Recognition: unknown
Shortcut Solutions Learned by Transformers Impair Continual Compositional Reasoning
Pith reviewed 2026-05-08 16:38 UTC · model grok-4.3
The pith
Feedforward Transformers learn shortcut solutions that impair their ability to continually learn compositional tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
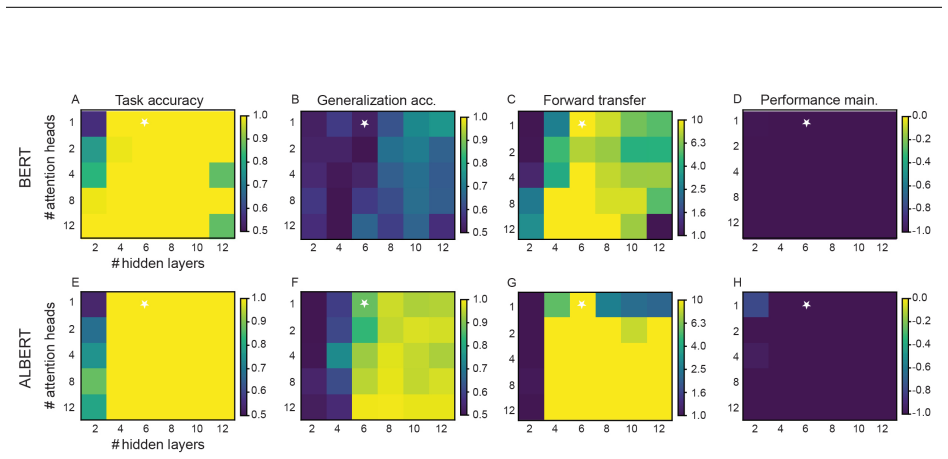
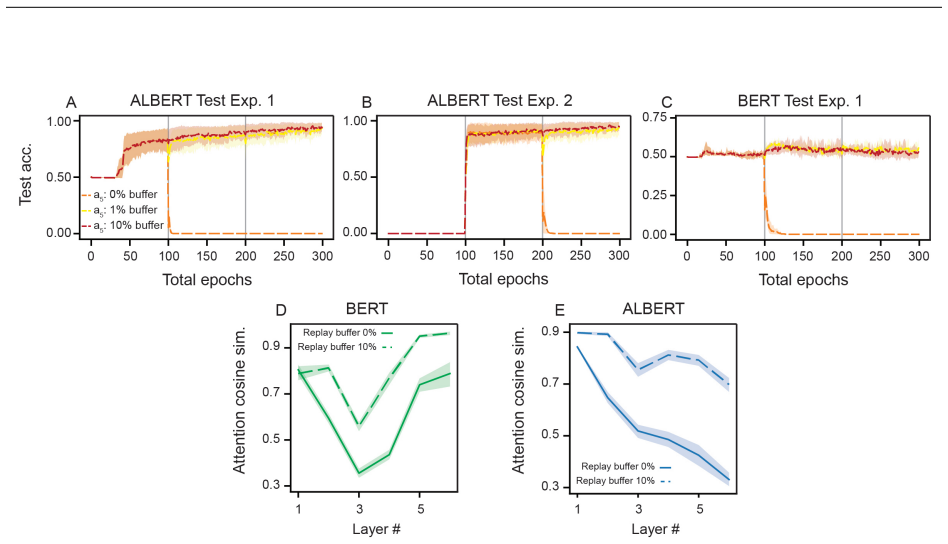
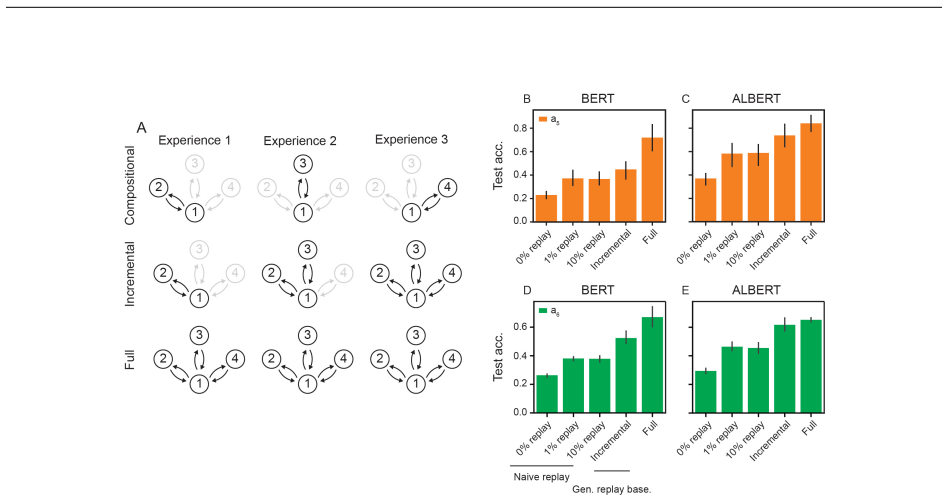
In the continual LEGO setting, BERT models adopt shortcut solutions that limit generalization and prevent strong forward transfer, whereas ALBERT models adopt For loop-esque solutions enabling better continual learning performance; both fail on tasks requiring composition across experiences, though ALBERT's performance can be rescued by mixed training data while BERT's shortcuts become entrenched.
What carries the argument
The continual LEGO paradigm that sequences equality and group operation tasks so models must reuse or compose prior learning for new experiences.
If this is right
- BERT models entrench detrimental shortcuts after initial training, so later mixed-data strategies cannot rescue their performance.
- ALBERT models improve under training strategies that combine data across experiences.
- Both feedforward and recurrent Transformer families fail at compositional reasoning that integrates information across multiple learning experiences.
- Recurrent architectures may carry an inductive bias more compatible with continual learning than feedforward ones.
Where Pith is reading between the lines
- The specific computational strategy that emerges during training appears tied to architectural recurrence, which in turn shapes how models handle sequences of related tasks.
- Early prevention of shortcut learning may be necessary for any neural network to maintain the flexibility needed for ongoing compositional reasoning.
- Similar shortcut versus iterative solution patterns could appear in other sequence models or in tasks that require analogy across domains.
Load-bearing premise
Performance differences between BERT and ALBERT arise primarily from the feedforward versus recurrent architectural difference rather than from model size, training hyperparameters, or other implementation details.
What would settle it
Training a recurrent Transformer matched exactly in size and hyperparameters to BERT and checking whether it still learns the iterative solution and shows improved continual learning performance would test the architecture hypothesis.
Figures



read the original abstract
Identifying and exploiting common features across domains is at the heart of the human ability to make analogies, and is believed to be crucial for the ability to continually learn. To do this successfully, general and flexible computational strategies must be developed. While the extent to which Transformer neural network models can perform compositional reasoning has been the subject of intensive recent investigation, little work has been done to systematically understand how well these models can leverage their representations to learn new, related experiences. To address this gap, we expand the previously developed Learning Equality and Group Operations (LEGO) framework to a continual learning (CL) setting ("continual LEGO"). Using this continual LEGO experimental paradigm, we study the capability of feedforward and recurrent Transformer models to perform CL. We find that BERT, a canonical feedforward Transformer model, learns shortcut solutions that limits its ability to generalize and prevents strong forward transfer to new experiences. In contrast, we find evidence supporting the hypothesis that ALBERT, a recurrent version of BERT, learns a For loop-esque solution, which leads to better CL performance. When applying BERT and ALBERT models to a CL setting that requires composition across experiences, we find that both model families fail. Our investigation suggests that ALBERT models can have their performance drop rescued by use of training strategies that combine data across experiences, but this is not true for BERT models, where a detrimental shortcut solution becomes entrenched with initial training. Our results demonstrate that the recurrent ALBERT model may have an inductive bias better suited for CL and motivate future investigation of the interplay between Transformer architecture and computational solutions that emerge in modern models and tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the LEGO framework to a continual learning (CL) setting and compares feedforward Transformers (BERT) with recurrent variants (ALBERT). It claims that BERT learns shortcut solutions that impair generalization and block strong forward transfer, while ALBERT learns reusable 'For loop'-like computations that yield better CL performance. Both families fail on tasks requiring composition across experiences, but ALBERT can be rescued by cross-experience data mixing whereas BERT cannot; the authors attribute the difference to inductive bias.
Significance. If the architectural attribution is isolated, the work would be significant for understanding how Transformer inductive biases shape shortcut versus compositional solutions in continual and compositional settings. It supplies concrete empirical motivation for recurrent structures in lifelong learning and highlights the risk that initial training can entrench non-generalizable strategies.
major comments (3)
- [model comparison and experimental sections] The central attribution of performance differences to recurrence versus feedforward structure is not isolated. ALBERT additionally uses cross-layer parameter sharing (absent in standard BERT), different pre-training objectives, and typically different effective capacity or optimization settings. The continual LEGO results therefore cannot yet distinguish whether the shortcut entrenchment in BERT versus the loop-like behavior in ALBERT is driven by the recurrent inductive bias or by these other systematic differences. Controlled ablations that vary only recurrence while holding parameter sharing, size, and training regime fixed are required to support the architectural hypothesis.
- [results on ALBERT and data-mixing rescue] The claim that ALBERT learns a 'For loop-esque solution' rests on performance patterns under data mixing and CL transfer. No mechanistic evidence (e.g., representation probing, intervention experiments, or analysis of attention patterns across layers) is provided to demonstrate reusable loop-like computation rather than other forms of parameter reuse enabled by sharing. This interpretation is load-bearing for the contrast with BERT's shortcuts.
- [compositional CL experiments] In the cross-experience compositional CL setting, both models are reported to fail, yet the manuscript provides no quantitative details on the precise failure modes, metrics, statistical tests, error bars, or controls for data order and splits. Without these, it is difficult to evaluate whether the failures are due to entrenched shortcuts (BERT) or insufficient capacity for composition (both), undermining the claim that shortcuts specifically impair forward transfer.
minor comments (2)
- [abstract] The abstract omits all details on metrics, statistical tests, error bars, data splits, and controls; a brief summary of these should be added for readers.
- [introduction and methods] Notation for the continual LEGO tasks and the precise definition of 'shortcut' versus 'compositional' solutions should be introduced earlier and used consistently.
Simulated Author's Rebuttal
Thank you for your detailed and constructive review. We appreciate the focus on isolating architectural effects and strengthening the empirical claims. We address each major comment below and commit to revisions that clarify our findings without overstating the current evidence.
read point-by-point responses
-
Referee: [model comparison and experimental sections] The central attribution of performance differences to recurrence versus feedforward structure is not isolated. ALBERT additionally uses cross-layer parameter sharing (absent in standard BERT), different pre-training objectives, and typically different effective capacity or optimization settings. The continual LEGO results therefore cannot yet distinguish whether the shortcut entrenchment in BERT versus the loop-like behavior in ALBERT is driven by the recurrent inductive bias or by these other systematic differences. Controlled ablations that vary only recurrence while holding parameter sharing, size, and training regime fixed are required to support the architectural hypothesis.
Authors: We agree that the current comparison does not fully isolate recurrence from parameter sharing and other differences between BERT and ALBERT. The recurrent structure is the primary hypothesized driver, but we recognize the potential confounds. In the revised manuscript we will add controlled ablations: a BERT variant with cross-layer parameter sharing (feedforward only) and, where computationally feasible, an ALBERT variant without sharing. We will also standardize pre-training objectives, model sizes, and optimization hyperparameters across conditions to the extent possible. These additions will allow a clearer test of whether the observed differences in shortcut versus reusable computation stem from the recurrent inductive bias. revision: yes
-
Referee: [results on ALBERT and data-mixing rescue] The claim that ALBERT learns a 'For loop-esque solution' rests on performance patterns under data mixing and CL transfer. No mechanistic evidence (e.g., representation probing, intervention experiments, or analysis of attention patterns across layers) is provided to demonstrate reusable loop-like computation rather than other forms of parameter reuse enabled by sharing. This interpretation is load-bearing for the contrast with BERT's shortcuts.
Authors: Our interpretation of loop-like computation in ALBERT is currently supported by behavioral patterns: superior forward transfer, rescue under data mixing, and the contrast with BERT's entrenched shortcuts. We acknowledge that this remains an inference without direct mechanistic confirmation. In the revision we will add analysis of attention patterns across layers and sequence positions in ALBERT to look for evidence of iterative reuse. We will present this as supplementary evidence rather than definitive proof and will tone down the language to 'consistent with' rather than asserting the solution type outright if the mechanistic results are inconclusive. revision: partial
-
Referee: [compositional CL experiments] In the cross-experience compositional CL setting, both models are reported to fail, yet the manuscript provides no quantitative details on the precise failure modes, metrics, statistical tests, error bars, or controls for data order and splits. Without these, it is difficult to evaluate whether the failures are due to entrenched shortcuts (BERT) or insufficient capacity for composition (both), undermining the claim that shortcuts specifically impair forward transfer.
Authors: We agree that the compositional CL results require more granular reporting. The current manuscript states overall failure for both families with a differential rescue effect under mixed training, but lacks the requested details. In the revision we will include full quantitative results: per-condition accuracies with error bars from multiple random seeds, statistical significance tests, explicit descriptions of data order and split controls, and a breakdown of failure modes (e.g., inability to compose specific operations across experiences). These additions will allow readers to assess whether the failures are driven by shortcut entrenchment versus general compositional limits. revision: yes
Circularity Check
No significant circularity; purely empirical study with no load-bearing derivations
full rationale
The paper is an empirical investigation comparing feedforward (BERT) and recurrent (ALBERT) Transformers on continual LEGO tasks. All claims about shortcut solutions versus For-loop-like solutions, forward transfer, and rescue by data mixing are grounded in observed performance metrics across experiments rather than any mathematical derivation, parameter fitting that is then relabeled as prediction, or self-referential definitions. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the inputs by construction. Self-citations, if present, are not load-bearing for the central empirical findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about data distributions, optimization dynamics, and generalization in neural network training.
Reference graph
Works this paper leans on
-
[1]
Physics of language models: Part 1, context-free gram- mar
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 1, context-free grammar.arXiv preprint arXiv:2305.13673,
-
[2]
Awni Altabaa and John Lafferty. Disentangling and integrating relational and sensory information in trans- former architectures.arXiv preprint arXiv:2405.16727,
-
[3]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473,
work page internal anchor Pith review arXiv
-
[4]
YuliangCaiandMohammadRostami. Dynamictransformerarchitectureforcontinuallearningofmultimodal tasks.arXiv preprint arXiv:2401.15275,
-
[5]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
JacobDevlin, Ming-WeiChang, KentonLee, andKristinaToutanova. Bert: Pre-trainingofdeepbidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805,
work page internal anchor Pith review arXiv
-
[6]
13 Subhash Kantamneni, Ziming Liu, and Max Tegmark
doi: 10.1109/TNNLS.2021.3070843. 13 Subhash Kantamneni, Ziming Liu, and Max Tegmark. How do transformers" do" physics? investigating the simple harmonic oscillator.arXiv preprint arXiv:2405.17209,
-
[7]
Mikail Khona, Maya Okawa, Jan Hula, Rahul Ramesh, Kento Nishi, Robert Dick, Ekdeep Singh Lubana, and Hidenori Tanaka. Towards an understanding of stepwise inference in transformers: A synthetic graph navigation model.arXiv preprint arXiv:2402.07757,
-
[8]
When can transformers compositionally generalize in-context? arXiv preprint arXiv:2407.12275,
Seijin Kobayashi, Simon Schug, Yassir Akram, Florian Redhardt, Johannes von Oswald, Razvan Pascanu, Guillaume Lajoie, and João Sacramento. When can transformers compositionally generalize in-context? arXiv preprint arXiv:2407.12275,
-
[9]
Revealing the dark secrets of bert
Olga Kovaleva, Alexey Romanov, Anna Rogers, and Anna Rumshisky. Revealing the dark secrets of bert. arXiv preprint arXiv:1908.08593,
-
[10]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Al- bert: A lite bert for self-supervised learning of language representations.arXiv preprint arXiv:1909.11942,
work page internal anchor Pith review arXiv 1909
-
[11]
Lifelong learning metrics.arXiv preprint arXiv:2201.08278,
Alexander New, Megan Baker, Eric Nguyen, and Gautam Vallabha. Lifelong learning metrics.arXiv preprint arXiv:2201.08278,
-
[12]
arXiv preprint arXiv:2311.12997 , year=
Rahul Ramesh, Mikail Khona, Robert P Dick, Hidenori Tanaka, and Ekdeep Singh Lubana. How capable can a transformer become? a study on synthetic, interpretable tasks.arXiv preprint arXiv:2311.12997,
-
[13]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671,
work page internal anchor Pith review arXiv
-
[14]
14 Xinyi Wang, Alfonso Amayuelas, Kexun Zhang, Liangming Pan, Wenhu Chen, and William Yang Wang. Un- derstanding the reasoning ability of language models from the perspective of reasoning paths aggregation. arXiv preprint arXiv:2402.03268,
-
[15]
Continual learning for large language models: A survey.arXiv preprint arXiv:2402.01364, 2024
Tongtong Wu, Linhao Luo, Yuan-Fang Li, Shirui Pan, Thuy-Trang Vu, and Gholamreza Haffari. Continual learning for large language models: A survey.arXiv preprint arXiv:2402.01364,
-
[16]
Investigating continual pretraining in large language models: Insights and implications,
Çağatay Yıldız, Nishaanth Kanna Ravichandran, Nitin Sharma, Matthias Bethge, and Beyza Ermis. In- vestigating continual pretraining in large language models: Insights and implications.arXiv preprint arXiv:2402.17400,
-
[17]
Improving vision transformers for incremental learning
Pei Yu, Yinpeng Chen, Ying Jin, and Zicheng Liu. Improving vision transformers for incremental learning. arXiv preprint arXiv:2112.06103,
-
[18]
arXiv preprint arXiv:2206.04301 , year=
Yi Zhang, Arturs Backurs, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, and Tal Wagner. Unveiling transformers with lego: a synthetic reasoning task.arXiv preprint arXiv:2206.04301,
-
[19]
elements
Each experience is comprised of two group elements,xi andx j, that can be mapped to each other through the action of a third group element,x k. That isx i◦xk =x j andx j◦xk =x i. We refer tox i andx j as the “elements” of the experience andx k as the “relation” of the experience. We also include the identity group element,x1, as a relation for each experi...
2022
-
[20]
The batch size was set to500
The training and test sets were constructed of60,000and6,000 examples, per flip-flop experience. The batch size was set to500. C Continual learning metrics To quantify the performance of BERT and ALBERT models on the continual LEGO task, we make use of four metrics: task accuracy, generalization accuracy, forward transfer, and performance maintenance (New...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.