Recognition: 3 theorem links
· Lean TheoremHow Long Does Infinite Width Last? Signal Propagation in Long-Range Linear Recurrences
Pith reviewed 2026-05-08 17:48 UTC · model grok-4.3
The pith
Infinite-width theory for signal propagation in linear recurrences holds only up to depth scaling as the square root of width.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
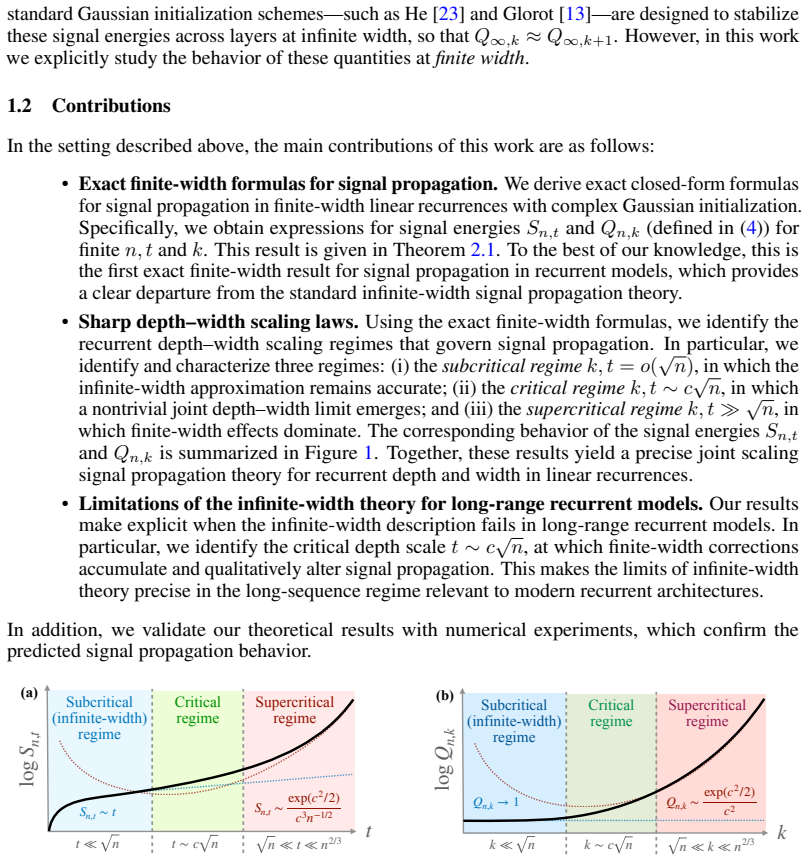
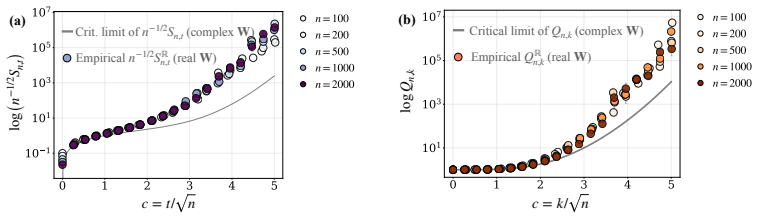
Exact finite-width formulas for hidden state signal energies reveal that infinite-width predictions remain valid in the subcritical regime where recurrent depth grows slower than the square root of width, that nontrivial deviations emerge in the critical regime at depths proportional to sqrt(width), and that finite-width effects dominate in the supercritical regime. This establishes the precise depth scale at which infinite-width theory breaks down and standard initializations become unstable in long-range linear recurrences, with finite-width corrections accumulating more rapidly than in feedforward models.
What carries the argument
Exact finite-width formulas for hidden state signal energies under complex Gaussian initialization, which identify the subcritical, critical, and supercritical joint depth-width scaling regimes for signal propagation.
If this is right
- In the subcritical regime where t = o(sqrt(n)), the infinite-width approximation for signal propagation remains valid.
- In the critical regime where t ~ c sqrt(n), non-negligible deviations from infinite-width predictions emerge.
- In the supercritical regime where t >> sqrt(n), finite-width effects dominate signal propagation.
- Standard initialization schemes such as Glorot become unstable beyond the critical depth scale.
- Finite-width effects accumulate more rapidly with depth in recurrent models than in feedforward models.
Where Pith is reading between the lines
- Practical recurrent neural networks with nonlinear activations may exhibit similar scaling breakdowns, warranting numerical checks at depth around sqrt(width).
- The critical scaling could guide the design of width-dependent initialization methods for long-sequence models.
- Extending the analysis to real-valued weights might shift the critical exponent away from square root.
- These regimes suggest that mean-field limits for recurrent networks require careful depth-width balancing not needed in feedforward cases.
Load-bearing premise
The derivation relies on linear recurrences and complex Gaussian initialization of the weights.
What would settle it
Simulations computing the signal energy variance for widths around 10,000 and depths from 100 to 1000 to check if the transition to finite-width dominance occurs near depth equal to sqrt(width).
Figures

read the original abstract
We study signal propagation in linear recurrent models at finite width. While existing signal propagation theory relies predominantly on the infinite-width limit, it remains unclear for how long that approximation remains accurate when recurrent depth $t$ grows jointly with width $n$. This question is especially relevant for modern recurrent sequence models, whose natural operating regime involves long input sequences, i.e., large $t$. We derive exact finite-width formulas for the hidden state signal energies in linear recurrences under complex Gaussian initialization. Using these formulas, we identify the joint depth-width scaling regimes that govern signal propagation: (i) a subcritical regime $t=o(\sqrt n)$, in which the infinite-width approximation remains valid; (ii) a critical regime $t\sim c\sqrt n$, in which non-negligible deviations from infinite-width predictions appear and a nontrivial joint scaling limit emerges; and (iii) a supercritical regime $t\gg \sqrt n$, in which finite-width effects dominate. Thus, our results pinpoint the precise recurrent depth scale at which infinite-width theory breaks down in long-range linear recurrences. In turn, this shows when standard initialization schemes, such as Glorot, become unstable. More broadly, our results demonstrate that finite-width effects accumulate more rapidly with depth in recurrent models than in feedforward ones, leading to qualitatively different signal propagation behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives exact closed-form expressions for hidden-state signal energies in linear recurrent models under complex Gaussian weight initialization at finite width n and recurrent depth t. From these, it identifies three joint scaling regimes: subcritical (t = o(√n)) where infinite-width predictions remain accurate, critical (t ∼ c√n) featuring a nontrivial joint limit with non-negligible deviations, and supercritical (t ≫ √n) where finite-width effects dominate. The authors conclude that this pinpoints the depth scale at which infinite-width theory breaks down in long-range linear recurrences and indicates when standard initializations such as Glorot become unstable, while noting that finite-width effects accumulate faster with depth in recurrent than feedforward models.
Significance. If the closed-form derivations hold, the work supplies a precise, non-asymptotic characterization of signal propagation that directly yields the three regimes without relying on approximations or fitted parameters. This is a clear strength for theoretical understanding of recurrent models. The observation that recurrent finite-width corrections set in at t ∼ √n (rather than the slower t ∼ n^{1/4} or similar scales sometimes seen in feedforward nets) is potentially useful for guiding initialization and depth choices in sequence models. Significance is reduced, however, by the restriction to linear dynamics and complex Gaussians, which leaves open the transfer to the nonlinear, real-valued networks where Glorot is actually applied.
major comments (1)
- [Abstract] Abstract (final paragraph) and concluding discussion: the claim that the derived regimes 'show when standard initialization schemes, such as Glorot, become unstable' is unsupported by the analysis. The exact formulas and scaling limits are obtained only for linear recurrences with complex Gaussian initialization; Glorot uses real-valued weights with variance scaling 2/(fan-in + fan-out) and is deployed inside nonlinear activations. No moment calculations for real Gaussians, no extension to nonlinearities, and no empirical verification are provided to justify the transfer of the t ∼ √n breakdown.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for highlighting the need to align our claims more precisely with the scope of the analysis. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph) and concluding discussion: the claim that the derived regimes 'show when standard initialization schemes, such as Glorot, become unstable' is unsupported by the analysis. The exact formulas and scaling limits are obtained only for linear recurrences with complex Gaussian initialization; Glorot uses real-valued weights with variance scaling 2/(fan-in + fan-out) and is deployed inside nonlinear activations. No moment calculations for real Gaussians, no extension to nonlinearities, and no empirical verification are provided to justify the transfer of the t ∼ √n breakdown.
Authors: We agree that the specific claim linking our regimes directly to the instability of Glorot initialization is not supported by the current derivations, which are restricted to linear dynamics under complex Gaussian weights. The reference to Glorot was meant to suggest broader relevance for initialization in recurrent models, but we acknowledge that transferring the t ∼ √n scale to real-valued nonlinear networks would require additional analysis of moments under real Gaussians, incorporation of nonlinear activations, and ideally empirical checks. We will revise the abstract and concluding discussion to remove this claim, instead stating that the results characterize the breakdown of infinite-width theory in linear recurrent models and provide a foundation for studying finite-width effects in more general recurrent architectures. A short limitations paragraph will be added to discuss the linear/complex-Gaussian restriction and outline extensions to real weights and nonlinearities as future work. revision: yes
Circularity Check
No circularity: derivation follows from direct expectation calculations under stated assumptions
full rationale
The paper computes exact finite-width expressions for hidden-state signal energies by taking expectations over complex Gaussian weights in linear recurrences. Scaling regimes (subcritical t = o(√n), critical t ∼ c√n, supercritical t ≫ √n) are obtained by asymptotic analysis of those closed-form expressions. No fitted parameters are relabeled as predictions, no self-citations supply load-bearing uniqueness theorems, and no ansatz is smuggled in; the claimed breakdown scale is a direct consequence of the derived formulas rather than a redefinition of the inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Weights are initialized as complex Gaussian random variables
- domain assumption The recurrence is strictly linear
Lean theorems connected to this paper
-
Cost.FunctionalEquation (no parallel: RS cost J is not a Gaussian trace moment)washburn_uniqueness_aczel unclearE[(1/n) tr((W^k)* W^k)] = (F^+_{k+2}(n) − F^-_{k+2}(n)) / (n^{k+1}(k+1)(k+2))
Reference graph
Works this paper leans on
-
[1]
The recurrent neural tangent kernel
Sina Alemohammad, Zichao Wang, Randall Balestriero, and Richard Baraniuk. The recurrent neural tangent kernel. InThe International Conference on Learning Representations, 2021
2021
-
[2]
Hultman numbers, polygon gluings and matrix integrals
Nikita Alexeev and Peter Zograf. Hultman numbers, polygon gluings and matrix integrals. arXiv preprint arXiv:1111.3061, 2011
-
[3]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review arXiv 2016
-
[4]
Revisiting glorot initialization for long-range linear recurrences
Noga Bar, Mariia Seleznova, Yotam Alexander, Gitta Kutyniok, and Raja Giryes. Revisiting glorot initialization for long-range linear recurrences. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[5]
Learning long-term dependencies with gradient descent is difficult.IEEE transactions on neural networks, 5(2):157–166, 1994
Yoshua Bengio, Patrice Simard, and Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult.IEEE transactions on neural networks, 5(2):157–166, 1994
1994
-
[6]
Dynamical isometry and a mean field theory of rnns: Gating enables signal propagation in recurrent neural networks
Minmin Chen, Jeffrey Pennington, and Samuel Schoenholz. Dynamical isometry and a mean field theory of rnns: Gating enables signal propagation in recurrent neural networks. In International Conference on Machine Learning, pages 873–882. PMLR, 2018
2018
-
[7]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder- decoder for statistical machine translation.arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review arXiv 2014
-
[8]
Griffin: Mixing gated linear recurrences with local attention for efficient language models,
Soham De, Samuel L Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427, 2024
-
[9]
On the number of cycles in commutators of random permutations.The Annals of Applied Probability, 34(4):4072–4084, 2024
Guillaume Dubach. On the number of cycles in commutators of random permutations.The Annals of Applied Probability, 34(4):4072–4084, 2024
2024
-
[10]
Hungry hungry hippos: Towards language modeling with state space models
Daniel Y Fu, Tri Dao, Khaled Kamal Saab, Armin W Thomas, Atri Rudra, and Christopher Re. Hungry hungry hippos: Towards language modeling with state space models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[11]
Lstm recurrent networks learn simple context-free and context-sensitive languages.IEEE transactions on neural networks, 12(6):1333–1340, 2001
Felix A Gers and E Schmidhuber. Lstm recurrent networks learn simple context-free and context-sensitive languages.IEEE transactions on neural networks, 12(6):1333–1340, 2001
2001
-
[12]
Dynamical isometry and a mean field theory of lstms and grus.arXiv preprint arXiv:1901.08987, 2019
Dar Gilboa, Bo Chang, Minmin Chen, Greg Yang, Samuel S Schoenholz, Ed H Chi, and Jeffrey Pennington. Dynamical isometry and a mean field theory of lstms and grus.arXiv preprint arXiv:1901.08987, 2019
-
[13]
Understanding the difficulty of training deep feedfor- ward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedfor- ward neural networks. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010
2010
-
[14]
The edge of chaos: quantum field theory and deep neural networks.SciPost Physics, 12(3):081, 2022
Kevin Grosvenor and Ro Jefferson. The edge of chaos: quantum field theory and deep neural networks.SciPost Physics, 12(3):081, 2022
2022
-
[15]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems, 33:1474–1487, 2020
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré. Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems, 33:1474–1487, 2020
2020
-
[17]
On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré. On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
2022
-
[18]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021. 10
work page internal anchor Pith review arXiv 2021
-
[19]
Which neural net architectures give rise to exploding and vanishing gradients? Advances in neural information processing systems, 31, 2018
Boris Hanin. Which neural net architectures give rise to exploding and vanishing gradients? Advances in neural information processing systems, 31, 2018
2018
-
[20]
Random fully connected neural networks as perturbatively solvable hierarchies
Boris Hanin. Random fully connected neural networks as perturbatively solvable hierarchies. Journal of Machine Learning Research, 25(267):1–58, 2024
2024
-
[21]
Finite depth and width corrections to the neural tangent kernel
Boris Hanin and Mihai Nica. Finite depth and width corrections to the neural tangent kernel. arXiv preprint arXiv:1909.05989, 2019
-
[22]
Products of many large random matrices and gradients in deep neural networks.Communications in Mathematical Physics, 376(1):287–322, 2020
Boris Hanin and Mihai Nica. Products of many large random matrices and gradients in deep neural networks.Communications in Mathematical Physics, 376(1):287–322, 2020
2020
-
[23]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. InProceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015
2015
-
[24]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[25]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997
1997
-
[26]
On a formula for the product-moment coefficient of any order of a normal frequency distribution in any number of variables.Biometrika, 12(1/2):134–139, 1918
Leon Isserlis. On a formula for the product-moment coefficient of any order of a normal frequency distribution in any number of variables.Biometrika, 12(1/2):134–139, 1918
1918
-
[27]
Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31, 2018
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31, 2018
2018
-
[28]
arXiv preprint arXiv:1804.11271 , year=
Alexander G de G Matthews, Mark Rowland, Jiri Hron, Richard E Turner, and Zoubin Ghahramani. Gaussian process behaviour in wide deep neural networks.arXiv preprint arXiv:1804.11271, 2018
-
[29]
Resurrecting recurrent neural networks for long sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. In International Conference on Machine Learning, pages 26670–26698. PMLR, 2023
2023
-
[30]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInternational conference on machine learning, pages 1310–1318. Pmlr, 2013
2013
-
[31]
Exponential expressivity in deep neural networks through transient chaos.Advances in neural information processing systems, 29, 2016
Ben Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl-Dickstein, and Surya Ganguli. Exponential expressivity in deep neural networks through transient chaos.Advances in neural information processing systems, 29, 2016
2016
-
[32]
Cambridge University Press Cambridge, MA, USA, 2022
Daniel A Roberts, Sho Yaida, and Boris Hanin.The principles of deep learning theory, volume 46. Cambridge University Press Cambridge, MA, USA, 2022
2022
-
[33]
Deep informa- tion propagation.arXiv preprint arXiv:1611.01232, 2016
Samuel S Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein. Deep informa- tion propagation.arXiv preprint arXiv:1611.01232, 2016
-
[34]
Unified field theoretical approach to deep and recurrent neuronal networks
Kai Segadlo, Bastian Epping, Alexander Van Meegen, David Dahmen, Michael Krämer, and Moritz Helias. Unified field theoretical approach to deep and recurrent neuronal networks. Journal of Statistical Mechanics: Theory and Experiment, 2022(10):103401, 2022
2022
-
[35]
Neural tangent kernel beyond the infinite-width limit: Effects of depth and initialization
Mariia Seleznova and Gitta Kutyniok. Neural tangent kernel beyond the infinite-width limit: Effects of depth and initialization. InInternational Conference on Machine Learning, pages 19522–19560. PMLR, 2022
2022
-
[36]
Two enumerative results on cycles of permutations.European Journal of Combinatorics, 32(6):937–943, 2011
Richard P Stanley. Two enumerative results on cycles of permutations.European Journal of Combinatorics, 32(6):937–943, 2011. 11
2011
-
[37]
Dynamical isometry is achieved in residual networks in a universal way for any activation function
Wojciech Tarnowski, Piotr Warchol, Stanislaw Jastrzebski, Jacek Tabor, and Maciej Nowak. Dynamical isometry is achieved in residual networks in a universal way for any activation function. InThe 22nd International Conference on Artificial Intelligence and Statistics, pages 2221–2230. PMLR, 2019
2019
-
[38]
The evaluation of the collision matrix.Physical review, 80(2):268, 1950
Gian-Carlo Wick. The evaluation of the collision matrix.Physical review, 80(2):268, 1950
1950
-
[39]
Dynamical isometry and a mean field theory of cnns: How to train 10,000-layer vanilla convolutional neural networks
Lechao Xiao, Yasaman Bahri, Jascha Sohl-Dickstein, Samuel Schoenholz, and Jeffrey Pen- nington. Dynamical isometry and a mean field theory of cnns: How to train 10,000-layer vanilla convolutional neural networks. InInternational Conference on Machine Learning, pages 5393–5402. PMLR, 2018
2018
-
[40]
Non-gaussian processes and neural networks at finite widths
Sho Yaida. Non-gaussian processes and neural networks at finite widths. InMathematical and Scientific Machine Learning, pages 165–192. PMLR, 2020
2020
- [41]
-
[42]
arXiv preprint arXiv:2006.14548 , year =
Greg Yang. Tensor programs ii: Neural tangent kernel for any architecture.arXiv preprint arXiv:2006.14548, 2020
-
[43]
Tensor programs iii: Neural matrix laws.arXiv preprint arXiv:2009.10685, 2020
Greg Yang. Tensor programs iii: Neural matrix laws.arXiv preprint arXiv:2009.10685, 2020
-
[44]
Tensor programs iv: Feature learning in infinite-width neural networks
Greg Yang and Edward J Hu. Tensor programs iv: Feature learning in infinite-width neural networks. InInternational Conference on Machine Learning, pages 11727–11737. PMLR, 2021. 12 A Appendix B Proof of Theorem 2.1 The central part of the proof is the exact evaluation of the trace moment E tr (Wk)∗Wk for finite n and k, given in the following Subsections ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.