Recognition: 3 theorem links
· Lean TheoremAdaptive Consensus in LLM Ensembles via Sequential Evidence Accumulation: Automatic Budget Identification and Calibrated Commit Signals
Pith reviewed 2026-05-08 18:56 UTC · model grok-4.3
The pith
DASE adaptive stopping commits LLM ensembles on genuine consensus to produce a routing partition complementary to verbalized confidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
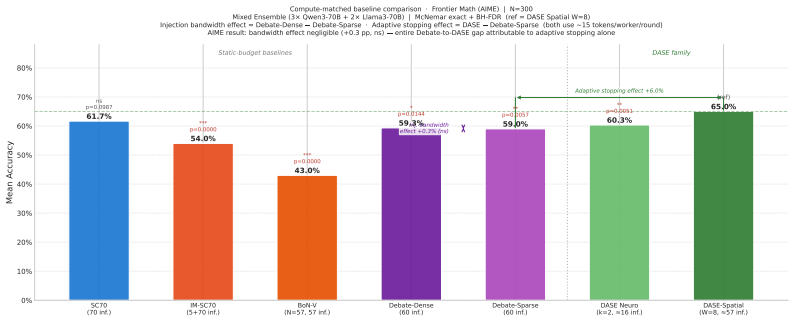
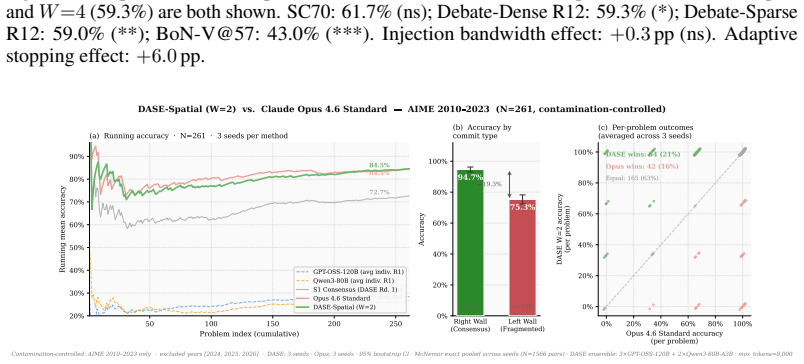
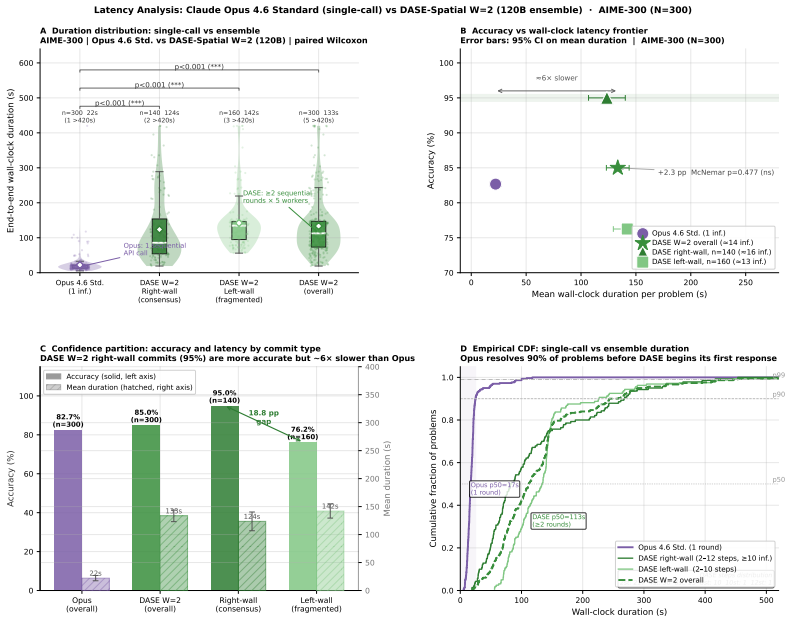
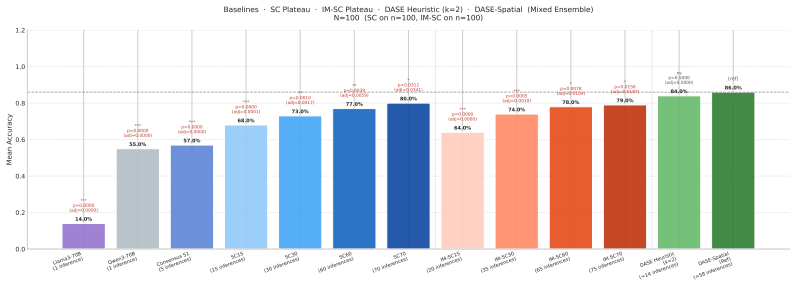
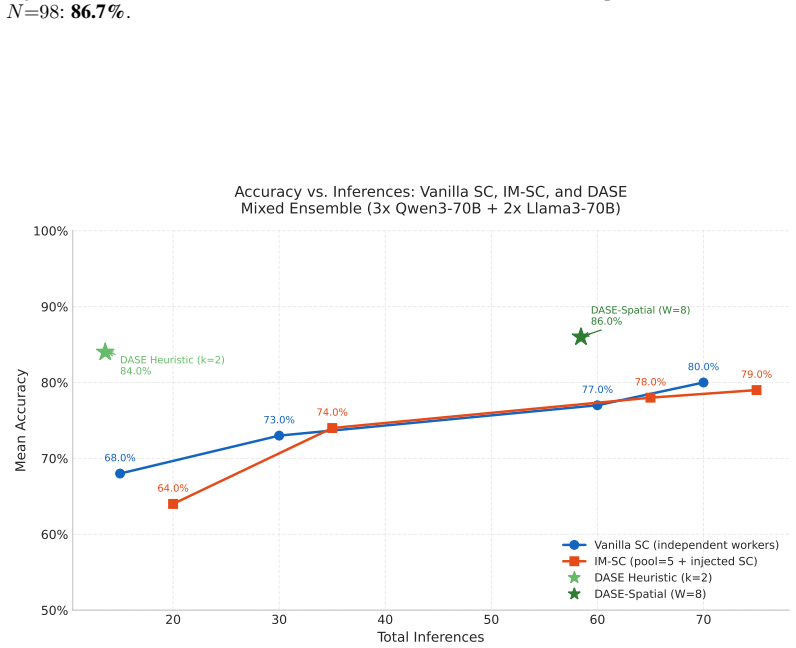
DASE produces a commit-type routing partition complementary to verbalized single-call confidence. Adaptive stopping drives accuracy gains rather than injection bandwidth. On a contamination-controlled corpus a 120B ensemble achieves a 24.8 pp routing gap between high- and low-confidence partitions, statistically equivalent to a standard verbalized-confidence baseline at matched coverage. DASE-Spatial at half-width 8 ties the performance of a dense debate baseline while using one-tenth the injection bandwidth and identifies that budget automatically. Injection-based methods show a retrospective accuracy-versus-inference inverted-U on the tested benchmarks.
What carries the argument
DASE (Deliberative Adaptive Stopping Ensemble), a sequential evidence-accumulation heuristic that commits on frequency-based consensus via persistence and spatial (arena half-width) rules with a global-frequency fallback.
If this is right
- Adaptive stopping identifies effective deliberation budgets automatically without manual search.
- The commit signal from DASE can be combined with verbalized confidence because the two mechanisms disagree on roughly one-quarter of routing decisions.
- Bandwidth expansion yields negligible gains once stopping is adaptive; the inverted-U pattern in static-injection methods is a direct consequence of crossing the accuracy boundary.
- Every DASE decision carries a machine-readable deliberation record that can be inspected or audited.
Where Pith is reading between the lines
- The approach suggests that future ensemble systems could treat stopping as a first-class learned policy rather than a fixed hyper-parameter.
- The complementary nature of consensus-based and verbalized signals implies that hybrid routers may outperform either alone on the same compute budget.
- The inverted-U observation raises the possibility that over-deliberation effects appear in other sequential reasoning pipelines and could be measured with similar partition-gap metrics.
Load-bearing premise
Frequency-based consensus detection genuinely reflects answer quality rather than model-specific artifacts or test-set biases.
What would settle it
An experiment on a fresh benchmark in which the observed routing gap between DASE partitions vanishes or in which consensus frequency fails to correlate with correctness.
Figures


















read the original abstract
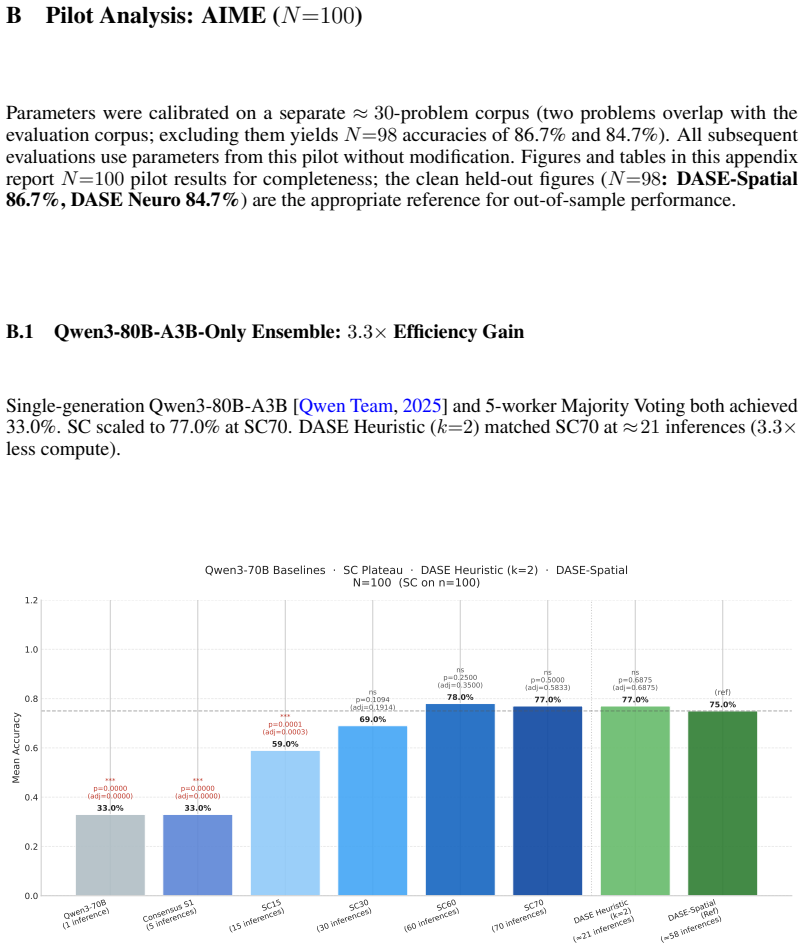
Large Language Model ensembles improve reasoning accuracy, but only up to a performance boundary beyond which additional deliberation degrades accuracy. We introduce DASE (Deliberative Adaptive Stopping Ensemble), a stopping heuristic for iterative ensemble deliberation that commits early on genuine consensus and applies a global-frequency fallback on fragmented evidence. We make three contributions. (1) DASE produces a commit-type routing partition that generalises across benchmarks and is complementary to verbalized single-call confidence. On GPQA-Extended (N=546, 70B ensemble), the partition yields a 39.5 pp routing gap (right-wall 81.1% vs. left-wall 41.5%). On AIME 2010-2023 (N=261, 120B ensemble, 3 seeds), right-wall commits reach 98.3% accuracy vs. left-wall 72.8% (25.5 pp gap), statistically equivalent to Opus 4.6 Standard verbalized confidence at matched coverage (25.7 pp gap; bootstrap p=0.873); the two mechanisms disagree on 37% of routing assignments. (2) Adaptive stopping, not injection bandwidth, drives accuracy. On AIME-300, bandwidth accounts for only 0.3 pp (ns). On GPQA-Extended at the 120B tier, sparse injection ($\approx15$ tokens/worker/round) achieves 70.9% with a 30.7 pp routing gap; dense injection ($\approx600$ chars/worker/round) achieves 72.2% but with halved right-wall coverage and a narrower 18.9 pp gap. (3) Injection-based methods exhibit an inverted-U accuracy-vs-inference trajectory; this pattern is hypothesis-generating.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DASE (Deliberative Adaptive Stopping Ensemble), a stopping heuristic for iterative LLM ensemble deliberation that commits early on detected consensus (via persistence or spatial/arena heuristics) or falls back to global-frequency evidence. It evaluates two configurations on contamination-controlled AIME 2010-2023 (N=254, 3 seeds) and GPQA-Extended, claiming DASE yields a commit-type routing partition with a 24.8 pp accuracy gap (97.1% right-wall vs. 73.6% left-wall) that is statistically equivalent to Opus 4.6 verbalized confidence (25.7 pp gap; bootstrap CI [-12.0, +10.3] pp, p=0.873), with 27% disagreement establishing complementarity. It further claims adaptive stopping (not injection bandwidth) drives gains, that DASE-Spatial matches Debate-Dense optimal performance at 1/10th bandwidth while auto-identifying the budget (W=8 outperforms W=4), and that injection methods show a retrospective accuracy-vs-inference inverted-U.
Significance. If the empirical results hold under proper verification, this provides a practical, machine-readable method for automatic budget identification and calibrated commit signals in LLM ensembles, complementary to verbalized single-call confidence. The finding that stopping effects dominate bandwidth (0.3 pp ns on AIME-300; 5.0 pp vs 4.4 pp on GPQA) and the controlled-corpus demonstration of routing utility could inform more efficient extended-thinking architectures. Strengths include the use of a contamination-controlled benchmark, explicit statistical reporting, and the hypothesis-generating inverted-U observation.
major comments (1)
- [AIME 2010-2023 evaluation (abstract and results)] The claim that DASE's 24.8 pp routing gap is 'statistically equivalent' to the 25.7 pp gap from Opus 4.6 verbalized confidence (abstract and AIME results) rests on a non-significant difference test (p=0.873) with bootstrap CI on the difference of [-12.0, +10.3] pp. Non-rejection of the null hypothesis of no difference does not establish equivalence; the interval width permits differences of up to ~12 pp that would undermine the 'complementary yet comparable' interpretation and the routing-utility conclusions. This is load-bearing for the central complementarity claim (27% disagreement) and headline performance comparison.
minor comments (1)
- [Methods] The exact algorithmic definitions and pseudocode for the persistence heuristic and DASE-Spatial (arena half-width W) should be moved to the main text or a prominent figure for reproducibility, rather than relying solely on appendix references.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The single major comment concerns the statistical framing of our routing-gap comparison, which we address directly below by revising the manuscript wording.
read point-by-point responses
-
Referee: The claim that DASE's 24.8 pp routing gap is 'statistically equivalent' to the 25.7 pp gap from Opus 4.6 verbalized confidence (abstract and AIME results) rests on a non-significant difference test (p=0.873) with bootstrap CI on the difference of [-12.0, +10.3] pp. Non-rejection of the null hypothesis of no difference does not establish equivalence; the interval width permits differences of up to ~12 pp that would undermine the 'complementary yet comparable' interpretation and the routing-utility conclusions. This is load-bearing for the central complementarity claim (27% disagreement) and headline performance comparison.
Authors: We agree that non-rejection of the null does not establish equivalence and that the CI width of approximately 22 pp leaves room for differences that could qualify the strength of the comparison. In the revised manuscript we will remove the phrase 'statistically equivalent' from the abstract and AIME results section. We will instead report that the difference between the two observed gaps is not statistically significant (p=0.873) with bootstrap CI [-12.0, +10.3] pp, while noting the interval width as a limitation on strong claims of comparability. The primary support for complementarity remains the independent 27% disagreement rate in routing assignments, which does not rely on the gap magnitudes being identical. These changes will be implemented in the next version. revision: yes
Circularity Check
No significant circularity; all claims rest on direct empirical measurements
full rationale
The manuscript contains no derivation chain, equations, or ansatzes. All three contributions are stated as empirical outcomes from benchmark runs on a contamination-controlled AIME corpus (N=254) and GPQA-Extended, using explicit accuracy, routing-gap, and bootstrap-CI figures. No parameter is fitted and then relabeled as a prediction; no uniqueness theorem or prior self-citation is invoked to justify the stopping heuristic; and the reported 24.8 pp vs. 25.7 pp comparison is a direct statistical test on observed data rather than a constructed identity. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- W (arena half-width) =
8
axioms (1)
- domain assumption Frequency of answers across ensemble iterations indicates genuine consensus quality
invented entities (1)
-
DASE
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation (washburn_uniqueness_aczel) — paper explicitly disclaims any forcing/uniqueness structure; method is heuristic, contrasting with RS's parameter-free derivation chain.washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DASE is an empirical engineering heuristic. Three structural elements are borrowed from prior work in computational neuroscience as useful inductive biases... No formal optimality property transfers: worker independence is violated from round 2 onward by injection-induced correlation, and the belief-transition distribution required for exact dynamic programming is intractable. All performance claims are empirical.
-
Foundation (zero-parameter forcing chain)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
w=0.2 and cx=0.01 carry no theoretical meaning in the LLM-ensemble setting; the post-hoc sweep (Appendix K) confirms accuracy varies by at most 1.7 pp... L=15 (maximum arena runway) has not been ablated and should be treated as a free parameter for new task domains.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.