Recognition: unknown
The Threshold Breakdown Point
Pith reviewed 2026-05-08 16:46 UTC · model grok-4.3
The pith
The threshold breakdown point is the smallest contamination fraction that forces an estimator past a chosen deviation level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We define the threshold breakdown point as the smallest contamination fraction needed to induce a prescribed deviation, and the finite sample m-sensitivity as the worst-case deviation that an estimator can incur after m observations are contaminated. We derive these measures for commonly used M-estimators, their standard errors and related test statistics. This allows us to extend the decision breakdown point to obtain general breakdown characterizations for hypothesis testing, and show how these notions correspond to finite sample counterparts of the power and level breakdown functions.
What carries the argument
The threshold breakdown point, which inverts the usual breakdown calculation by solving for the contamination fraction that produces a fixed deviation rather than solving for the deviation at a fixed contamination fraction.
If this is right
- If the threshold breakdown point for a target deviation is high, the estimator or test remains stable under moderate contamination.
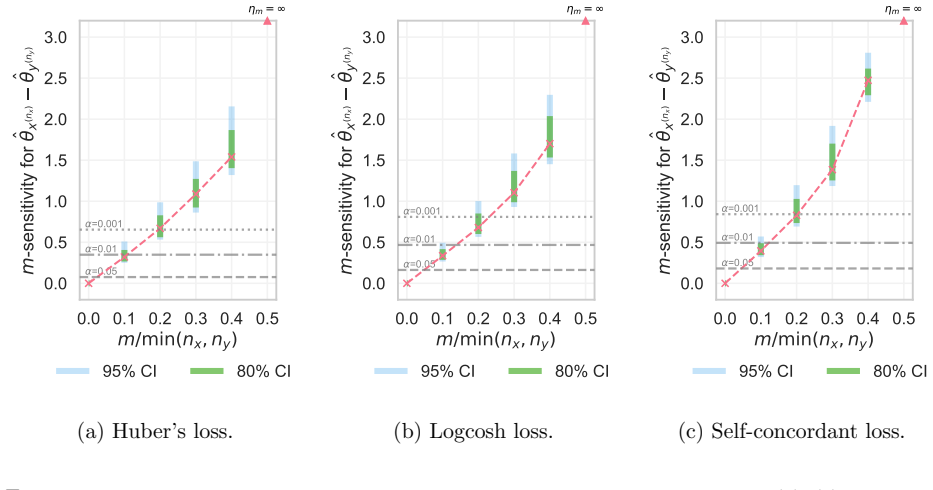
- The m-sensitivity supplies a direct finite-sample bound on how far an estimator can move when a known number of points are altered.
- The same machinery applies to standard errors and test statistics, giving breakdown characterizations for both point estimation and inference.
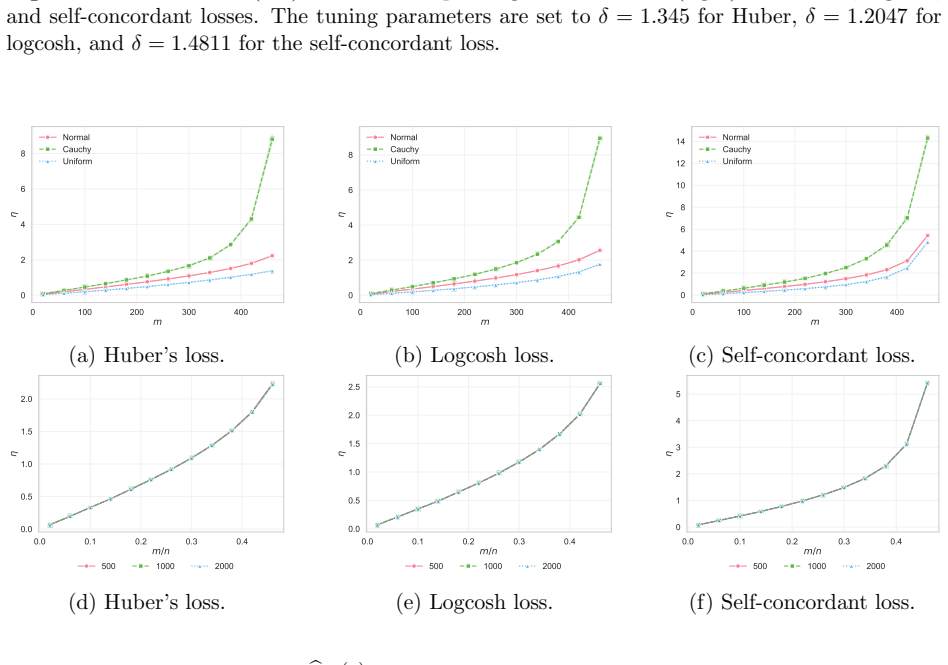
- The multiplier bootstrap yields consistent and asymptotically normal estimates of the threshold breakdown point and m-sensitivity, enabling uncertainty quantification in applications.
Where Pith is reading between the lines
- A plot of threshold breakdown points across a range of deviation levels would produce a graded robustness profile for any given estimator.
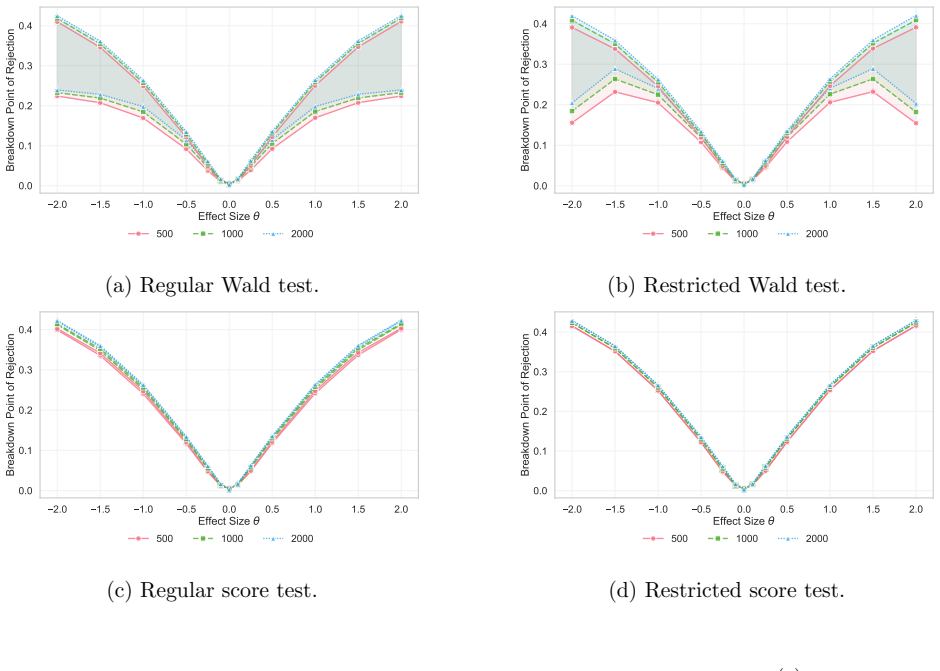
- The two-sample testing application shows that these measures can be used to assess how contamination affects the actual decisions of a statistical test.
- Because the measures are defined for finite samples, they offer a way to compare estimators on data sets of the size actually encountered in practice.
Load-bearing premise
The explicit derivations assume that the M-estimators satisfy regularity conditions permitting closed-form breakdown calculations and that the contamination model yields well-defined worst-case deviations.
What would settle it
A simulation that contaminates data at fractions both below and above the computed threshold breakdown point and checks whether the estimator's deviation crosses the prescribed level precisely at the computed fraction would confirm or refute the measure.
Figures






read the original abstract
We introduce a novel approach to finite sample robustness that avoids the pessimism of traditional breakdown analyses. We define the threshold breakdown point, the smallest contamination fraction needed to induce a prescribed deviation, and the finite sample m-sensitivity, the worst-case deviation that an estimator can incur after m observations are contaminated. We derive these measures for commonly used M-estimators, their standard errors and related test statistics. This allows us to extend the decision breakdown point of Zhang (1996) to obtain general breakdown characterizations for hypothesis testing, and show how these notions correspond to finite sample counterparts of the power and level breakdown functions of He, Simpson and Portnoy (1990). We complement our work with an inferential framework for the threshold breakdown and m-sensitivity that yields consistency and asymptotic normality results, as well as a valid multiplier bootstrap for uncertainty quantification. We illustrate the practical utility of our methods in various numerical examples and an application to a two sample testing problem for a blood pressure dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the threshold breakdown point (the smallest contamination fraction ε inducing a prescribed deviation δ in an estimator or test statistic) and the finite-sample m-sensitivity (the worst-case deviation after m contaminated observations). It derives explicit expressions for these quantities for standard M-estimators, their standard errors, and related test statistics; extends Zhang's (1996) decision breakdown point to hypothesis testing; relates the new measures to finite-sample analogs of the power and level breakdown functions of He, Simpson and Portnoy (1990); and supplies an inferential framework establishing consistency, asymptotic normality, and multiplier bootstrap validity, with numerical illustrations and an application to a two-sample blood-pressure test.
Significance. If the derivations and asymptotic results hold, the work supplies a targeted, non-pessimistic finite-sample robustness tool that complements classical breakdown analysis and enables practical inference on robustness measures. Explicit derivations for M-estimators together with the bootstrap procedure constitute concrete strengths that could support applied use in robust statistics.
major comments (2)
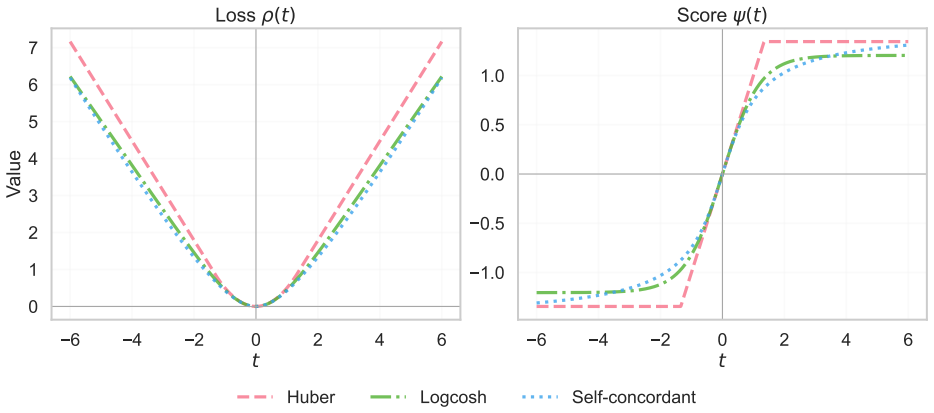
- [§4] §4 (inferential framework), Theorem on asymptotic normality: the delta-method and multiplier-bootstrap arguments for the threshold breakdown point estimator presuppose Hadamard differentiability of the inverse bias map ε ↦ bias(ε). For typical M-estimators the bias function is monotone but not everywhere strictly differentiable (flat regions or kinks occur at the median or Huber estimator), so the stated asymptotic normality and bootstrap validity do not follow from the given regularity conditions without additional smoothing or strict-monotonicity assumptions.
- [§3.2] §3.2 (derivations for test statistics): the extension of the decision breakdown point to hypothesis testing relies on the same inverse-bias construction; the same differentiability gap therefore propagates to the claimed consistency and normality results for the breakdown point of the test statistic.
minor comments (2)
- [Abstract] The abstract lists 'various numerical examples' without enumerating the estimators or sample sizes; a short list would improve readability.
- [§2] Notation for population versus sample versions of the threshold breakdown point and m-sensitivity is introduced in §2 but reused without consistent subscripting in later sections.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a potential gap in the regularity conditions underlying the asymptotic results. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [§4] §4 (inferential framework), Theorem on asymptotic normality: the delta-method and multiplier-bootstrap arguments for the threshold breakdown point estimator presuppose Hadamard differentiability of the inverse bias map ε ↦ bias(ε). For typical M-estimators the bias function is monotone but not everywhere strictly differentiable (flat regions or kinks occur at the median or Huber estimator), so the stated asymptotic normality and bootstrap validity do not follow from the given regularity conditions without additional smoothing or strict-monotonicity assumptions.
Authors: We agree that the bias map for some M-estimators (e.g., the median or Huber) is not everywhere differentiable. The manuscript states the asymptotic normality and bootstrap results under the standing assumption that the inverse bias map is Hadamard differentiable at the relevant interior point. To make this explicit, we will add a short remark clarifying that the operating points considered in the examples lie away from kinks or flat regions, together with a mild local strict-monotonicity condition that guarantees the required differentiability. With this clarification the delta-method and multiplier-bootstrap arguments apply directly to the cases treated in the paper. revision: partial
-
Referee: [§3.2] §3.2 (derivations for test statistics): the extension of the decision breakdown point to hypothesis testing relies on the same inverse-bias construction; the same differentiability gap therefore propagates to the claimed consistency and normality results for the breakdown point of the test statistic.
Authors: The observation is correct: the breakdown-point results for test statistics are obtained by the identical inverse-bias construction. We will therefore carry the same local differentiability clarification and monotonicity condition into §3.2, ensuring that the consistency and asymptotic normality statements for the test-statistic breakdown points rest on the same (now explicitly stated) regularity assumptions as those for the estimators. revision: partial
Circularity Check
No significant circularity in definitions or derivations
full rationale
The threshold breakdown point is introduced by direct definition as the infimum contamination fraction inducing a prescribed deviation, and m-sensitivity as the worst-case deviation after m contaminations; both are then computed explicitly for M-estimators and statistics under stated regularity conditions. These constructions extend external prior results (Zhang 1996; He, Simpson and Portnoy 1990) without reducing to self-referential inputs or fitted quantities renamed as predictions. The subsequent consistency, asymptotic normality, and multiplier bootstrap claims are presented as standard asymptotic arguments applied to the defined quantities, not forced by the definitions themselves. No load-bearing self-citations, ansatz smuggling, or uniqueness theorems imported from the authors appear in the chain. The derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption M-estimators satisfy the regularity conditions required for explicit finite-sample breakdown calculations and asymptotic inference.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , pages=
Deep learning with differential privacy , author=. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , pages=. 2016 , organization=
2016
-
[2]
Bias robustness of depth estimators in multivariate settings
Some insights into depth estimators for location and scatter in the multivariate setting , author=. arXiv preprint arXiv:2505.07383 , year=
work page internal anchor Pith review arXiv
-
[3]
Weighted
Rosenbaum, Paul R , journal=. Weighted. 2014 , publisher=
2014
-
[4]
Annals of Mathematical Statistics , volume=
A general qualitative definition of robustness , author=. Annals of Mathematical Statistics , volume=. 1971 , publisher=
1971
-
[5]
1986 , publisher=
Robust Statistics: The Approach Based on Influence Functions , author=. 1986 , publisher=
1986
-
[6]
Propose, test, release: Differentially private estimation with high probability , author=. arXiv preprint arXiv:2002.08774 , year=
-
[7]
Symposium on Theory of Computing (STOC) , pages=
Smooth sensitivity and sampling in private data analysis , author=. Symposium on Theory of Computing (STOC) , pages=
-
[8]
1968 , publisher=
Contributions to the theory of robust estimation , author=. 1968 , publisher=
1968
-
[9]
A simple two-sample
Wang, Min and Liu, Guangying , journal=. A simple two-sample. 2016 , publisher=
2016
-
[10]
Journal of the American Statistical Association , volume=
Robust bounded-influence tests in general parametric models , author=. Journal of the American Statistical Association , volume=. 1994 , publisher=
1994
-
[11]
Econometrica , volume=
Estimation and inference with weak, semi-strong, and strong identification , author=. Econometrica , volume=. 2012 , publisher=
2012
-
[12]
Biometrika , volume=
Robust estimation of high-dimensional covariance and precision matrices , author=. Biometrika , volume=. 2018 , publisher=
2018
-
[13]
International Conference on Machine Learning (ICML) , volume=
Convergence rates for differentially private statistical estimation , author=. International Conference on Machine Learning (ICML) , volume=
-
[14]
Bootstrap consistency for general semiparametric
Cheng, Guang and Huang, Jianhua Z , journal=. Bootstrap consistency for general semiparametric. 2010 , publisher=
2010
-
[15]
Bernoulli (to appear) , year=
On the breakdown point of transport-based quantiles , author=. Bernoulli (to appear) , year=
-
[16]
arXiv preprint, arXiv:2603.16005 , year=
Breakdown properties of optimal transport maps: general transportation costs , author=. arXiv preprint, arXiv:2603.16005 , year=
-
[17]
A theoretical framework for
Marusic, Juraj and Medina, Marco Avella and Rush, Cynthia , journal=. A theoretical framework for
-
[18]
Annals of Applied Probability (to appear) , year=
On the robustness of semi-discrete optimal transport , author=. Annals of Applied Probability (to appear) , year=
-
[19]
Existence and breakdown analysis of
Konen, Dimitri and Paindaveine, Davy , journal=. Existence and breakdown analysis of. 2025 , publisher=
2025
-
[20]
Annales de l’Institut Henri Poincar
On the robustness of spatial quantiles , author=. Annales de l’Institut Henri Poincar
-
[21]
Asymptotic behaviour of
Davies, Laurie P , journal=. Asymptotic behaviour of. 1987 , publisher=
1987
-
[22]
Journal of the American Statistical Association , volume=
Least median of squares regression , author=. Journal of the American Statistical Association , volume=. 1984 , publisher=
1984
-
[23]
Robust regression by means of
Rousseeuw, Peter and Yohai, Victor , booktitle=. Robust regression by means of. 1984 , organization=
1984
-
[24]
Annals of Statistics , pages=
High breakdown-point and high efficiency robust estimates for regression , author=. Annals of Statistics , pages=. 1987 , publisher=
1987
-
[25]
Annals of Statistics , volume=
On robustness and local differential privacy , author=. Annals of Statistics , volume=. 2023 , publisher=
2023
-
[26]
Privately estimating a
Alabi, Daniel and Kothari, Pravesh K and Tankala, Pranay and Venkat, Prayaag and Zhang, Fred , booktitle=. Privately estimating a
-
[27]
Annals of Statistics , volume=
Maximum bias curves for robust regression with non-elliptical regressors , author=. Annals of Statistics , volume=. 2001 , publisher=
2001
-
[28]
Journal of the american statistical association , volume=
Wald's test as applied to hypotheses in logit analysis , author=. Journal of the american statistical association , volume=. 1977 , publisher=
1977
-
[29]
Symposium on Theory of Computing (STOC) , pages=
Robustness implies privacy in statistical estimation , author=. Symposium on Theory of Computing (STOC) , pages=
-
[30]
Chance , volume=
The role of robust statistics in private data analysis , author=. Chance , volume=. 2020 , publisher=
2020
-
[31]
Journal of the American Statistical Association , volume=
Privacy-preserving parametric inference: a case for robust statistics , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
2021
-
[32]
Annals of Statistics , volume=
Differentially private inference via noisy optimization , author=. Annals of Statistics , volume=. 2023 , publisher=
2023
-
[33]
Journal of Computational and Graphical Statistics , pages=
Differentially private significance tests for regression coefficients , author=. Journal of Computational and Graphical Statistics , pages=. 2019 , publisher=
2019
-
[34]
2014 IEEE 55th Annual Symposium on Foundations of Computer Science , pages=
Private empirical risk minimization: Efficient algorithms and tight error bounds , author=. 2014 IEEE 55th Annual Symposium on Foundations of Computer Science , pages=. 2014 , organization=
2014
-
[35]
Journal of the American Statistical Association , volume=
Prepivoting test statistics: a bootstrap view of asymptotic refinements , author=. Journal of the American Statistical Association , volume=. 1988 , publisher=
1988
-
[36]
Transactions of the american mathematical society , volume=
The accuracy of the Gaussian approximation to the sum of independent variates , author=. Transactions of the american mathematical society , volume=. 1941 , publisher=
1941
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Covariance-aware private mean estimation without private covariance estimation , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[38]
IEEE Transactions on Information Theory , volume=
Bandits with heavy tail , author=. IEEE Transactions on Information Theory , volume=. 2013 , publisher=
2013
-
[39]
Advances in Neural Information Processing Systems (NeruIPS) , volume=
Private hypothesis selection , author=. Advances in Neural Information Processing Systems (NeruIPS) , volume=
-
[40]
arXiv preprint arXiv:1902.04495 , year=
The cost of privacy: optimal rates of convergence for paramer estimaion with differential privacy , author=. arXiv preprint arXiv:1902.04495 , year=
-
[41]
Annales de l'IHP Probabilit
Challenging the empirical mean and empirical variance: a deviation study , author=. Annales de l'IHP Probabilit
-
[42]
Journal of Machine Learning Research , volume=
Differentially private empirical risk minimization , author=. Journal of Machine Learning Research , volume=
-
[43]
International Conference on Machine Learning (ICML) , year=
Convergence rates for differentially private statistical estimation , author=. International Conference on Machine Learning (ICML) , year=
-
[44]
The Annals of Statistics , volume=
Robust covariance and scatter matrix estimation under Huber’s contamination model , author=. The Annals of Statistics , volume=. 2018 , publisher=
2018
-
[45]
Journal of Nonparametric Statistics , volume=
Maxbias curves of robust location estimators based on subranges , author=. Journal of Nonparametric Statistics , volume=. 2002 , publisher=
2002
-
[46]
Journal of Econometrics , volume=
The power of bootstrap and asymptotic tests , author=. Journal of Econometrics , volume=. 2006 , publisher=
2006
-
[47]
The Annals of Statistics , volume=
Breakdown and groups , author=. The Annals of Statistics , volume=
-
[48]
REVSTAT-Statistical Journal , volume=
The breakdown point—examples and counterexamples , author=. REVSTAT-Statistical Journal , volume=
-
[49]
arXiv preprint arXiv:2011.14999 , year=
An automatic finite-sample robustness metric: when can dropping a little data make a big difference? , author=. arXiv preprint arXiv:2011.14999 , year=
-
[50]
International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=
Influence diagnostics under self-concordance , author=. International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=. 2023 , organization=
2023
-
[51]
Advances in neural information processing systems (NeurIPS) , volume=
On the accuracy of influence functions for measuring group effects , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Most influential subset selection: Challenges, promises, and beyond , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[53]
Statistical Science , volume=
Robustness by reweighting for kernel estimators: an overview , author=. Statistical Science , volume=. 2021 , publisher=
2021
-
[54]
The Annals of Statistics , volume=
Sub-Gaussian mean estimators , author=. The Annals of Statistics , volume=. 2016 , publisher=
2016
-
[55]
SIAM Journal on Computing , volume=
Robust estimators in high-dimensions without the computational intractability , author=. SIAM Journal on Computing , volume=. 2019 , publisher=
2019
-
[56]
1997 , publisher=
Evaluating density forecasts , author=. 1997 , publisher=
1997
-
[57]
A Festschrift for Erich L
The notion of breakdown point , author=. A Festschrift for Erich L. Lehmann , year=
-
[58]
Journal of the American Statistical Association , volume=
Minimax optimal procedures for locally private estimation , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
2018
-
[59]
, author=
Differential privacy and robust statistics. , author=. Symposium on Theory of Computing (STOC) , volume=
-
[60]
Theory of cryptography conference , pages=
Calibrating noise to sensitivity in private data analysis , author=. Theory of cryptography conference , pages=. 2006 , organization=
2006
-
[61]
Foundations and Trends
The algorithmic foundations of differential privacy , author=. Foundations and Trends. 2014 , publisher=
2014
-
[62]
ICML'16 Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48 , year=
Differentially private chi-squared hypothesis testing: Goodness of fit and independence testing , author=. ICML'16 Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48 , year=
-
[63]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Privacy induces robustness: Information-computation gaps and sparse mean estimation , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[64]
, title =
Hampel, Frank R. , title =. Journal of the American Statistical Association , year =
-
[65]
Journal of the American Statistical Association , volume=
Breakdown robustness of tests , author=. Journal of the American Statistical Association , volume=. 1990 , publisher=
1990
-
[66]
Symposium on Theory of Computing (STOC) , pages=
Efficient mean estimation with pure differential privacy via a sum-of-squares exponential mechanism , author=. Symposium on Theory of Computing (STOC) , pages=
-
[67]
The Journal of Machine Learning Research , volume=
Loss minimization and parameter estimation with heavy tails , author=. The Journal of Machine Learning Research , volume=. 2016 , publisher=
2016
-
[68]
1994 , publisher=
Robust Asymptotic Statistics , author=. 1994 , publisher=
1994
-
[69]
1982 , publisher=
Robust testing in linear models: the infinitesimal approach , author=. 1982 , publisher=
1982
-
[70]
and Ronchetti, Elvezio , Edition =
Huber, Peter J. and Ronchetti, Elvezio , Edition =. Robust Statistics , Year =
-
[71]
Annals of Mathematical Statistics , volume=
Robust Estimation of a Location Parameter , author=. Annals of Mathematical Statistics , volume=. 1964 , publisher=
1964
-
[72]
The Annals of Statistics , volume=
Finite Sample Breakdown of M -and P -Estimators , author=. The Annals of Statistics , volume=. 1984 , publisher=
1984
-
[73]
Tukey's contributions to robust statistics , author=
John W. Tukey's contributions to robust statistics , author=. Annals of statistics , pages=. 2002 , publisher=
2002
-
[74]
Biometrika , volume=
A simple resampling method by perturbing the minimand , author=. Biometrika , volume=. 2001 , publisher=
2001
-
[75]
Conference on Learning Theory (COLT) , pages=
Private mean estimation of heavy-tailed distributions , author=. Conference on Learning Theory (COLT) , pages=
-
[76]
The Annals of Statistics , volume=
Inference using noisy degrees: Differentially private beta-model and synthetic graphs , author=. The Annals of Statistics , volume=. 2016 , publisher=
2016
-
[77]
Statistical Science , volume=
User-friendly covariance estimation for heavy-tailed distributions , author=. Statistical Science , volume=. 2019 , publisher=
2019
-
[78]
Working paper , year=
The threshold breakdown point , author=. Working paper , year=
-
[79]
Conference on Learning Theory , pages=
Private convex empirical risk minimization and high-dimensional regression , author=. Conference on Learning Theory , pages=
-
[80]
2008 , publisher=
Introduction to empirical processes and semiparametric inference , author=. 2008 , publisher=
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.