Recognition: no theorem link
SPHERE: Mitigating the Loss of Spectral Plasticity in Mixture-of-Experts for Deep Reinforcement Learning
Pith reviewed 2026-05-11 01:46 UTC · model grok-4.3
The pith
A Parseval penalty on expert feature matrices prevents loss of spectral plasticity in mixture-of-experts policies for continual reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Building on Neural Tangent Kernel theory, plasticity loss in MoE policies is formalized as a loss of spectral plasticity. A tractable proxy for this quantity is derived directly from the feature matrices of the separate experts. SPHERE is then defined as a Parseval penalty tailored to these matrices that keeps the proxy from falling. When tested on MetaWorld and HumanoidBench under continual RL, the regularized policies achieve 133 percent and 50 percent higher average success than an unregularized MoE baseline while recording higher spectral-plasticity values at every stage of training.
What carries the argument
SPHERE, the Parseval penalty applied to the feature matrices of the individual experts inside the mixture-of-experts policy; it directly regularizes the NTK-derived proxy for spectral plasticity.
If this is right
- MoE policies retain the ability to learn diverse skills from new experience without degeneration over extended continual RL training.
- The spectral-plasticity proxy remains higher for the entire duration of training when the Parseval penalty is applied.
- Average task success rises by 133 percent on MetaWorld and 50 percent on HumanoidBench relative to the unregularized MoE baseline.
Where Pith is reading between the lines
- The same NTK-derived proxy could be used to monitor plasticity loss in mixture-of-experts models outside reinforcement learning.
- Similar penalties might reduce the need for auxiliary techniques such as periodic network resets in long-horizon continual learning.
- If the proxy correlates with actual adaptation speed, it could serve as an early diagnostic for when an MoE policy is about to lose plasticity.
Load-bearing premise
The tractable proxy for spectral plasticity, expressed in terms of individual expert feature matrices and derived from NTK theory, accurately reflects the true loss of plasticity in MoE policies during continual RL training.
What would settle it
An experiment in which the proxy value is tracked alongside a direct test of new-task acquisition speed after long training; if the regularized and unregularized agents show identical new-task learning curves despite large differences in the proxy, the central claim is falsified.
Figures









read the original abstract
In deep reinforcement learning (DRL), an agent is trained from a stream of experience. In a continual learning setting, such agents can suffer from plasticity loss: their ability to learn new skills from new experiences diminishes over training. Recently, Mixture-of-Experts (MoE) networks have been reported to enable scaling laws and facilitate the learning of diverse skills. However, in continual reinforcement learning settings, their performance can degenerate as learning proceeds, indicating a loss of plasticity. To address this, building on Neural Tangent Kernel (NTK) theory, we formalize the plasticity loss in MoE policies as a loss of spectral plasticity. We then derive a tractable proxy for spectral plasticity, one expressible in terms of individual expert feature matrices. Leveraging this proxy, we introduce SPHERE, a practical Parseval penalty tailored for MoE-based policies that alleviates the loss of spectral plasticity. On MetaWorld and HumanoidBench, SPHERE improves average success under continual RL by 133% and 50% over an unregularized MoE baseline, while maintaining higher spectral plasticity throughout training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Mixture-of-Experts policies in continual deep RL suffer from loss of spectral plasticity, which can be formalized via NTK theory as a tractable proxy expressible in terms of individual expert feature matrices; SPHERE, a Parseval penalty based on this proxy, is introduced to mitigate the issue and yields 133% and 50% gains in average success rate over unregularized MoE baselines on MetaWorld and HumanoidBench while preserving higher spectral plasticity throughout training.
Significance. If the NTK-derived proxy is shown to accurately track true plasticity loss rather than serving as generic regularization, the work offers a principled, scalable approach to maintaining learning capacity in MoE architectures for non-stationary RL; the reported gains on two standard continual-RL benchmarks constitute a concrete empirical contribution, and the explicit grounding in NTK theory is a strength that could enable further theoretical analysis.
major comments (3)
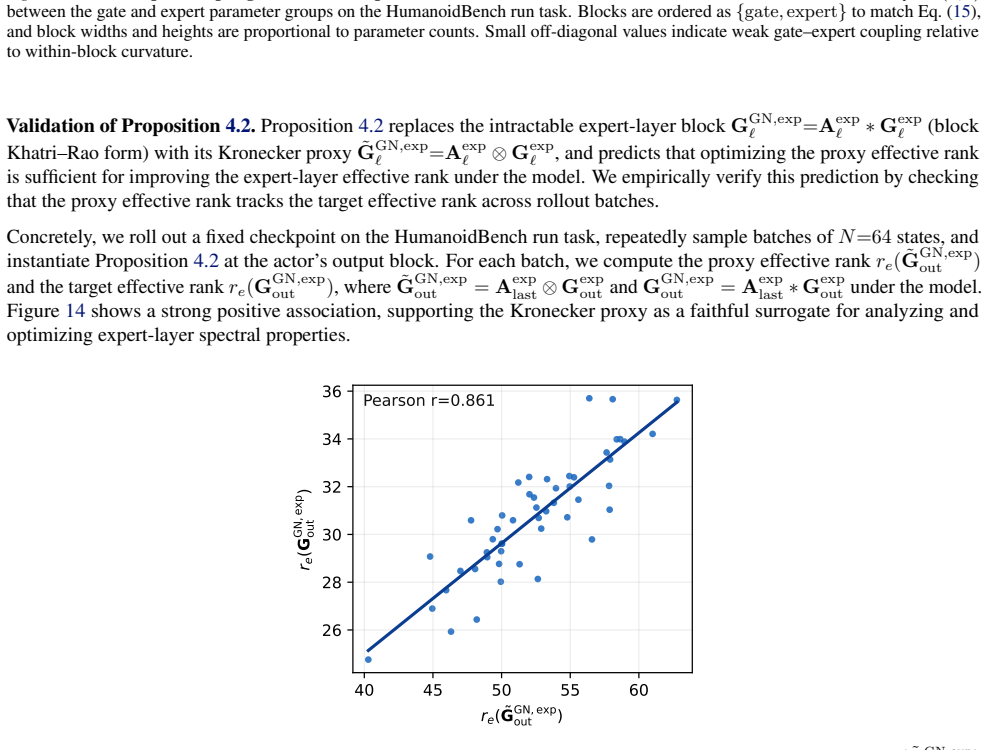
- [§3.2] §3.2 (derivation of the tractable proxy): the proxy is obtained by linearizing the MoE policy under NTK assumptions (infinite width, fixed data distribution at initialization); continual RL violates these via finite-width experts, non-stationary task streams, and policy updates far from initialization, so the manuscript must demonstrate (via correlation plots or ablation) that the proxy remains predictive of actual degradation in new-task performance rather than merely acting as a tunable regularizer.
- [§4.3] §4.3 and Table 2: the 133% and 50% average-success improvements are reported without error bars, number of seeds, or statistical tests; because the central claim is that SPHERE specifically mitigates spectral-plasticity loss (rather than generic regularization), these omissions make it impossible to judge whether the gains are robust or reproducible.
- [§3.1] §3.1 (formalization of spectral plasticity): the loss is defined via the smallest eigenvalue of the NTK Gram matrix restricted to expert features; the paper should clarify whether this quantity is computed exactly or approximated, and whether the approximation remains valid once experts are updated during continual training.
minor comments (2)
- [Abstract] The abstract states the performance gains but omits any mention of variance, number of runs, or hyper-parameter sensitivity; adding these details would strengthen the empirical claims.
- [§3.3] Notation for the Parseval penalty (Eq. (X)) should explicitly state how the coefficient is chosen or tuned; the current description leaves open whether it is a fixed hyper-parameter or derived from the proxy.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revising the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§3.2] §3.2 (derivation of the tractable proxy): the proxy is obtained by linearizing the MoE policy under NTK assumptions (infinite width, fixed data distribution at initialization); continual RL violates these via finite-width experts, non-stationary task streams, and policy updates far from initialization, so the manuscript must demonstrate (via correlation plots or ablation) that the proxy remains predictive of actual degradation in new-task performance rather than merely acting as a tunable regularizer.
Authors: We acknowledge that the NTK assumptions are idealized and do not hold exactly under continual RL. In the revised manuscript we will add correlation plots relating the proxy values to measured new-task performance degradation across training checkpoints. We will also include ablations comparing SPHERE against alternative regularizers to isolate its effect on spectral plasticity. revision: yes
-
Referee: [§4.3] §4.3 and Table 2: the 133% and 50% average-success improvements are reported without error bars, number of seeds, or statistical tests; because the central claim is that SPHERE specifically mitigates spectral-plasticity loss (rather than generic regularization), these omissions make it impossible to judge whether the gains are robust or reproducible.
Authors: We agree that these statistical details are necessary. We will revise Table 2 and the experimental section to report mean ± standard deviation over 5 random seeds, state the seed count explicitly, and add statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank) between SPHERE and the unregularized baseline. revision: yes
-
Referee: [§3.1] §3.1 (formalization of spectral plasticity): the loss is defined via the smallest eigenvalue of the NTK Gram matrix restricted to expert features; the paper should clarify whether this quantity is computed exactly or approximated, and whether the approximation remains valid once experts are updated during continual training.
Authors: The smallest eigenvalue is computed exactly from the Gram matrix of the current expert feature matrices at each evaluation checkpoint. We will add a clarifying paragraph in §3.1 describing this exact computation and discuss its continued empirical validity during training, consistent with the spectral-plasticity tracking already shown throughout the experiments. revision: yes
Circularity Check
No circularity: derivation grounded in external NTK theory with empirical validation
full rationale
The paper formalizes plasticity loss via NTK theory (external), derives a tractable proxy expressible in expert feature matrices, and introduces SPHERE as a Parseval penalty based on that proxy. Performance improvements (133%/50%) are shown via experiments on MetaWorld and HumanoidBench rather than by construction. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain; the central claims remain independent of the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- penalty strength coefficient
axioms (1)
- domain assumption Neural Tangent Kernel theory provides a valid linearization for analyzing plasticity in trained MoE policies under continual RL updates.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , year=
Continual world: A robotic benchmark for continual reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Wide neural networks of any depth evolve as linear models under gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Proceedings of the 34th International Conference on Machine Learning , year=
Practical Gauss-Newton Optimisation for Deep Learning , author=. Proceedings of the 34th International Conference on Machine Learning , year=
-
[5]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
A Study of Plasticity Loss in On-Policy Deep Reinforcement Learning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[6]
The Twelfth International Conference on Learning Representations , year=
Revisiting Plasticity in Visual Reinforcement Learning: Data, Modules and Training Stages , author=. The Twelfth International Conference on Learning Representations , year=
-
[7]
Proceedings of the Conference on Robot Learning , year=
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning , author=. Proceedings of the Conference on Robot Learning , year=
-
[8]
International Conference on Machine Learning , year=
Controlling overestimation bias with truncated mixture of continuous distributional quantile critics , author=. International Conference on Machine Learning , year=
-
[9]
Reinforcement learning: An introduction , author=. A Bradford Book , year=
-
[10]
International Journal of Information and Systems Sciences , year=
Hadamard, Khatri-Rao, Kronecker and other matrix products , author=. International Journal of Information and Systems Sciences , year=
-
[11]
Plasticity Loss in Deep Reinforcement Learning: A Survey
Plasticity Loss in Deep Reinforcement Learning: A Survey , author=. arXiv preprint arXiv:2411.04832 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
2007 15th European signal processing conference , year=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , year=
work page 2007
-
[13]
International Conference on Machine Learning , year=
The dormant neuron phenomenon in deep reinforcement learning , author=. International Conference on Machine Learning , year=
-
[14]
Advances in Neural Information Processing Systems , year=
Deep reinforcement learning with plasticity injection , author=. Advances in Neural Information Processing Systems , year=
-
[15]
Conference on lifelong learning agents , year=
Loss of plasticity in continual deep reinforcement learning , author=. Conference on lifelong learning agents , year=
-
[16]
Trends in neurosciences , year=
Memory retention--the synaptic stability versus plasticity dilemma , author=. Trends in neurosciences , year=
- [17]
-
[18]
International Conference on Learning Representations , year=
Implicit under-parameterization inhibits data-efficient deep reinforcement learning , author=. International Conference on Learning Representations , year=
-
[19]
Brain mechanisms in conditioning and learning , author=
-
[20]
International Conference on Learning Representations , year=
Understanding and Preventing Capacity Loss in Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[21]
International Conference on Machine Learning , year=
Understanding plasticity in neural networks , author=. International Conference on Machine Learning , year=
-
[22]
Frontiers in Cellular Neuroscience , year=
The impact of studying brain plasticity , author=. Frontiers in Cellular Neuroscience , year=
-
[23]
International conference on machine learning , year=
The primacy bias in deep reinforcement learning , author=. International conference on machine learning , year=
-
[24]
International Conference on Machine Learning , year=
Mixtures of Experts unlock parameter scaling for deep RL , author=. International Conference on Machine Learning , year=
-
[25]
Reinforcement Learning Journal , year=
Mixture of Experts in a Mixture of RL settings , author=. Reinforcement Learning Journal , year=
-
[26]
International Conference on Machine Learning , year=
Transient non-stationarity and generalisation in deep reinforcement learning , author=. International Conference on Machine Learning , year=
-
[27]
International Conference on Learning Representations , year=
Don't flatten, tokenize! Unlocking the key to SoftMoE's efficacy in deep RL , author=. International Conference on Learning Representations , year=
-
[28]
IEEE/RSJ International Conference on Intelligent Robots and Systems , year=
MoE-Loco: Mixture of Experts for Multitask Locomotion , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , year=
-
[30]
International Conference on Machine Learning , year=
Mentor: Mixture-of-experts network with task-oriented perturbation for visual reinforcement learning , author=. International Conference on Machine Learning , year=
-
[31]
International Conference on Learning Representations , year=
DrM: Mastering visual reinforcement learning through dormant ratio minimization , author=. International Conference on Learning Representations , year=
-
[32]
International Conference on Learning Representations , year=
Neuroplastic expansion in deep reinforcement learning , author=. International Conference on Learning Representations , year=
-
[33]
The Thirteenth International Conference on Learning Representations , year=
Prevalence of Negative Transfer in Continual Reinforcement Learning: Analyses and a Simple Baseline , author=. The Thirteenth International Conference on Learning Representations , year=
-
[34]
Aneesh Muppidi and Zhiyu Zhang and Heng Yang , booktitle=. Fast
-
[35]
Proceedings of the 42nd International Conference on Machine Learning , year =
Knowledge Retention in Continual Model-Based Reinforcement Learning , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[36]
The Thirteenth International Conference on Learning Representations , year=
Theory on Mixture-of-Experts in Continual Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[37]
Conference on Lifelong Learning Agents , pages=
Measuring and mitigating interference in reinforcement learning , author=. Conference on Lifelong Learning Agents , pages=. 2023 , organization=
work page 2023
-
[38]
International conference on machine learning , year=
Addressing function approximation error in actor-critic methods , author=. International conference on machine learning , year=
- [39]
- [40]
-
[41]
Inequalities: theory of majorization and its applications , author=. 1979 , publisher=
work page 1979
-
[42]
Pattern recognition and machine learning , author=. 2006 , publisher=
work page 2006
- [43]
-
[44]
International Conference on Learning Representations , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. International Conference on Learning Representations , year=
-
[45]
Journal of Machine Learning Research , year=
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. Journal of Machine Learning Research , year=
-
[46]
Advances in Neural Information Processing Systems , year=
Mixture-of-Experts with Expert Choice Routing , author=. Advances in Neural Information Processing Systems , year=
-
[47]
Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664,
Auxiliary-loss-free load balancing strategy for mixture-of-experts , author=. arXiv preprint arXiv:2408.15664 , year=
-
[48]
Advances in Neural Information Processing Systems , year=
Parseval Regularization for Continual Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[50]
International Conference on Machine Learning , year=
Mitigating Plasticity Loss in Continual Reinforcement Learning by Reducing Churn , author=. International Conference on Machine Learning , year=
-
[51]
Conference on Lifelong Learning Agents , year=
Disentangling the Causes of Plasticity Loss in Neural Networks , author=. Conference on Lifelong Learning Agents , year=
-
[52]
International Conference on Learning Representations , year =
Spectral Normalization for Generative Adversarial Networks , author =. International Conference on Learning Representations , year =
-
[53]
Proceedings of the 7th International Conference on Learning Representations , year =
The Singular Values of Convolutional Layers , author =. Proceedings of the 7th International Conference on Learning Representations , year =
-
[54]
International conference on machine learning , year=
Optimizing neural networks with kronecker-factored approximate curvature , author=. International conference on machine learning , year=
-
[55]
International Conference on Machine Learning , year=
A kronecker-factored approximate fisher matrix for convolution layers , author=. International Conference on Machine Learning , year=
-
[56]
Advances in Neural Information Processing Systems , year =
Theoretical Characterisation of the Gauss Newton Conditioning in Neural Networks , author=. Advances in Neural Information Processing Systems , year =
-
[57]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
-
[58]
Technical University of Denmark , year=
The matrix cookbook , author=. Technical University of Denmark , year=
-
[59]
Transactions on Machine Learning Research , year=
The Low-Rank Simplicity Bias in Deep Networks , author=. Transactions on Machine Learning Research , year=
-
[61]
International Conference on Learning Representations , year=
Learning Continually by Spectral Regularization , author=. International Conference on Learning Representations , year=
-
[62]
Advances in Neural Information Processing Systems , year =
Towards Deeper Deep Reinforcement Learning with Spectral Normalization , author =. Advances in Neural Information Processing Systems , year =
-
[63]
Abbas, Z., Zhao, R., Modayil, J., White, A., and Machado, M. C. Loss of plasticity in continual deep reinforcement learning. In Conference on lifelong learning agents, 2023
work page 2023
-
[64]
Bjorck, N., Gomes, C. P., and Weinberger, K. Q. Towards deeper deep reinforcement learning with spectral normalization. In Advances in Neural Information Processing Systems, 2021
work page 2021
-
[65]
Practical gauss-newton optimisation for deep learning
Botev, A., Ritter, H., and Barber, D. Practical gauss-newton optimisation for deep learning. In Proceedings of the 34th International Conference on Machine Learning, 2017
work page 2017
-
[66]
Parseval regularization for continual reinforcement learning
Chung, W., Cherif, L., Meger, D., and Precup, D. Parseval regularization for continual reinforcement learning. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[67]
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models
Dai, D., Deng, C., Zhao, C., Xu, R., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[68]
F., Lan, Q., Rahman, P., Mahmood, A
Dohare, S., Hernandez-Garcia, J. F., Lan, Q., Rahman, P., Mahmood, A. R., and Sutton, R. S. Loss of plasticity in deep continual learning. Nature, 2024
work page 2024
-
[69]
Golub, G. H. and Van Loan, C. F. Matrix computations. JHU press, 2013
work page 2013
-
[70]
Grosse, R. and Martens, J. A kronecker-factored approximate fisher matrix for convolution layers. In International Conference on Machine Learning, 2016
work page 2016
-
[71]
Spectral collapse drives loss of plasticity in deep continual learning
He, N., Guo, K., Prakash, A., Tiwari, S., Tao, R. Y., Serapio, T., Greenwald, A., and Konidaris, G. Spectral collapse drives loss of plasticity in deep continual learning. arXiv preprint arXiv:2509.22335, 2025
-
[72]
Horn, R. A. and Johnson, C. R. Matrix analysis. Cambridge University Press, 2012
work page 2012
-
[73]
Huang, R. et al. Moe-loco: Mixture of experts for multitask locomotion. In IEEE/RSJ International Conference on Intelligent Robots and Systems, 2025 a
work page 2025
-
[74]
Huang, S. et al. Mentor: Mixture-of-experts network with task-oriented perturbation for visual reinforcement learning. In International Conference on Machine Learning, 2025 b
work page 2025
-
[75]
The low-rank simplicity bias in deep networks
Huh, M., Mobahi, H., Zhang, R., Cheung, B., Agrawal, P., and Isola, P. The low-rank simplicity bias in deep networks. Transactions on Machine Learning Research, 2023
work page 2023
-
[76]
Igl, M. et al. Transient non-stationarity and generalisation in deep reinforcement learning. In International Conference on Machine Learning, 2021
work page 2021
-
[77]
Juliani, A. and Ash, J. T. A study of plasticity loss in on-policy deep reinforcement learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[78]
Implicit under-parameterization inhibits data-efficient deep reinforcement learning
Kumar, A., Agarwal, R., Ghosh, D., and Levine, S. Implicit under-parameterization inhibits data-efficient deep reinforcement learning. In International Conference on Learning Representations, 2021
work page 2021
-
[79]
S., Bahri, Y., Novak, R., Sohl-Dickstein, J., and Pennington, J
Lee, J., Xiao, L., Schoenholz, S. S., Bahri, Y., Novak, R., Sohl-Dickstein, J., and Pennington, J. Wide neural networks of any depth evolve as linear models under gradient descent. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
- [80]
-
[81]
Lewandowski, A., Bortkiewicz, M., Kumar, S., Gy \"o rgy, A., Schuurmans, D., Ostaszewski, M., and Machado, M. C. Learning continually by spectral regularization. In International Conference on Learning Representations, 2025
work page 2025
-
[82]
Hadamard, khatri-rao, kronecker and other matrix products
Liu, S., Trenkler, G., et al. Hadamard, khatri-rao, kronecker and other matrix products. International Journal of Information and Systems Sciences, 2008
work page 2008
-
[83]
Livingston, R. B. Brain mechanisms in conditioning and learning. Technical report, Office of Naval Research, 1966
work page 1966
-
[84]
Understanding and preventing capacity loss in reinforcement learning
Lyle, C., Rowland, M., and Dabney, W. Understanding and preventing capacity loss in reinforcement learning. In International Conference on Learning Representations, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.