Recognition: unknown
On the Blessing of Pre-training in Weak-to-Strong Generalization
Pith reviewed 2026-05-08 14:55 UTC · model grok-4.3
The pith
Pre-training supplies the geometric warm start that makes weak-to-strong generalization possible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
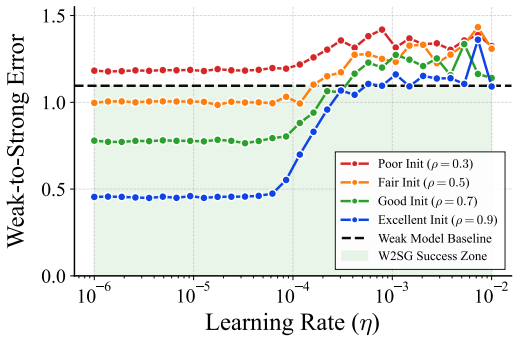
We prove that W2SG is achievable when pre-training provides a geometric warm start that places the model within an 'effective region' characterized by a perturbed strong-convexity geometry. Within this region, we derive a rigorous generalization bound that naturally captures the optimization dynamics: an initial performance improvement followed by a saturation bottleneck dictated by the weak supervisor's bias.
What carries the argument
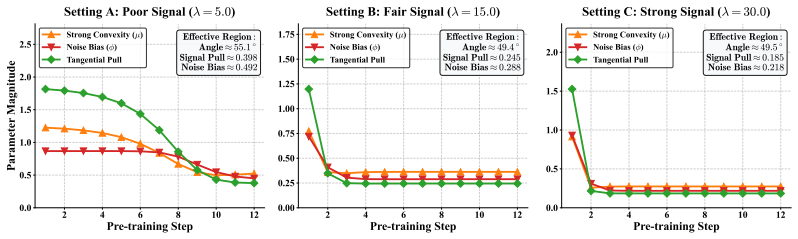
The effective region of perturbed strong-convexity geometry reached by spectral initialization from pre-training, inside the single-index model with spiked Gaussian data.
If this is right
- Random initialization alone cannot produce weak-to-strong generalization; the geometric warm start is required.
- Performance improves early in fine-tuning but is ultimately capped by the bias of the weak supervisor.
- The emergence of the capability is a phase transition that tracks the amount of pre-training rather than model scale alone.
- Massive evaluations of intermediate LLM checkpoints confirm the transition occurs in real models.
Where Pith is reading between the lines
- Further pre-training could raise the saturation ceiling if the weak supervisor's bias is also reduced.
- The same geometric mechanism may govern why certain alignment methods succeed only on well-pre-trained bases.
- Testing whether analogous phase transitions appear under other supervision regimes would clarify the generality of the result.
Load-bearing premise
Pre-training can be modeled as a spectral initialization step inside a high-dimensional single-index model that uses spiked Gaussian data.
What would settle it
A controlled experiment in which a randomly initialized model achieves generalization performance comparable to its pre-trained counterpart, or the absence of any phase-transition jump in weak-to-strong performance across a dense sequence of pre-training checkpoints.
Figures












read the original abstract
The paradigm of Weak-to-Strong Generalization (W2SG) suggests that a pre-trained strong model can surpass its weak supervisor, yet the decisive role of pre-training remains theoretically and empirically under-explored. In this work, we identify pre-training as the essential prerequisite for the emergence of W2SG. Theoretically, we formalize the W2SG problem within a high-dimensional single-index model framework using spiked Gaussian data, modeling pre-training as a spectral initialization step. Building upon prior impossibility results regarding the failure of learning under random initialization, we prove that W2SG is achievable when pre-training provides a geometric warm start that places the model within an "effective region" characterized by a perturbed strong-convexity geometry. Within this region, we derive a rigorous generalization bound that naturally captures the optimization dynamics: an initial performance improvement followed by a saturation bottleneck dictated by the weak supervisor's bias. Empirically, we first validate all our assumptions and theoretical insights through controlled synthetic simulations. Finally, through a massive-scale evaluation of hundreds of intermediate pre-training checkpoints from large language models, we demonstrate that W2SG is not an innate capability but emerges via a phase transition tightly coupled with the progression of pre-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pre-training is the essential prerequisite for weak-to-strong generalization (W2SG). It formalizes the problem in a high-dimensional single-index model with spiked Gaussian data, modeling pre-training as spectral initialization that supplies a geometric warm-start into an 'effective region' of perturbed strong-convexity. Within this region a generalization bound is derived that captures initial performance gains followed by saturation due to the weak supervisor's bias. Assumptions are validated in synthetic simulations, and a phase transition in W2SG performance is demonstrated across hundreds of intermediate checkpoints from large language models.
Significance. If the result holds, the work supplies a rigorous theoretical account of why pre-training enables surpassing weak supervisors, including explicit bounds on optimization dynamics inside a stylized model, plus large-scale empirical evidence of a pre-training-dependent phase transition. The proofs and controlled simulations are strengths that ground the modeling choices.
major comments (2)
- [§3] §3 (theoretical derivation): The generalization bound is obtained only after restricting to the perturbed-strong-convexity region that spectral initialization is assumed to reach; the result is therefore conditional on the single-index spiked-Gaussian modeling choices rather than reducing directly to properties of the target data or the weak supervisor alone.
- [Empirical LLM section] Empirical LLM section: The observed phase transition across checkpoints is presented as evidence that W2SG emerges via pre-training, yet no diagnostic (local curvature, alignment with the weak supervisor direction, or effective strong-convexity constant) is reported to verify that any checkpoint has entered the 'effective region' defined in the theory. Without this link the theoretical guarantee does not transfer to the LLM phenomenon.
minor comments (1)
- [§2-3] The definition of the 'effective region' and the precise statement of the perturbed strong-convexity assumption should be stated explicitly with all parameters before the bound is derived, to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the scope of our theoretical results and strengthening the empirical-theory link where feasible.
read point-by-point responses
-
Referee: [§3] §3 (theoretical derivation): The generalization bound is obtained only after restricting to the perturbed-strong-convexity region that spectral initialization is assumed to reach; the result is therefore conditional on the single-index spiked-Gaussian modeling choices rather than reducing directly to properties of the target data or the weak supervisor alone.
Authors: We acknowledge that the generalization bound is derived conditionally on the model reaching the perturbed-strong-convexity region via spectral initialization in the single-index spiked-Gaussian setting. This is an intentional modeling choice that permits a rigorous derivation by leveraging prior impossibility results for random initialization and explicitly characterizing pre-training as a geometric warm-start. The analysis does not purport to hold unconditionally for arbitrary data distributions or supervisors; instead, it isolates the mechanism by which pre-training enables W2SG within a tractable framework. We will revise the manuscript to more explicitly discuss the stylized nature of the model and its role in providing insight rather than claiming full generality. revision: partial
-
Referee: [Empirical LLM section] Empirical LLM section: The observed phase transition across checkpoints is presented as evidence that W2SG emerges via pre-training, yet no diagnostic (local curvature, alignment with the weak supervisor direction, or effective strong-convexity constant) is reported to verify that any checkpoint has entered the 'effective region' defined in the theory. Without this link the theoretical guarantee does not transfer to the LLM phenomenon.
Authors: We agree that additional diagnostics would strengthen the bridge between theory and the LLM experiments. Direct computation of local curvature or the effective strong-convexity constant is computationally prohibitive at LLM scale. However, we can and will add analysis of the alignment between model parameters at successive checkpoints and the weak supervisor direction, which our theory identifies as a key indicator of entry into the effective region. We will include this in the revised empirical section along with discussion of its relation to the observed phase transition. revision: yes
Circularity Check
No circularity: theory derives consequences inside explicitly stated single-index model
full rationale
The paper states its modeling choices upfront (single-index spiked-Gaussian framework, pre-training as spectral initialization) and derives the generalization bound as a consequence of entering the perturbed-strong-convexity region under those assumptions. This is a standard conditional theoretical result rather than a self-definitional loop or fitted parameter renamed as prediction. No load-bearing self-citation, ansatz smuggling, or renaming of known results is present in the provided text. The empirical sections (synthetic validation and LLM checkpoint evaluation) are presented separately and do not feed back into the derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The learning problem can be modeled as a high-dimensional single-index model with spiked Gaussian data
- domain assumption Pre-training corresponds to a spectral initialization that supplies a geometric warm start
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[2]
Forty-first International Conference on Machine Learning , year=
On the Origins of Linear Representations in Large Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[3]
The Twelfth International Conference on Learning Representations , year=
Language Models Represent Space and Time , author=. The Twelfth International Conference on Learning Representations , year=
-
[4]
First Conference on Language Modeling , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. First Conference on Language Modeling , year=
-
[5]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review arXiv
-
[6]
Steering Language Models With Activation Engineering
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review arXiv
-
[7]
Preprint , year=
OLMo: Accelerating the Science of Language Models , author=. Preprint , year=
-
[8]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[9]
Forty-first International Conference on Machine Learning , year=
Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision , author=. Forty-first International Conference on Machine Learning , year=
-
[10]
2016 , volume =
Foundations and Trends® in Optimization , title =. 2016 , volume =
2016
-
[11]
Entropy , volume=
The information geometry of Bregman divergences and some applications in multi-expert reasoning , author=. Entropy , volume=
-
[12]
The annals of probability , pages=
I-divergence geometry of probability distributions and minimization problems , author=. The annals of probability , pages=. 1975 , publisher=
1975
-
[13]
Universal Language Model Fine-tuning for Text Classification
Howard, Jeremy and Ruder, Sebastian. Universal Language Model Fine-tuning for Text Classification. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018
2018
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review arXiv
-
[15]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review arXiv
-
[16]
International Conference on Learning Representations , year=
Fine-tuning can distort pretrained features and underperform out-of-distribution , author=. International Conference on Learning Representations , year=
-
[17]
1997 , publisher=
Parallel optimization: Theory, algorithms, and applications , author=. 1997 , publisher=
1997
-
[18]
2013 , publisher=
Probability in Banach Spaces: isoperimetry and processes , author=. 2013 , publisher=
2013
-
[19]
Journal of Machine Learning Research , volume=
Rademacher and Gaussian complexities: Risk bounds and structural results , author=. Journal of Machine Learning Research , volume=
-
[20]
Advances in neural information processing systems , volume=
On the theory of transfer learning: The importance of task diversity , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in neural information processing systems , year=
Quantifying the Gain in Weak-to-Strong Generalization , author=. Advances in neural information processing systems , year=
-
[22]
2004 , publisher=
Convex optimization , author=. 2004 , publisher=
2004
-
[23]
IEEE transactions on pattern analysis and machine intelligence , volume=
Towards safe weakly supervised learning , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2019 , publisher=
2019
-
[24]
IV , author=
Asymptotic evaluation of certain Markov process expectations for large time. IV , author=. Communications on pure and applied mathematics , volume=
-
[25]
International Conference on Learning Representations , year=
Information-theoretic analysis of unsupervised domain adaptation , author=. International Conference on Learning Representations , year=
-
[26]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[27]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review arXiv
-
[28]
2023 , url =
OpenAI , title =. 2023 , url =
2023
-
[29]
The Thirteenth International Conference on Learning Representations , year=
Super (ficial)-alignment: Strong models may deceive weak models in weak-to-strong generalization , author=. The Thirteenth International Conference on Learning Representations , year=
-
[30]
arXiv preprint arXiv:2410.04571 , year=
EnsemW2S: Can an Ensemble of LLMs be Leveraged to Obtain a Stronger LLM? , author=. arXiv preprint arXiv:2410.04571 , year=
-
[31]
arXiv preprint arXiv:2406.19032 , year=
Improving weak-to-strong generalization with reliability-aware alignment , author=. arXiv preprint arXiv:2406.19032 , year=
-
[32]
Forty-second International Conference on Machine Learning , year=
Discrepancies are Virtue: Weak-to-Strong Generalization through Lens of Intrinsic Dimension , author=. Forty-second International Conference on Machine Learning , year=
-
[33]
High-dimensional Learning Dynamics 2025 , year=
From Linear to Nonlinear: Provable Weak-to-Strong Generalization through Feature Learning , author=. High-dimensional Learning Dynamics 2025 , year=
2025
-
[34]
arXiv preprint arXiv:2505.18346 , year=
On the Mechanisms of Weak-to-Strong Generalization: A Theoretical Perspective , author=. arXiv preprint arXiv:2505.18346 , year=
-
[35]
Great Models Think Alike and this Undermines
Shashwat Goel and Joschka Str. Great Models Think Alike and this Undermines. Forty-second International Conference on Machine Learning , year=
-
[36]
Second Conference on Language Modeling , year=
Limitations of refinement methods for weak to strong generalization , author=. Second Conference on Language Modeling , year=
-
[37]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Theoretical Analysis of Weak-to-Strong Generalization , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[38]
arXiv preprint arXiv:2410.12621 , year=
Weak-to-Strong Generalization beyond Accuracy: a Pilot Study in Safety, Toxicity, and Legal Reasoning , author=. arXiv preprint arXiv:2410.12621 , year=
-
[39]
The Thirteenth International Conference on Learning Representations , year=
Provable weak-to-strong generalization via benign overfitting , author=. The Thirteenth International Conference on Learning Representations , year=
-
[40]
arXiv preprint arXiv:2405.16236 , year=
A statistical framework for weak-to-strong generalization , author=. arXiv preprint arXiv:2405.16236 , year=
-
[41]
Advances in neural information processing systems , volume=
Information-theoretic analysis of generalization capability of learning algorithms , author=. Advances in neural information processing systems , volume=
-
[42]
IEEE Journal on Selected Areas in Information Theory , volume=
Tightening mutual information-based bounds on generalization error , author=. IEEE Journal on Selected Areas in Information Theory , volume=. 2020 , publisher=
2020
-
[43]
2018 IEEE International Symposium on Information Theory , pages=
Generalization error bounds for noisy, iterative algorithms , author=. 2018 IEEE International Symposium on Information Theory , pages=
2018
-
[44]
Advances in Neural Information Processing Systems , volume=
Generalization bounds for meta-learning: An information-theoretic analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International Conference on Artificial Intelligence and Statistics , pages=
An information-theoretical approach to semi-supervised learning under covariate-shift , author=. International Conference on Artificial Intelligence and Statistics , pages=
-
[46]
arXiv preprint arXiv:2309.04381 , year=
Generalization bounds: Perspectives from information theory and PAC-Bayes , author=. arXiv preprint arXiv:2309.04381 , year=
-
[47]
Journal of Machine Learning Research , year =
Huayi Tang and Yong Liu , title =. Journal of Machine Learning Research , year =
-
[48]
Artificial Intelligence and Statistics , pages=
Controlling bias in adaptive data analysis using information theory , author=. Artificial Intelligence and Statistics , pages=
-
[49]
International Conference on Machine Learning , year=
Tighter information-theoretic generalization bounds from supersamples , author=. International Conference on Machine Learning , year=
-
[50]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review arXiv
-
[51]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review arXiv 1909
-
[52]
Advances in neural information processing systems , volume=
Reverse kl-divergence training of prior networks: Improved uncertainty and adversarial robustness , author=. Advances in neural information processing systems , volume=
-
[53]
arXiv preprint arXiv:2410.12456 , year=
Training Neural Samplers with Reverse Diffusive KL Divergence , author=. arXiv preprint arXiv:2410.12456 , year=
-
[54]
arXiv preprint arXiv:2410.22081 , year=
Choosy Babies Need One Coach: Inducing Mode-Seeking Behavior in BabyLlama with Reverse KL Divergence , author=. arXiv preprint arXiv:2410.22081 , year=
-
[55]
International Conference on Learning Representations , year=
Beyond reverse kl: Generalizing direct preference optimization with diverse divergence constraints , author=. International Conference on Learning Representations , year=
-
[56]
International Conference on Machine Learning , pages=
On calibration of modern neural networks , author=. International Conference on Machine Learning , pages=
-
[57]
Proceedings of the AAAI conference on artificial intelligence , pages=
Obtaining well calibrated probabilities using bayesian binning , author=. Proceedings of the AAAI conference on artificial intelligence , pages=
-
[58]
Advances in neural information processing systems , volume=
Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration , author=. Advances in neural information processing systems , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Verified uncertainty calibration , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
International Conference on Artificial Intelligence and Statistics , pages=
Mitigating bias in calibration error estimation , author=. International Conference on Artificial Intelligence and Statistics , pages=
-
[61]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review arXiv
-
[62]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[63]
International Conference on Learning Representations , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations , year=
-
[64]
Advances in neural information processing systems , volume=
On fairness and calibration , author=. Advances in neural information processing systems , volume=
-
[65]
International Conference on Machine Learning , pages=
The implicit fairness criterion of unconstrained learning , author=. International Conference on Machine Learning , pages=
-
[66]
On the Calibration of Large Language Models and Alignment
Zhu, Chiwei and Xu, Benfeng and Wang, Quan and Zhang, Yongdong and Mao, Zhendong. On the Calibration of Large Language Models and Alignment. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023
2023
-
[67]
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback
Tian, Katherine and Mitchell, Eric and Zhou, Allan and Sharma, Archit and Rafailov, Rafael and Yao, Huaxiu and Finn, Chelsea and Manning, Christopher. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
2023
-
[68]
1999 , publisher=
Elements of information theory , author=. 1999 , publisher=
1999
-
[69]
arXiv preprint arXiv:2003.07892 , year=
Calibration of pre-trained transformers , author=. arXiv preprint arXiv:2003.07892 , year=
-
[70]
Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021) , pages=
An overview of uncertainty calibration for text classification and the role of distillation , author=. Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021) , pages=
2021
-
[71]
arXiv preprint arXiv:2210.15452 , year=
Exploring predictive uncertainty and calibration in NLP: A study on the impact of method & data scarcity , author=. arXiv preprint arXiv:2210.15452 , year=
-
[72]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
A Survey of Confidence Estimation and Calibration in Large Language Models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[73]
IEEE transactions on medical imaging , volume=
Confidence calibration and predictive uncertainty estimation for deep medical image segmentation , author=. IEEE transactions on medical imaging , volume=
-
[74]
International conference on machine learning , pages=
Accurate uncertainties for deep learning using calibrated regression , author=. International conference on machine learning , pages=
-
[75]
The European Conference on Computer Vision , pages=
Weakly supervised learning with side information for noisy labeled images , author=. The European Conference on Computer Vision , pages=
-
[76]
arXiv preprint arXiv:2503.07660 , year=
Research on Superalignment Should Advance Now with Parallel Optimization of Competence and Conformity , author=. arXiv preprint arXiv:2503.07660 , year=
-
[77]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Training object class detectors with click supervision , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[78]
The VLDB Journal , volume=
Snorkel: rapid training data creation with weak supervision , author=. The VLDB Journal , volume=
-
[79]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Is object localization for free?-weakly-supervised learning with convolutional neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[80]
Distilling Rule-based Knowledge into Large Language Models
Yang, Wenkai and Lin, Yankai and Zhou, Jie and Wen, Ji-Rong. Distilling Rule-based Knowledge into Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.