Recognition: unknown
Scaling Pretrained Representations Enables Label-Free Out-of-Distribution Detection Without Fine-Tuning
Pith reviewed 2026-05-08 14:53 UTC · model grok-4.3
The pith
Frozen pretrained representations contain enough geometric structure for accurate label-free out-of-distribution detection without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
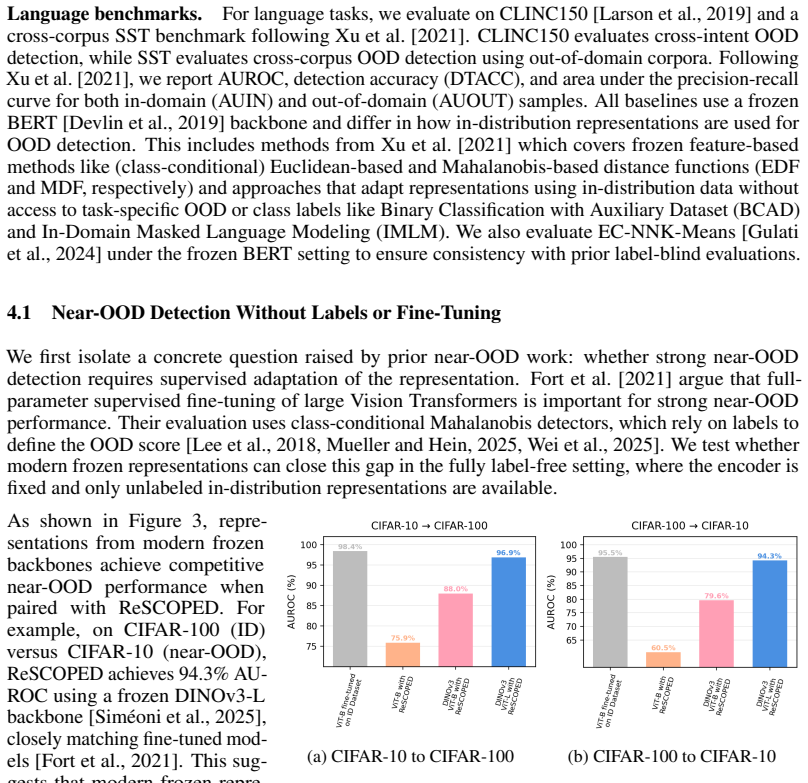
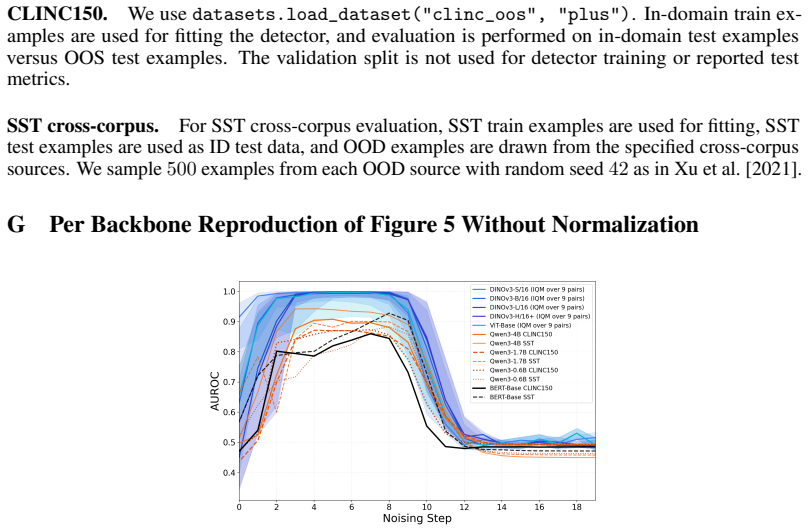
Frozen pretrained representations encode sufficient geometric structure for accurate label-free OOD detection. Across 59 backbone-task pairings, both a global Mahalanobis estimator and a local diffusion-based typicality estimator improve in absolute performance as representation quality scales, and the performance gap between them disappears in both vision and language domains.
What carries the argument
Scaling of frozen pretrained representations, which improves the latent-space geometry available to both global distance-based and local typicality-based detectors.
If this is right
- Label-free OOD detectors can be deployed directly on existing frozen models without any additional training or labels.
- As backbone scale increases, the specific choice between global and local detection mechanisms becomes less consequential.
- Representation quality, rather than detector sophistication, is the primary driver of label-free OOD performance.
- Both distance-based and diffusion-based methods benefit similarly once the underlying features are sufficiently rich.
Where Pith is reading between the lines
- Efforts to improve OOD detection may be better spent on scaling representation quality than on inventing new detector architectures.
- The same scaling benefits observed here could apply to other tasks that rely on the geometry of pretrained embeddings, such as anomaly scoring or uncertainty estimation.
- Models that learn tighter data manifolds through scale may reduce the need for explicit out-of-distribution training objectives.
Load-bearing premise
That the geometry already present in frozen pretrained features is enough to separate in-distribution from out-of-distribution inputs without labels or further training.
What would settle it
If OOD detection accuracy stops improving with larger pretrained models or if the performance difference between the global and local detectors remains large even at the biggest scales tested.
Figures




read the original abstract
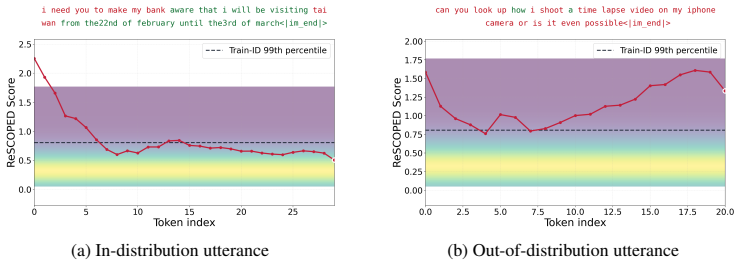
Models trained with deep learning often fail to signal when inputs fall outside their training data manifold, leading to unreliable predictions under distribution shift. Prior work suggests that effective out-of-distribution (OOD) detection often requires class-conditional modeling or specialized models obtained through supervised fine-tuning. We revisit this assumption in modern pretrained models and show that their frozen representations already encode sufficient geometric structure for accurate label-free OOD detection. Across 59 backbone-task pairings spanning vision and language, we compare two complementary label-free detectors: a global Mahalanobis estimator fit on unlabeled latent representations, and ReSCOPED, a lightweight, diffusion-based typicality estimator operating on the same features at a local level. Despite their different detection mechanisms, representation scaling reveals a consistent regime-dependent pattern: both local and global detectors' absolute performance improves with better representation quality, and performance gaps between the two detectors disappear across both language and vision tasks as representations scale. These results suggest that label-free OOD detection depends strongly on the geometry exposed by frozen pretrained backbones, reducing the importance of detector choice as backbone scale increases and enabling efficient deployment directly on frozen models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that frozen representations from modern pretrained models already contain sufficient geometric structure for effective label-free out-of-distribution (OOD) detection, eliminating the need for class-conditional modeling or supervised fine-tuning. Across 59 backbone-task pairings in vision and language, a global Mahalanobis detector and a local diffusion-based ReSCOPED detector both show improved performance with increasing representation scale, with the gap between the two detectors narrowing and eventually disappearing in both modalities.
Significance. If substantiated with fuller experimental detail, the result would be significant for reliable ML deployment: it indicates that representation scaling can render detector choice secondary and enable direct use of frozen backbones for OOD tasks, reducing computational overhead from fine-tuning while highlighting the primacy of pretrained feature geometry over specialized post-processing.
major comments (2)
- [Abstract] Abstract: Results are reported across 59 backbone-task pairings without error bars, standard deviations, statistical significance tests, or explicit exclusion criteria for the pairings. This omission makes it impossible to verify whether the claimed disappearance of detector gaps is robust or merely an artifact of selective reporting.
- [Experimental evaluation] Experimental evaluation: No baseline comparisons to fine-tuned detectors, class-conditional methods, or alternative label-free approaches are described, leaving the central claim that scaling alone suffices without fine-tuning unsupported by direct evidence of relative improvement.
minor comments (1)
- [Abstract] The abstract introduces ReSCOPED only briefly as a 'lightweight, diffusion-based typicality estimator'; a short parenthetical on its core mechanism would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: Results are reported across 59 backbone-task pairings without error bars, standard deviations, statistical significance tests, or explicit exclusion criteria for the pairings. This omission makes it impossible to verify whether the claimed disappearance of detector gaps is robust or merely an artifact of selective reporting.
Authors: We acknowledge the importance of statistical rigor in reporting results across multiple backbone-task pairings. Although the pretrained backbones are deterministic, the OOD detection performance can vary based on the choice of in-distribution and out-of-distribution datasets. In the revised manuscript, we will include error bars representing standard deviations computed over multiple random splits or seeds for dataset sampling. We will also add statistical significance tests (e.g., paired t-tests) to confirm the disappearance of performance gaps. Additionally, we will explicitly state the exclusion criteria: we included all publicly available pretrained models with varying scales that we could access and evaluate within computational constraints, covering both vision (e.g., ResNet, ViT variants) and language (e.g., BERT, GPT variants) modalities. This will allow readers to assess the robustness of our findings. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: No baseline comparisons to fine-tuned detectors, class-conditional methods, or alternative label-free approaches are described, leaving the central claim that scaling alone suffices without fine-tuning unsupported by direct evidence of relative improvement.
Authors: The core focus of our work is on label-free OOD detection using frozen representations, demonstrating that scaling improves performance and reduces the need for specialized detectors. We compare two label-free methods (global Mahalanobis and local ReSCOPED) to highlight the effect of scale. However, to better support the claim that fine-tuning is not necessary, we will incorporate baseline comparisons in the revision. Specifically, we will add results for a fine-tuned detector on a representative subset of tasks and compare against class-conditional approaches from prior work, such as the original Mahalanobis detector with class labels. This will provide direct evidence of relative performance and substantiate that scaling pretrained representations enables effective detection without fine-tuning. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports purely empirical results: performance of two label-free OOD detectors (global Mahalanobis and local ReSCOPED) is measured on frozen pretrained representations across 59 backbone-task pairs in vision and language. Both detectors improve with scale and their gap narrows, supporting the claim that frozen representations suffice for label-free detection. No equations, fitted parameters renamed as predictions, or self-citation chains reduce any reported quantity to its own inputs by construction. The chain consists of direct experimental observations on external pretrained models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen pretrained representations encode sufficient geometric structure for accurate label-free OOD detection
Reference graph
Works this paper leans on
-
[1]
Deep Anomaly Detection with Outlier Exposure
Deep anomaly detection with outlier exposure , author=. arXiv preprint arXiv:1812.04606 , year=
-
[2]
Advances in neural information processing systems , volume=
Energy-based out-of-distribution detection , author=. Advances in neural information processing systems , volume=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Denoising diffusion models for out-of-distribution detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Advances in Neural Information Processing Systems , volume=
Out-of-distribution detection with a single unconditional diffusion model , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Do Deep Generative Models Know What They Don't Know?
Do deep generative models know what they don't know? , author=. arXiv preprint arXiv:1810.09136 , year=
- [6]
-
[7]
2015 , url=
Variational Autoencoder based Anomaly Detection using Reconstruction Probability , author=. 2015 , url=
2015
-
[8]
arXiv preprint arXiv:2102.11650 , year=
Unsupervised brain anomaly detection and segmentation with transformers , author=. arXiv preprint arXiv:2102.11650 , year=
-
[9]
2006 , edition =
Elements of Information Theory , author =. 2006 , edition =
2006
-
[10]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[12]
2025 , eprint=
SCOPED: Score-Curvature Out-of-distribution Proximity Evaluator for Diffusion , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
Locally Typical Sampling , author=. 2025 , eprint=
2025
-
[14]
2021 , eprint=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
2021
-
[15]
2015 , eprint=
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
2015
-
[16]
2022 , eprint=
A ConvNet for the 2020s , author=. 2022 , eprint=
2022
-
[17]
2025 , eprint=
DINOv3 , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[19]
Advances in neural information processing systems , volume=
Exploring the limits of out-of-distribution detection , author=. Advances in neural information processing systems , volume=
-
[20]
KNN -Contrastive Learning for Out-of-Domain Intent Classification
Zhou, Yunhua and Liu, Peiju and Qiu, Xipeng. KNN -Contrastive Learning for Out-of-Domain Intent Classification. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.352
-
[21]
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , url =
Lee, Kimin and Lee, Kibok and Lee, Honglak and Shin, Jinwoo , booktitle =. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , url =
-
[22]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[23]
2015 , eprint=
Deep Learning Face Attributes in the Wild , author=. 2015 , eprint=
2015
-
[24]
Unsupervised out-of-domain detection via pre-trained transformers , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[25]
Lee, K., Lee, K., Lee, H., and Shin, J
A survey on out-of-distribution detection in NLP , author=. arXiv preprint arXiv:2305.03236 , year=
-
[26]
Deep Learning for Anomaly Detection: A Survey
Deep learning for anomaly detection: A survey , author=. arXiv preprint arXiv:1901.03407 , year=
work page Pith review arXiv 1901
-
[27]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Out-of-distribution detection through soft clustering with non-negative kernel regression , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[28]
, author=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. , author=. Proceedings of Thirty-third Conference on Neural Information Processing Systems (NIPS2019) , year=
-
[29]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[30]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review arXiv
-
[31]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review arXiv
-
[32]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[33]
An evaluation dataset for intent classification and out-of-scope prediction , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
2019
-
[34]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[35]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review arXiv 2011
-
[36]
Detecting out-of-distribution inputs to deep generative models using typicality , author=. arXiv preprint arXiv:1906.02994 , year=
-
[37]
2018 , publisher=
High-Dimensional Probability: An Introduction with Applications in Data Science , author=. 2018 , publisher=
2018
-
[38]
International Conference on Machine Learning , pages =
Unsupervised out-of-distribution detection with diffusion inpainting , author =. International Conference on Machine Learning , pages =
-
[39]
Advances in Neural Information Processing Systems , volume =
Likelihood ratios for out-of-distribution detection , author =. Advances in Neural Information Processing Systems , volume =
-
[40]
Gallager, Robert G. , year=. Stochastic Processes: Theory for Applications , publisher=
-
[41]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Yash Katariya and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[42]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Huggingface's transformers: State-of-the-art natural language processing , author=. arXiv preprint arXiv:1910.03771 , year=
work page internal anchor Pith review arXiv 1910
-
[43]
X-Mahalanobis: Transformer Feature Mixing for Reliable
Tong Wei and Bo-Lin Wang and Jiang-Xin Shi and Yu-Feng Li and Min-Ling Zhang , booktitle=. X-Mahalanobis: Transformer Feature Mixing for Reliable. 2025 , url=
2025
-
[44]
Advances in neural information processing systems , volume=
A simple unified framework for detecting out-of-distribution samples and adversarial attacks , author=. Advances in neural information processing systems , volume=
-
[45]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
A baseline for detecting misclassified and out-of-distribution examples in neural networks , author=. arXiv preprint arXiv:1610.02136 , year=
work page internal anchor Pith review arXiv
-
[46]
2005 , url=
Algorithms for manifold learning , author=. 2005 , url=
2005
-
[47]
International Conference on Machine Learning , pages =
Improved contrastive divergence training of energy-based models , author =. International Conference on Machine Learning , pages =
-
[48]
International Conference on Artificial Intelligence and Statistics , pages =
Density of states estimation for out of distribution detection , author =. International Conference on Artificial Intelligence and Statistics , pages =
-
[49]
arXiv preprint arXiv:2010.13132 , year=
Multiscale score matching for out-of-distribution detection , author=. arXiv preprint arXiv:2010.13132 , year=
-
[50]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[51]
Communications in Statistics--Simulation and Computation , volume=
A Stochastic Estimator of the Trace of the Influence Matrix for Laplacian Smoothing Splines , author=. Communications in Statistics--Simulation and Computation , volume=
-
[52]
Scandinavian Conference on Image Analysis , pages=
Revisiting likelihood-based out-of-distribution detection by modeling representations , author=. Scandinavian Conference on Image Analysis , pages=. 2025 , organization=
2025
-
[53]
2009 , url=
Learning Multiple Layers of Features from Tiny Images , author=. 2009 , url=
2009
-
[54]
2011 , url=
Reading Digits in Natural Images with Unsupervised Feature Learning , author=. 2011 , url=
2011
-
[55]
Proceedings of International Conference on Computer Vision (ICCV) , month =
Deep Learning Face Attributes in the Wild , author =. Proceedings of International Conference on Computer Vision (ICCV) , month =
-
[56]
2025 , eprint=
Mahalanobis++: Improving OOD Detection via Feature Normalization , author=. 2025 , eprint=
2025
-
[57]
2025 , eprint=
Equipping Vision Foundation Model with Mixture of Experts for Out-of-Distribution Detection , author=. 2025 , eprint=
2025
-
[58]
2026 , eprint=
A Geometry-Based View of Mahalanobis OOD Detection , author=. 2026 , eprint=
2026
-
[59]
2024 , eprint=
How Good Are LLMs at Out-of-Distribution Detection? , author=. 2024 , eprint=
2024
-
[60]
2024 , eprint=
DINOv2: Learning Robust Visual Features without Supervision , author=. 2024 , eprint=
2024
-
[61]
2021 , eprint=
No True State-of-the-Art? OOD Detection Methods are Inconsistent across Datasets , author=. 2021 , eprint=
2021
-
[62]
5: Enhanced Benchmark for Out-of-Distribution Detection , author=
OpenOOD v1. 5: Enhanced Benchmark for Out-of-Distribution Detection , author=. Journal of Data-centric Machine Learning Research , year=
-
[63]
arXiv preprint arXiv:2209.15558 , year=
Out-of-distribution detection and selective generation for conditional language models , author=. arXiv preprint arXiv:2209.15558 , year=
-
[64]
Proceedings on , pages=
Self-Evaluation Improves Selective Generation in Large Language Models , author=. Proceedings on , pages=. 2023 , organization=
2023
-
[65]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
The internal state of an LLM knows when it’s lying , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.