Recognition: unknown
Information Plane Analysis of Binary Neural Networks
Pith reviewed 2026-05-07 16:51 UTC · model grok-4.3
The pith
Binary neural networks show frequent late-stage compression in their information planes, yet this does not reliably improve generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
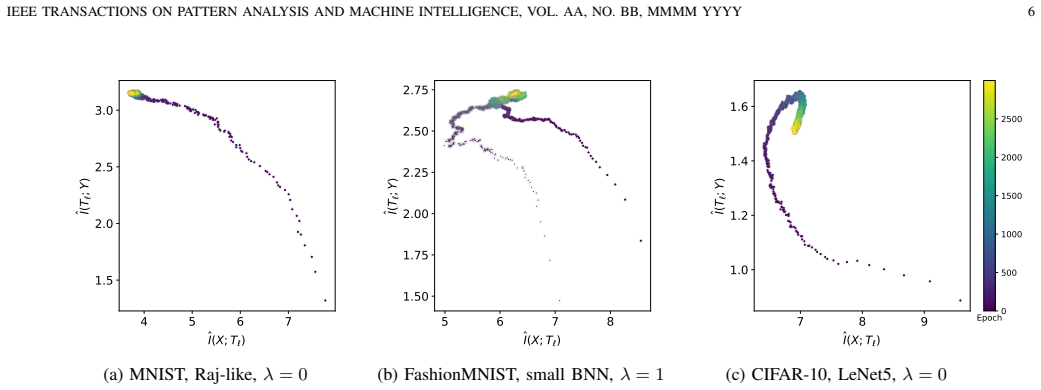
Restricting analysis to regimes where mutual information estimates from binary activations remain reliable, experiments with 375 binary neural networks show that late-stage compression in the information plane occurs frequently, yet compressed representations do not consistently correlate with improved generalization performance; the relationship instead depends strongly on task, architecture, and regularization.
What carries the argument
Plug-in mutual information estimator applied to discrete binary activations, with identified regimes of sample size N and dimension D that keep estimates below saturation at log2 N.
If this is right
- Late-stage compression phases appear often during training of binary neural networks.
- Compressed latent representations in the information plane do not produce better generalization in every setting.
- The compression-generalization link changes with the chosen task, network architecture, and regularization method.
Where Pith is reading between the lines
- If better estimators become available, similar information-plane checks could be applied to ordinary real-valued networks.
- The strong dependence on regularization hints that compression may be an artifact of particular training choices rather than a universal training principle.
- Model selection routines that reward compression should be tested separately for each task and architecture before adoption.
Load-bearing premise
The plug-in estimator's finite-sample bias depends only on sample size and representation dimension without further assumptions on the data distribution or training dynamics.
What would settle it
Observing mutual information values that stay well below log2 N for sample sizes and dimensions outside the claimed reliable regimes, or finding a single task-architecture-regularization combination where late compression consistently predicts higher test accuracy.
Figures



read the original abstract
Information plane (IP) analysis has been suggested to study the training dynamics of deep neural networks through mutual information (MI) between inputs, representations, and targets. However, its statistical validity is often compromised by the difficulty of estimating MI from samples of high-dimensional, deterministic representations. In this work, we perform IP analyses on binary neural networks (BNNs) where activations are discrete and MI is finite. We characterise the finite-sample behaviour of the plug-in entropy estimator and identify regimes for sample size $N$ and representation dimensionality $D$ under which MI estimates are reliable. Outside these regimes, we show that empirical MI estimates saturate to $\log_2 N$, rendering IP trajectories uninformative. Restricting attention to the reliable regime, we train 375 BNNs to investigate the existence of late-stage compression phases and the relationship between compressed representations and generalisation performance. Our results show that while late-stage compression is frequently observed, compressed latent representations do not consistently correlate with improved generalization performance. Instead, the relationship between compression and generalisation is highly dependent on task, architecture, and regularisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs information plane analysis on binary neural networks (BNNs) with discrete activations, where mutual information is finite. It characterizes the finite-sample behavior of the plug-in entropy estimator to identify regimes of sample size N and representation dimensionality D under which MI estimates are reliable; outside these, estimates saturate to log2 N. Restricting to reliable regimes, the authors train 375 BNNs and report that late-stage compression is frequently observed, but compressed latent representations do not consistently correlate with improved generalization performance; the relationship depends on task, architecture, and regularization.
Significance. If the regime characterization is robust, the work provides a useful cautionary result for IP analyses in deep learning by showing that apparent compression can be an estimator artifact. The empirical finding that compression is common yet uncorrelated with generalization (in a controlled BNN setting) challenges assumptions in the literature about the role of compression phases.
major comments (1)
- [Section characterizing finite-sample behaviour of the plug-in estimator] The identification of reliable MI regimes is performed as a function of N and D alone (see the section characterizing finite-sample behaviour of the plug-in estimator). For binary activations the plug-in estimator bias depends on the specific probability mass function over the 2^D patterns; these masses are determined by the input data distribution and the weights reached during training. The manuscript does not demonstrate that regime boundaries are insensitive to these factors, so trajectories currently treated as reliable may still be biased toward log2 N saturation. This directly affects the central claim that late-stage compression is frequently observed yet uncorrelated with generalization.
minor comments (1)
- [Abstract] The abstract states that 375 BNNs were trained but provides no summary table or description of the distribution over architectures, tasks, and regularization strengths; this makes it difficult to assess how representative the 'highly dependent' conclusion is.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting an important statistical consideration in our analysis of the plug-in estimator. We address the major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Section characterizing finite-sample behaviour of the plug-in estimator] The identification of reliable MI regimes is performed as a function of N and D alone (see the section characterizing finite-sample behaviour of the plug-in estimator). For binary activations the plug-in estimator bias depends on the specific probability mass function over the 2^D patterns; these masses are determined by the input data distribution and the weights reached during training. The manuscript does not demonstrate that regime boundaries are insensitive to these factors, so trajectories currently treated as reliable may still be biased toward log2 N saturation. This directly affects the central claim that late-stage compression is frequently observed yet uncorrelated with generalization.
Authors: We agree that the finite-sample bias of the plug-in entropy estimator for binary representations depends on the specific PMF over the 2^D patterns and is therefore influenced by the input distribution and the weights learned during training. Our characterization combined theoretical bounds (derived under the worst-case uniform distribution to obtain conservative regime limits) with empirical simulations on synthetic binary patterns. While these steps provide a practical guide for reliable estimation, we did not explicitly verify that the identified (N, D) boundaries remain stable under the exact empirical PMFs arising in trained BNNs. To resolve this, we will add an appendix containing additional experiments that (i) extract the observed activation histograms from the 375 trained networks and (ii) re-evaluate estimator behavior under those distributions. The revised manuscript will report that the regime boundaries shift only marginally, thereby confirming that the trajectories we classified as reliable are not subject to log2 N saturation. This addition will directly bolster the central empirical claim that late-stage compression is common yet does not consistently correlate with generalization performance. revision: yes
Circularity Check
No significant circularity in empirical IP analysis of BNNs
full rationale
The paper's derivation chain consists of an empirical characterization of the plug-in estimator's finite-sample behavior (saturation to log2 N when N << 2^D follows directly from counting distinct samples in the estimator definition) followed by direct observations on 375 trained BNNs within the identified reliable regimes. No load-bearing step reduces to a self-definition, fitted input renamed as prediction, or self-citation chain; the central claims on late-stage compression frequency and its task-dependent relation to generalization are standalone experimental results without imported uniqueness theorems or ansatzes. The work is self-contained as an empirical investigation.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Mutual information between discrete random variables is finite and can be estimated via the plug-in entropy estimator.
- domain assumption The finite-sample behaviour of the plug-in estimator is fully characterised by regimes of N and D.
Reference graph
Works this paper leans on
-
[1]
Opening the Black Box of Deep Neural Networks via Information
R. Shwartz-Ziv and N. Tishby, “Opening the black box of deep neural networks via information,”arXiv:1703.00810 [cs.LG], Mar. 2017
work page Pith review arXiv 2017
-
[2]
On Information Plane Analyses of Neural Network Classifiers—A Review,
B. C. Geiger, “On Information Plane Analyses of Neural Network Classifiers—A Review,”IEEE Trans. Neural Netw. Learn. Syst., vol. 33, no. 12, pp. 7039–7051, Dec. 2022
2022
-
[3]
Information bottleneck: Exact analysis of (quantized) neural networks,
S. S. Lorenzen, C. Igel, and M. Nielsen, “Information bottleneck: Exact analysis of (quantized) neural networks,”arXiv:2106.12912 [cs.LG], Jun. 2021
-
[4]
On the information bottleneck theory of deep learning,
A. M. Saxe, Y . Bansal, J. Dapello, M. Advani, A. Kolchinsky, B. D. Tracey, and D. D. Cox, “On the information bottleneck theory of deep learning,”Journal of Statistical Mechanics: Theory and Experiment, vol. 2019, no. 12, p. 124020, Dec. 2019. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. AA, NO. BB, MMMM YYYY 8
2019
-
[5]
R. A. Amjad and B. C. Geiger, “Learning representations for neural network-based classification using the information bottleneck principle,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 9, pp. 2225–2239, Sep. 2020, open-access:arXiv:1802.09766 [cs.LG]
-
[6]
Estimating information flow in deep neural networks,
Z. Goldfeld, E. Van Den Berg, K. Greenewald, I. Melnyk, N. Nguyen, B. Kingsbury, and Y . Polyanskiy, “Estimating information flow in deep neural networks,” pp. 2299–2308, Jun. 2019
2019
-
[7]
BinaryConnect: Training Deep Neural Networks with binary weights during propagations,
M. Courbariaux, Y . Bengio, and J.-P. David, “BinaryConnect: Training Deep Neural Networks with binary weights during propagations,” in Proc. Advances in Neural Information Processing Systems, 2015
2015
-
[8]
Quantized Neural Networks: Training Neural Networks with Low Pre- cision Weights and Activations,
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y . Bengio, “Quantized Neural Networks: Training Neural Networks with Low Pre- cision Weights and Activations,”Journal of Machine Learning Research, vol. 18, no. 187, pp. 1–30, 2018
2018
-
[9]
Convergence properties of functional estimates for discrete distributions,
A. Antos and I. Kontoyiannis, “Convergence properties of functional estimates for discrete distributions,”Random Structures & Algorithms, vol. 19, no. 3-4, pp. 163–193, Oct. 2001
2001
-
[10]
Markov Information Bottleneck to Improve Information Flow in Stochastic Neural Networks,
T. Nguyen-Tang and J. Choi, “Markov Information Bottleneck to Improve Information Flow in Stochastic Neural Networks,”Entropy, vol. 21, no. 10, p. 976, Oct. 2019
2019
-
[11]
Understanding learning dy- namics of binary neural networks via information bottleneck,
V . Raj, N. Nayak, and S. Kalyani, “Understanding learning dy- namics of binary neural networks via information bottleneck,” arXiv:2006.07522 [cs.LG], Jun. 2020
-
[12]
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference,” inProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2018, pp. 2704–2713
2018
-
[13]
Neural Networks for Machine Learning,
G. Hinton, “Neural Networks for Machine Learning,” University of Toronto, 2012
2012
-
[14]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation,” Aug. 2013,arXiv:1308.3432 [cs]
work page internal anchor Pith review arXiv 2013
-
[15]
Minimax rates of entropy estimation on large alphabets via best polynomial approximation,
Y . Wu and P. Yang, “Minimax rates of entropy estimation on large alphabets via best polynomial approximation,”IEEE Trans. Inf. Theory, vol. 62, no. 6, pp. 3702–3720, 2016
2016
-
[16]
Estimation of Entropy and Mutual Information,
L. Paninski, “Estimation of Entropy and Mutual Information,”Neural Computation, vol. 15, no. 6, pp. 1191–1253, Jun. 2003
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.