Recognition: unknown
Information-Preserving Domain Transfer with Unlabeled Data in Misspecified Simulation-Based Inference
Pith reviewed 2026-05-08 14:55 UTC · model grok-4.3
The pith
SPIN uses label-guided cycles to keep parameter information when adapting SBI to mismatched real data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a cycle of domain translations—sending simulator observations to the real-world domain and mapping them back while conditioning on the original simulator labels—preserves the mutual information between observations and parameters. Once this cycle is learned, real-world observations can be transported into the simulator domain at test time, allowing existing SBI methods to produce accurate posteriors without real parameter labels or paired data.
What carries the argument
The bidirectional domain transport cycle that uses simulator parameter labels to enforce preservation of parameter-relevant mutual information.
If this is right
- Real-world posterior estimates improve relative to methods that align distributions without using simulator labels.
- The accuracy gain widens as the simulator becomes more misspecified.
- No paired real-simulator observations or real-world parameter labels are required.
- The approach applies to both synthetic benchmarks and physical real-world tasks.
Where Pith is reading between the lines
- The result suggests that marginal distribution alignment is not enough for inference tasks; explicit protection of parameter information during transfer is necessary.
- Similar label-guided cycles could be tested between two different simulators rather than simulator and reality.
- One could measure preserved mutual information as a diagnostic to decide whether the transferred data is still usable for inference.
- The framework might combine with other SBI improvements such as better summary statistics or sequential refinement.
Load-bearing premise
The cycle of domain translation guided by simulator labels sufficiently preserves parameter-relevant mutual information for downstream posterior inference to remain accurate.
What would settle it
A controlled test in which mutual information between the transported observations and parameters is measured directly and shown to drop without a corresponding drop in posterior accuracy, or in which SPIN shows no advantage over simple marginal alignment baselines at high misspecification.
Figures









read the original abstract
Simulation-based inference (SBI) provides amortized Bayesian parameter inference from simulator-generated data without requiring explicit likelihood evaluation. Its reliability can degrade under model misspecification, where real-world observations are not well represented by the simulator used for training. Existing methods using unlabeled real-world data often align simulated and real-world data distributions, but marginal alignment alone does not directly preserve parameter-relevant information needed for posterior inference. We propose SPIN, an SBI framework with parameter-relevant information-preserving domain transfer using unlabeled, unpaired real-world observations. During training, SPIN translates labeled simulator observations toward the real-world domain and back to the simulator domain, using the original simulator labels to encourage domain transfer that preserves parameter-relevant mutual information. At test time, the learned real-to-simulator transport maps real-world observations into the simulator domain for posterior inference, without requiring real-world parameter labels or paired real--simulator observations. Across controlled synthetic and physical real-world benchmarks, SPIN improves real-world posterior inference, with the improvement becoming clearer as misspecification increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPIN, an SBI framework for parameter-relevant information-preserving domain transfer with unlabeled unpaired real-world data. It translates labeled simulator observations to the real domain and back to the simulator domain, using the original labels to regularize the cycle and encourage preservation of parameter-relevant mutual information; at inference, real observations are mapped to the simulator domain for posterior estimation. The approach is evaluated on controlled synthetic and physical real-world benchmarks, with the claim that posterior inference improves and the gains become more pronounced as misspecification increases.
Significance. If the empirical results hold, the work could meaningfully advance practical SBI by providing a heuristic for incorporating unpaired unlabeled real data to mitigate misspecification without requiring real labels or paired observations. The label-regularized cycle is a reasonable extension of cycle-consistent translation to the SBI setting, and the focus on performance trends under increasing misspecification offers a direct test of utility in realistic conditions.
major comments (2)
- Method section (cycle regularization): the claim that simulator labels in the sim-to-real-to-sim cycle preserve parameter-relevant mutual information is load-bearing for the central contribution, yet the manuscript provides no quantitative verification such as mutual-information estimates between parameters and translated observations or an ablation removing the label-based regularization term to isolate its effect versus generic domain alignment.
- Experiments section: to support the claim that improvement becomes clearer as misspecification increases, results must systematically vary misspecification levels (with explicit definitions of each level) and report performance metrics with error bars or statistical tests; without this, the trend cannot be distinguished from noise or dataset-specific effects.
minor comments (3)
- Abstract: the claim of benchmark improvements is stated without any numerical values, metrics, or error ranges; adding one sentence summarizing key quantitative gains would improve clarity for readers.
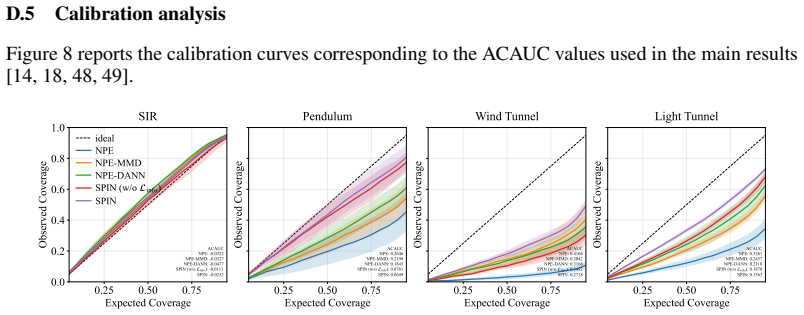
- Figures and tables: captions should explicitly state the misspecification levels used, the exact metrics plotted (e.g., posterior mean error, coverage), and whether results are averaged over multiple runs.
- Notation: define the precise form of the label-regularization loss (e.g., cross-entropy on parameters or reconstruction) at first use rather than relying on high-level description.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive comments. We address each major point below and have incorporated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Method section (cycle regularization): the claim that simulator labels in the sim-to-real-to-sim cycle preserve parameter-relevant mutual information is load-bearing for the central contribution, yet the manuscript provides no quantitative verification such as mutual-information estimates between parameters and translated observations or an ablation removing the label-based regularization term to isolate its effect versus generic domain alignment.
Authors: We agree that explicit quantitative verification would strengthen the central claim. In the revised manuscript we have added an ablation that removes the label-based regularization term from the cycle-consistent loss and compares posterior performance against the full model on the synthetic benchmarks. We also report mutual-information estimates (using a neural estimator) between simulator parameters and the translated observations for both the regularized and unregularized cycles, showing that the label regularization maintains substantially higher parameter-relevant MI. These additions provide the requested empirical support without altering the original method. revision: yes
-
Referee: Experiments section: to support the claim that improvement becomes clearer as misspecification increases, results must systematically vary misspecification levels (with explicit definitions of each level) and report performance metrics with error bars or statistical tests; without this, the trend cannot be distinguished from noise or dataset-specific effects.
Authors: We concur that the trend requires more rigorous presentation. The revision now includes explicit definitions of the misspecification levels (parameterized by the magnitude of the distribution shift introduced in the real-world data generator). All reported metrics are accompanied by error bars over 10 independent random seeds, and we have added paired t-tests with p-values to compare SPIN against baselines at each level. These changes make the increasing benefit under higher misspecification statistically distinguishable from noise. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents SPIN as a practical heuristic framework that adapts cycle-consistent domain translation to SBI by using simulator labels to regularize the sim-to-real-to-sim cycle, thereby aiming to preserve parameter-relevant mutual information. The central claims rest on empirical demonstrations across synthetic and physical benchmarks rather than on any closed-form derivation or prediction that reduces to its own fitted inputs by construction. No load-bearing self-citations, self-definitional steps, or uniqueness theorems imported from prior author work are invoked to force the result; the method is evaluated against external real-world data and standard SBI baselines, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulator-generated data carries usable parameter labels that can guide domain transfer to retain relevant information.
Reference graph
Works this paper leans on
-
[1]
2020, Proceedings of the National Academy of Science, 117, 30055, doi: 10.1073/pnas.1912789117
Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference. Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020. doi: 10.1073/ pnas.1912789117. URLhttps://doi.org/10.1073/pnas.1912789117
-
[2]
Michael Deistler, Jan Boelts, Peter Steinbach, Guy Moss, Thomas Moreau, Manuel Gloeckler, Pedro L. C. Rodrigues, Julia Linhart, Janne K. Lappalainen, Benjamin Kurt Miller, Pedro J. Gonçalves, Jan-Matthis Lueckmann, Cornelius Schröder, and Jakob H. Macke. Simulation- based inference: A practical guide, 2025. URLhttps://arxiv.org/abs/2508.12939
-
[3]
Fastϵ-free inference of simulation models with Bayesian conditional density estimation
George Papamakarios and Iain Murray. Fastϵ-free inference of simulation models with Bayesian conditional density estimation. InAdvances in Neural Information Processing Systems, vol- ume 29, pages 1028–1036, 2016. URL https://proceedings.neurips.cc/paper/2016/ hash/6aca97005c68f1206823815f66102863-Abstract.html
2016
-
[4]
Greenberg, Marcel Nonnenmacher, and Jakob H
David S. Greenberg, Marcel Nonnenmacher, and Jakob H. Macke. Automatic posterior trans- formation for likelihood-free inference. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 2404–2414,
-
[5]
URLhttps://proceedings.mlr.press/v97/greenberg19a.html
-
[6]
George E. P. Box. Science and statistics.Journal of the American Statistical Association, 71 (356):791–799, 1976. doi: 10.1080/01621459.1976.10480949. URL https://doi.org/10. 1080/01621459.1976.10480949
-
[7]
David T. Frazier, Christian P. Robert, and Judith Rousseau. Model misspecification in approxi- mate bayesian computation: Consequences and diagnostics.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(2):421–444, 2020. doi: 10.1111/rssb.12356. URLhttps://doi.org/10.1111/rssb.12356
- [8]
-
[9]
B. J. K. Kleijn and A. W. van der Vaart. The bernstein-von mises theorem under misspecification. Electronic Journal of Statistics, 6:354–381, 2012. doi: 10.1214/12-EJS675. URL https: //doi.org/10.1214/12-EJS675
-
[10]
Posterior predictive assessment of model fitness via realized discrepancies.Statistica Sinica, 6(4):733–807, 1996
Andrew Gelman, Xiao-Li Meng, and Hal Stern. Posterior predictive assessment of model fitness via realized discrepancies.Statistica Sinica, 6(4):733–807, 1996. URL https://www3.stat. sinica.edu.tw/statistica/j6n4/j6n41/j6n41.htm
1996
-
[11]
Daniel Ward, Patrick Cannon, Mark Beaumont, Matteo Fasiolo, and Sebastian M. Schmon. Robust neural posterior estimation and statistical model criticism. InAdvances in Neural Information Processing Systems, volume 35, pages 33845–33859, 2022. URL https:// neurips.cc/virtual/2022/poster/52936
2022
-
[12]
Detecting model misspecification in amortized bayesian inference with neural networks
Marvin Schmitt, Paul-Christian Bürkner, Ullrich Köthe, and Stefan T Radev. Detecting model misspecification in amortized bayesian inference with neural networks. InDagm german conference on pattern recognition, pages 541–557. Springer, 2023. URL https://arxiv. org/pdf/2112.08866. 10
-
[13]
Souza, Luigi Acerbi, and Samuel Kaski
Daolang Huang, Ayush Bharti, Amauri H. Souza, Luigi Acerbi, and Samuel Kaski. Learning robust statistics for simulation-based inference under model mis- specification. InAdvances in Neural Information Processing Systems, volume 36,
-
[14]
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 16c5b4102a6b6eb061e502ce6736ad8a-Abstract-Conference.html
2023
-
[15]
Marvin Schmitt, Desi Ivanova, Daniel Habermann, Paul-Christian Bürkner, Ullrich Köthe, and Stefan T. Radev. Robust amortized bayesian inference with self-consistency losses on unlabeled data. InInternational Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=E1dANKwo4I
2026
-
[16]
Gamella, Ozan Sener, Jens Behrmann, Guillermo Sapiro, Jörn- Henrik Jacobsen, and Marco Cuturi
Antoine Wehenkel, Juan L. Gamella, Ozan Sener, Jens Behrmann, Guillermo Sapiro, Jörn- Henrik Jacobsen, and Marco Cuturi. Addressing misspecification in simulation-based inference through data-driven calibration. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, 2025. URL https://...
2025
-
[17]
Nicolas Courty, Rémi Flamary, Devis Tuia, and Alain Rakotomamonjy. Optimal transport for domain adaptation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(9): 1853–1865, 2017. doi: 10.1109/TPAMI.2016.2615921. URL https://doi.org/10.1109/ TPAMI.2016.2615921
-
[18]
Cédric Villani.Optimal Transport: Old and New, volume 338 ofGrundlehren der mathematis- chen Wissenschaften. Springer, Berlin, Heidelberg, 2009. doi: 10.1007/978-3-540-71050-9. URLhttps://doi.org/10.1007/978-3-540-71050-9
-
[19]
Gabriel Peyré and Marco Cuturi.Computational optimal transport: With applications to data science. Now Foundations and Trends, 2019. URLhttps://arxiv.org/abs/1803.00567
-
[20]
Inductive domain transfer in misspecified simulation-based inference
Ortal Senouf, Antoine Wehenkel, Cédric Vincent-Cuaz, Emmanuel Abbé, and Pascal Frossard. Inductive domain transfer in misspecified simulation-based inference. InAdvances in Neu- ral Information Processing Systems, 2025. URL https://openreview.net/forum?id= PhnquAa8eV
2025
-
[21]
Marvin Schmitt, Desi Ivanova, Daniel Habermann, Paul-Christian Bürkner, Ullrich Köthe, and Stefan T. Radev. Leveraging self-consistency for data-efficient amortized bayesian inference. InProceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 43723–43741. PMLR, 2024. URL https: //...
2024
-
[22]
Ivanova, Marvin Schmitt, and Stefan T
Desi R. Ivanova, Marvin Schmitt, and Stefan T. Radev. Data-efficient variational mutual informa- tion estimation via bayesian self-consistency. InNeurIPS 2024 Workshop on Bayesian Decision- making and Uncertainty, 2024. URLhttps://openreview.net/forum?id=QfiyElaO1f
2024
-
[23]
Lasse Elsemüller, Valentin Pratz, Mischa von Krause, Andreas V oss, Paul-Christian Bürkner, and Stefan T. Radev. Does unsupervised domain adaptation improve the robustness of amortized bayesian inference? a systematic evaluation.Transactions on Machine Learning Research,
-
[24]
URLhttps://openreview.net/forum?id=ewgLuvnEw6
-
[25]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.Journal of Machine Learning Research, 13(25):723–773,
-
[26]
URLhttps://jmlr.org/papers/v13/gretton12a.html
-
[27]
Domain-adversarial training of neural networks.Journal of Machine Learning Research, 17(59):1–35, 2016
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks.Journal of Machine Learning Research, 17(59):1–35, 2016. URL https://jmlr. org/papers/v17/15-239.html
2016
-
[28]
Johansson, David Sontag, and Rajesh Ranganath
Fredrik D. Johansson, David Sontag, and Rajesh Ranganath. Support and invertibility in domain- invariant representations. InProceedings of the 22nd International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 527–536, 2019. URLhttps://proceedings.mlr.press/v89/johansson19a.html. 11
2019
-
[29]
Han Zhao, Remi Tachet des Combes, Kun Zhang, and Geoffrey J. Gordon. On learning invariant representations for domain adaptation. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 7523–7532,
-
[30]
URLhttps://proceedings.mlr.press/v97/zhao19a.html
-
[31]
Domain adaptation with invariant representation learning: What transformations to learn? In M
Petar Stojanov, Zijian Li, Mingming Gong, Ruichu Cai, Jaime Carbonell, and Kun Zhang. Domain adaptation with invariant representation learning: What transformations to learn? In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 24791–24803. Curran Assoc...
2021
-
[32]
CyCADA: Cycle-consistent adversarial domain adaptation
Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. CyCADA: Cycle-consistent adversarial domain adaptation. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1989–1998. PM...
1989
-
[33]
Stefan T. Radev, Ulf K. Mertens, Andreas V oss, Lynton Ardizzone, and Ullrich Köthe. BayesFlow: Learning complex stochastic models with invertible neural networks.IEEE Transactions on Neural Networks and Learning Systems, 33(4):1452–1466, 2022. doi: 10.1109/TNNLS.2020.3042395. URL https://doi.org/10.1109/TNNLS.2020.3042395
-
[34]
Gutmann, Aaron Courville, and Zhanxing Zhu
Yanzhi Chen, Dinghuai Zhang, Michael U. Gutmann, Aaron Courville, and Zhanxing Zhu. Neural approximate sufficient statistics for implicit models. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=SRDuJssQud
2021
-
[35]
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE International Conference on Computer Vision, pages 2223–2232, 2017. doi: 10.1109/ICCV .2017.244. URL https://doi.org/10.1109/ICCV.2017.244
-
[36]
Claude E. Shannon. A mathematical theory of communication.The Bell System Technical Journal, 27(3–4):379–423, 623–656, 1948. doi: 10.1002/j.1538-7305.1948.tb01338.x. URL https://doi.org/10.1002/j.1538-7305.1948.tb01338.x
-
[37]
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. Wiley-Interscience, Hoboken, NJ, 2 edition, 2006. doi: 10.1002/047174882X. URL https://doi.org/10.1002/ 047174882X
-
[38]
David Barber and Felix V . Agakov. The IM algorithm: A variational approach to information maximization. InAdvances in Neural Information Processing Systems, volume 16, 2003. URL https://aivalley.com/Papers/MI_NIPS_final.pdf
2003
-
[39]
Alemi, and George Tucker
Ben Poole, Sherjil Ozair, Aaron van den Oord, Alexander A. Alemi, and George Tucker. On variational bounds of mutual information. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 5171– 5180, 2019. URLhttps://proceedings.mlr.press/v97/poole19a.html
2019
-
[40]
Spectral normalization for generative adversarial networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. InInternational Conference on Learning Representations,
-
[41]
URLhttps://openreview.net/forum?id=B1QRgziT-
-
[42]
William Ogilvy Kermack and Anderson G. McKendrick. A contribution to the mathematical theory of epidemics.Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character, 115(772):700–721, 1927. doi: 10.1098/rspa.1927.0118. URLhttps://doi.org/10.1098/rspa.1927.0118
-
[43]
L., Peters, J., and B \"u hlmann, P
Juan L. Gamella, Jonas Peters, and Peter Bühlmann. Causal chambers as a real-world physical testbed for AI methodology.Nature Machine Intelligence, 7:107–118, 2025. doi: 10.1038/ s42256-024-00964-x. URLhttps://doi.org/10.1038/s42256-024-00964-x. 12
-
[44]
Greenberg, Pedro J
Jan-Matthis Lueckmann, Jan Boelts, David S. Greenberg, Pedro J. Gonçalves, and Jakob H. Macke. Benchmarking simulation-based inference. InProceedings of the 24th International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 343–351, 2021. URL https://proceedings.mlr.press/v130/ lueckmann21a.html
2021
-
[45]
A crisis in simulation-based inference? beware, your posterior approx- imations can be unfaithful.Transactions on Machine Learning Research, 2022
Joeri Hermans, Arnaud Delaunoy, François Rozet, Antoine Wehenkel, V olodimir Begy, and Gilles Louppe. A crisis in simulation-based inference? beware, your posterior approx- imations can be unfaithful.Transactions on Machine Learning Research, 2022. URL https://openreview.net/forum?id=LHAbHkt6Aq
2022
-
[46]
Solomon Kullback and Richard A. Leibler. On information and sufficiency.The Annals of Mathematical Statistics, 22(1):79–86, 1951. doi: 10.1214/aoms/1177729694. URL https: //doi.org/10.1214/aoms/1177729694
-
[47]
Aaditya Ramdas, Nicolás García Trillos, and Marco Cuturi. On wasserstein two-sample testing and related families of nonparametric tests.Entropy, 19(2):47, 2017. doi: 10.3390/e19020047. URLhttps://doi.org/10.3390/e19020047
-
[48]
SPIE Press, Bellingham, WA, 2005
Edward Collett.Field Guide to Polarization. SPIE Press, Bellingham, WA, 2005. doi: 10.1117/3.626141. URLhttps://doi.org/10.1117/3.626141
-
[49]
Wasserstein auto- encoders
Ilya Tolstikhin, Olivier Bousquet, Sylvain Gelly, and Bernhard Schölkopf. Wasserstein auto- encoders. InInternational Conference on Learning Representations, 2018. URL https: //openreview.net/forum?id=HkL7n1-0b
2018
-
[50]
Masked autoregressive flow for density estimation
George Papamakarios, Theo Pavlakou, and Iain Murray. Masked autoregressive flow for density estimation. InAdvances in Neural Information Processing Systems, volume 30, pages 2335–2344, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/ 6c1da886822c67822bcf3679d04369fa-Abstract.html
2017
-
[51]
probabilists/zuko: Zuko 1.1.0, January 2024
François Rozet, Felix Divo, and Simon Schnake. probabilists/zuko: Zuko 1.1.0, January 2024. URLhttps://doi.org/10.5281/zenodo.10571785
-
[52]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
2019
-
[53]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations, 2015. URL https://arxiv.org/abs/1412. 6980
2015
-
[54]
Validation of software for bayesian models using posterior quantiles,
Samantha R. Cook, Andrew Gelman, and Donald B. Rubin. Validation of software for bayesian models using posterior quantiles.Journal of Computational and Graphical Statistics, 15 (3):675–692, 2006. doi: 10.1198/106186006X136976. URL https://doi.org/10.1198/ 106186006X136976
-
[55]
Sean Talts, Michael Betancourt, Daniel Simpson, Aki Vehtari, and Andrew Gelman. Validating bayesian inference algorithms with simulation-based calibration, 2018. URL https://arxiv. org/abs/1804.06788. 13 A Mathematical details for parameter-relevant information preservation This appendix collects the population identities used to interpret the information...
-
[56]
with scales {0.1,0.2,0.5,1,2,5,10} .NPE-DANN[ 21] also uses the same summary network and posterior flow, and adds a domain classifier with3 hidden layers of width 256. Domain confusion is applied through a gradient reversal layer with the standard schedule [23] λgrl(p) = 2 1 + exp(−10p) −1, where p is the normalized training progress. The domain classifie...
-
[57]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.