Recognition: 3 theorem links
· Lean TheoremBreaking the Quality-Privacy Tradeoff in Tabular Data Generation via In-Context Learning
Pith reviewed 2026-05-08 18:25 UTC · model grok-4.3
The pith
Tabular data generation can improve both quality and privacy by using in-context learning on pretrained structural priors instead of fitting small datasets from scratch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
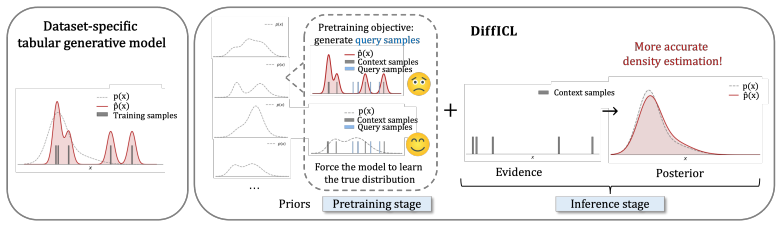
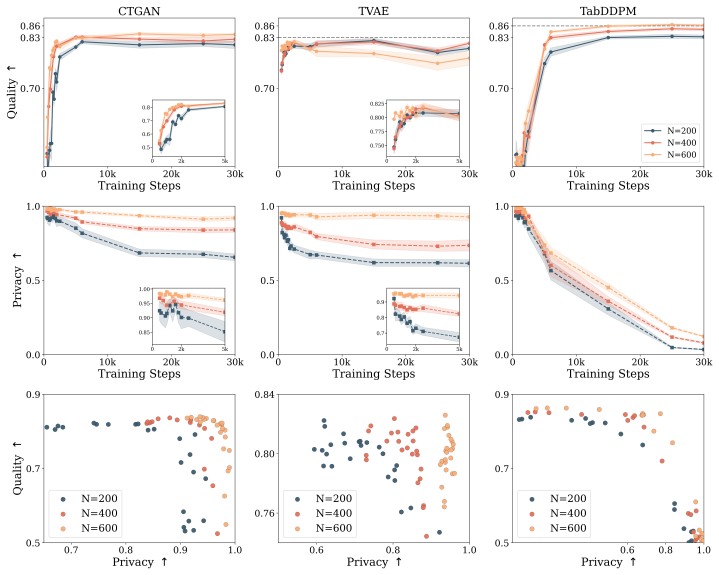
The central discovery is that the quality-privacy tradeoff in tabular synthesis arises from dataset-specific training in small regimes. DiffICL overcomes it by leveraging pretrained structural priors via in-context learning to generate synthetic data that matches distributions without memorizing samples, leading to better quality, privacy, and augmentation performance across 14 datasets.
What carries the argument
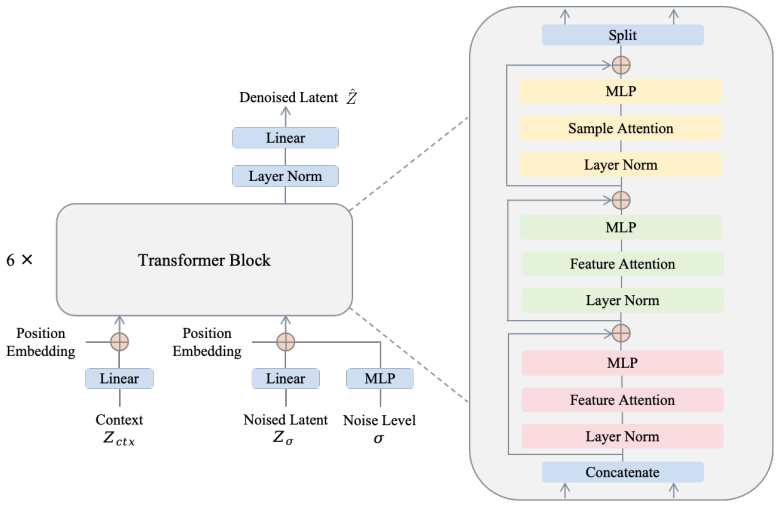
DiffICL, which recasts tabular data generation as an in-context learning task that applies pretrained structural priors from a large collection of datasets to infer distributions from limited context.
If this is right
- DiffICL achieves higher data quality and stronger privacy protection than prior methods on 14 real-world tabular datasets.
- The generated synthetic data serves as effective augmentation for improving performance on downstream tasks.
- Shifting to in-context learning with general priors rather than per-dataset fitting reduces the tendency to memorize training samples.
- The quality-privacy tradeoff in small-data tabular generation can be mitigated through better use of cross-dataset structural knowledge.
Where Pith is reading between the lines
- Similar in-context approaches might extend to other data modalities like images or text where small-data regimes also trade off fidelity and privacy.
- Pretraining tabular models on broad collections could become a foundation for privacy-friendly synthetic data pipelines in regulated industries.
- Future work could test whether the same priors help in generating data under additional constraints like fairness or specific marginals.
Load-bearing premise
Pretrained structural priors from many tabular datasets transfer effectively via in-context learning to small new datasets, allowing accurate inference without memorizing any individual training examples.
What would settle it
A demonstration that DiffICL fails to improve privacy or quality over baselines on additional small tabular datasets, or that its outputs show signs of memorization, would challenge the central claim.
Figures





read the original abstract
Tabular data synthesis aims to generate high-quality data while preserving privacy. However, we find that existing tabular generative models exhibit a clear tradeoff in the small-data regime: improving data quality typically comes at the cost of increased memorization of training samples, thereby weakening privacy protection. This tradeoff arises because small training sets make it difficult for dataset-specific generative models to distinguish generalizable structure from sample-specific patterns. To address this, we propose DiffICL, which formulates tabular data generation as an in-context learning problem. Instead of fitting each dataset from scratch,DiffICL leverages pretrained structural priors learned from a large collection of datasets, enabling it to infer data distributions from limited context rather than memorizing individual samples. We evaluate DiffICL on 14 real-world datasets. Results show that DiffICL improves both data quality and privacy, and generate synthetic data that provides effective data augmentation. Our findings suggest that the quality-privacy tradeoff can be improved through better training paradigms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DiffICL, which reformulates tabular data synthesis as an in-context learning problem. Rather than training dataset-specific generative models from scratch (which the authors argue leads to a quality-privacy tradeoff in small-data regimes), DiffICL leverages structural priors pretrained on a large collection of tabular datasets to infer distributions from limited context without memorizing individual samples. The authors evaluate the approach on 14 real-world datasets and report that it simultaneously improves data quality and privacy while producing synthetic data useful for augmentation.
Significance. If the empirical results hold under rigorous controls, the work could meaningfully advance privacy-preserving synthetic data generation for tabular data. The core idea—shifting from per-dataset fitting to cross-dataset pretrained priors via in-context learning—directly targets the stated source of the tradeoff and is internally consistent. The multi-dataset evaluation provides a reasonable test of generalizability, and the emphasis on both quality and privacy metrics (rather than one at the expense of the other) is a strength.
minor comments (2)
- Abstract: the sentence 'Instead of fitting each dataset from scratch,DiffICL leverages...' is missing a space after the comma.
- Abstract: the final sentence states that 'the quality-privacy tradeoff can be improved through better training paradigms' but does not specify whether this is a general claim or specific to the small-data regime emphasized earlier; a brief qualifier would improve precision.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. The report does not raise any specific major comments, so we have no individual points to rebut. We will address any minor issues during revision.
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain is self-contained and non-circular. DiffICL is constructed by pretraining structural priors on a large external collection of tabular datasets and then applying in-context learning to infer distributions from limited target context; this is not defined in terms of the target data's own fitted parameters or predictions. The quality-privacy improvement claim is supported by direct evaluation on 14 held-out real-world datasets rather than by renaming fitted quantities as predictions or by load-bearing self-citations. No self-definitional equations, ansatz smuggling, or uniqueness theorems imported from the authors' prior work appear in the method description. The approach therefore reduces to an independent modeling choice whose validity is tested externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained models can capture generalizable structural priors from diverse tabular datasets that transfer to new small datasets via in-context learning.
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationJ_uniquely_calibrated_via_higher_derivative unclearλ(σ) = (σ²+σ_data²)/(σσ_data)² and σ_data = 0.5 ... lnσ ∼ N(−1.2, 1.2²)
Reference graph
Works this paper leans on
-
[1]
How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models
Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela Van Der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International conference on machine learning, pages 290–306. PMLR, 2022
2022
-
[2]
An improved tabular data generator with vae-gmm integration
Patricia A Apellániz, Juan Parras, and Santiago Zazo. An improved tabular data generator with vae-gmm integration. In2024 32nd European Signal Processing Conference (EUSIPCO), pages 1886–1890. IEEE, 2024
2024
-
[3]
arXiv preprint arXiv:2505.17638 (2025)
Tony Bonnaire, Raphaël Urfin, Giulio Biroli, and Marc Mézard. Why diffusion models don’t memorize: The role of implicit dynamical regularization in training.arXiv preprint arXiv:2505.17638, 2025
-
[4]
arXiv preprint arXiv:2210.06280 , year=
Vadim Borisov, Kathrin Seßler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Language models are realistic tabular data generators.arXiv preprint arXiv:2210.06280, 2022
-
[5]
Modeling wine preferences by data mining from physicochemical properties.Decision support systems, 47(4):547–553, 2009
Paulo Cortez, António Cerdeira, Fernando Almeida, Telmo Matos, and José Reis. Modeling wine preferences by data mining from physicochemical properties.Decision support systems, 47(4):547–553, 2009
2009
-
[6]
Unique in the crowd: The privacy bounds of human mobility.Scientific reports, 3(1):1376, 2013
Yves-Alexandre De Montjoye, César A Hidalgo, Michel Verleysen, and Vincent D Blondel. Unique in the crowd: The privacy bounds of human mobility.Scientific reports, 3(1):1376, 2013
2013
-
[7]
Unique in the shopping mall: On the reidentifiability of credit card metadata.Science, 347(6221):536–539, 2015
Yves-Alexandre De Montjoye, Laura Radaelli, Vivek Kumar Singh, and Alex “Sandy” Pent- land. Unique in the shopping mall: On the reidentifiability of credit card metadata.Science, 347(6221):536–539, 2015
2015
-
[8]
O’Reilly Media, Inc
Khaled El Emam and Luk Arbuckle.Anonymizing health data: case studies and methods to get you started. " O’Reilly Media, Inc.", 2013
2013
-
[9]
Anurag Garg, Muhammad Ali, Noah Hollmann, Lennart Purucker, Samuel Müller, and Frank Hutter. Real-tabpfn: Improving tabular foundation models via continued pre-training with real-world data.arXiv preprint arXiv:2507.03971, 2025
-
[10]
Comprehensive evaluation framework for synthetic tabular data in health: fidelity, utility and privacy analysis of generative models with and without privacy guarantees
Mikel Hernandez, Pablo A Osorio-Marulanda, Mikel Catalina, Lorea Loinaz, Gorka Epelde, and Naiara Aginako. Comprehensive evaluation framework for synthetic tabular data in health: fidelity, utility and privacy analysis of generative models with and without privacy guarantees. Frontiers in Digital Health, 7:1576290, 2025
2025
-
[11]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[12]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
2025
-
[13]
Anil K Jain, Robert P. W. Duin, and Jianchang Mao. Statistical pattern recognition: A review. IEEE Transactions on pattern analysis and machine intelligence, 22(1):4–37, 2000. 10
2000
-
[14]
Jingang Qu and David Holzmüller and Gaël Varoquaux and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data.arXiv preprint arXiv:2502.05564, 2025
-
[15]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[16]
Stasy: Score-based tabular data synthesis.arXiv preprint arXiv:2210.04018, 2022
Jayoung Kim, Chaejeong Lee, and Noseong Park. Stasy: Score-based tabular data synthesis. arXiv preprint arXiv:2210.04018, 2022
-
[17]
Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid
Ron Kohavi et al. Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid. In Kdd, volume 96, pages 202–207, 1996
1996
-
[18]
Tabddpm: Mod- elling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Mod- elling tabular data with diffusion models. InInternational conference on machine learning, pages 17564–17579. PMLR, 2023
2023
-
[19]
Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis
Chaejeong Lee, Jayoung Kim, and Noseong Park. Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis. InInternational Conference on Machine Learning, pages 18940–18956. PMLR, 2023
2023
-
[20]
Ctsyn: A foundation model for cross tabular data generation.arXiv preprint arXiv:2406.04619, 2024
Xiaofeng Lin, Chenheng Xu, Matthew Yang, and Guang Cheng. Ctsyn: A foundation model for cross tabular data generation.arXiv preprint arXiv:2406.04619, 2024
-
[21]
Talent: A tabular analytics and learning toolbox.Journal of Machine Learning Research, 26(226):1–16, 2025
Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, Huai-Hong Yin, Tao Zhou, Jun-Peng Jiang, and Han-Jia Ye. Talent: A tabular analytics and learning toolbox.Journal of Machine Learning Research, 26(226):1–16, 2025
2025
-
[22]
Goggle: Generative modelling for tabular data by learning relational structure
Tennison Liu, Zhaozhi Qian, Jeroen Berrevoets, and Mihaela van der Schaar. Goggle: Generative modelling for tabular data by learning relational structure. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[23]
Tab- DPT: Scaling tabular foundation models.arXiv preprint arXiv:2410.18164, 2024
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Hamidreza Kamkari, Jesse C Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L Caterini, and Maksims V olkovs. Tabdpt: Scaling tabular foundation models on real data.arXiv preprint arXiv:2410.18164, 2024
-
[24]
Menzies and J.S
T. Menzies and J.S. Di Stefano. How good is your blind spot sampling policy. InHigh Assurance Systems Engineering, 2004. Proceedings. Eighth IEEE International Symposium on, pages 129–138, March 2004
2004
-
[25]
Robust de-anonymization of large sparse datasets
Arvind Narayanan and Vitaly Shmatikov. Robust de-anonymization of large sparse datasets. In 2008 IEEE Symposium on Security and Privacy (sp 2008), pages 111–125. IEEE, 2008
2008
-
[26]
The population biology of abalone (haliotis species) in tasmania
Warwick J Nash, Tracy L Sellers, Simon R Talbot, Andrew J Cawthorn, and Wes B Ford. The population biology of abalone (haliotis species) in tasmania. i. blacklip abalone (h. rubra) from the north coast and islands of bass strait.Sea Fisheries Division, Technical Report, 48:p411, 1994
1994
-
[27]
Craig A Olson. A comparison of parametric and semiparametric estimates of the effect of spousal health insurance coverage on weekly hours worked by wives.Journal of Applied Econometrics, 13(5):543–565, 1998
1998
-
[28]
Analyzing and predicting verification of data-aware process models–a case study with spectrum auctions.IEEE Access, 10:31699–31713, 2022
Elaheh Ordoni, Jakob Bach, and Ann-Katrin Fleck. Analyzing and predicting verification of data-aware process models–a case study with spectrum auctions.IEEE Access, 10:31699–31713, 2022
2022
-
[29]
Data privacy laws and their impact on financial technology companies: a review.Computer science & IT research journal, 5(3):628– 650, 2024
Adedoyin Tolulope Oyewole, Bisola Beatrice Oguejiofor, Nkechi Emmanuella Eneh, Chid- iogo Uzoamaka Akpuokwe, and Seun Solomon Bakare. Data privacy laws and their impact on financial technology companies: a review.Computer science & IT research journal, 5(3):628– 650, 2024
2024
-
[30]
arXiv preprint arXiv:1806.03384 (2018)
Noseong Park, Mahmoud Mohammadi, Kshitij Gorde, Sushil Jajodia, Hongkyu Park, and Youngmin Kim. Data synthesis based on generative adversarial networks.arXiv preprint arXiv:1806.03384, 2018. 11
-
[31]
The synthetic data vault
Neha Patki, Roy Wedge, and Kalyan Veeramachaneni. The synthetic data vault. In2016 IEEE international conference on data science and advanced analytics (DSAA), pages 399–410. IEEE, 2016
2016
-
[32]
A critical compara- tive study of liver patients from usa and india: an exploratory analysis.International Journal of Computer Science Issues (IJCSI), 9(3):506, 2012
Bendi Venkata Ramana, M Surendra Prasad Babu, and NB Venkateswarlu. A critical compara- tive study of liver patients from usa and india: an exploratory analysis.International Journal of Computer Science Issues (IJCSI), 9(3):506, 2012
2012
-
[33]
Delve data for evaluating learning in valid experiments, 1995–1996.URL http://www
CE Rasmussen, RM Neal, G Hinton, D Van Camp, M Revow, Z Ghahramani, R Kustra, and R Tibshirani. Delve data for evaluating learning in valid experiments, 1995–1996.URL http://www. cs. toronto. edu/ delve, 2003
1995
-
[34]
Synthetic data: revisiting the privacy-utility trade-off: F
Fatima Jahan Sarmin, Atiquer Rahman Sarkar, Yang Wang, and Noman Mohammed. Synthetic data: revisiting the privacy-utility trade-off: F. jahan sarmin et al.International Journal of Information Security, 24(4):156, 2025
2025
-
[35]
Addison-Wesley Longman Publishing Co., Inc., 1987
Alen D Shapiro.Structured induction in expert systems. Addison-Wesley Longman Publishing Co., Inc., 1987
1987
-
[36]
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. Tabd- iff: a mixed-type diffusion model for tabular data generation.arXiv preprint arXiv:2410.20626, 2024
-
[37]
Vehicle recognition using rule based methods
Jan Paul Siebert. Vehicle recognition using rule based methods. 1987
1987
-
[38]
Using the adap learning algorithm to forecast the onset of diabetes mellitus
Jack W Smith, James E Everhart, William C Dickson, William C Knowler, and Robert Scott Johannes. Using the adap learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the annual symposium on computer application in medical care, page 261, 1988
1988
-
[39]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[40]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page Pith review arXiv 2010
-
[41]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page Pith review arXiv 2011
-
[42]
Nuclear feature extraction for breast tumor diagnosis
W Nick Street, William H Wolberg, and Olvi L Mangasarian. Nuclear feature extraction for breast tumor diagnosis. InBiomedical image processing and biomedical visualization, volume 1905, pages 861–870. SPIE, 1993
1905
-
[43]
Modeling tabular data using conditional gan.Advances in neural information processing systems, 32, 2019
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan.Advances in neural information processing systems, 32, 2019
2019
-
[44]
arXiv preprint arXiv:1811.11264 (2018)
Lei Xu and Kalyan Veeramachaneni. Synthesizing tabular data using generative adversarial networks.arXiv preprint arXiv:1811.11264, 2018
-
[45]
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, and George Karypis. Mixed-type tabular data synthesis with score-based diffusion in latent space.arXiv preprint arXiv:2310.09656, 2023
-
[46]
Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, et al. Limix: Unleashing structured-data modeling capability for generalist intelligence.arXiv preprint arXiv:2509.03505, 2025
-
[47]
Xiyuan Zhang, Danielle C Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W Mahoney, et al. Mitra: Mixed synthetic priors for enhancing tabular foundation models.arXiv preprint arXiv:2510.21204, 2025. 12
-
[48]
Ctab-gan: Effective table data synthesizing
Zilong Zhao, Aditya Kunar, Robert Birke, and Lydia Y Chen. Ctab-gan: Effective table data synthesizing. InAsian conference on machine learning, pages 97–112. PMLR, 2021
2021
-
[49]
Ctab-gan+: Enhancing tabular data synthesis.Frontiers in big Data, 6:1296508, 2024
Zilong Zhao, Aditya Kunar, Robert Birke, Hiek Van der Scheer, and Lydia Y Chen. Ctab-gan+: Enhancing tabular data synthesis.Frontiers in big Data, 6:1296508, 2024. A Implementation Details A.1 Pretraining Details We construct a pretraining corpus from real-world tabular datasets collected from Kaggle and the UCI Machine Learning Repository. We exclude dat...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.