Recognition: 2 theorem links
· Lean TheoremTrustworthy Federated Label Distribution Learning under Annotation Quality Disparity
Pith reviewed 2026-05-12 02:18 UTC · model grok-4.3
The pith
In federated label distribution learning with varying annotation quality, client-specific calibration is strictly better than any uniform calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
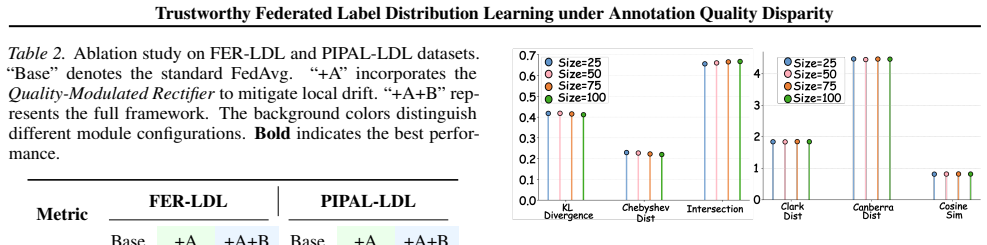
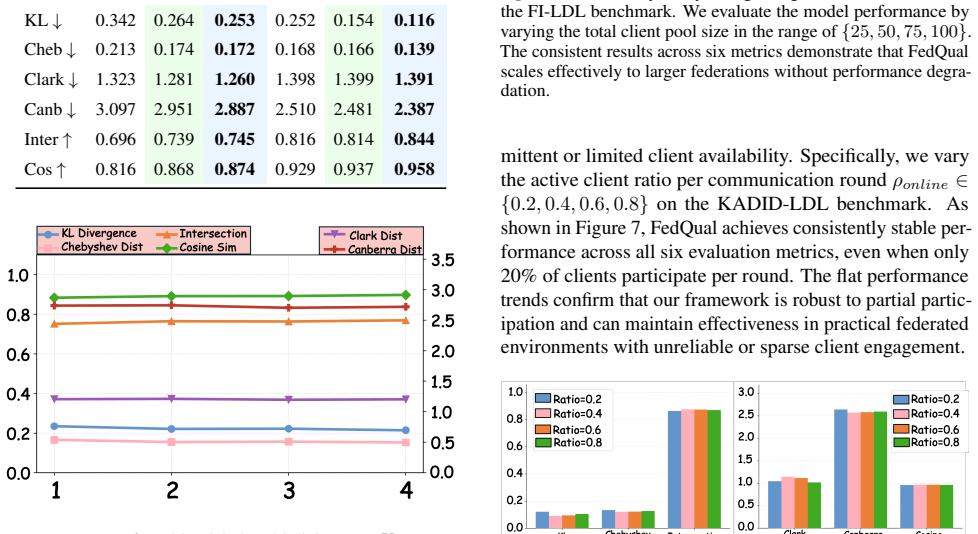
We propose FedQual, a quality-aware Fed-LDL framework with quality-adaptive client training guided by a global semantic anchor and reliability-aware server aggregation. We provide a theoretical guarantee showing that under heterogeneous supervision quality, client-specific calibration is strictly better than any uniform calibration. We construct four new Fed-LDL benchmarks with controlled annotation quality disparity.
What carries the argument
Quality-adaptive client training guided by a global semantic anchor that calibrates low-quality clients while preserving high-quality autonomy, paired with reliability-aware server aggregation that reweights by effective reliable information instead of sample size.
If this is right
- Local model updates from low-quality clients become more reliable through targeted calibration without affecting high-quality clients.
- Server aggregation prioritizes clients with more effective reliable information, improving global model quality.
- Standard sample-size-based methods like FedAvg are outperformed in heterogeneous quality scenarios.
- The theoretical result implies that uniform approaches cannot achieve optimal performance when quality varies.
Where Pith is reading between the lines
- This suggests that in real deployments, identifying a shared semantic structure could help bootstrap quality improvement across clients.
- Applications in domains with varying expert annotation qualities could retain more data without forcing uniform standards.
- Dynamic quality estimation that updates as the model trains might reduce reliance on fixed anchors.
Load-bearing premise
A usable global semantic anchor exists that can calibrate low-quality clients while preserving high-quality autonomy, and that effective reliable information per client can be quantified without circular dependence on the final model performance.
What would settle it
Observing on one of the new benchmarks that a uniform calibration strategy matches or exceeds the performance of client-specific calibration would contradict the theoretical guarantee.
Figures




read the original abstract
Label Distribution Learning (LDL) models supervision as an instance-wise probability distribution, enabling fine-grained learning under inherent ambiguity, but its success relies on high-fidelity label distributions that are costly to obtain and thus often noisy. Motivated by privacy-sensitive applications, we study Federated Label Distribution Learning (Fed-LDL), where data isolation further induces heterogeneous annotation quality across clients, making local updates unevenly reliable and breaking sample-size-based aggregation (e.g., FedAvg). To address this trust dilemma, we propose FedQual, a quality-aware Fed-LDL framework with two coupled mechanisms: (i) quality-adaptive client training guided by a global semantic anchor that calibrates low-quality clients while preserving high-quality autonomy, and (ii) reliability-aware server aggregation that reweights client contributions by effective reliable information rather than raw sample size. To enable rigorous evaluation, we construct four new Fed-LDL benchmarks (FER-LDL, FI-LDL, PIPAL-LDL, and KADID-LDL) with controlled annotation quality disparity. We further provide a theoretical guarantee showing that under heterogeneous supervision quality, client-specific calibration is strictly better than any uniform calibration. Extensive experiments on the proposed benchmarks demonstrate the effectiveness of FedQual.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FedQual, a quality-aware framework for Federated Label Distribution Learning (Fed-LDL) under heterogeneous annotation quality. It couples a global semantic anchor for client-specific calibration (preserving high-quality client autonomy) with reliability-aware server aggregation that reweights contributions by effective reliable information rather than sample size. Four new benchmarks (FER-LDL, FI-LDL, PIPAL-LDL, KADID-LDL) with controlled quality disparity are constructed, a theoretical guarantee is provided that client-specific calibration is strictly superior to any uniform calibration under heterogeneous supervision, and experiments demonstrate effectiveness.
Significance. If the central theoretical claim holds without circular dependence, the work meaningfully advances trustworthy federated learning for label-distribution tasks by replacing sample-size aggregation with quality-aware mechanisms and supplying both a strict superiority result and new evaluation benchmarks. These elements would be useful for privacy-sensitive applications where annotation quality varies.
major comments (1)
- [Theoretical Analysis] The theoretical guarantee (abstract and theoretical analysis section) asserts strict superiority of client-specific calibration over uniform calibration under heterogeneous quality, relying on the global semantic anchor providing an independent high-fidelity reference. However, the anchor is constructed from aggregated client updates whose reliability weights are defined in terms of effective reliable information (itself model-dependent). This introduces a potential circularity that could violate the independence assumption required for the strict inequality; the proof should explicitly derive or assume non-circularity of the anchor construction.
minor comments (2)
- [Benchmark Construction] The description of how controlled annotation quality disparity is injected into the four new benchmarks would benefit from additional implementation details to support reproducibility.
- [Preliminaries and Method] Notation for 'effective reliable information' and the precise definition of the global semantic anchor should be introduced earlier and used consistently to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful feedback on our manuscript. We address the major comment regarding the theoretical analysis below. We agree that greater clarity is needed on the independence assumptions and will revise accordingly.
read point-by-point responses
-
Referee: [Theoretical Analysis] The theoretical guarantee (abstract and theoretical analysis section) asserts strict superiority of client-specific calibration over uniform calibration under heterogeneous quality, relying on the global semantic anchor providing an independent high-fidelity reference. However, the anchor is constructed from aggregated client updates whose reliability weights are defined in terms of effective reliable information (itself model-dependent). This introduces a potential circularity that could violate the independence assumption required for the strict inequality; the proof should explicitly derive or assume non-circularity of the anchor construction.
Authors: We thank the referee for identifying this important point on potential circularity. The theoretical result shows that, under heterogeneous supervision, client-specific calibration (guided by the anchor) is strictly superior to any uniform calibration because it preserves autonomy for high-quality clients while correcting low-quality ones. The proof treats the global semantic anchor as an independent high-fidelity reference whose construction is separate from the per-client calibration step being analyzed. In the algorithm the anchor is formed via reliability-weighted aggregation, where weights reflect effective reliable information derived from divergence to the current anchor; however, the superiority inequality is derived conditionally on the anchor already being fixed and of higher average fidelity than the heterogeneous client distributions. This conditional framing avoids direct circular dependence in the mathematical argument. That said, we acknowledge the referee's concern that the iterative nature of anchor construction could be stated more explicitly to rule out any implicit dependence. In the revised manuscript we will (i) add an explicit assumption statement in the theoretical analysis section that the anchor is independent of the calibrated client models for the purpose of the inequality, (ii) provide a short derivation showing that the reliability weights are computed from the pre-calibration models and therefore do not create a feedback loop within the proof, and (iii) include a brief remark on how the iterative procedure converges to a stable anchor without violating the strict inequality. These changes will strengthen the rigor of the theoretical contribution without altering its core claim. revision: yes
Circularity Check
No significant circularity; theoretical guarantee presented as independent
full rationale
The abstract and description outline a theoretical guarantee that client-specific calibration is strictly better than uniform calibration under heterogeneous supervision quality. No equations, self-citations, or derivations are visible that reduce this claim by construction to fitted parameters, self-definitions, or load-bearing self-citations. Reliability-aware aggregation and the global semantic anchor are described as mechanisms to address the problem, but without exhibited reduction to inputs (e.g., no shown equivalence like reliability weight = model performance by definition), the derivation chain remains self-contained against external benchmarks. This is the expected honest non-finding for papers without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A global semantic anchor can be maintained that calibrates low-quality clients while preserving high-quality autonomy
- domain assumption Effective reliable information contributed by each client can be measured independently of final model performance
invented entities (1)
-
FedQual framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1 ... Jadapt < Juni ... lambda^*_m = sigma_m^2 / (sigma_m^2 + delta_m^2)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Global Semantic Anchor A(x) ≜ z(x; w^t_g) ... alpha_m = sigma(beta (lambda(q_m) - lambda_0))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https: //doi.org/10.1109/JBHI.2021.3095128
doi: 10.1109/JBHI.2021.3095128. URL https: //doi.org/10.1109/JBHI.2021.3095128. Chen, H. and Chao, W. Fedbe: Making bayesian model ensemble applicable to federated learning. In9th Inter- national Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenRe- view.net, 2021. URL https://openreview.net/ forum?id=dgtpE6gKjH...
-
[2]
URL https: //doi.org/10.1109/TPAMI.2007.70733
doi: 10.1109/TPAMI.2007.70733. URL https: //doi.org/10.1109/TPAMI.2007.70733. Goodfellow, I. J., Erhan, D., Carrier, P. L., Courville, A. C., Mirza, M., Hamner, B., Cukierski, W., Tang, Y ., Thaler, D., Lee, D., Zhou, Y ., Ramaiah, C., Feng, F., Li, R., Wang, X., Athanasakis, D., Shawe-Taylor, J., Milakov, M., Park, J., Ionescu, R. T., Popescu, M., Grozea...
-
[4]
URL https: //doi.org/10.1609/aaai.v38i4.28095
doi: 10.1609/AAAI.V38I4.28095. URL https: //doi.org/10.1609/aaai.v38i4.28095. Li, Q., He, B., and Song, D. Model-contrastive federated learning. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pp. 10713–10722. Computer Vision Foundation / IEEE, 2021. doi: 10.1109/CVPR46437.2021.01057. URL https: //openac...
-
[5]
org/paper_files/paper/2020/hash/ 1f5fe83998a09396ebe6477d9475ba0c-Abstract
URL https://proceedings.mlsys. org/paper_files/paper/2020/hash/ 1f5fe83998a09396ebe6477d9475ba0c-Abstract. html. 10 Trustworthy Federated Label Distribution Learning under Annotation Quality Disparity Li, X., Liang, X., Luo, G., Wang, W., Wang, K., and Li, S. ULTRA: uncertainty-aware label distribution learn- ing for breast tumor cellularity assessment. I...
-
[6]
Ren, T., Jia, X., Li, W., and Zhao, S
URL http://proceedings.mlr.press/ v54/mcmahan17a.html. Ren, T., Jia, X., Li, W., and Zhao, S. Label distribu- tion learning with label correlations via low-rank ap- proximation. In Kraus, S. (ed.),Proceedings of the Twenty-Eighth International Joint Conference on Ar- tificial Intelligence, IJCAI 2019, Macao, China, Au- gust 10-16, 2019, pp. 3325–3331. ijc...
-
[7]
URL https://doi.org/10.24963/ijcai. 2017/443. Xu, N., Liu, Y ., and Geng, X. Label enhancement for label distribution learning.IEEE Trans. Knowl. Data Eng., 33(4):1632–1643, 2021. doi: 10.1109/ TKDE.2019.2947040. URL https://doi.org/10. 1109/TKDE.2019.2947040. Xu, S., Shang, L., Shen, F., Yang, X., and Pedrycz, W. Incomplete label distribution learning vi...
-
[8]
However, these approaches generally target discrete categorical noise
introduces an end-to-end framework for noisy label correction, while FedES (Zeng et al., 2024) utilizes federated early-stopping to prevent models from memorizing noisy patterns. However, these approaches generally target discrete categorical noise. They typically treat noise as binary errors, making them ill-equipped for tasks requiring dense, continuous...
work page 2024
-
[9]
employ low-rank approximation to model these dependencies, while others (Xu & Zhou, 2017; Xu et al., 2025) utilize correlation decomposition mechanisms to effectively complete missing label information in sparse distribution settings. Despite their effectiveness, these remediation strategies predominantly rely on a centralized data access assumption, wher...
work page 2017
-
[10]
FIThis dataset is a large-scale benchmark for affective computing which consists of over 23,000 real-world images collected from social media platforms (Flickr and Instagram) (You et al., 2016). The original annotations define eight emotion categories based on Mikels’ psychological model: Amusement, Anger, Awe, Contentment, Disgust, Excitement, Fear, and ...
work page 2016
-
[11]
All images are standardized to a resolution of 512×384 pixels
KADID-10kThe Konstanz Artificially Distorted Image quality Database (KADID-10k) contains 10,125 distorted images derived from 81 pristine reference images collected from Pixabay (Lin et al., 2019). All images are standardized to a resolution of 512×384 pixels. The dataset covers 25 distortion types (including blur, color shifts, and compression) across 5 ...
work page 2019
-
[12]
PIPALThe Perceptual Image Processing ALgorithms (PIPAL) dataset is a large-scale IQA benchmark explicitly designed to evaluate Image Restoration (IR) algorithms (Gu et al., 2020). It contains 29,000 distorted images generated from 250 high-quality reference patches (288×288 pixels) selected from the DIV2K and Flickr2K datasets. A distinguishing feature of...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.