiometry,
R. E. A. Goodall and A. A. Lee, “Predicting materials properties without crystal structure: deep representation learning from stoichiometry,”Nat. Commun., vol. 11, no. 1, p. 6280, 8 Dec. 2020
2020
-
[18]
Compositionally restricted attention- based network for materials property predictions,
A. Y.-T. Wang, S. K. Kauwe, R. J. Murdocket al., “Compositionally restricted attention- based network for materials property predictions,”Npj Comput. Mater., vol. 7, no. 1, p. 77, 28 May 2021
2021
-
[19]
CrysMMNet: Multimodal representation for crystal prop- erty prediction,
K. Das, P. Goyal, S.-C. Leeet al., “CrysMMNet: Multimodal representation for crystal prop- erty prediction,” inUncertainty in Artificial Intelligence. PMLR, 2 Jul. 2023, pp. 507–517
2023
-
[20]
Large language models for material property predictions: elastic constant tensor prediction and materials design,
S. Liu, T. Wen, B. Yeet al., “Large language models for material property predictions: elastic constant tensor prediction and materials design,”Digit. Discov., vol. 4, no. 6, pp. 1625–1638, 2025. 12
2025
-
[21]
Fine-tuned language models generate stable inor- ganic materials as text,
N. Gruver, A. Sriram, A. Madottoet al., “Fine-tuned language models generate stable inor- ganic materials as text,”arXiv [cs.LG], 6 Feb. 2024, arXiv:2402.04379
-
[22]
Crystal structure generation with autore- gressive large language modeling,
L. M. Antunes, K. T. Butler, and R. Grau-Crespo, “Crystal structure generation with autore- gressive large language modeling,”Nat. Commun., vol. 15, no. 1, p. 10570, 6 Dec. 2024
2024
-
[23]
Materials property prediction with uncertainty quantification: A benchmark study,
D. Varivoda, R. Dong, S. S. Omeeet al., “Materials property prediction with uncertainty quantification: A benchmark study,”Appl. Phys. Rev., vol. 10, no. 2, p. 021409, 1 Jun. 2023
2023
-
[24]
Ensemble methods in machine learning,
T. G. Dietterich, “Ensemble methods in machine learning,” inMultiple Classifier Systems, ser. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer Berlin Heidelberg, 2000, pp. 1–15
2000
-
[25]
R. Seoh, “Qualitative analysis of monte carlo dropout,”arXiv [stat.ML], 3 Jul. 2020, arXiv:2007.01720
-
[26]
Deep evidential regression,
A. Amini, W. Schwarting, A. Soleimanyet al., “Deep evidential regression,”Advances in Neural Information Processing Systems, vol. 33, pp. 14 927–14 937, 2020
2020
-
[27]
Uncertainty sets for image classifiers using conformal prediction.arXiv:2009.14193,
A. Angelopoulos, S. Bates, J. Maliket al., “Uncertainty sets for image classifiers using confor- mal prediction,”arXiv [cs.CV], 29 Sep. 2020, arXiv:2009.14193
-
[28]
Materials property prediction with uncertainty quantification: A benchmark study,
D. Varivoda, R. Dong, S. S. Omeeet al., “Materials property prediction with uncertainty quantification: A benchmark study,”arXiv [cond-mat.mtrl-sci], 3 Nov. 2022, arXiv:2211.02235
-
[29]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieskeet al., “Survey of hallucination in natural language generation,”ACM Comput. Surv., 17 Nov. 2022
2022
-
[30]
A survey of confidence estimation and calibration in large language models,
J. Geng, F. Cai, Y. Wanget al., “A survey of confidence estimation and calibration in large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg, PA, USA: Association for Computational Linguistics, 2024, pp. 6577–6595
2024
-
[31]
Benchmarking uncertainty quantification meth- ods for large language models with LM-polygraph,
R. Vashurin, E. Fadeeva, A. Vazhentsevet al., “Benchmarking uncertainty quantification meth- ods for large language models with LM-polygraph,”Trans. Assoc. Comput. Linguist., vol. 13, pp. 220–248, 19 Mar. 2025
2025
-
[32]
Leveraging language representation for materials exploration and discovery,
J. Qu, Y. R. Xie, K. M. Ciesielskiet al., “Leveraging language representation for materials exploration and discovery,”Npj Comput. Mater., vol. 10, no. 1, p. 58, 21 Mar. 2024
2024
-
[33]
AtomGPT: Atomistic generative pretrained transformer for forward and in- verse materials design,
K. Choudhary, “AtomGPT: Atomistic generative pretrained transformer for forward and in- verse materials design,”J. Phys. Chem. Lett., vol. 15, no. 27, pp. 6909–6917, 11 Jul. 2024
2024
-
[34]
Accelerated data-driven materials science with the materials project,
M. K. Horton, P. Huck, R. X. Yanget al., “Accelerated data-driven materials science with the materials project,”Nat. Mater., vol. 24, no. 10, pp. 1522–1532, 3 Oct. 2025
2025
-
[35]
Robocrystallographer: automated crystal structure text descrip- tions and analysis,
A. M. Ganose and A. Jain, “Robocrystallographer: automated crystal structure text descrip- tions and analysis,”MRS Commun., vol. 9, no. 3, pp. 874–881, 20 Sep. 2019
2019
-
[36]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y. Shen, P. Walliset al., “LoRA: Low-rank adaptation of large language models,” arXiv [cs.CL], 17 Jun. 2021, arXiv:2106.09685. 13
work page internal anchor Pith review arXiv 2021
-
[37]
T. Xie and J. C. Grossman, “Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties,”arXiv [cond-mat.mtrl-sci], 27 Oct. 2017, arXiv:1710.10324
-
[38]
Obtaining well calibrated probabilities using bayesian binning,
M. Pakdaman Naeini, G. Cooper, and M. Hauskrecht, “Obtaining well calibrated probabilities using bayesian binning,”Proc. Conf. AAAI Artif. Intell., vol. 29, no. 1, 21 Feb. 2015
2015
-
[39]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y. Sunet al., “On calibration of modern neural networks,”arXiv [cs.LG], 14 Jun. 2017, arXiv:1706.04599
-
[40]
The art of abstention: Selective prediction and error reg- ularization for natural language processing,
J. Xin, R. Tang, Y. Yuet al., “The art of abstention: Selective prediction and error reg- ularization for natural language processing,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA, USA: Associati...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.