Recognition: unknown
Replay-Based Continual Learning for Physics-Informed Neural Operators
Pith reviewed 2026-05-08 17:19 UTC · model grok-4.3
The pith
A replay-based strategy lets physics-informed neural operators adapt to new physical problems without forgetting prior ones and without needing labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replaying a limited number of previous input fields and applying a distillation loss based solely on physical constraints, together with a low-rank adaptation module, the method preserves performance on earlier distributions while rapidly incorporating new out-of-distribution data, all in a fully unsupervised, physics-informed setting.
What carries the argument
Replay buffer of past input fields plus distillation on physical laws, paired with LoRA for parameter-efficient adaptation to new data.
If this is right
- Memory and compute costs drop relative to retraining on all accumulated data at each step.
- The approach scales to multiple physical domains without requiring task-specific labels.
- Training time for each new problem shortens while old-task performance remains stable.
- The framework applies directly to operator architectures built on Transolver and similar backbones.
Where Pith is reading between the lines
- If the replay size can be kept very small across many sequential tasks, the method could support lifelong learning pipelines for evolving simulation environments.
- The reliance on input fields alone suggests possible extension to settings where only boundary conditions or geometry change over time.
- Success here raises the question of whether similar replay-plus-distillation ideas transfer to other operator-learning architectures beyond the tested Transolver base.
Load-bearing premise
Replaying a small number of past input fields together with a distillation constraint on physical laws is sufficient to preserve prior knowledge without any labeled data or access to the original training distribution.
What would settle it
An experiment in which accuracy on the original physical problems falls sharply after sequential training on new out-of-distribution cases even when the replay buffer and distillation terms are active.
Figures
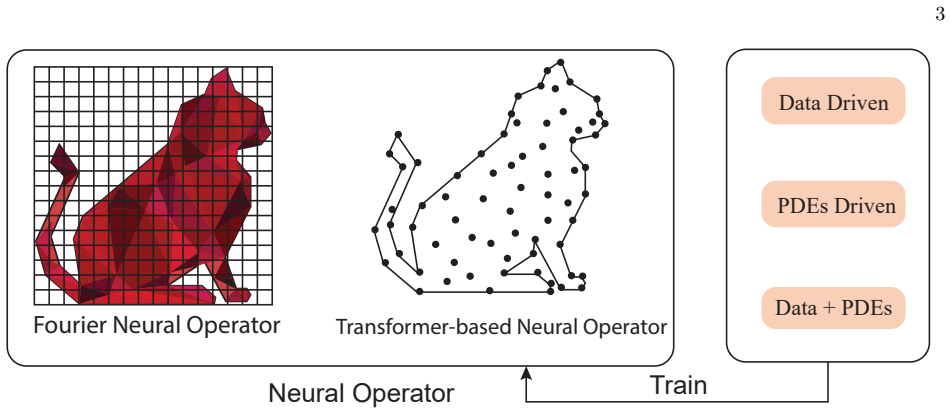



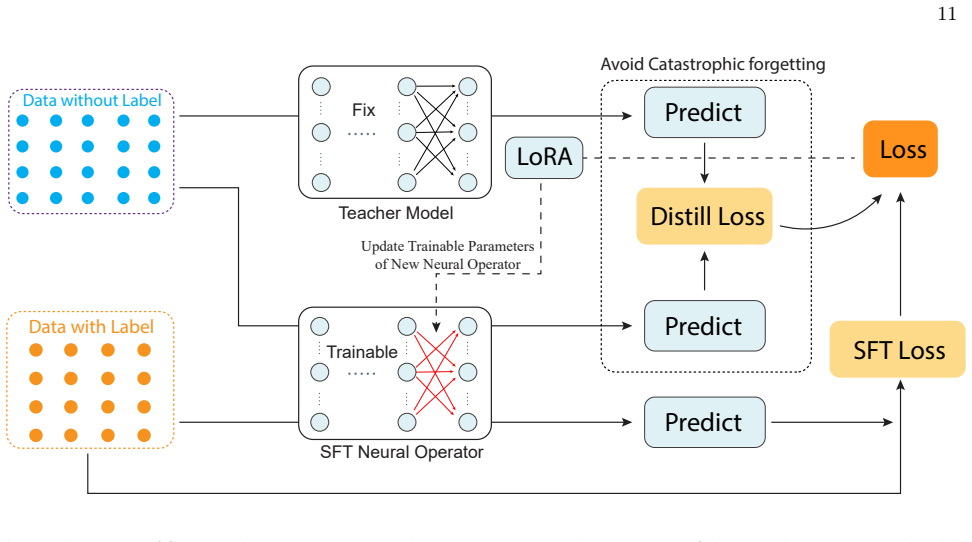


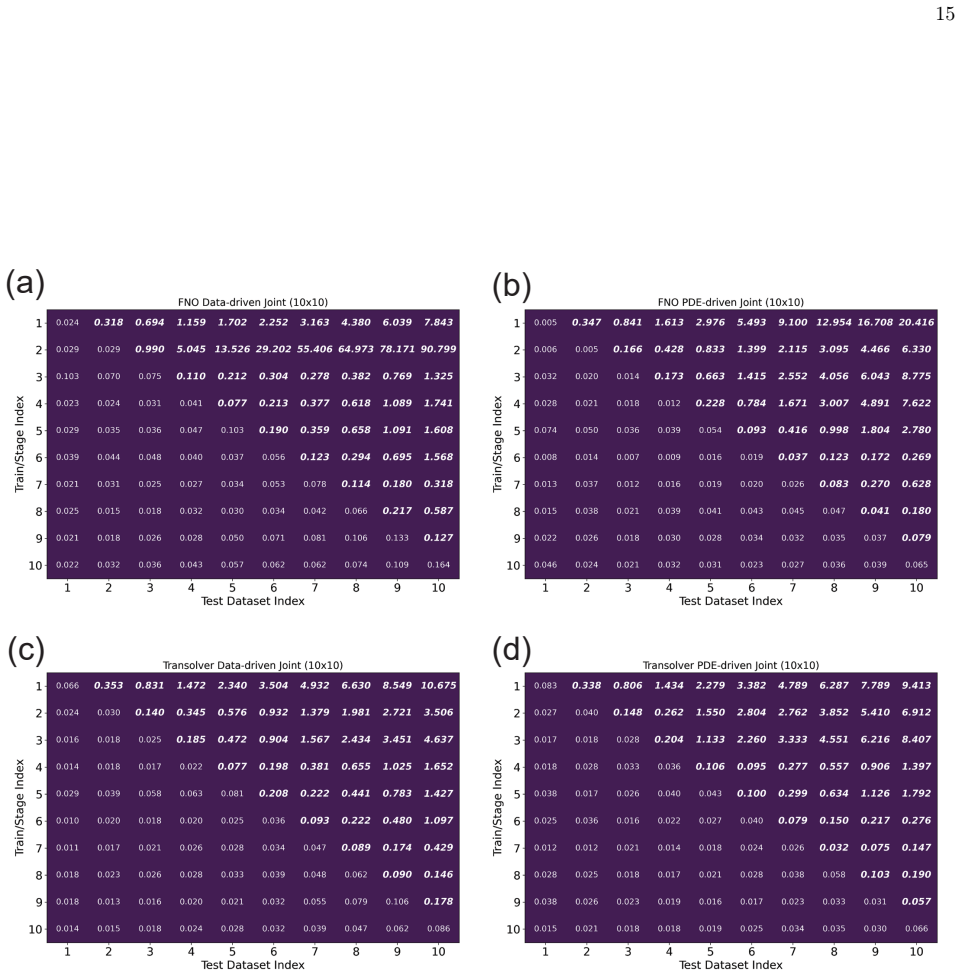

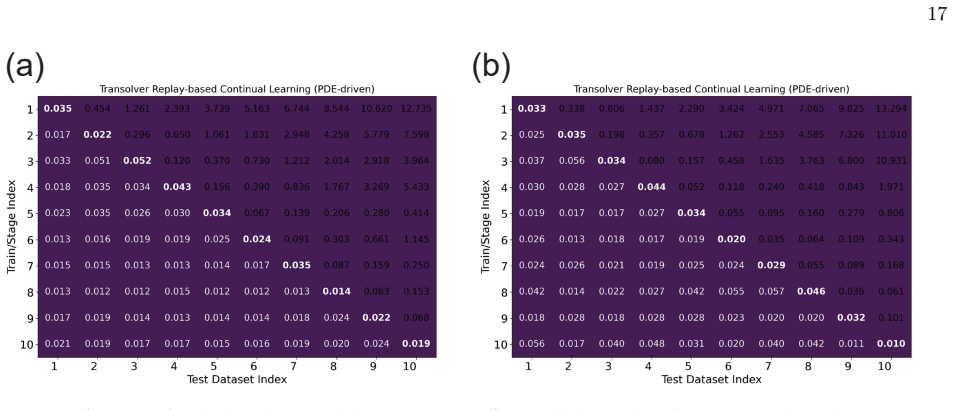










read the original abstract
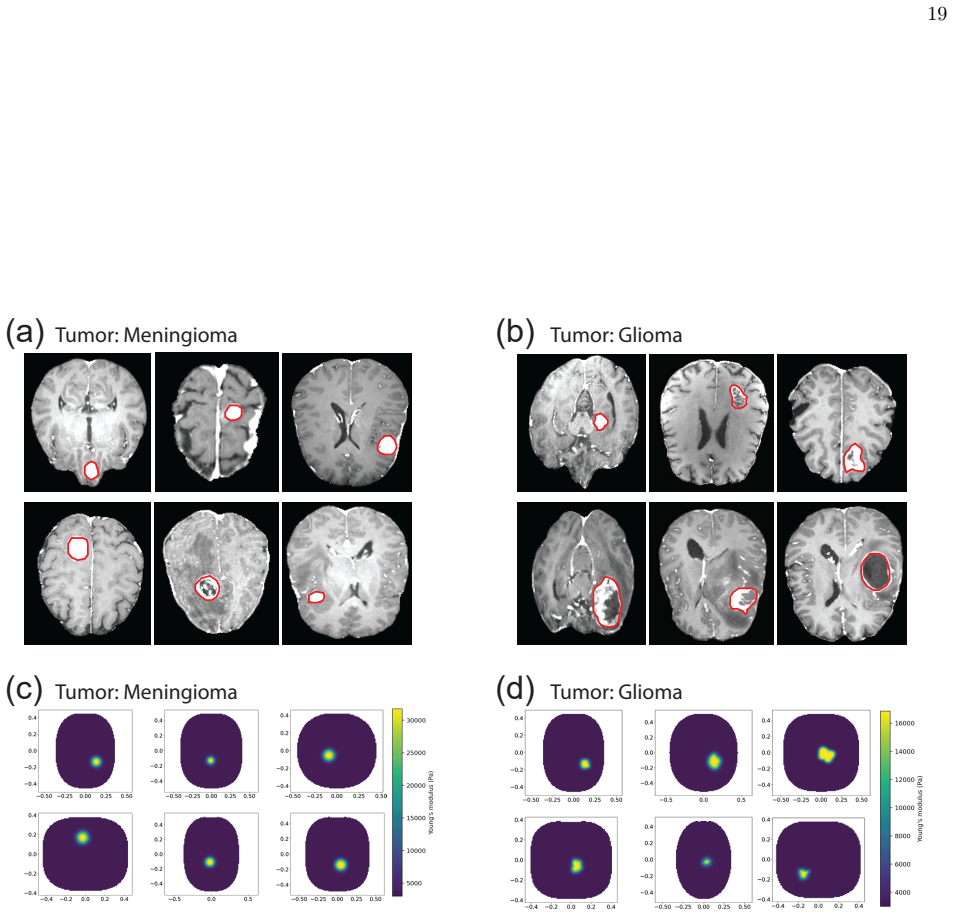
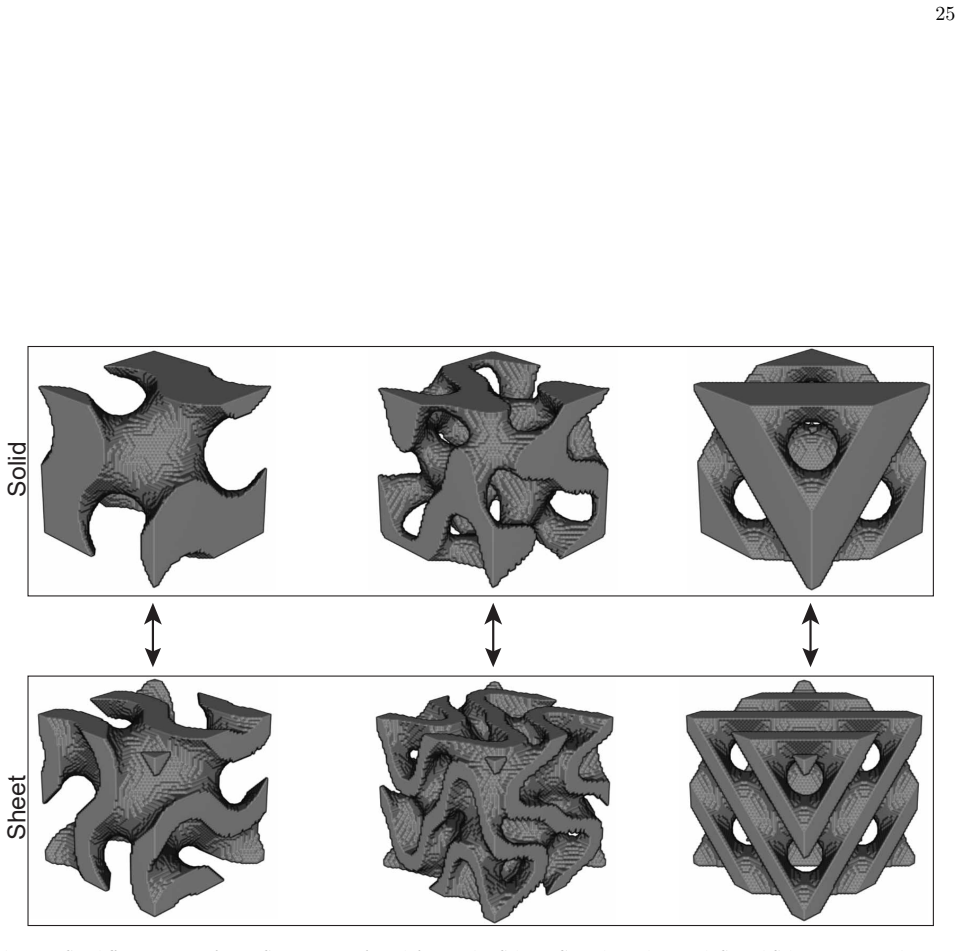
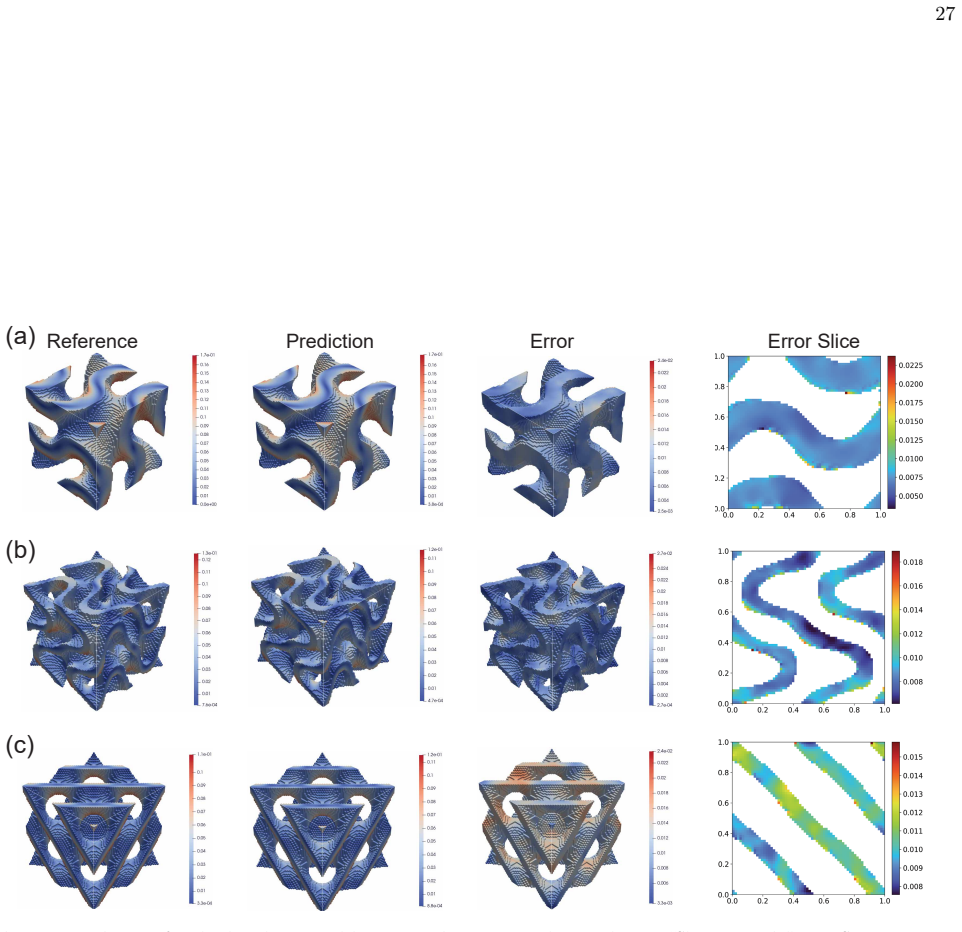
Neural operators generally demonstrate strong predictive performance on in-distribution (ID) problems. However, a critical limitation of existing methods is their significant performance degradation when encountering out-of-distribution (OOD) data. To address this issue, this work introduces continual learning into physics-informed neural operators, with particular emphasis on neural operators built upon the Transolver architecture, and proposes a simple yet effective replay-based continual learning strategy. The proposed method is fully physics-informed and does not require labeled data, relying solely on input fields together with physical constraints for training. When new OOD data become available, a small number of past data are incorporated through a distillation-based constraint to preserve previously acquired knowledge and alleviate catastrophic forgetting. Meanwhile, a transfer learning LoRA is employed to enable rapid adaptation to the new data. The proposed framework is systematically validated on three representative physical problems, including the Darcy flow problem in fluid mechanics, a two-dimensional hyperelastic brain tumor problem in biomechanics, and a three-dimensional linear elastic Triply Periodic Minimal Surfaces problem in solid mechanics. The results demonstrate that the proposed method effectively mitigates catastrophic forgetting on previously learned data while maintaining fast adaptability to new data. Compared with conventional joint training strategies, the proposed method significantly improves training efficiency while reducing additional memory usage and computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a replay-based continual learning strategy for physics-informed neural operators (PINOs) built on the Transolver architecture. When new out-of-distribution data arrives, a small replay buffer of past input fields is combined with a physics-law distillation loss (no labels required) to preserve prior knowledge and reduce catastrophic forgetting; LoRA is used for fast adaptation to the new task. The framework is evaluated on the Darcy flow problem, a 2D hyperelastic brain-tumor problem, and a 3D linear-elastic TPMS problem, with claims of effective forgetting mitigation, rapid adaptability, and lower memory/compute cost than joint retraining.
Significance. If the empirical claims hold under rigorous coverage analysis, the work would be a useful contribution to continual learning for scientific machine learning. It demonstrates a label-free, physics-constrained replay mechanism that could reduce the cost of adapting neural operators to new physical regimes, a practical bottleneck in deploying PINOs for multi-task or streaming scientific data.
major comments (2)
- [§3 and §4] The central claim that replaying a small number of past input fields plus PDE-residual distillation suffices to prevent operator drift (abstract and §3) rests on an unverified coverage assumption. In high-dimensional function spaces typical of Darcy, hyperelasticity, and elasticity operators, a fixed-size replay buffer chosen without diversity or importance sampling can leave large regions of the prior input manifold unconstrained; the distillation term only enforces the PDE on those few points, allowing silent deviation elsewhere. No analysis of replay selection strategy, buffer-size sensitivity, or out-of-buffer generalization is provided in the experiments (§4).
- [§4] The reported performance gains over joint training (abstract) are not accompanied by quantitative tables, ablation studies on replay size, or statistical significance tests in the provided description. Without these, it is impossible to assess whether the efficiency and forgetting-mitigation claims are load-bearing or merely qualitative.
minor comments (2)
- [§3] Notation for the distillation loss and LoRA adaptation should be introduced with explicit equations rather than high-level description.
- [§3] Clarify whether the replay samples are drawn from the original training distribution or generated on-the-fly; this affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have carefully reviewed each point and provide point-by-point responses below. We agree that additional analyses will strengthen the paper and commit to incorporating them in the revision.
read point-by-point responses
-
Referee: [§3 and §4] The central claim that replaying a small number of past input fields plus PDE-residual distillation suffices to prevent operator drift (abstract and §3) rests on an unverified coverage assumption. In high-dimensional function spaces typical of Darcy, hyperelasticity, and elasticity operators, a fixed-size replay buffer chosen without diversity or importance sampling can leave large regions of the prior input manifold unconstrained; the distillation term only enforces the PDE on those few points, allowing silent deviation elsewhere. No analysis of replay selection strategy, buffer-size sensitivity, or out-of-buffer generalization is provided in the experiments (§4).
Authors: We appreciate the referee highlighting the coverage assumption underlying our replay-based approach. Our framework uses a small replay buffer of past input fields together with PDE-residual distillation (no labels) to constrain operator drift, and LoRA for adaptation. In §4 we evaluate this on three problems spanning 2D and 3D domains (Darcy flow, hyperelastic brain tumor, 3D linear-elastic TPMS) and report that small buffers suffice to maintain prior-task accuracy. We acknowledge, however, that the current experiments do not include explicit sensitivity studies on buffer size, alternative selection strategies (e.g., diversity sampling), or explicit checks of generalization to inputs outside the replay set. We will add these analyses—including buffer-size ablation curves, discussion of random versus importance-based selection, and out-of-buffer evaluation—to the revised §4 to directly address the coverage concern. revision: yes
-
Referee: [§4] The reported performance gains over joint training (abstract) are not accompanied by quantitative tables, ablation studies on replay size, or statistical significance tests in the provided description. Without these, it is impossible to assess whether the efficiency and forgetting-mitigation claims are load-bearing or merely qualitative.
Authors: We thank the referee for this observation. While the abstract summarizes the efficiency and forgetting-mitigation results, the full §4 already contains quantitative comparisons of our method against joint training and fine-tuning baselines, reporting relative L2 errors and wall-clock training times on the three benchmark problems. To make these claims fully verifiable, we will expand §4 with (i) complete numerical tables, (ii) systematic ablations varying replay buffer size, and (iii) statistical significance testing (means and standard deviations over multiple random seeds together with appropriate hypothesis tests). These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity in the proposed replay-based continual learning framework
full rationale
The paper proposes an empirical replay-based continual learning strategy for physics-informed neural operators that combines a small replay buffer with physics-law distillation and LoRA adaptation. Claims of mitigated forgetting and improved efficiency are supported by direct validation on three PDE problems (Darcy flow, hyperelasticity, elasticity) rather than any derivation that reduces by construction to its own inputs. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the method description or abstract; the central premise remains an externally testable engineering approach.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physical constraints alone, without labels, suffice to train and preserve knowledge in the continual learning setting
Reference graph
Works this paper leans on
-
[1]
S. Wang, H. Wang, P. Perdikaris, Learning the solution operator of parametric partial differential equations with physics-informed deeponets, Science advances 7 (40) (2021) eabi8605
2021
-
[2]
H. Wang, T. Fu, Y. Du, W. Gao, K. Huang, Z. Liu, P. Chandak, S. Liu, P. Van Katwyk, A. Deac, et al., Scientific discovery in the age of artificial intelligence, Nature 620 (7972) (2023) 47–60
2023
-
[3]
N. B. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. M. Stuart, A. Anandkumar, Neural operator: Learning maps between function spaces with applications to pdes., J. Mach. Learn. Res. 24 (89) (2023) 1–97
2023
-
[4]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via deeponet based on the universal approximation theorem of operators, Nature Machine Intelligence 3 (3) (2021) 218–229. doi:10.1038/s42256-021-00302-5
-
[5]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, arXiv preprint arXiv:2010.08895 (2020)
work page internal anchor Pith review arXiv 2010
-
[6]
Z. Hao, Z. Wang, H. Su, C. Ying, Y. Dong, S. Liu, Z. Cheng, J. Song, J. Zhu, Gnot: A general neural operator transformer for operator learning, in: International Conference on Machine Learning, PMLR, 2023, pp. 12556–12569
2023
- [7]
-
[8]
L. Wang, X. Zhang, H. Su, J. Zhu, A comprehensive survey of continual learning: Theory, method and application, IEEE transactions on pattern analysis and machine intelligence 46 (8) (2024) 5362–5383
2024
-
[9]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ra- malho, A. Grabska-Barwinska, et al., Overcoming catastrophic forgetting in neural networks, Proceedings of the national academy of sciences 114 (13) (2017) 3521–3526
2017
-
[10]
Tripura, S
T. Tripura, S. Chakraborty, Neural combinatorial wavelet neural operator for catastrophic forgetting free in-context operator learning of multiple partial differential equations, Computer Physics Communications (2025) 109882. 40
2025
-
[11]
SLE-FNO: Single-Layer Extensions for Task-Agnostic Continual Learning in Fourier Neural Operators
M. Elhadidy, R. M. D’Souza, A. Arzani, Sle-fno: Single-layer extensions for task-agnostic continual learning in fourier neural operators, arXiv preprint arXiv:2603.20410 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
S. S. Menon, T. Mondal, S. Brahmachary, A. Panda, S. M. Joshi, K. Kalyanaraman, A. D. Jagtap, On scientific foundation models: Rigorous definitions, key applications, and a comprehensive survey, Neural Networks (2026) 108567
2026
- [13]
- [14]
- [15]
-
[16]
Walrus: A cross-domain foundation model for continuum dynamics.arXiv preprint arXiv:2511.15684, 2025
M. McCabe, P. Mukhopadhyay, T. Marwah, B. R.-S. Blancard, F. Rozet, C. Diaconu, L. Meyer, K. W. Wong, H. Sotoudeh, A. Bietti, et al., Walrus: A cross-domain foundation model for continuum dynamics, arXiv preprint arXiv:2511.15684 (2025)
-
[17]
K. Bi, L. Xie, H. Zhang, X. Chen, X. Gu, Q. Tian, Accurate medium-range global weather forecasting with 3d neural networks, Nature (2023) 1–6
2023
- [18]
-
[19]
M. S. Eshaghi, C. Anitescu, M. Thombre, Y. Wang, X. Zhuang, T. Rabczuk, Variational physics-informed neural operator (vino) for solving partial differential equations, Computer Methods in Applied Mechanics and Engineering 437 (2025) 117785
2025
-
[20]
Al-Ketan, R
O. Al-Ketan, R. K. Abu Al-Rub, Multifunctional mechanical metamaterials based on triply periodic min- imal surface lattices, Advanced Engineering Materials 21 (10) (2019) 1900524
2019
-
[21]
Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Azizzadenesheli, A. Anandkumar, Physics- informed neural operator for learning partial differential equations, ACM/JMS Journal of Data Science 1 (3) (2024) 1–27
2024
-
[22]
Y. Wang, J. Sun, J. Bai, C. Anitescu, M. S. Eshaghi, X. Zhuang, T. Rabczuk, Y. Liu, Kolmogorov arnold informed neural network: A physics-informed deep learning framework for solving forward and inverse problems based on kolmogorov–arnold networks, Computer Methods in Applied Mechanics and Engineering 433 (2025) 117518
2025
-
[23]
I. Abbes, G. Subbaraj, M. Riemer, N. Islah, B. Therien, T. Tabaru, H. Kingetsu, S. Chandar, I. Rish, Revisiting replay and gradient alignment for continual pre-training of large language models, arXiv preprint arXiv:2508.01908 (2025)
-
[24]
L. Yang, S. Liu, T. Meng, S. J. Osher, In-context operator learning with data prompts for differential equation problems, Proceedings of the National Academy of Sciences 120 (39) (2023) e2310142120
2023
-
[25]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, Lora: Low-rank adaptation of large language models, arXiv preprint arXiv:2106.09685 (2021)
work page internal anchor Pith review arXiv 2021
-
[26]
Y. Wang, J. Bai, M. S. Eshaghi, C. Anitescu, X. Zhuang, T. Rabczuk, Y. Liu, Transfer learning in physics- informed neurals networks: full fine-tuning, lightweight fine-tuning, and low-rank adaptation, International Journal of Mechanical System Dynamics 5 (2) (2025) 212–235. 41
2025
-
[27]
G. Dong, H. Yuan, K. Lu, C. Li, M. Xue, D. Liu, W. Wang, Z. Yuan, C. Zhou, J. Zhou, How abilities in large language models are affected by supervised fine-tuning data composition, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 177–198
2024
-
[28]
L. M. DeAngelis, Brain tumors, New England journal of medicine 344 (2) (2001) 114–123
2001
-
[29]
Ciasca, T
G. Ciasca, T. E. Sassun, E. Minelli, M. Antonelli, M. Papi, A. Santoro, F. Giangaspero, R. Delfini, M. De Spirito, Nano-mechanical signature of brain tumours, Nanoscale 8 (47) (2016) 19629–19643
2016
-
[30]
Chauvet, M
D. Chauvet, M. Imbault, L. Capelle, C. Demene, M. Mossad, C. Karachi, A.-L. Boch, J.-L. Gennisson, M. Tanter, In vivo measurement of brain tumor elasticity using intraoperative shear wave elastography, Ultraschall in der Medizin-European Journal of Ultrasound 37 (06) (2016) 584–590
2016
-
[31]
Miller, K
K. Miller, K. Chinzei, G. Orssengo, P. Bednarz, Mechanical properties of brain tissue in-vivo: experiment and computer simulation, Journal of biomechanics 33 (11) (2000) 1369–1376
2000
-
[32]
Bunevicius, K
A. Bunevicius, K. Schregel, R. Sinkus, A. Golby, S. Patz, Mr elastography of brain tumors, NeuroImage: Clinical 25 (2020) 102109
2020
-
[33]
Wittek, T
A. Wittek, T. Hawkins, K. Miller, On the unimportance of constitutive models in computing brain defor- mation for image-guided surgery, Biomechanics and modeling in mechanobiology 8 (1) (2009) 77–84
2009
-
[34]
Z. Lin, J. Bai, S. Li, X. Chen, B. Li, X.-Q. Feng, A physics-informed neural network framework for sim- ulating creep buckling in growing viscoelastic biological tissues, Computer Methods in Applied Mechanics and Engineering 452 (2026) 118715
2026
-
[35]
E. Calabrese, D. LaBella, Brats-men (2023).doi:10.7303/SYN51514106. URLhttps://repo-prod.prod.sagebase.org/repo/v1/doi/locate?id=syn51514106&type=ENTITY
-
[36]
Calabrese, J
E. Calabrese, J. E. Villanueva-Meyer, J. D. Rudie, A. M. Rauschecker, U. Baid, S. Bakas, S. Cha, J. T. Mongan, C. P. Hess, The university of california san francisco preoperative diffuse glioma mri dataset, Radiology: Artificial Intelligence 4 (6) (2022) e220058
2022
-
[37]
Hashin, et al., Analysis of composite materials, J
Z. Hashin, et al., Analysis of composite materials, J. appl. Mech 50 (2) (1983) 481–505
1983
-
[38]
Guedes, N
J. Guedes, N. Kikuchi, Preprocessing and postprocessing for materials based on the homogenization method with adaptive finite element methods, Computer methods in applied mechanics and engineering 83 (2) (1990) 143–198
1990
-
[39]
Hassani, E
B. Hassani, E. Hinton, A review of homogenization and topology optimization i homogenization theory for media with periodic structure, Computers and Structures 69 (6) (1998) 707–717
1998
-
[40]
Harandi, H
A. Harandi, H. Danesh, K. Linka, S. Reese, S. Rezaei, Spifol: A spectral-based physics-informed finite operator learning for prediction of mechanical behavior of microstructures, Journal of the Mechanics and Physics of Solids (2025) 106219
2025
-
[41]
Y. Wang, X. Li, Z. Yan, S. Ma, J. Bai, B. Liu, X. Zhuang, T. Rabczuk, Y. Liu, A pretraining-finetuning computational framework for material homogenization, International Journal of Mechanical Sciences (2026) 111388
2026
-
[42]
Andreassen, C
E. Andreassen, C. S. Andreasen, How to determine composite material properties using numerical homog- enization, Computational Materials Science 83 (2014) 488–495
2014
-
[43]
J. T. Oden, S. Prudhomme, Goal-oriented error estimation and adaptivity for the finite element method, Computers & mathematics with applications 41 (5-6) (2001) 735–756
2001
-
[44]
Z. Li, D. Z. Huang, B. Liu, A. Anandkumar, Fourier neural operator with learned deformations for pdes on general geometries, Journal of Machine Learning Research 24 (388) (2023) 1–26
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.