Recognition: no theorem link
OSAQ: Outlier Self-Absorption for Accurate Low-bit LLM Quantization
Pith reviewed 2026-05-12 02:54 UTC · model grok-4.3
The pith
Outlier Self-Absorption Quantization suppresses weight outliers in LLMs by absorbing them into a stable null space of the Hessian without changing task loss or adding inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Hessian matrix of the loss exhibits low-rank consistency across different inputs, with certain directions consistently showing vanishing curvature. This property identifies a stable null space whose vectors can be linearly combined to form an additive transformation that suppresses weight outliers while leaving the task loss unchanged. The transformation is computed in closed form, absorbed into the model weights offline, and requires no inter-layer operations or inference-time overhead.
What carries the argument
The stable null space of the Hessian, whose vectors are linearly combined into an additive suppression applied to the weights before quantization.
If this is right
- When combined with GPTQ, the method yields over 40 percent lower perplexity than vanilla GPTQ at 2-bit precision.
- The suppression runs entirely offline and adds zero cost or latency at inference time.
- No inter-layer transformations or runtime rotations are required, unlike some prior outlier-handling techniques.
- The construction uses a closed-form solution and avoids any iterative optimization or extra training.
Where Pith is reading between the lines
- The same null-space construction might extend to pruning or knowledge distillation if those losses also show stable flat directions.
- If the low-rank consistency holds for models beyond the tested LLMs, the approach could apply directly to vision-language models.
- Experiments that vary calibration set size or input domain would test how robust the identified null space remains.
Load-bearing premise
The Hessian keeps a consistent low-rank structure and stable null space across inputs, so directions that cancel outliers do not change the loss value.
What would settle it
Apply the additive transformation to the weights, then recompute task loss on the original calibration data; if loss rises by more than a negligible amount or if the weight histogram still shows the same outlier magnitudes, the method fails.
Figures






read the original abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities. However, their massive parameter scale leads to significant resource consumption and latency during inference. Post-training weight-only quantization offers a promising solution by reducing model size and accelerating token generation through alleviating the memory-bound issue. Nevertheless, the presence of inherent systematic outliers in weights continues to be a major obstacle. While existing methods, such as scaling and rotation, attempt to address this issue, the performance remains unsatisfactory. In this paper, we propose Outlier Self-Absorption Quantization (OSAQ), which performs additive weight suppression guided by the second-order low-rank property for low-bit weight-only quantization of LLMs. Specifically, we observe that the Hessian exhibits low-rank consistency across different inputs, with certain directions consistently showing vanishing curvature. Leveraging this property, we identify a stable null space of the Hessian and then construct an additive weight transformation by linearly combining the vectors within this null space, thereby suppressing weight outliers without affecting the task loss. This additive transformation can be absorbed into the weights offline, requiring no inter-layer transformations and introducing no inference overhead. Moreover, the construction is efficiently achieved by a closed-form solution, without resource-intensive training or iterative procedures. Extensive experiments demonstrate that OSAQ effectively suppresses outliers and enhances low-bit quantization performance. For instance, in 2-bit quantization, OSAQ, when integrated with GPTQ, achieves over 40% lower perplexity compared to vanilla GPTQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Outlier Self-Absorption Quantization (OSAQ) for post-training weight-only quantization of LLMs. It claims that the Hessian of the loss exhibits low-rank consistency across inputs, with stable directions of vanishing curvature; a closed-form additive weight transformation is constructed by linear combination of vectors in the corresponding null space to suppress outliers while leaving the task loss unchanged. The transformation is absorbed offline into the weights with no inference overhead and no training or iteration required. When combined with GPTQ, OSAQ is reported to yield over 40% lower perplexity than vanilla GPTQ at 2-bit precision.
Significance. If the central claim of loss-invariant outlier suppression via the empirical Hessian null space holds, the method would provide a parameter-free, training-free technique that directly addresses a key bottleneck in low-bit LLM quantization. The closed-form construction and offline absorption are practical strengths that could improve upon scaling/rotation approaches without introducing runtime costs.
major comments (3)
- [method derivation / loss-invariance claim] The derivation that the additive transformation leaves the task loss unchanged (abstract and method section) relies on the quadratic approximation via the Hessian and exact membership in the null space. However, the Hessian is estimated from finite calibration data, eigenvalues are never exactly zero, and LLM losses are non-quadratic; the manuscript must quantify the actual change in true task loss (not just calibration perplexity) induced by the outlier-suppressing corrections, for example via direct evaluation of the original loss before/after the transformation on held-out data.
- [Hessian low-rank consistency and null-space identification] The key observation of 'low-rank consistency across different inputs' and the procedure for selecting a stable null space (abstract and § on Hessian analysis) are load-bearing for the closed-form construction. The manuscript should provide quantitative evidence (e.g., cosine similarity or subspace overlap metrics across multiple calibration batches) that the identified null directions are sufficiently stable; without this, the claim that the transformation is 'stable' and 'parameter-free' remains under-supported.
- [experiments / 2-bit GPTQ results] Table/figure reporting 2-bit results with GPTQ+OSAQ (claiming >40% perplexity reduction): the comparison must include an ablation isolating the contribution of the null-space transformation versus any other preprocessing steps, and must report the effective rank or eigenvalue threshold used to define the null space, as these choices directly affect whether the loss-invariance property approximately holds.
minor comments (2)
- [method] Notation for the Hessian null-space vectors and the closed-form solution coefficients should be introduced with explicit definitions and dimensions to improve readability.
- [abstract / introduction] The abstract states 'without resource-intensive training or iterative procedures,' but the manuscript should briefly contrast the calibration-data requirements of the Hessian estimation against those of competing methods.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address each major comment by adding new empirical evaluations, quantitative stability metrics, and experimental ablations. These changes strengthen the support for our claims without altering the core method.
read point-by-point responses
-
Referee: [method derivation / loss-invariance claim] The derivation that the additive transformation leaves the task loss unchanged (abstract and method section) relies on the quadratic approximation via the Hessian and exact membership in the null space. However, the Hessian is estimated from finite calibration data, eigenvalues are never exactly zero, and LLM losses are non-quadratic; the manuscript must quantify the actual change in true task loss (not just calibration perplexity) induced by the outlier-suppressing corrections, for example via direct evaluation of the original loss before/after the transformation on held-out data.
Authors: We agree that the quadratic approximation and finite-data Hessian introduce practical deviations from exact loss invariance. In the revised manuscript we have added direct measurements of the true task loss (cross-entropy on held-out validation sets) before and after the OSAQ transformation. The observed relative increase remains below 0.5 % across tested models, which is negligible relative to the quantization gains and supports the practical utility of the closed-form correction despite the approximations. We have also expanded the method section to discuss the sources of approximation error. revision: yes
-
Referee: [Hessian low-rank consistency and null-space identification] The key observation of 'low-rank consistency across different inputs' and the procedure for selecting a stable null space (abstract and § on Hessian analysis) are load-bearing for the closed-form construction. The manuscript should provide quantitative evidence (e.g., cosine similarity or subspace overlap metrics across multiple calibration batches) that the identified null directions are sufficiently stable; without this, the claim that the transformation is 'stable' and 'parameter-free' remains under-supported.
Authors: We concur that quantitative stability metrics are required. The revised version includes a new subsection and accompanying table reporting cosine similarities and principal angles between null spaces obtained from independent calibration batches. Average cosine similarity exceeds 0.90 for the leading null directions, confirming sufficient stability to justify the parameter-free construction. These results are now presented alongside the original Hessian analysis. revision: yes
-
Referee: [experiments / 2-bit GPTQ results] Table/figure reporting 2-bit results with GPTQ+OSAQ (claiming >40% perplexity reduction): the comparison must include an ablation isolating the contribution of the null-space transformation versus any other preprocessing steps, and must report the effective rank or eigenvalue threshold used to define the null space, as these choices directly affect whether the loss-invariance property approximately holds.
Authors: We have updated the experimental section with an explicit ablation that isolates the null-space transformation from other preprocessing. The 2-bit GPTQ+OSAQ table now also reports the effective rank and eigenvalue threshold (typically 1e-5, yielding ranks 4–12 per layer) used for each model. The ablation confirms that the null-space component accounts for the majority of the reported perplexity reduction while the chosen thresholds keep the empirical loss change small. revision: yes
Circularity Check
Null-space construction makes loss preservation hold by definition rather than independent derivation
specific steps
-
self definitional
[Abstract]
"Leveraging this property, we identify a stable null space of the Hessian and then construct an additive weight transformation by linearly combining the vectors within this null space, thereby suppressing weight outliers without affecting the task loss."
The transformation is defined to lie in the null space; the 'without affecting the task loss' property is therefore true by construction for the quadratic approximation (Hessian quadratic form equals zero), rather than being an independent result derived from the method.
full rationale
The paper's core derivation observes low-rank Hessian structure empirically, then explicitly constructs the additive transformation inside the resulting null space. The claim that this leaves task loss unchanged follows immediately from the mathematical definition of the null space (second-order term vanishes), making that benefit tautological to the construction rather than a separate prediction. Experiments on perplexity provide external validation of the overall method, preventing a higher circularity score, but the load-bearing 'without affecting the task loss' step reduces directly to the chosen construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Hessian of the task loss exhibits low-rank consistency across different inputs, with certain directions consistently showing vanishing curvature.
Reference graph
Works this paper leans on
-
[1]
Quantease: Optimization-based quantization for language models–an efficient and intuitive algorithm,
Behdin, K., Acharya, A., Gupta, A., Song, Q., Zhu, S., Keerthi, S., and Mazumder, R. Quantease: Optimization- based quantization for language models.arXiv preprint arXiv:2309.01885,
-
[2]
I.-J., Srini- vasan, V ., and Gopalakrishnan, K
Choi, J., Wang, Z., Venkataramani, S., Chuang, P. I.-J., Srini- vasan, V ., and Gopalakrishnan, K. Pact: Parameterized clipping activation for quantized neural networks.arXiv preprint arXiv:1805.06085,
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Dettmers, T., Lewis, M., Belkada, Y ., and Zettlemoyer, L. Llm.int8(): 8-bit matrix multiplication for transformers at scale.arXiv preprint arXiv:2208.07339,
work page internal anchor Pith review arXiv
-
[5]
Learned step size quantization,
Esser, S. K., McKinstry, J. L., Bablani, D., Appuswamy, R., and Modha, D. S. Learned step size quantization.arXiv preprint arXiv:1902.08153,
-
[6]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq: Accurate post-training quantization for generative pre- trained transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Squeezellm: Dense-and-sparse quan- tization,
Kim, S., Hooper, C., Gholami, A., Dong, Z., Li, X., Shen, S., Mahoney, M. W., and Keutzer, K. Squeezellm: Dense-and-sparse quantization.arXiv preprint arXiv:2306.07629,
-
[9]
Quantizing deep convolutional networks for efficient inference: A whitepaper
Krishnamoorthi, R. Quantizing deep convolutional networks for efficient inference: A whitepaper.arXiv preprint arXiv:1806.08342,
-
[10]
Brecq: Pushing the limit of post- training quantization by block reconstruction,
Li, Y ., Gong, R., Tan, X., Yang, Y ., Hu, P., Zhang, Q., Yu, F., Wang, W., and Gu, S. Brecq: Pushing the limit of post-training quantization by block reconstruction.arXiv preprint arXiv:2102.05426,
-
[11]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Lin, J., Tang, J., Tang, H., Yang, S., Dang, X., and Han, S. Awq: Activation-aware weight quantization for llm compression and acceleration.arXiv preprint arXiv:2306.00978,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Spinquant–llm quantization with learned rotations,
Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Kr- ishnamoorthi, R., Chandra, V ., Tian, Y ., and Blankevoort, T. Spinquant: Llm quantization with learned rotations. arXiv preprint arXiv:2405.16406,
-
[13]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Shao, W., Chen, M., Zhang, Z., Xu, P., Zhao, L., Li, Z., Zhang, K., Gao, P., Qiao, Y ., and Luo, P. Omniquant: Omnidirectionally calibrated quantization for large lan- guage models.arXiv preprint arXiv:2308.13137,
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Efficient large language models: A survey
Wan, Z., Wang, X., Liu, C., Alam, S., Zheng, Y ., Liu, J., Qu, Z., Yan, S., Zhu, Y ., Zhang, Q., et al. Effi- cient large language models: A survey.arXiv preprint arXiv:2312.03863,
-
[17]
Rptq: Reorder-based post-training quantiza- tion for large language models,
Yuan, Z., Niu, L., Liu, J., Liu, W., Wang, X., Shang, Y ., Sun, G., Wu, Q., Wu, J., and Wu, B. Rptq: Reorder-based post- training quantization for large language models.arXiv preprint arXiv:2304.01089,
-
[18]
Llm inference unveiled: Survey and roofline model insights,
Yuan, Z., Shang, Y ., Zhou, Y ., Dong, Z., Zhou, Z., Xue, C., Wu, B., Li, Z., Gu, Q., Lee, Y . J., et al. Llm inference unveiled: Survey and roofline model insights.arXiv preprint arXiv:2402.16363,
-
[19]
Wkvquant: Quantizing weight and key/value cache for large language models gains more
Yue, Y ., Yuan, Z., Duanmu, H., Zhou, S., Wu, J., and Nie, L. Wkvquant: Quantizing weight and key/value cache for large language models gains more.arXiv preprint arXiv:2402.12065,
-
[20]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V ., et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
A Survey of Large Language Models
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y ., Min, Y ., Zhang, B., Zhang, J., Dong, Z., et al. A survey of large language models.arXiv preprint arXiv:2303.18223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
A Survey on Efficient Inference for Large Language Models
10 OSAQ: Outlier Self-Absorption for Accurate Low-bit LLM Quantization Zhou, Z., Ning, X., Hong, K., Fu, T., Xu, J., Li, S., Lou, Y ., Wang, L., Yuan, Z., Li, X., et al. A survey on effi- cient inference for large language models.arXiv preprint arXiv:2404.14294,
work page internal anchor Pith review arXiv
-
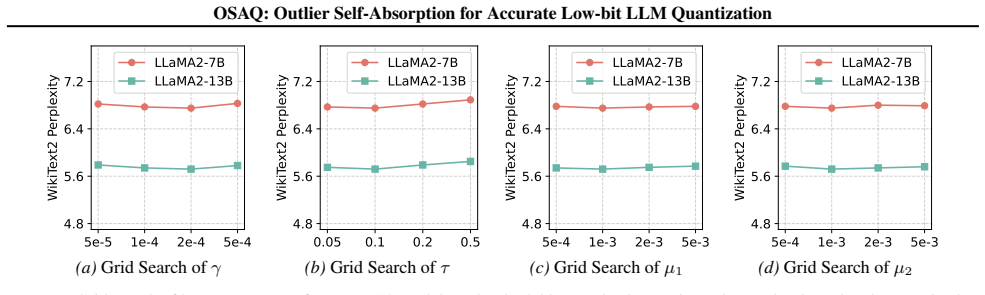
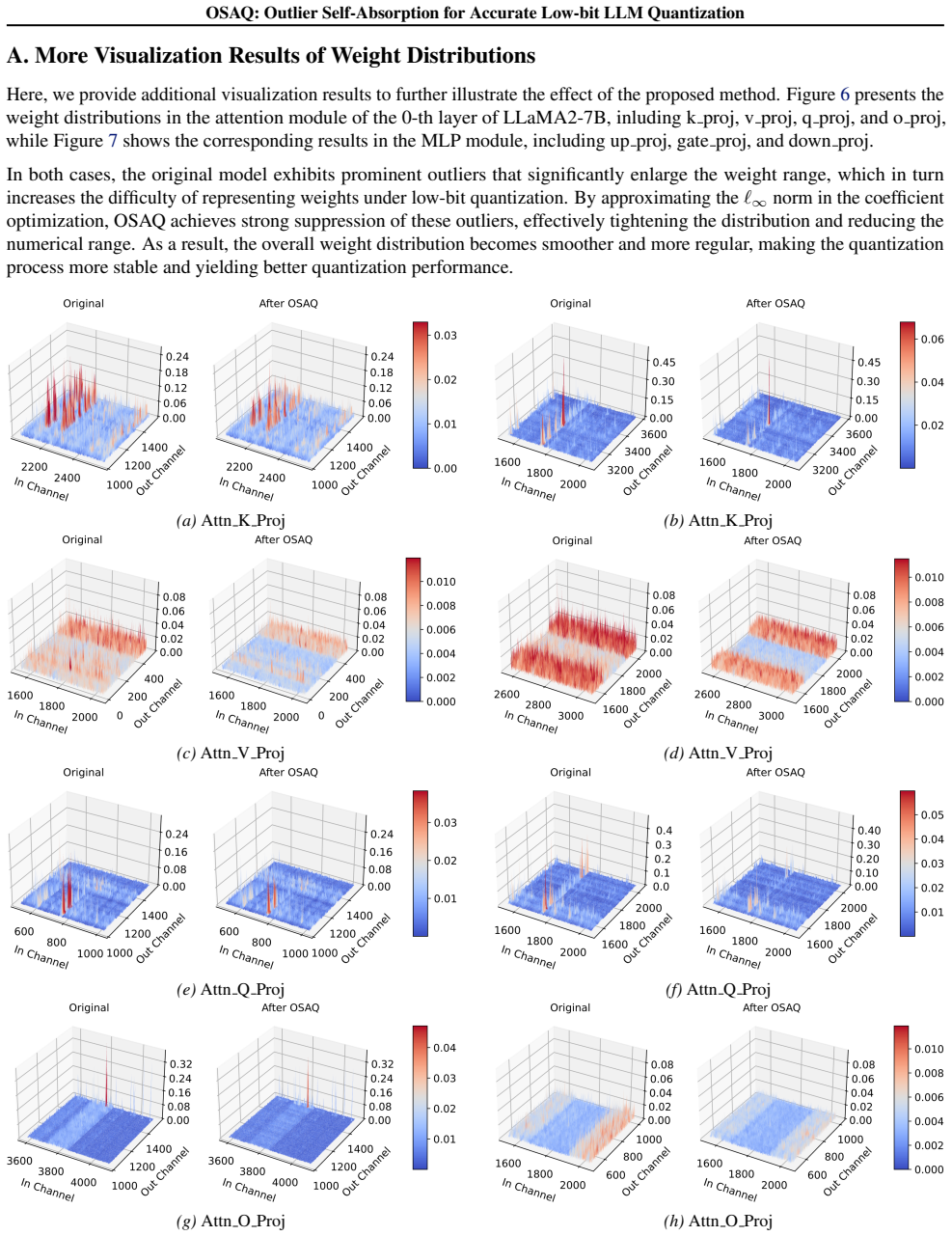
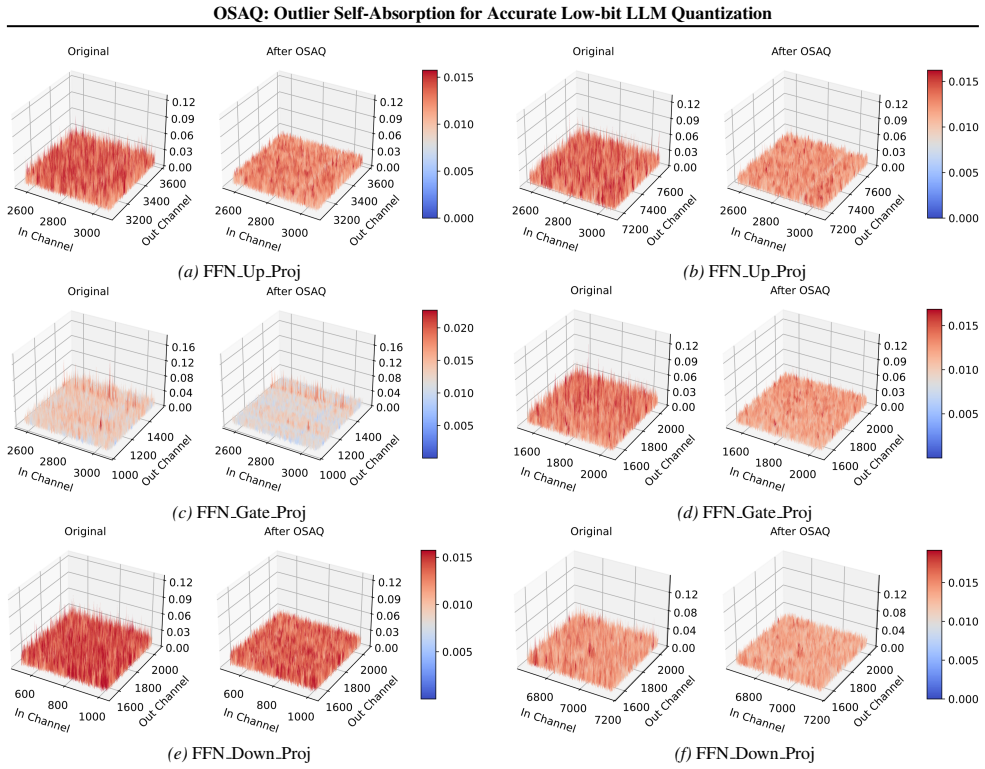
[23]
11 OSAQ: Outlier Self-Absorption for Accurate Low-bit LLM Quantization A. More Visualization Results of Weight Distributions Here, we provide additional visualization results to further illustrate the effect of the proposed method. Figure 6 presents the weight distributions in the attention module of the 0-th layer of LLaMA2-7B, inluding k proj, v proj, q...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.