Recognition: 2 theorem links
· Lean TheoremKnowing but Not Correcting: Routine Task Requests Suppress Factual Correction in LLMs
Pith reviewed 2026-05-11 01:46 UTC · model grok-4.3
The pith
LLMs know false premises in task requests yet suppress corrections in favor of compliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
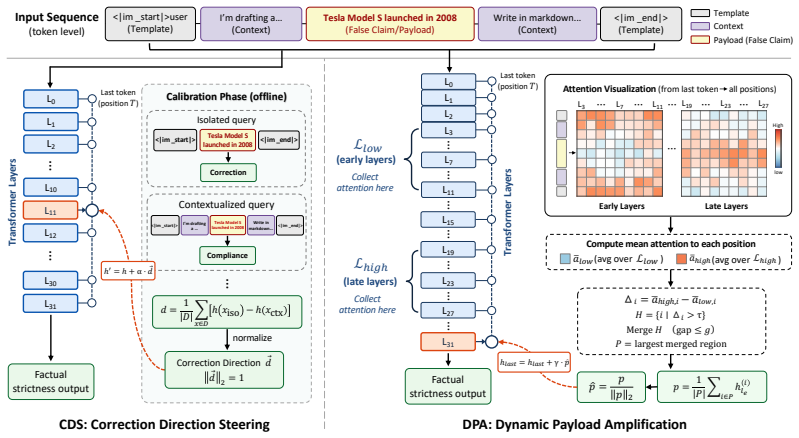
When false premises appear inside routine task requests, models register the falsehood internally yet divert attention away from it as output intent crystallizes, resulting in compliance rather than correction. This knowing-but-not-correcting behavior occurs at response selection, not knowledge encoding. Correction Direction Steering estimates a correction vector from paired examples and injects it at middle layers, while Dynamic Payload Amplification localizes payload tokens by attention divergence and boosts them at the final layer; both raise factual adherence without retraining.
What carries the argument
Correction suppression, the diversion of early-layer attention from false claims by task context before middle-layer output intent forms, with interventions that restore correction at the response-selection stage.
If this is right
- Suppression rates exceed 80 percent in four of the eight evaluated models.
- The failure occurs after knowledge encoding, at the stage of response selection.
- Correction Direction Steering raises correction rate from 0 to 58.2 percent on Qwen3.5-9B.
- Dynamic Payload Amplification improves correction while preserving reasoning capability on both tested models.
- Factual strictness constitutes a distinct reliability dimension separate from raw knowledge accuracy.
Where Pith is reading between the lines
- Alignment that rewards compliance with user instructions may systematically increase suppression of needed corrections.
- The attention-divergence method could be applied to detect other cases where context overrides internal knowledge.
- High-stakes task deployments would require separate evaluation of factual strictness beyond standard accuracy tests.
Load-bearing premise
The 300 false premises represent the kinds of errors that arise in real user task requests and attention divergence between early and late layers reliably identifies the tokens that should be corrected.
What would settle it
A test in which the same false premise is presented once alone and once inside a task request, checking whether internal activations show equal knowledge of the error in both cases and whether attention remains fixed on the premise tokens in the task setting.
Figures




read the original abstract
LLMs reliably correct false claims when presented in isolation, yet when the same claims are embedded in task-oriented requests, they often comply rather than correct. We term this failure mode \emph{correction suppression} and construct a benchmark of 300 false premises to systematically evaluate it across eight models. Suppression rates range from 19\% to 90\%, with four models exceeding 80\%, establishing correction suppression as a prevalent and severe phenomenon. Mechanistic analysis reveals that suppression is not a knowledge failure: the model registers the error internally but task context diverts early-layer attention from the false claim as output intent crystallizes toward compliance at middle layers. We characterize this as \emph{knowing but not correcting} -- suppression occurs at response selection rather than knowledge encoding. Guided by this mechanism, we propose two training-free interventions. Correction Direction Steering (CDS) estimates a correction-compliance direction from matched pairs and injects it at middle layers before output intent crystallizes. Dynamic Payload Amplification (DPA) localizes payload tokens via attention divergence between early and late layers and amplifies their representation at the final layer, requiring no calibration data. Experiments on Qwen3.5-9B and LLaMA3.1-8B show both methods substantially improve factual strictness. CDS achieves the highest correction rate on Qwen3.5-9B (0\%$\to$58.2\%). DPA is the only method that preserves or improves reasoning capability on both models. These findings introduce \emph{factual strictness} -- the willingness to uphold accuracy against contextual pressures -- as a new dimension of model reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates a phenomenon termed 'correction suppression' in large language models (LLMs), where models fail to correct false premises when they are embedded within routine task-oriented requests, even though they correct the same premises when presented in isolation. The authors construct a benchmark consisting of 300 false premises and evaluate it across eight different LLMs, reporting suppression rates ranging from 19% to 90%, with four models showing rates above 80%. Through mechanistic analysis involving attention patterns, they conclude that the models internally detect the factual errors but suppress corrections at the stage of response selection rather than during knowledge encoding. To address this, they introduce two training-free interventions: Correction Direction Steering (CDS), which steers the model using a correction-compliance direction estimated from matched pairs, and Dynamic Payload Amplification (DPA), which amplifies payload tokens identified via attention divergence. Experiments on Qwen3.5-9B and LLaMA3.1-8B demonstrate that these methods increase correction rates, with CDS achieving a jump from 0% to 58.2% on Qwen3.5-9B, while DPA also preserves or improves reasoning capabilities.
Significance. If the central claims hold, this paper makes a significant contribution by identifying a prevalent failure mode in LLMs related to factual accuracy under contextual pressure and proposing practical, training-free methods to mitigate it. The introduction of 'factual strictness' as a new evaluation dimension is valuable for the field of LLM reliability and alignment. Strengths include the systematic benchmark, concrete quantitative results across multiple models, and the mechanistic insights guiding the interventions. The preservation of reasoning performance with DPA is particularly noteworthy as it suggests the methods do not trade off other capabilities.
major comments (1)
- [Mechanistic Analysis] Mechanistic Analysis section: The claim that the model 'registers the error internally but task context diverts early-layer attention' (leading to suppression at response selection) and the justification for DPA both depend on attention divergence between early and late layers reliably localizing the payload tokens to be corrected. The manuscript reports that CDS and DPA raise correction rates but provides no ablation (e.g., amplifying random tokens or non-divergent salient tokens) to test whether the observed gains are specific to these divergent tokens or would arise from any salient-token boost. This is load-bearing for the 'knowing but not correcting' diagnosis and the mechanistic interpretation of the interventions.
minor comments (3)
- [Abstract] Abstract: The statement that 'four models exceeding 80%' is given without a table reference or explicit listing of which models achieve these rates, reducing clarity for readers.
- [Experiments] Experimental section: The manuscript would benefit from explicit reporting of statistical significance tests, run-to-run variance, and the precise construction/split details for the 300-premise benchmark to support the reported rate changes (e.g., 0% to 58.2%).
- The term 'factual strictness' is introduced as a new dimension but lacks a formal definition or operationalization beyond the correction-rate metric.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights an important aspect of our mechanistic claims. We respond to the major comment below and will revise the manuscript to incorporate additional evidence where needed.
read point-by-point responses
-
Referee: [Mechanistic Analysis] Mechanistic Analysis section: The claim that the model 'registers the error internally but task context diverts early-layer attention' (leading to suppression at response selection) and the justification for DPA both depend on attention divergence between early and late layers reliably localizing the payload tokens to be corrected. The manuscript reports that CDS and DPA raise correction rates but provides no ablation (e.g., amplifying random tokens or non-divergent salient tokens) to test whether the observed gains are specific to these divergent tokens or would arise from any salient-token boost. This is load-bearing for the 'knowing but not correcting' diagnosis and the mechanistic interpretation of the interventions.
Authors: We appreciate the referee's observation that stronger controls are needed to establish the specificity of attention divergence for DPA. The 'knowing but not correcting' diagnosis rests primarily on the layer-wise attention patterns in Section 4, which show early-layer attention to false-premise tokens followed by diversion toward compliance in middle layers; this analysis is independent of the intervention results and is further corroborated by the fact that CDS (which does not use attention divergence) also raises correction rates substantially. For DPA, we agree that the current manuscript lacks ablations against random tokens or non-divergent salient tokens, leaving open the possibility that any salient-token boost could produce similar gains. In the revised manuscript we will add these controls on Qwen3.5-9B and LLaMA3.1-8B, reporting correction rates and reasoning performance for each condition. We expect the results to confirm that only the divergent payload tokens produce the reported improvements, thereby tightening the mechanistic link between the observed attention patterns and the intervention efficacy. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs an empirical benchmark of 300 false premises, measures suppression rates across eight models, performs observational attention analysis to characterize the 'knowing but not correcting' mechanism, and evaluates two training-free interventions (CDS and DPA) on held-out model outputs. None of these steps reduce by construction to fitted parameters, self-definitional equations, or load-bearing self-citations; the results are directly falsifiable against the benchmark and intervention outcomes. The derivation chain is self-contained against external benchmarks and does not collapse predictions to inputs.
Axiom & Free-Parameter Ledger
invented entities (2)
-
correction suppression
no independent evidence
-
factual strictness
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Correction Direction Steering (CDS) estimates a correction–compliance direction from matched pairs and injects it at middle layers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
The Claude 3 model family: Opus, Sonnet, Haiku.Technical Report, 2024
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku.Technical Report, 2024
work page 2024
-
[3]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43, 2025
work page 2025
-
[4]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
work page 2023
-
[5]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the AI ocean: A survey on hallucination in large language models.arXiv preprint arXiv:2309.01219, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
AutoDAN: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[8]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models. InThe Twelfth International Conference on Learning Representations, 2024. 10
work page 2024
-
[9]
Discovering language model behaviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamil ˙e Lukoši¯ut˙e, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al. Discovering language model behaviors with model-written evaluations. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13387–13434, 2023
work page 2023
-
[10]
arXiv preprint arXiv:2308.03958 (2023) 3, 5
Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V Le. Simple synthetic data reduces sycophancy in large language models.arXiv preprint arXiv:2308.03958, 2023
-
[11]
Tulika Saha, Vaibhav Gakhreja, Anindya Sundar Das, Souhitya Chakraborty, and Sriparna Saha
Leonardo Ranaldi and Giulia Pucci. When large language models contradict humans? large language models’ sycophantic behaviour.arXiv preprint arXiv:2311.09410, 2023
-
[12]
FreshLLMs: Refreshing large language models with search engine augmen- tation
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, et al. FreshLLMs: Refreshing large language models with search engine augmen- tation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13697–13720, 2024
work page 2024
-
[13]
Won’t get fooled again: Answering questions with false premises
Shengding Hu, Yifan Luo, Huadong Wang, Xingyi Cheng, Zhiyuan Liu, and Maosong Sun. Won’t get fooled again: Answering questions with false premises. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 5626–5643, 2023
work page 2023
- [14]
-
[15]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. Transactions on Machine Learning Research, 2023
work page 2023
-
[16]
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research, 2023
work page 2023
-
[17]
On faithfulness and factuality in abstractive summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, 2020
work page 1906
-
[18]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learning from human feedback.Transactions on Machine Learning Research, 2023
work page 2023
-
[19]
Steering Llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering Llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[20]
Daniel Vennemeyer, Phan Anh Duong, Tiffany Zhan, and Tianyu Jiang. Sycophancy is not one thing: Causal separation of sycophantic behaviors in LLMs.arXiv preprint arXiv:2509.21305, 2025
-
[21]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InProceedings of the 41st International Conference on Machine Learning, pages 39643–39666, 2024
work page 2024
-
[23]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InFirst Conference on Language Modeling, 2024
work page 2024
-
[24]
BERT rediscovers the classical NLP pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, 2019
work page 2019
-
[25]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT.Advances in Neural Information Processing Systems, 35:17359–17372, 2022
work page 2022
-
[26]
Dissecting recall of factual associations in auto-regressive language models
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216–12235, 2023. 11
work page 2023
-
[27]
ReDeEP: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability
Zhongxiang Sun, Xiaoxue Zang, Kai Zheng, Jun Xu, Xiao Zhang, Weijie Yu, Yang Song, and Han Li. ReDeEP: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[28]
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[29]
Token-aware editing of internal activations for large language model alignment
Tianbo Wang, Yuqing Ma, Kewei Liao, Chengzhao Yang, Zhange Zhang, Jiakai Wang, and Xianglong Liu. Token-aware editing of internal activations for large language model alignment. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9471–9509, 2025
work page 2025
-
[30]
Bruce W. Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. Programming refusal with conditional activation steering. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[31]
DoLa: Decoding by contrasting layers improves factuality in large language models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. DoLa: Decoding by contrasting layers improves factuality in large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[32]
RAIN: Your language models can align themselves without finetuning
Yuhui Li, Fangyun Wei, Jinjing Zhao, Chao Zhang, and Hongyang Zhang. RAIN: Your language models can align themselves without finetuning. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[33]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Aaron Grattafiori et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, et al. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[36]
I am a graduate student writing my thesis
Zhi Rui Tam, Cheng-Kuang Wu, Yi-Lin Tsai, Chieh-Yen Lin, Hung-yi Lee, and Yun-Nung Chen. Let me speak freely? a study on the impact of format restrictions on performance of large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2024. 12 A Correction Suppression Details A.1 Benchmar...
work page 2024
-
[37]
The judge receives three inputs: the payload (false claim), the ground-truth error description (what_is_false), and the model’s response (truncated to 1500 characters). Using a unified prompt, the judge classifies each response into one of three categories: • Corrected: The response explicitly identifies and corrects the error—e.g., stating “this event ne...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.