Recognition: unknown
Hybrid Iterative Neural Low-Regularity Integrator for Nonlinear Dispersive Equations
Pith reviewed 2026-05-08 17:01 UTC · model grok-4.3
The pith
Augmenting low-regularity integrators with scaled neural corrections yields global error C(ε_net + δ) τ^γ ln(1/τ) for nonlinear dispersive equations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under stated assumptions the global error of the hybrid integrator satisfies C times (network approximation quality plus training shortfall) times tau to the gamma times the natural log of one over tau. The framework augments a base low-regularity integrator with a lightweight neural operator on a latent manifold, trained end-to-end via unrolled iterations that penalize full-trajectory error. The explicit time-step scaling on the correction term guarantees that its contribution to the Lipschitz constant is order tau, producing a Gronwall factor bounded independently of both time step and spatial resolution.
What carries the argument
The HIN-LRI hybrid framework, consisting of a low-regularity integrator augmented by a neural correction term scaled explicitly by the time step and trained on unrolled solver trajectories.
If this is right
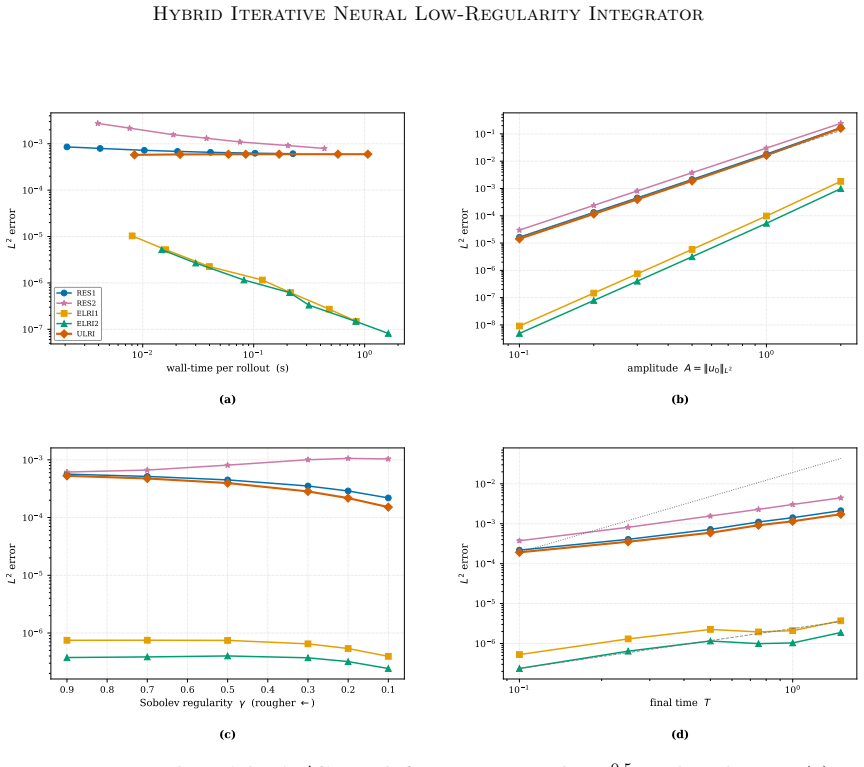
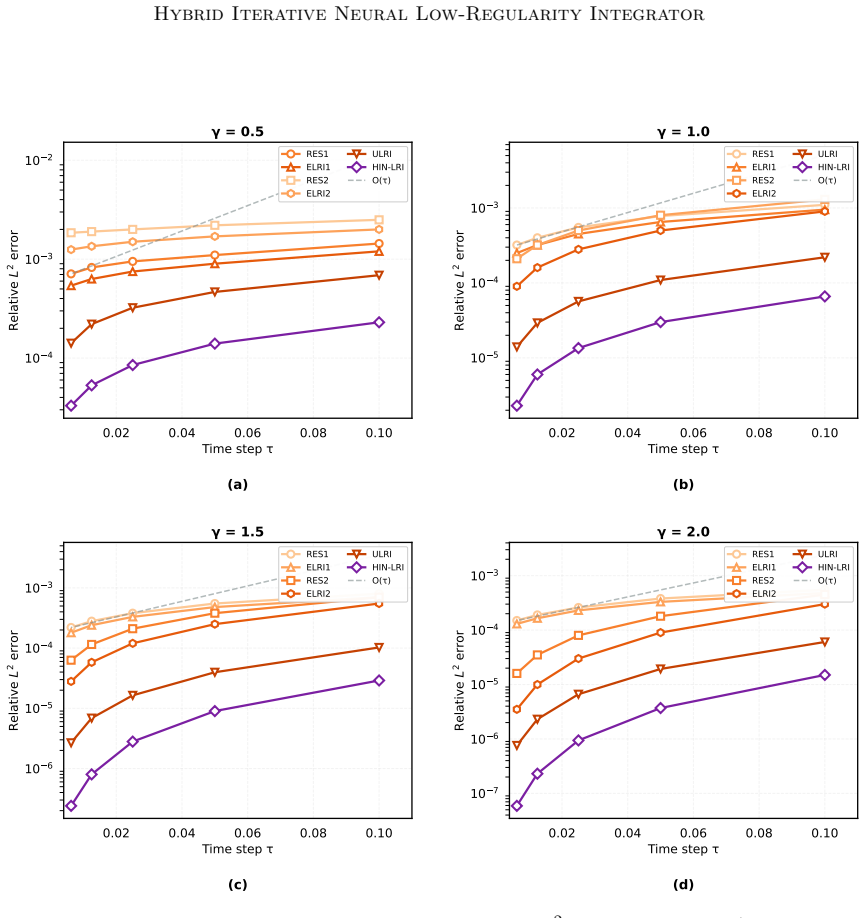
- The hybrid method yields higher accuracy than analytical integrators, splitting methods, and neural PDE surrogates on dispersive benchmarks with rough data.
- Accuracy improves stably as spatial resolution increases.
- Performance transfers well to out-of-distribution initial data without retraining.
- The online computational cost remains modest while preserving theoretical stability properties.
Where Pith is reading between the lines
- The training strategy of penalizing multi-step trajectory errors could be transferred to other numerical methods to enhance their long-term accuracy.
- Uniform stability independent of spatial resolution suggests the approach may scale to very fine grids in high-dimensional simulations.
- If the error bound holds for other dispersive systems, it could guide the design of neural corrections for related wave propagation problems.
Load-bearing premise
The assumption that after scaling the neural correction by the time step, its Lipschitz contribution stays order tau, allowing the Gronwall stability factor to remain bounded independently of spatial resolution even as the network error is small.
What would settle it
Computing the observed global error for decreasing time steps on a dispersive benchmark and checking if it exceeds the predicted C(ε_net + δ) τ^γ ln(1/τ) scaling would falsify the error bound claim.
Figures















read the original abstract
We propose HIN-LRI, a hybrid framework that augments a classical numerical solver with a neural operator trained to correct the solver's structured truncation error. A base low-regularity integrator provides a consistent first-order approximation to nonlinear dispersive PDEs, while a lightweight neural network, operating on a low-dimensional latent manifold, learns the residual defect that analytical methods cannot close. An explicit time-step scaling on the neural correction ensures that its Lipschitz contribution remains $\mathcal{O}(\tau)$, yielding a Gronwall stability factor bounded uniformly in the step size and independent of the spatial resolution. The network is trained end-to-end through a solver-in-the-loop objective that unrolls the full iteration and penalises trajectory error in a Bourgain-type norm, aligning learning with multi-step solver dynamics rather than isolated one-step targets. Under stated assumptions, the global error satisfies $C(\varepsilon_{net}+\delta)\,\tau^\gamma\ln(1/\tau)$, where $\varepsilon_{net}$ measures the network approximation quality and $\delta$ the training shortfall. Experiments on three dispersive benchmarks with rough data show that HIN-LRI improves accuracy over analytical integrators, splitting methods, and neural PDE surrogates, with stable spatial refinement, effective out-of-distribution transfer, and modest online overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HIN-LRI, a hybrid method that augments a classical low-regularity integrator for nonlinear dispersive PDEs with a lightweight neural operator correction operating on a low-dimensional latent manifold. An explicit time-step scaling is applied to the neural term to keep its Lipschitz contribution O(τ), which is used to obtain a Gronwall stability factor bounded uniformly in τ and independent of spatial resolution. The network is trained end-to-end by unrolling the solver and minimizing trajectory error in a Bourgain-type norm. Under stated assumptions the global error is bounded by C(ε_net + δ) τ^γ ln(1/τ). Experiments on three dispersive benchmarks with rough initial data report improved accuracy relative to analytical integrators, splitting methods, and neural PDE surrogates, together with stable spatial refinement and out-of-distribution transfer.
Significance. If the claimed error bound and its uniformity with respect to spatial resolution can be rigorously established, the work would offer a concrete route to higher-order accuracy for low-regularity solutions of dispersive equations while retaining the consistency properties of the underlying integrator. The end-to-end training objective that aligns with multi-step dynamics and the modest online overhead are practical strengths. The experimental gains on rough-data benchmarks suggest potential utility beyond purely analytical or purely data-driven approaches, provided the Lipschitz-control assumption holds uniformly.
major comments (2)
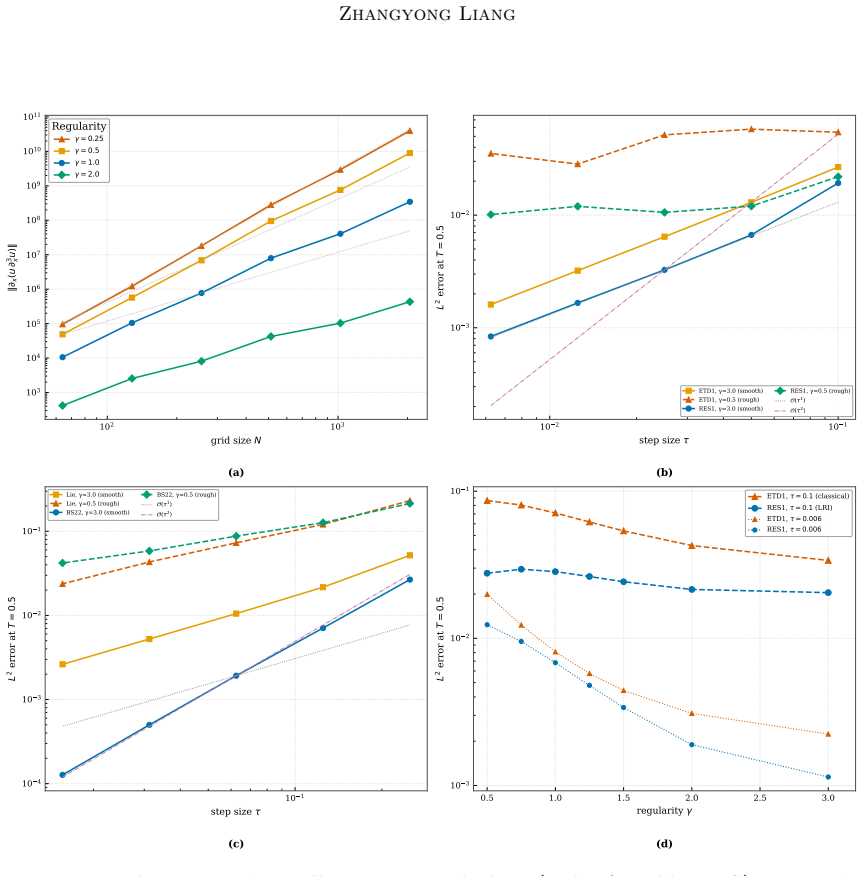
- [Abstract / stability analysis] Abstract and stability analysis: the central error bound C(ε_net + δ) τ^γ ln(1/τ) rests on the claim that explicit time-step scaling renders the neural correction's Lipschitz constant exactly O(τ) uniformly in the spatial discretization parameter and in the Sobolev regularity of the data. The manuscript provides no explicit derivative bounds on the trained network after scaling, nor a quantitative verification that this O(τ) property is preserved under the Bourgain-norm training and across the range of spatial resolutions tested. Without such control the Gronwall factor may acquire a hidden dependence on the number of modes, undermining the stated uniformity.
- [Abstract] The abstract states that the global error satisfies the displayed bound under 'stated assumptions,' yet the provided text supplies neither the precise list of assumptions nor a derivation sketch showing how the O(τ) Lipschitz condition is verified and how it interacts with the low-regularity integrator. This gap is load-bearing for the theoretical contribution.
minor comments (1)
- [Abstract] The abstract refers to 'three dispersive benchmarks' and 'stable spatial refinement' without specifying the exact equations, the range of spatial resolutions, or quantitative error tables; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying key points that require clarification in the stability analysis and theoretical presentation. We address each major comment below and will incorporate the necessary additions and expansions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / stability analysis] Abstract and stability analysis: the central error bound C(ε_net + δ) τ^γ ln(1/τ) rests on the claim that explicit time-step scaling renders the neural correction's Lipschitz constant exactly O(τ) uniformly in the spatial discretization parameter and in the Sobolev regularity of the data. The manuscript provides no explicit derivative bounds on the trained network after scaling, nor a quantitative verification that this O(τ) property is preserved under the Bourgain-norm training and across the range of spatial resolutions tested. Without such control the Gronwall factor may acquire a hidden dependence on the number of modes, undermining the stated uniformity.
Authors: We agree that the current version lacks explicit derivative bounds on the scaled network and quantitative verification of the O(τ) Lipschitz property. In the revision we will add a new lemma in the stability section that derives the uniform O(τ) bound from the network architecture and the explicit scaling factor, with estimates independent of the spatial discretization parameter and Sobolev regularity. We will also include a short numerical study verifying that the empirical Lipschitz constant remains O(τ) across the tested resolutions and data regularities, confirming that the Gronwall factor stays uniform. revision: yes
-
Referee: [Abstract] The abstract states that the global error satisfies the displayed bound under 'stated assumptions,' yet the provided text supplies neither the precise list of assumptions nor a derivation sketch showing how the O(τ) Lipschitz condition is verified and how it interacts with the low-regularity integrator. This gap is load-bearing for the theoretical contribution.
Authors: We acknowledge that the manuscript refers to 'stated assumptions' without enumerating them or providing a derivation sketch. In the revised version we will (i) expand the abstract to list the principal assumptions in one sentence and (ii) insert a dedicated paragraph immediately after the statement of the main theorem that enumerates all assumptions and gives a concise derivation outline: the explicit scaling ensures the neural term contributes an O(τ) perturbation to the Lipschitz constant of the integrator, which is absorbed into the Gronwall factor without introducing dependence on the number of modes, yielding the claimed global error bound. revision: yes
Circularity Check
No circularity: error bound follows from explicit scaling and standard Gronwall
full rationale
The paper's central derivation applies an explicit time-step scaling to the neural correction term so that its Lipschitz contribution is O(τ), then invokes the Gronwall inequality to obtain the global error bound C(ε_net + δ) τ^γ ln(1/τ) under stated assumptions. This is a conventional stability argument and does not reduce by construction to the network weights, the training data, or the Bourgain-norm trajectory loss; the scaling is a deliberate design choice stated separately from the learned residual. The training objective is defined externally via unrolled solver-in-the-loop trajectory error rather than being tautological with the error bound itself. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text, and the low-regularity integrator is taken as a classical base method. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Yvonne Alama Bronsard, Yvain Bruned, Georg Maierhofer, and Katharina Schratz
doi: 10.1093/imanum/drad093. Yvonne Alama Bronsard, Yvain Bruned, Georg Maierhofer, and Katharina Schratz. Sym- metric resonance based integrators and forest formulae.Foundations of Computational Mathematics,
-
[3]
doi: 10.1007/s10208-026-09742-0. Published online
-
[4]
Jiachuan Cao, Buyang Li, and Yanping Lin
doi: 10.1017/fmp.2021.13. Jiachuan Cao, Buyang Li, and Yanping Lin. A new second-order low-regularity integrator for the cubic nonlinear schr¨ odinger equation.IMA Journal of Numerical Analysis, 44(3): 1313–1345,
-
[5]
SH Chan, X Wang, and OA Elgendy
doi: 10.1093/imanum/drad017. SH Chan, X Wang, and OA Elgendy. Plug-and-play admm for image restoration.IEEE Transactions on Computational Imaging,
-
[6]
doi: 10.1109/72.392253. 45 Zhangyong Liang Y. Cui, S. Wang, and L. Zheng. A coarse-grid correction method built on fourier neural network for solving partial differential equations.Journal of Computational Mathematics, 1,
-
[7]
Mathematics of Computation , year =
doi: 10.1090/mcom/3922. Yue Feng, Georg Maierhofer, and Chushan Wang. Explicit symmetric low-regularity inte- grators for the nonlinear schr¨ odinger equation.arXiv preprint arXiv:2411.07720,
-
[8]
Learning core design for multigrid methods.arXiv preprint arXiv:1902.05656,
Jun-Ting Hsieh, Shengjia Zhao, Stephan Eickenberg, Arthur Balvert, and Qiaoning Liao. Learning core design for multigrid methods.arXiv preprint arXiv:1902.05656,
-
[9]
A fourier integrator for the cubic nonlinear schr¨ odinger equation with rough initial data.SIAM Journal on Numerical Analysis, 57(4):1967–1986,
Marvin Kn¨ oller, Alexander Ostermann, and Katharina Schratz. A fourier integrator for the cubic nonlinear schr¨ odinger equation with rough initial data.SIAM Journal on Numerical Analysis, 57(4):1967–1986,
1967
-
[10]
A Kopanicakova and GE Karniadakis
doi: 10.1137/18M1198375. A Kopanicakova and GE Karniadakis. Deeponet-based hybrid preconditioners.Computer Methods in Applied Mechanics and Engineering,
-
[11]
Neural Operator: Graph Kernel Network for Partial Differential Equations
doi: 10.1007/ s10208-025-09702-0. Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020a. Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattachary...
work page internal anchor Pith review arXiv 2003
-
[12]
I. Luz, M. Galun, H. Maron, R. Basri, and I. Yavneh. Learning algebraic multigrid using graph neural networks.ICML 2020,
2020
-
[13]
Nils Margenberg, Jonas K”ohler, Rick Boelens, and Tijn Oosterlee
doi: 10.1090/mcom/4105. Nils Margenberg, Jonas K”ohler, Rick Boelens, and Tijn Oosterlee. Neural networks as structural priors for deep learning-based image reconstruction.arXiv preprint arXiv:2201.07722,
-
[14]
Alexander Ostermann and Katharina Schratz. Low regularity exponential-type integrators for semilinear schr¨ odinger equations.Foundations of Computational Mathematics, 18(3): 731–755, 2018b. doi: 10.1007/s10208-017-9352-1. Alexander Ostermann, Fr´ ed´ eric Rousset, and Katharina Schratz. Error estimates of a fourier integrator for the cubic schr¨ odinger ...
-
[15]
Alexander Ostermann, Yifei Wu, and Fangyan Yao
doi: 10.1007/s10208-020-09468-7. Alexander Ostermann, Yifei Wu, and Fangyan Yao. A second-order low-regularity integrator for the nonlinear schr¨ odinger equation.Advances in Continuous and Discrete Models, 2022(23),
-
[16]
Alexander Ostermann, Fr´ ed´ eric Rousset, and Katharina Schratz
doi: 10.1186/s13662-022-03695-8. Alexander Ostermann, Fr´ ed´ eric Rousset, and Katharina Schratz. Fourier integrator for periodic NLS: Low regularity estimates via discrete bourgain spaces.Journal of the European Mathematical Society, 25(10):3913–3952,
-
[17]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis
doi: 10.4171/JEMS/1275. Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural net- works: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707,
-
[18]
Improved error estimates for low-regularity integrators using space-time bounds
doi: 10.1137/20M1371506. Fr´ ed´ eric Rousset and Katharina Schratz. Convergence error estimates at low regularity for time discretizations of KdV.Pure and Applied Analysis, 4(1):127–152, 2022b. doi: 10.2140/paa.2022.4.127. Maximilian Ruff. Improved error estimates for low-regularity integrators using space-time bounds.arXiv preprint arXiv:2503.22621,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1137/20m1371506 2022
-
[19]
K. Um, R. Brand, Y. R. Fei, P. Holl, and N. Thuerey. Solver-in-the-loop: Learning from differentiable physics to interact with iterative pde-solvers.NeurIPS 2020,
2020
-
[20]
Y. Wu and X. Zhao. Embedded exponential-type low-regularity integrators for kdv equation under rough data. doi:10.1007/s10543-021-00895-8.BIT,
-
[21]
doi: 10.1007/s10543-021-00895-8. Fangyan Yao. A second-order embedded low-regularity integrator for the quadratic non- linear schr¨ odinger equation on torus.International Journal of Numerical Analysis and Modeling, 19(5):656–668,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.