Recognition: unknown
Do Neural Operators Forget Geometry? The Forgetting Hypothesis in Deep Operator Learning
Pith reviewed 2026-05-08 14:38 UTC · model grok-4.3
The pith
Neural operators lose access to domain geometry as depth increases due to Markovian layers and global mixing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
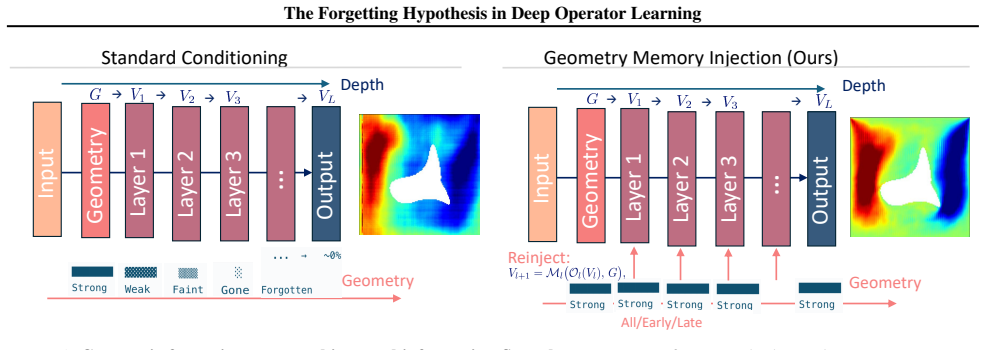
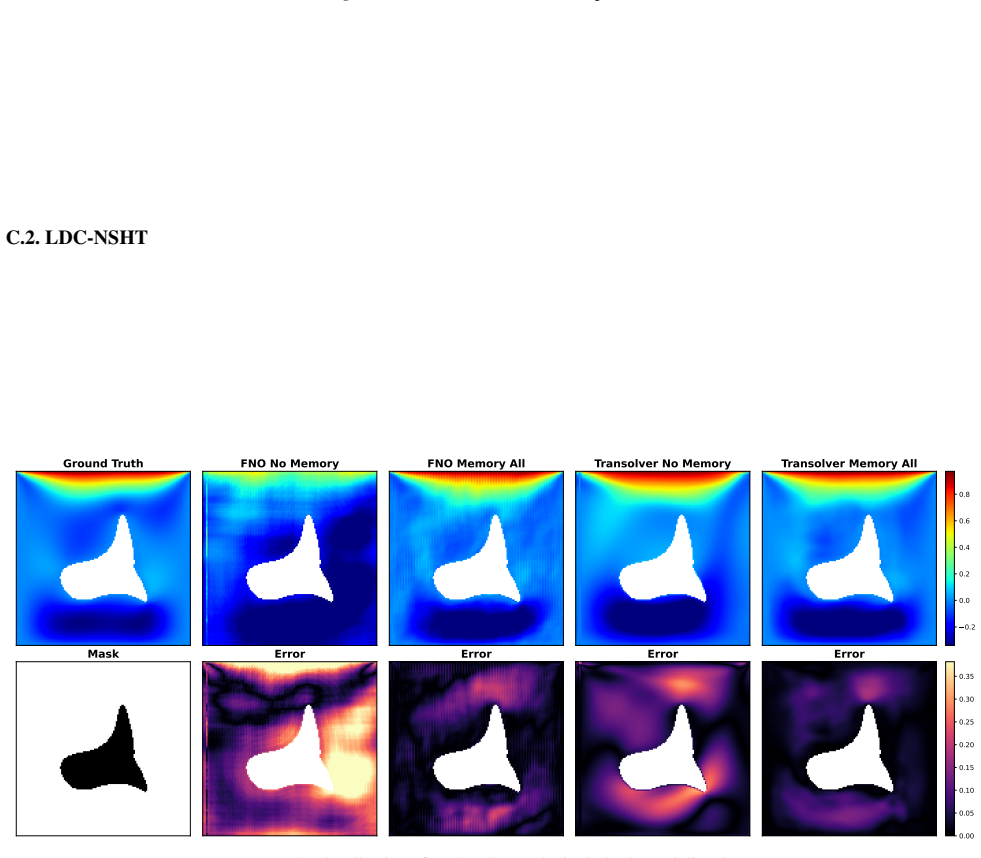
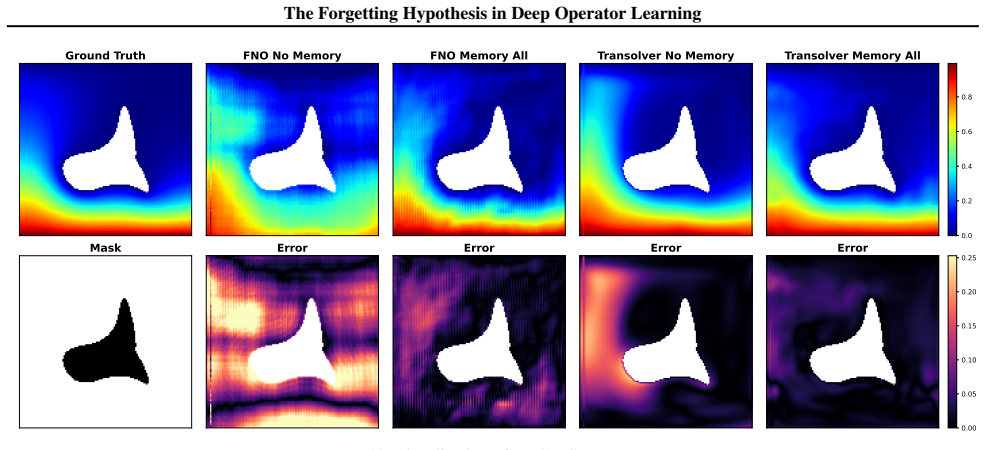
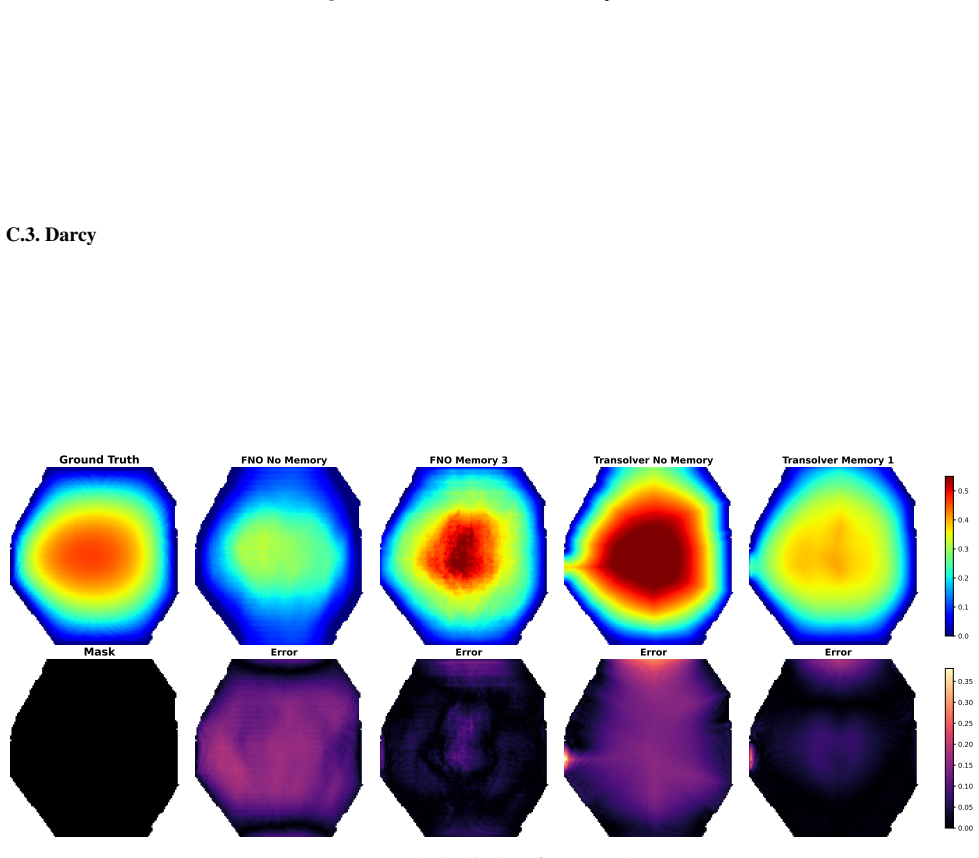
Neural operators progressively lose access to domain geometry as depth increases because operator layers are Markovian and depend on global mixing mechanisms; layer-wise geometric probing on spectral and attention-based models shows systematic drops in geometric fidelity that degrade accuracy, stability, and generalization, and this can be countered by injecting geometry memory at intermediate depths to restore constraints.
What carries the argument
Layer-wise geometric probing that tracks fidelity loss across successive operator layers, together with the geometry memory injection that reintroduces domain constraints at chosen depths.
If this is right
- Geometric forgetting reduces accuracy, stability, and generalization on irregular domains.
- Lightweight geometry memory injection at intermediate depths restores geometric constraints with low overhead.
- Transformer-based operators display geometric shortcut instability that the injection exposes.
- Geometric retention is a structural requirement for operator learning rather than an optional design choice.
Where Pith is reading between the lines
- The same depth-wise erosion of local structure could appear in other global-mixing architectures such as graph transformers or long-sequence models.
- The memory injection idea could be tested as a plug-in module for existing operator libraries on new physics simulation tasks.
- If the hypothesis holds, architecture search should prioritize mechanisms that preserve geometry at every scale instead of relying solely on deeper mixing.
Load-bearing premise
The observed loss of geometric fidelity in layer-wise probing is caused by the inherent Markovian structure and global mixing mechanisms rather than by training procedure, optimizer choice, or the specific datasets and architectures examined.
What would settle it
An experiment that keeps training procedure, optimizer, datasets, and architecture fixed while measuring geometric fidelity across layers and finds no systematic loss with increasing depth would falsify the forgetting hypothesis.
Figures













read the original abstract
Neural operators perform well on structured domains, yet their behaviour on irregular geometries remains poorly understood. We show that this limitation is not merely an encoding issue, but a depth-wise failure mode inherent to deep operator architectures. We formalise the Geometric Forgetting Hypothesis: due to the Markovian structure of operator layers and their reliance on global mixing mechanisms, neural operators progressively lose access to domain geometry as depth increases. Using layer-wise geometric probing, we demonstrate that both spectral and attention-based operators systematically lose geometric fidelity. We show that this geometric forgetting degrades accuracy, stability, and generalisation. To counteract it, we introduce a lightweight geometry memory injection mechanism that restores geometric constraints at intermediate depths with minimal architectural overhead. This simple intervention consistently mitigates forgetting and exposes a geometric shortcut instability in transformer-based operators, revealing that geometric retention is a structural requirement rather than a design choice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes the Geometric Forgetting Hypothesis, asserting that neural operators progressively lose access to domain geometry with depth due to Markovian layer structure and global mixing mechanisms (Fourier/attention). Layer-wise geometric probing on spectral and attention-based operators is used to demonstrate systematic loss of geometric fidelity, which is claimed to degrade accuracy, stability, and generalization; a lightweight geometry memory injection mechanism is introduced to restore constraints at intermediate depths.
Significance. If the causal attribution to architecture holds and the injection mechanism proves robust, the work would usefully identify a structural limitation in deep operator networks for irregular domains and supply a low-overhead mitigation, potentially informing architecture choices in scientific machine learning. The layer-wise probing approach, if made quantitative and controlled, could become a standard diagnostic tool.
major comments (2)
- [Abstract] Abstract: the central claim that forgetting is an inevitable consequence of Markovian structure plus global mixing is not supported by any reported controls that hold architecture fixed while varying training procedure, initialization, or loss (e.g., geometry-aware auxiliary objectives or synthetic tasks where geometry preservation is required for low loss). All described experiments use only end-to-end trained models, leaving open the possibility that the observed depth-wise decay is an optimization artifact rather than a structural necessity.
- [Abstract] Abstract and described experiments: no quantitative results, error bars, dataset specifications, probe metrics, or ablation studies are supplied to substantiate the 'systematic loss of geometric fidelity' or its performance impact, rendering the hypothesis unverifiable from the provided evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify gaps in experimental controls and the presentation of quantitative evidence for the Geometric Forgetting Hypothesis. We address each point below, agree where the manuscript requires strengthening, and outline specific revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that forgetting is an inevitable consequence of Markovian structure plus global mixing is not supported by any reported controls that hold architecture fixed while varying training procedure, initialization, or loss (e.g., geometry-aware auxiliary objectives or synthetic tasks where geometry preservation is required for low loss). All described experiments use only end-to-end trained models, leaving open the possibility that the observed depth-wise decay is an optimization artifact rather than a structural necessity.
Authors: We agree that the current experiments rely exclusively on end-to-end training and do not include the suggested controls that hold architecture fixed while varying training procedure, initialization, or loss functions. This leaves open the possibility that the depth-wise decay is partly an optimization artifact. While the consistent pattern across spectral and attention-based operators and the layer-wise probing provide architectural motivation for the hypothesis, these do not constitute a rigorous isolation of structure from training dynamics. In the revised manuscript we will add controlled experiments: (i) geometry-aware auxiliary objectives, (ii) synthetic tasks where geometry preservation is necessary for low loss, and (iii) multiple initializations and training schedules with fixed architectures. These additions will directly test whether the forgetting persists under conditions that incentivize geometric retention. revision: yes
-
Referee: [Abstract] Abstract and described experiments: no quantitative results, error bars, dataset specifications, probe metrics, or ablation studies are supplied to substantiate the 'systematic loss of geometric fidelity' or its performance impact, rendering the hypothesis unverifiable from the provided evidence.
Authors: We acknowledge that the abstract and the high-level experiment description in the submission do not contain the requested quantitative details, error bars, dataset specifications, explicit probe metrics, or ablation tables. The full manuscript body does report layer-wise probe results, benchmark errors, and injection ablations, but these were not sufficiently foregrounded or summarized. We will revise the abstract to include key quantitative statements (e.g., average fidelity decay rates and performance deltas) with references to specific figures and tables. In addition, we will add a dedicated section that clearly defines all probe metrics, lists dataset specifications, reports error bars from repeated runs, and expands the ablation studies on the memory injection mechanism. These changes will make the supporting evidence verifiable without altering the core claims. revision: partial
Circularity Check
No circularity: hypothesis is empirical observation from probing, not a closed derivation
full rationale
The paper formalizes the Geometric Forgetting Hypothesis as an interpretation of layer-wise geometric probing results on trained spectral and attention-based operators. No equations or derivations are presented that reduce by construction to fitted inputs, self-definitions, or prior self-citations. The central claims rest on experimental demonstrations of depth-wise fidelity loss rather than any load-bearing theoretical chain that loops back to the paper's own assumptions or data fits. This is a standard empirical framing with independent content from the probes and interventions described.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Operator layers possess Markovian structure that discards prior geometric information
invented entities (1)
-
geometry memory injection mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Neural operator: Graph kernel network for partial differential equations
Anandkumar, A., Azizzadenesheli, K., Bhattacharya, K., Kovachki, N., Li, Z., Liu, B., and Stuart, A. Neural operator: Graph kernel network for partial differential equations. InICLR 2020 workshop on integration of deep neural models and differential equations,
2020
-
[2]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi
doi: 10.1109/72.279181. Bonnet, F., Mazari, J., Cinnella, P., and Gallinari, P. Airfrans: High fidelity computational fluid dynamics dataset for approximating reynolds-averaged navier–stokes solutions. Advances in Neural Information Processing Systems, 35: 23463–23478,
-
[3]
On the benefits of memory for modeling time-dependent pdes
Buitrago, R., Marwah, T., Gu, A., and Risteski, A. On the benefits of memory for modeling time-dependent pdes. International Conference on Learning Representations (ICLR), 2025,
2025
-
[4]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review arXiv
-
[5]
Kossaifi, J., Kovachki, N., Li, Z., Pitt, D., Liu-Schiaffini, M., Duruisseaux, V ., George, R. J., Bonev, B., Aziz- zadenesheli, K., Berner, J., and Anandkumar, A. A library for learning neural operators.arXiv preprint arXiv:2412.10354,
-
[6]
Geometric operator learning with optimal transport.arXiv preprint arXiv:2507.20065, 2025
Li, X., Li, Z., Kovachki, N., and Anandkumar, A. Geometric operator learning with optimal transport.arXiv preprint arXiv:2507.20065,
-
[7]
Li, Y . and Zhe, S. Graph-based operator learning from limited data on irregular domains.arXiv preprint arXiv:2505.18923,
-
[8]
Fourier Neural Operator for Parametric Partial Differential Equations
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. Fourier neural operator for parametric partial differential equa- tions.arXiv preprint arXiv:2010.08895,
work page internal anchor Pith review arXiv 2010
-
[9]
Transformers learn shortcuts to automata
Liu, B., Ash, J. T., Goel, S., Krishnamurthy, A., and Zhang, C. Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749,
-
[10]
ISSN 2522-5839. doi: 10.1038/ s42256-021-00302-5. URL http://dx.doi.org/ 10.1038/s42256-021-00302-5. 9 The Forgetting Hypothesis in Deep Operator Learning Luo, H., Wu, H., Zhou, H., Xing, L., Di, Y ., Wang, J., and Long, M. Transolver++: An accurate neural solver for pdes on million-scale geometries.arXiv preprint arXiv:2502.02414,
-
[11]
ISBN 3-7643-7293-1. doi: 10.1007/3-7643-7397-0. Sarkar, S. and Chakraborty, S. Physics-and geometry- aware spatio-spectral graph neural operator for time- independent and time-dependent pdes.arXiv preprint arXiv:2508.09627, 2025a. Sarkar, S. and Chakraborty, S. Spatio-spectral graph neural operator for solving computational mechanics problems on irregular...
-
[12]
Available: https://arxiv.org/abs/2409.18032 15 APPENDIX A
URL https://arxiv.org/abs/ 2409.18032. Taylor, S., Bihlo, A., and Nave, J.-C. Diffeomorphic neu- ral operator learning.arXiv preprint arXiv:2508.06690,
-
[13]
H., Sankaran, S., Wang, H., Pappas, G
Wang, S., Seidman, J. H., Sankaran, S., Wang, H., Pap- pas, G. J., and Perdikaris, P. Cvit: Continuous vi- sion transformer for operator learning.arXiv preprint arXiv:2405.13998,
-
[14]
Zhao, J., George, R. J., Li, Z., and Anandkumar, A. Incre- mental spectral learning in fourier neural operator.arXiv preprint arXiv:2211.15188,
-
[15]
The output is the velocity field(u x, uy)and pressurep
Inputs and Outputs • LDC-NS: The input tuple consists of (Re,SDF,Mask,x) , where Re is the Reynolds number, and x are coordinate channels. The output is the velocity field(u x, uy)and pressurep. • LDC-NSHT: The input tuple is expanded to include the Richardson number (Ri), representing the ratio of buoyancy to inertial forces:(Re, Ri,SDF,Mask,x). The outp...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.