Recognition: unknown
Structural Correspondence and Universal Approximation in Diagonal plus Low-Rank Neural Networks
Pith reviewed 2026-05-08 15:01 UTC · model grok-4.3
The pith
Adding a sparse diagonal to low-rank layers restores universal approximation without pretrained priors or special activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that augmenting low-rank layers with only a minimal sparse diagonal component is sufficient to reach universal approximation. Any full-rank transformation can be exactly reconstructed using these DLoR components by trading off network width through additive decomposition or depth through multiplicative decomposition. By tracking asymptotic Taylor remainders, DLoR neural networks fully restore the Universal Approximation Theorem for general activation functions, and multiplicative depth yields better parameter-to-expressivity scaling than additive width.
What carries the argument
The Diagonal plus Low-Rank (DLoR) layer structure, which augments a low-rank factorization with a sparse diagonal matrix to enable exact recovery of arbitrary linear transformations.
If this is right
- DLoR networks achieve the same approximation power as dense networks for any continuous target.
- Universal approximation holds for general activations without ReLU or other restrictions.
- Multiplicative (depth) decompositions improve scaling of parameters to expressivity over additive (width) ones.
- Parameter-efficient architectures no longer require a pretrained dense base matrix.
Where Pith is reading between the lines
- The same minimal diagonal augmentation might improve other low-rank methods such as tensor factorizations or matrix completion.
- Architectures could be designed by choosing the smallest diagonal sparsity pattern that still permits exact decomposition for a given target function class.
- The width-versus-depth trade-off suggests testing whether deeper DLoR stacks outperform wider ones on high-dimensional tasks with fixed parameter budgets.
Load-bearing premise
The structural decompositions hold exactly for arbitrary continuous functions and the asymptotic Taylor remainders can be tracked without extra singularity conditions or pretrained priors.
What would settle it
A concrete continuous function on a compact domain that no finite-width finite-depth DLoR network can approximate to arbitrary accuracy, or a full-rank matrix that cannot be expressed as a product or sum of DLoR factors.
Figures

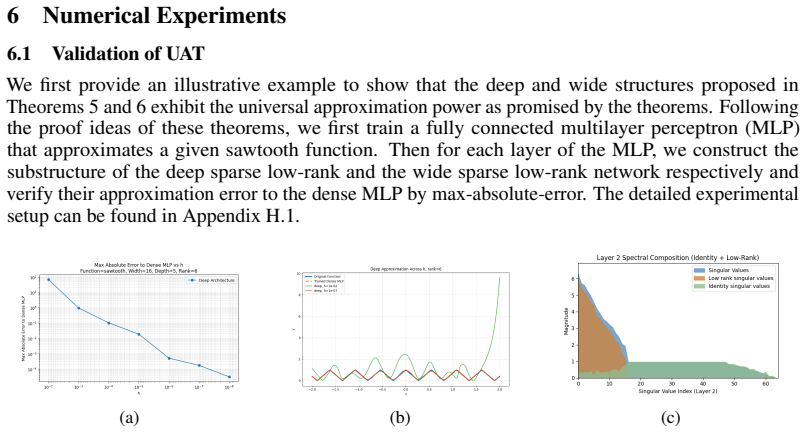
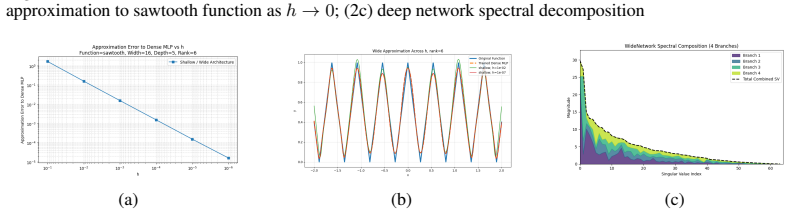
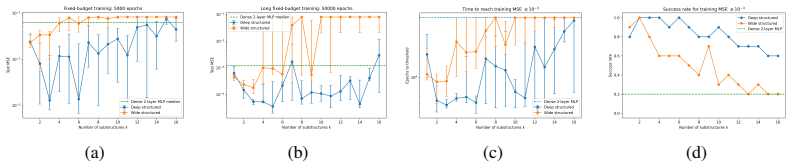


read the original abstract
The massive computational costs of scaling modern deep learning architectures have driven the widespread use of parameter-efficient low-rank structures, such as LoRA and low-rank factorization. However, theoretical guarantees for their expressive power are less explored, often relying on restrictive priors like a pretrained base matrix, ReLU activations or non-verifiable singularity conditions. We first investigate the limits of neural networks constrained strictly to low-rank manifolds without pretrained dense priors. We demonstrate a theoretical paradox: while purely rank-1 layers can exactly interpolate arbitrary scalar datasets, they collapse for function approximations. To overcome this bottleneck without surrendering parameter efficiency, we introduce a unified \textit{Structural Correspondence} framework. We prove that augmenting low-rank layers with only a minimal sparse diagonal component, say a Diagonal plus Low-Rank (DLoR) structure, is sufficient to reach Universal Approximation. We show that any full-rank transformation can be exactly reconstructed using these DLoR components by trading off network width (additive decomposition) or depth (multiplicative decomposition). By tracking asymptotic Taylor remainders, we prove that DLoR neural networks fully restore the Universal Approximation Theorem for general activation functions. Finally, we establish that multiplicative depth provides superior parameter-to-expressivity scaling compared to additive width. Our results show that dense matrices and specific activation functions are not topological prerequisites for universal expressivity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Structural Correspondence framework and proves that Diagonal plus Low-Rank (DLoR) neural networks suffice for universal approximation. It shows that any full-rank linear transformation can be exactly reconstructed from DLoR components via additive decomposition (trading width) or multiplicative decomposition (trading depth), then extends this to arbitrary continuous target functions by tracking asymptotic Taylor remainders, claiming restoration of the UAT for general activations without pretrained priors or singularity conditions. It further asserts that multiplicative depth yields superior parameter-to-expressivity scaling.
Significance. If the central derivations hold, the result is significant: it supplies a parameter-efficient structural alternative to dense matrices while recovering full expressivity, with explicit width/depth trade-offs and a framework that avoids restrictive assumptions common in prior low-rank analyses. The exact linear reconstruction and the emphasis on depth scaling are concrete strengths that could inform efficient architecture design.
major comments (2)
- [Abstract] Abstract (paragraph on Taylor remainders): the extension from exact linear reconstruction to the UAT for general activations rests on tracking asymptotic Taylor remainders to ensure uniform convergence; however, this step presupposes sufficient differentiability, which fails for standard non-smooth activations such as ReLU at the origin, and the manuscript does not supply explicit remainder bounds or singularity-handling conditions that would restore the claim for arbitrary continuous functions.
- [Main proof of UAT restoration] The reconstruction claims (additive and multiplicative decompositions): while the linear full-rank case is asserted to be exact, the load-bearing step for the nonlinear extension requires that the remainder terms vanish uniformly over the domain for the chosen activations; without this control shown for non-analytic activations, the restoration of the UAT cannot be verified from the stated construction.
minor comments (2)
- [Introduction] The definition and precise axioms of the 'Structural Correspondence' framework are introduced without an early formal statement; placing a concise definition or diagram in the introduction would improve readability.
- [Notation and definitions] Notation for the diagonal and low-rank components (e.g., how the sparse diagonal is parameterized) should be standardized across sections to avoid ambiguity when comparing width versus depth trade-offs.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The concerns about differentiability assumptions and remainder control in the UAT extension are valid, and we will revise the manuscript to address them explicitly while preserving the core contributions on structural correspondence and DLoR decompositions.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on Taylor remainders): the extension from exact linear reconstruction to the UAT for general activations rests on tracking asymptotic Taylor remainders to ensure uniform convergence; however, this step presupposes sufficient differentiability, which fails for standard non-smooth activations such as ReLU at the origin, and the manuscript does not supply explicit remainder bounds or singularity-handling conditions that would restore the claim for arbitrary continuous functions.
Authors: We agree that the Taylor remainder tracking presupposes sufficient differentiability and that the manuscript's phrasing of 'general activation functions' is too broad. The linear reconstruction results hold independently of activation smoothness. We will revise the abstract and introduction to qualify the UAT claim as holding for activations admitting Taylor expansions with controllable remainders (e.g., C^1 or C^infty on compact sets). Explicit asymptotic remainder bounds will be added to ensure uniform convergence, along with a clarifying note that the result does not directly cover non-differentiable activations such as ReLU and that alternative arguments would be required in those cases. revision: yes
-
Referee: [Main proof of UAT restoration] The reconstruction claims (additive and multiplicative decompositions): while the linear full-rank case is asserted to be exact, the load-bearing step for the nonlinear extension requires that the remainder terms vanish uniformly over the domain for the chosen activations; without this control shown for non-analytic activations, the restoration of the UAT cannot be verified from the stated construction.
Authors: The referee is correct that uniform vanishing of remainders must be shown explicitly for the nonlinear extension. The manuscript tracks asymptotic remainders but does not provide the full uniform bounds or domain-specific estimates needed for verification, especially beyond analytic activations. We will expand the relevant proof sections to include these controls under the differentiability assumptions, demonstrating that the remainders can be made arbitrarily small uniformly on compact domains. This will make the UAT restoration verifiable while leaving the exact linear decompositions unchanged. revision: yes
Circularity Check
No significant circularity; derivation is self-contained mathematical construction
full rationale
The paper's central claims rest on explicit additive and multiplicative decompositions of full-rank maps into DLoR components, followed by asymptotic Taylor remainder tracking to extend linear reconstruction to nonlinear universal approximation. These steps are presented as direct proofs from the definitions of DLoR structure and standard Taylor expansion properties, without any reduction to fitted parameters, self-referential definitions, or load-bearing self-citations. No equations or arguments in the provided text equate a prediction to its own input by construction. The derivation therefore remains independent of the target result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption General activation functions admit asymptotic Taylor expansions whose remainders can be controlled to establish universal approximation
invented entities (1)
-
Structural Correspondence framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021
2021
-
[3]
A convergence theory for deep learning via over-parameterization
Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. InInternational Conference on Machine Learning, pages 242–252. PMLR, 2019
2019
-
[4]
Implicit regularization in deep matrix factorization.Advances in Neural Information Processing Systems, 32, 2019
Sanjeev Arora, Nadav Cohen, Wei Hu, and Yuping Luo. Implicit regularization in deep matrix factorization.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[5]
Deep learning over-parameterization: the shallow fallacy
Pierre Baldi. Deep learning over-parameterization: the shallow fallacy. InNorthern Lights Deep Learning Conference, pages 7–12. PMLR, 2024
2024
-
[6]
Sparse plus low rank matrix decomposition: A discrete optimization approach.Journal of Machine Learning Research, 24(267):1–51, 2023
Dimitris Bertsimas, Ryan Cory-Wright, and Nicholas AG Johnson. Sparse plus low rank matrix decomposition: A discrete optimization approach.Journal of Machine Learning Research, 24(267):1–51, 2023
2023
-
[7]
Optimal approximation with sparsely connected deep neural networks.SIAM Journal on Mathematics of Data Science, 1(1):8–45, 2019
Helmut Bolcskei, Philipp Grohs, Gitta Kutyniok, and Philipp Petersen. Optimal approximation with sparsely connected deep neural networks.SIAM Journal on Mathematics of Data Science, 1(1):8–45, 2019
2019
-
[8]
SGD learns over- parameterized networks that provably generalize on linearly separable data
Alon Brutzkus, Amir Globerson, Eran Malach, and Shai Shalev-Shwartz. SGD learns over- parameterized networks that provably generalize on linearly separable data. InInternational Conference on Learning Representations, 2018
2018
-
[9]
Sparse and low-rank matrix decompositions.IFAC Proceedings Volumes, 42(10):1493–1498, 2009
Venkat Chandrasekaran, Sujay Sanghavi, Pablo A Parrilo, and Alan S Willsky. Sparse and low-rank matrix decompositions.IFAC Proceedings Volumes, 42(10):1493–1498, 2009
2009
-
[10]
Scatterbrain: unifying sparse and low-rank attention approximation, 2021
Beidi Chen, Tri Dao, Eric Winsor, Zhao Song, Atri Rudra, and Christopher Ré. Scatterbrain: unifying sparse and low-rank attention approximation, 2021
2021
-
[11]
The loss surfaces of multilayer networks
Anna Choromanska, Mikael Henaff, Michael Mathieu, Gérard Ben Arous, and Yann LeCun. The loss surfaces of multilayer networks. InInternational Conference on Artificial Intelligence and Statistics, pages 192–204. PMLR, 2015
2015
-
[12]
On the expressive power of deep learning: A tensor analysis
Nadav Cohen, Or Sharir, and Amnon Shashua. On the expressive power of deep learning: A tensor analysis. InConference on Learning Theory, pages 698–728. PMLR, 2016
2016
-
[13]
arXiv preprint arXiv:2304.10552 , year=
Vlad-Raul Constantinescu and Ionel Popescu. Approximation and interpolation of deep neural networks.arXiv preprint arXiv:2304.10552, 2023
-
[14]
Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
George Cybenko. Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
1989
-
[15]
Non- linear approximation and (deep) ReLU networks.Constructive Approximation, 55(1):127–172, 2022
Ingrid Daubechies, Ronald DeV ore, Simon Foucart, Boris Hanin, and Guergana Petrova. Non- linear approximation and (deep) ReLU networks.Constructive Approximation, 55(1):127–172, 2022
2022
-
[16]
Sparse low-rank adaptation of pre-trained language models
Ning Ding, Xingtai Lv, Qiaosen Wang, Yulin Chen, Bowen Zhou, Zhiyuan Liu, and Maosong Sun. Sparse low-rank adaptation of pre-trained language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 4133–4145, 2023. 10
2023
-
[17]
Deep neural network approximation theory.IEEE Transactions on Information Theory, 67(5):2581–2623, 2021
Dennis Elbrächter, Dmytro Perekrestenko, Philipp Grohs, and Helmut Bölcskei. Deep neural network approximation theory.IEEE Transactions on Information Theory, 67(5):2581–2623, 2021
2021
-
[18]
The power of depth for feedforward neural networks
Ronen Eldan and Ohad Shamir. The power of depth for feedforward neural networks. In Conference on Learning Theory, pages 907–940. PMLR, 2016
2016
-
[19]
The expressive power of tuning only the normalization layers.arXiv preprint arXiv:2302.07937, 2023
Angeliki Giannou, Shashank Rajput, and Dimitris Papailiopoulos. The expressive power of tuning only the normalization layers.arXiv preprint arXiv:2302.07937, 2023
-
[20]
Implicit regularization in matrix factorization.Advances in Neural Information Processing Systems, 30, 2017
Suriya Gunasekar, Blake E Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nati Srebro. Implicit regularization in matrix factorization.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[21]
Sltrain: a sparse plus low rank approach for parameter and memory efficient pretraining.Advances in Neural Information Processing Systems, 37:118267–118295, 2024
Andi Han, Jiaxiang Li, Wei Huang, Mingyi Hong, Akiko Takeda, Pratik Jawanpuria, and Bamdev Mishra. Sltrain: a sparse plus low rank approach for parameter and memory efficient pretraining.Advances in Neural Information Processing Systems, 37:118267–118295, 2024
2024
-
[22]
Approximating continuous functions by relu nets of minimal width.arXiv:1710.11278, 2017
Boris Hanin and Mark Sellke. Approximating continuous functions by ReLU nets of minimal width.arXiv preprint arXiv:1710.11278, 2017
-
[23]
Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
1989
-
[24]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InInternational Conference on Machine Learning, pages 2790–2799. PMLR, 2019
2019
-
[25]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[26]
Universal approximation with deep narrow networks
Patrick Kidger and Terry Lyons. Universal approximation with deep narrow networks. In Conference on learning theory, pages 2306–2327. PMLR, 2020
2020
-
[27]
Deep learning.nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.nature, 521(7553):436–444, 2015
2015
-
[28]
LoSparse: Structured compression of large language models based on low-rank and sparse approximation
Yixiao Li, Yifan Yu, Qingru Zhang, Chen Liang, Pengcheng He, Weizhu Chen, and Tuo Zhao. LoSparse: Structured compression of large language models based on low-rank and sparse approximation. InInternational Conference on Machine Learning, pages 20336–20350. PMLR, 2023
2023
-
[29]
Approximation to smooth functions by low-rank swish networks
Zimeng Li, Li Hongjun, Jingyuan Wang, and Ke Tang. Approximation to smooth functions by low-rank swish networks. InInternational Conference on Machine Learning, pages 35259– 35291. PMLR, 2025
2025
-
[30]
arXiv preprint arXiv:2303.15647 , year=
Vladislav Lialin, Vijeta Deshpande, Xiaowei Yao, and Anna Rumshisky. Scaling down to scale up: A guide to parameter-efficient fine-tuning.arXiv preprint arXiv:2303.15647, 2023
-
[31]
ReLoRA: High-rank training through low-rank updates
Vladislav Lialin, Namrata Shivagunde, Sherin Muckatira, and Anna Rumshisky. ReLoRA: High-rank training through low-rank updates. InInternational Conference on Learning Repre- sentations, 2024
2024
-
[32]
Resnet with one-neuron hidden layers is a universal approximator.Advances in Neural Information Processing Systems, 31, 2018
Hongzhou Lin and Stefanie Jegelka. Resnet with one-neuron hidden layers is a universal approximator.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[33]
The expressive power of neural networks: A view from the width.Advances in Neural Information Processing Systems, 30, 2017
Zhou Lu, Hongming Pu, Feicheng Wang, Zhiqiang Hu, and Liwei Wang. The expressive power of neural networks: A view from the width.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[34]
On the number of linear regions of deep neural networks
Guido Montúfar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the number of linear regions of deep neural networks. InAdvances in Neural Information Processing Systems, volume 27, 2014. 11
2014
-
[35]
The loss surface of deep and wide neural networks
Quynh Nguyen and Matthias Hein. The loss surface of deep and wide neural networks. In International Conference on Machine Learning, pages 2603–2612. PMLR, 2017
2017
-
[36]
Optimal approximation of piecewise smooth functions using deep ReLU neural networks.Neural Networks, 108:296–330, 2018
Philipp Petersen and Felix V oigtlaender. Optimal approximation of piecewise smooth functions using deep ReLU neural networks.Neural Networks, 108:296–330, 2018
2018
-
[37]
Approximation theory of the mlp model in neural networks.Acta numerica, 8:143–195, 1999
Allan Pinkus. Approximation theory of the mlp model in neural networks.Acta numerica, 8:143–195, 1999
1999
-
[38]
Zero: Memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimiza- tions toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[39]
Implicit regularization in deep learning may not be explainable by norms.Advances in Neural Information Processing Systems, 33:21174–21187, 2020
Noam Razin and Nadav Cohen. Implicit regularization in deep learning may not be explainable by norms.Advances in Neural Information Processing Systems, 33:21174–21187, 2020
2020
-
[40]
The power of deeper networks for expressing natural functions
David Rolnick and Max Tegmark. The power of deeper networks for expressing natural functions. InInternational Conference on Learning Representations, 2018
2018
-
[41]
Le, Geoffrey E
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[42]
ResLoRA: Identity residual mapping in low- rank adaption
Shuhua Shi, Shaohan Huang, Minghui Song, Zhoujun Li, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. ResLoRA: Identity residual mapping in low- rank adaption. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 8870–8884. Association for Computation...
2024
-
[43]
Energy and policy considerations for deep learning in NLP
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 3645–3650, 2019
2019
-
[44]
Benefits of depth in neural networks
Matus Telgarsky. Benefits of depth in neural networks. InConference on Learning Theory, pages 1517–1539. PMLR, 2016
2016
-
[45]
Wenhan Xia, Chengwei Qin, and Elad Hazan. Chain of LoRA: Efficient fine-tuning of language models via residual learning.arXiv preprint arXiv:2401.04151, 2024
-
[46]
Error bounds for approximations with deep ReLU networks.Neural networks, 94:103–114, 2017
Dmitry Yarotsky. Error bounds for approximations with deep ReLU networks.Neural networks, 94:103–114, 2017
2017
-
[47]
Sparse and low-rank matrix decomposition via alternating direction methods.Pacific Journal of Optimization, 9(1):167–180, 2013
Xiaoming Yuan and Junfeng Yang. Sparse and low-rank matrix decomposition via alternating direction methods.Pacific Journal of Optimization, 9(1):167–180, 2013
2013
-
[48]
Global optimality conditions for deep neural networks
Chulhee Yun, Suvrit Sra, and Ali Jadbabaie. Global optimality conditions for deep neural networks. InInternational Conference on Learning Representations, 2018
2018
-
[49]
The expressive power of low-rank adaptation
Yuchen Zeng and Kangwook Lee. The expressive power of low-rank adaptation. InInternational Conference on Learning Representations, 2024
2024
-
[50]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. InInternational Conference on Learning Representations, 2017
2017
-
[51]
Longteng Zhang, Sen Wu, Shuai Hou, Zhengyu Qing, Zhuo Zheng, Danning Ke, Qihong Lin, Qiang Wang, Shaohuai Shi, and Xiaowen Chu. Salr: Sparsity-aware low-rank representation for efficient fine-tuning of large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 40(33):28337–28345, 2026
2026
-
[52]
A unified framework for nonconvex low-rank plus sparse matrix recovery
Xiao Zhang, Lingxiao Wang, and Quanquan Gu. A unified framework for nonconvex low-rank plus sparse matrix recovery. InInternational Conference on Artificial Intelligence and Statistics, pages 1097–1107. PMLR, 2018. 12 A Background Implicit Regularization vs. Explicit Rank Constraints.A parallel line of literature has studied the implicit regularization of...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.