Recognition: unknown
A Few-Step Generative Model on Cumulative Flow Maps
Pith reviewed 2026-05-07 17:00 UTC · model grok-4.3
The pith
Cumulative flow maps let existing diffusion and flow models generate samples in one or few steps without losing quality or adding model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A cumulative-flow abstraction connects local instantaneous updates with finite-time transport in probability space, yielding a unified few-step framework built on cumulative transport and cumulative parameterization. The framework applies to existing diffusion- and flow-based models without being tied to a specific prediction instantiation, supports one-step generation while preserving synthesis quality, and requires only minimal changes to time embeddings and training objectives with no increase in model capacity.
What carries the argument
The cumulative-flow abstraction, which connects local instantaneous updates with finite-time transport in probability space and enables models to reason about global state transitions through cumulative parameterization.
If this is right
- Diffusion and flow models can be converted to few-step or one-step generators with only small changes to their time embeddings and loss functions.
- Generation quality stays comparable to multi-step baselines while inference cost drops substantially.
- The same abstraction works across image synthesis, geometric distribution modeling, joint prediction, and SDF generation tasks.
- No extra model parameters are needed to achieve the speedup.
Where Pith is reading between the lines
- The approach could make high-quality generative sampling feasible on devices with limited compute by cutting the number of required network evaluations.
- Similar cumulative abstractions might simplify other iterative refinement processes in machine learning beyond generative modeling.
- If the connection between local updates and global transport holds, it could guide the design of new training objectives that directly optimize for long-range consistency.
Load-bearing premise
The cumulative-flow abstraction must reliably connect local instantaneous updates to finite-time transport in probability space so that small changes to embeddings and objectives alone preserve quality without extra model capacity or task-specific tuning.
What would settle it
Take a standard diffusion model, apply the cumulative parameterization with only the claimed minimal embedding and objective adjustments, and observe whether sample quality drops sharply or requires major retraining to recover when generating in one or two steps.
Figures





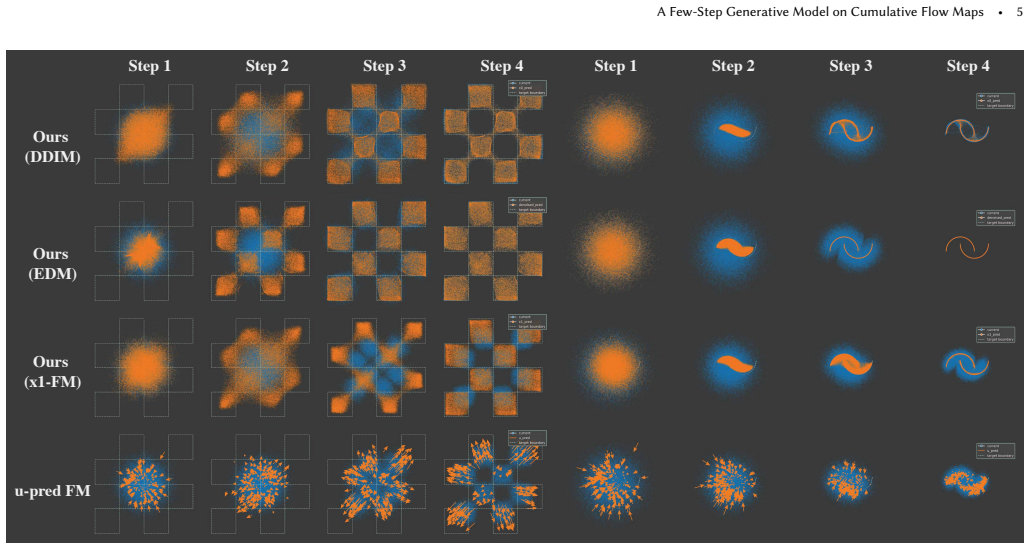
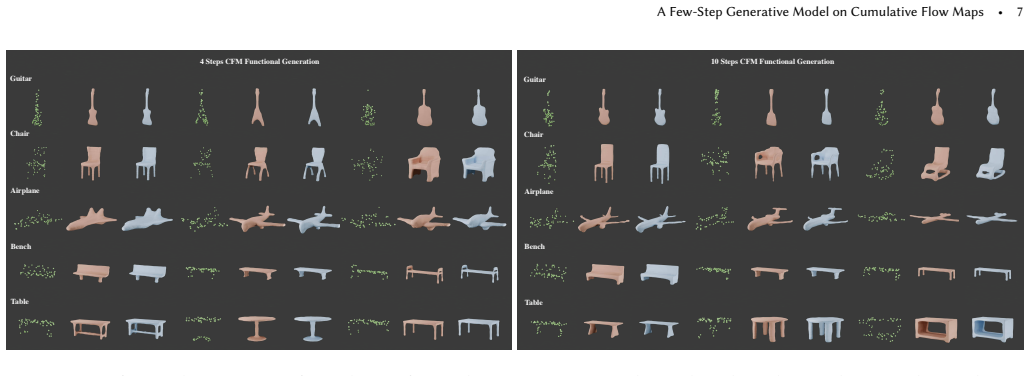





read the original abstract
We propose a unified, few-step generative modeling framework based on \emph{cumulative flow maps} for long-range transport in probability space, inspired by flow-map techniques for physical transport and dynamics. At its core is a cumulative-flow abstraction that connects local, instantaneous updates with finite-time transport, enabling generative models to reason about global state transitions. This perspective yields a unified few-step framework built on cumulative transport and \revise{cumulative} parameterization that applies broadly to existing diffusion- and flow-based models without being tied to a specific prediction \revise{instantiation}. Our formulation supports few-step and even one-step generation while preserving synthesis quality, requiring only minimal changes to time embeddings and training objectives, and no increase in model capacity. We demonstrate its effectiveness across diverse tasks, including image generation, geometric distribution modeling, joint prediction, and SDF generation, with reduced inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified few-step generative modeling framework based on cumulative flow maps for long-range transport in probability space. It introduces a cumulative-flow abstraction that connects local instantaneous updates to finite-time transport, enabling adaptation of existing diffusion- and flow-based models via cumulative transport and parameterization. The approach claims to support few-step and one-step generation while preserving synthesis quality, requiring only minimal changes to time embeddings and training objectives with no increase in model capacity, and demonstrates effectiveness on image generation, geometric distribution modeling, joint prediction, and SDF generation.
Significance. If the central claims hold, the work could be significant for providing a general, low-overhead method to accelerate inference in generative models across diffusion and flow paradigms without architectural modifications. The unified perspective on cumulative parameterization might facilitate broader adoption of efficient sampling in tasks like image synthesis and geometric modeling. The paper earns credit for claiming broad applicability across heterogeneous tasks and emphasizing minimal implementation changes, though the significance hinges on rigorous validation of the abstraction's ability to preserve quality without implicit capacity demands.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The claim that the cumulative parameterization 'applies broadly to existing diffusion- and flow-based models without being tied to a specific prediction instantiation' and enables quality preservation 'requiring only minimal changes to time embeddings and training objectives' with 'no increase in model capacity' is load-bearing for the central contribution; this needs explicit derivation showing how the abstraction connects local updates to finite-time transport without implicitly requiring additional expressivity or discretization adjustments for one-step sampling.
- [§5] §5 (experiments): The demonstrations across tasks (image generation, geometric distributions, joint prediction, SDF) must include ablations and quantitative metrics (e.g., FID, error rates) comparing the adapted models to unmodified baselines at identical capacity to substantiate that synthesis quality is preserved without post-hoc tuning or hidden capacity increases, particularly for the one-step case.
minor comments (2)
- [§2] Notation for 'cumulative flow maps' and 'cumulative parameterization' should be defined with explicit equations early in the method section to distinguish from standard flow-map or transport reparameterizations in prior work.
- [Figures and §5] Figure captions and experimental protocols should clarify the exact modifications made to time embeddings and objectives for each baseline model to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive feedback. We address each of the major comments below and have made revisions to the manuscript to incorporate the suggestions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The claim that the cumulative parameterization 'applies broadly to existing diffusion- and flow-based models without being tied to a specific prediction instantiation' and enables quality preservation 'requiring only minimal changes to time embeddings and training objectives' with 'no increase in model capacity' is load-bearing for the central contribution; this needs explicit derivation showing how the abstraction connects local updates to finite-time transport without implicitly requiring additional expressivity or discretization adjustments for one-step sampling.
Authors: We agree that an explicit derivation strengthens the presentation of the core contribution. In Section 3, the cumulative flow map is defined as the time-integrated transport map, connecting the instantaneous velocity field (as in standard flow or diffusion models) to the finite-time displacement. By reparameterizing the model to directly predict this cumulative map—via a simple adjustment to the time embedding (using integrated time steps) and the training objective (matching the cumulative displacement)—the same network architecture is used without any increase in capacity or additional discretization. This applies to both diffusion (by adapting the noise schedule to cumulative) and flow models. We will expand the derivation in the revised manuscript with additional intermediate steps and a diagram to clarify the connection for one-step sampling. revision: yes
-
Referee: [§5] §5 (experiments): The demonstrations across tasks (image generation, geometric distributions, joint prediction, SDF) must include ablations and quantitative metrics (e.g., FID, error rates) comparing the adapted models to unmodified baselines at identical capacity to substantiate that synthesis quality is preserved without post-hoc tuning or hidden capacity increases, particularly for the one-step case.
Authors: We acknowledge the importance of direct comparisons to unmodified baselines. The current experiments demonstrate the effectiveness of the cumulative parameterization across tasks with reduced inference steps, but to further substantiate the claims, we will add ablations in the revised version. These will include quantitative metrics such as FID for image generation tasks and appropriate error rates for geometric modeling, joint prediction, and SDF generation. Comparisons will be made to the original models at identical capacity, focusing on one-step and few-step regimes, to confirm quality preservation without hidden modifications. revision: yes
Circularity Check
No significant circularity; cumulative-flow abstraction presented as independent re-framing
full rationale
The paper introduces cumulative flow maps as a new abstraction connecting local instantaneous updates to finite-time transport, yielding a unified few-step framework applicable to diffusion and flow models via minimal embedding and objective changes. No equations, self-citations, or derivations in the provided text reduce the claimed parameterization or predictions to prior fitted inputs by construction, nor do they rely on load-bearing self-citations or imported uniqueness theorems. The formulation is positioned as a perspective that supports one-step generation without capacity increases, with effectiveness shown across tasks, making the chain self-contained rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cumulative flow abstraction connects local instantaneous updates with finite-time transport in probability space
Reference graph
Works this paper leans on
-
[1]
Mean Flows for One-step Generative Modeling
Mean flows for one-step generative modeling , author=. arXiv preprint arXiv:2505.13447 , year=
work page internal anchor Pith review arXiv
-
[2]
Improved Mean Flows: On the Challenges of Fastforward Generative Models
Improved Mean Flows: On the Challenges of Fastforward Generative Models , author=. arXiv preprint arXiv:2512.02012 , year=
work page internal anchor Pith review arXiv
-
[3]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review arXiv
-
[4]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review arXiv 2010
-
[5]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review arXiv 2011
-
[6]
Flow matching in latent space.arXiv preprint arXiv:2307.08698,
Flow matching in latent space , author=. arXiv preprint arXiv:2307.08698 , year=
-
[7]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[8]
Pseudo numerical methods for diffusion models on manifolds
Pseudo numerical methods for diffusion models on manifolds , author=. arXiv preprint arXiv:2202.09778 , year=
-
[9]
2022 , howpublished =
Diffusers: State-of-the-art diffusion models , author =. 2022 , howpublished =
2022
-
[10]
Back to Basics: Let Denoising Generative Models Denoise
Back to basics: Let denoising generative models denoise , author=. arXiv preprint arXiv:2511.13720 , year=
work page internal anchor Pith review arXiv
-
[11]
Consistency models made easy , author=. arXiv preprint arXiv:2406.14548 , year=
-
[12]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[13]
ACM Transactions on Graphics (TOG) , volume=
Dress-1-to-3: Single Image to Simulation-Ready 3D Outfit with Diffusion Prior and Differentiable Physics , author=. ACM Transactions on Graphics (TOG) , volume=. 2025 , publisher=
2025
-
[14]
International Conference on Learning Representations (ICLR) , year=
Progressive Distillation for Fast Sampling of Diffusion Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[15]
Neural Information Processing Systems (NeurIPS) , year=
One-Step Diffusion Distillation via Deep Equilibrium Models , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[16]
2024 , booktitle =
Sauer, Axel and Lorenz, Dominik and Blattmann, Andreas and Rombach, Robin , title =. 2024 , booktitle =
2024
-
[17]
Neural Information Processing Systems (NeurIPS) , year=
Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[18]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
One-step Diffusion with Distribution Matching Distillation , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[19]
2024 , booktitle=
Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation , author=. 2024 , booktitle=
2024
-
[20]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
On distillation of guided diffusion models , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[21]
International Conference on Learning Representations (ICLR) , year=
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
International Conference on Learning Representations (ICLR) , year=
One Step Diffusion via Shortcut Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
International Conference on Learning Representations (ICLR) , year=
Flow straight and fast: Learning to generate and transfer data with rectified flow , author=. International Conference on Learning Representations (ICLR) , year=
-
[24]
International Conference on Machine Learning (ICML) , year=
Inductive Moment Matching , author=. International Conference on Machine Learning (ICML) , year=
-
[25]
Transactions on Machine Learning Research (TMLR) , year=
Flow map matching with stochastic interpolants: A mathematical framework for consistency models , author=. Transactions on Machine Learning Research (TMLR) , year=
-
[26]
arXiv preprint arXiv:2502.15681 , year=
One-step Diffusion Models with f -Divergence Distribution Matching , author=. arXiv preprint arXiv:2502.15681 , year=
-
[27]
International Conference on Machine Learning (ICML) , year=
Consistency Models , author=. International Conference on Machine Learning (ICML) , year=
-
[28]
International Conference on Learning Representations (ICLR) , year=
Improved techniques for training consistency models , author=. International Conference on Learning Representations (ICLR) , year=
-
[29]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
Animax: Animating the inanimate in 3d with joint video-pose diffusion models , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[30]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
Artalk: Speech-driven 3d head animation via autoregressive model , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[31]
Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
Renderformer: Transformer-based neural rendering of triangle meshes with global illumination , author=. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
-
[32]
Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
Duetgen: Music driven two-person dance generation via hierarchical masked modeling , author=. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
-
[33]
Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
Octgpt: Octree-based multiscale autoregressive models for 3d shape generation , author=. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
-
[34]
ACM Transactions on Graphics (TOG) , volume=
Cast: Component-aligned 3d scene reconstruction from an rgb image , author=. ACM Transactions on Graphics (TOG) , volume=. 2025 , publisher=
2025
-
[35]
2025 , eprint=
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details , author=. 2025 , eprint=
2025
-
[36]
Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging , author=. arXiv preprint arXiv:2503.22236 , volume=
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
VGGT: Visual Geometry Grounded Transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[38]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
PAD3R: Pose-Aware Dynamic 3D Reconstruction from Casual Videos , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[39]
Advances in Neural Information Processing Systems , volume=
Lion: Latent point diffusion models for 3d shape generation , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Diffusion probabilistic models for 3d point cloud generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Pointflow: 3d point cloud generation with continuous normalizing flows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[42]
International conference on machine learning , pages=
Learning representations and generative models for 3d point clouds , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[43]
arXiv preprint arXiv:2510.05613 , year=
PointNSP: Autoregressive 3D Point Cloud Generation with Next-Scale Level-of-Detail Prediction , author=. arXiv preprint arXiv:2510.05613 , year=
-
[44]
ACM Transactions on graphics (TOG) , volume=
Automatic rigging and animation of 3d characters , author=. ACM Transactions on graphics (TOG) , volume=. 2007 , publisher=
2007
-
[45]
2019 international conference on 3D vision (3DV) , pages=
Predicting animation skeletons for 3d articulated models via volumetric nets , author=. 2019 international conference on 3D vision (3DV) , pages=. 2019 , organization=
2019
-
[46]
European Conference on Computer Vision , pages=
Learning gradient fields for shape generation , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[47]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
3d shape generation and completion through point-voxel diffusion , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
TIGER: Time-varying denoising model for 3D point cloud generation with diffusion process , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
, author=
Octree-based Point-Cloud Compression. , author=. PBG@ SIGGRAPH , volume=
-
[50]
Advances in neural information processing systems , volume=
Implicit neural representations with periodic activation functions , author=. Advances in neural information processing systems , volume=
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deepsdf: Learning continuous signed distance functions for shape representation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Occupancy networks: Learning 3d reconstruction in function space , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Neural geometric level of detail: Real-time rendering with implicit 3d shapes , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[54]
ACM transactions on graphics (TOG) , volume=
Instant neural graphics primitives with a multiresolution hash encoding , author=. ACM transactions on graphics (TOG) , volume=. 2022 , publisher=
2022
-
[55]
Pixelflow: Pixel-space generative models with flow.arXiv preprint arXiv:2504.07963, 2025
PixelFlow: Pixel-Space Generative Models with Flow , author=. arXiv preprint arXiv:2504.07963 , year=
-
[56]
Flow matching guide and code , author=. arXiv preprint arXiv:2412.06264 , year=
work page internal anchor Pith review arXiv
-
[57]
Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , series =
Arar, Ellie and Frenkel, Yarden and Cohen-Or, Daniel and Shamir, Ariel and Vinker, Yael , title =. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , series =. 2025 , publisher =
2025
-
[58]
and Simoncelli, E.P
Wang, Z. and Simoncelli, E.P. and Bovik, A.C. , booktitle=. Multiscale structural similarity for image quality assessment , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Advances in neural information processing systems , volume=
Video diffusion models , author=. Advances in neural information processing systems , volume=
-
[61]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Geometry distributions , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Functional diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[63]
ACM Transactions On Graphics (TOG) , volume=
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models , author=. ACM Transactions On Graphics (TOG) , volume=. 2023 , publisher=
2023
-
[64]
Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
PDT: Point Distribution Transformation with Diffusion Models , author=. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
-
[65]
Advances in neural information processing systems , volume=
Dit-3d: Exploring plain diffusion transformers for 3d shape generation , author=. Advances in neural information processing systems , volume=
-
[66]
arXiv preprint arXiv:2505.13316 , year=
Denoising Diffusion Probabilistic Model for Point Cloud Compression at Low Bit-Rates , author=. arXiv preprint arXiv:2505.13316 , year=
-
[67]
ACM Trans
RigNet: Neural Rigging for Articulated Characters , author=. ACM Trans. on Graphics , year=
-
[68]
Advances in neural information processing systems , volume=
Point-voxel cnn for efficient 3d deep learning , author=. Advances in neural information processing systems , volume=
-
[69]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[70]
Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
Diffusion as shader: 3d-aware video diffusion for versatile video generation control , author=. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
-
[71]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Progressive growing of gans for improved quality, stability, and variation , author=. arXiv preprint arXiv:1710.10196 , year=
work page internal anchor Pith review arXiv
-
[72]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[73]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[74]
2007 , school=
HOLA: a high-order Lie advection of discrete differential forms with applications in Fluid Dynamics , author=. 2007 , school=
2007
-
[75]
ACM Transactions on Graphics (TOG) , volume=
Solid-Fluid Interaction on Particle Flow Maps , author=. ACM Transactions on Graphics (TOG) , volume=. 2024 , publisher=
2024
-
[76]
arXiv preprint arXiv:2409.06246 , year=
Particle-Laden Fluid on Flow Maps , author=. arXiv preprint arXiv:2409.06246 , year=
-
[77]
Water Resources Research , volume=
Numerical predictions of two-dimensional transient groundwater flow by the method of characteristics , author=. Water Resources Research , volume=. 1976 , publisher=
1976
-
[78]
Computer Graphics International Workshop on VFX, Computer Animation, and Stereo Movies
The characteristic map for fast and efficient vfx fluid simulations , author=. Computer Graphics International Workshop on VFX, Computer Animation, and Stereo Movies. Ottawa, Canada , year=
-
[79]
Computational Visual Media , volume=
Spatially adaptive long-term semi-Lagrangian method for accurate velocity advection , author=. Computational Visual Media , volume=. 2018 , publisher=
2018
-
[80]
ACM SIGGRAPH 2005 Posters , pages=
Combined Lagrangian-Eulerian approach for accurate advection , author=. ACM SIGGRAPH 2005 Posters , pages=
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.