Recognition: unknown
Requests of a Feather Must Flock Together: Batch Size vs. Prefix Homogeneity in LLM Inference
Pith reviewed 2026-05-08 14:02 UTC · model grok-4.3
The pith
Smaller prefix-homogeneous batches can deliver higher decode throughput than larger heterogeneous batches in LLM inference when requests share prefixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Feather shows that an RL-driven scheduler can learn to form smaller, prefix-homogeneous batches that outperform larger heterogeneous batches on decode throughput. The scheduler is enabled by a Chunked Hash Tree that performs fast prefix detection and request selection without the CPU overhead of radix-tree traversals used in prior systems. When integrated into existing engines the approach reduces overall KV cache accesses and exceeds the gains available from prefix-aware attention kernels alone.
What carries the argument
The reinforcement learning policy that selects batch composition by trading off size against prefix homogeneity, supported by the Chunked Hash Tree for low-overhead prefix detection and request grouping.
If this is right
- End-to-end throughput rises 2-10x over existing schedulers on prefix-sharing workloads.
- Performance stays comparable to current schedulers when workloads lack sufficient prefix sharing.
- Total KV cache accesses drop enough to beat the speedups from prefix-aware attention kernels alone.
- The same scheduler integrates into vLLM and SGLang without requiring new hardware or model changes.
Where Pith is reading between the lines
- The same locality principle could guide batch formation in other memory-bound serving systems that handle repeated data structures.
- Future hardware might add direct support for homogeneous batch execution to amplify the locality gains.
- Extending the RL state to include runtime metrics such as current memory pressure could further improve the policy without changing its core logic.
- Efficient prefix detection appears more critical to scheduler performance than the absolute size of the batch.
Load-bearing premise
The reinforcement learning policy learns a tradeoff between batch size and prefix homogeneity that generalizes across workloads, hardware, and models, while the Chunked Hash Tree detects shared prefixes accurately with negligible overhead.
What would settle it
A direct measurement on a held-out workload or hardware platform showing that batches chosen by the RL policy produce lower throughput than standard schedulers or that Chunked Hash Tree detection time exceeds the cost of existing radix-tree methods.
Figures





















read the original abstract
Auto-regressive token generation in large language models is memory-bound because it requires "attending to" key and value tensors (KV cache) of all previous tokens. Prior work aims to improve the efficiency of this decode process by batching multiple requests together, and maximizing batch size subject to GPU memory constraints. The key observation of our work is that with prefix-sharing workloads, smaller, prefix-homogeneous batches -- where all requests share a common prefix -- can achieve higher decode throughput than larger, heterogeneous batches, due to better spatial and temporal locality during KV cache accesses. However, prefix-aware schedulers in state-of-the-art inference engines maximize prefix reuse within a batch only to reduce KV cache memory footprint, but do not stop batch formation at smaller homogeneous batches that could have performed better. Further, we show that shared prefix detection in existing schedulers relies on radix-tree traversals, incurring substantial CPU overhead that is often comparable to GPU execution time. This paper presents Feather, a prefix-aware scheduler that uses reinforcement learning (RL) to learn the optimal tradeoff between batch size and prefix homogeneity. We also introduce Chunked Hash Tree (CHT), a lightweight data structure that enables fast prefix detection and efficient request selection for the RL scheduler, avoiding expensive tree traversals. We integrate Feather into vLLM and SGLang, and our evaluation shows that Feather achieves 2--10$\times$ higher end-to-end throughput as compared to existing schedulers, while doing no worse than the status quo when the workload does not have enough prefix sharing. Feather achieves these gains by reducing the total number of KV cache accesses, surpassing the performance of prefix-aware attention kernels that have the same goal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current LLM inference schedulers in systems like vLLM and SGLang fail to exploit the observation that smaller prefix-homogeneous batches can outperform larger heterogeneous ones due to better KV cache locality. It introduces Feather, which uses reinforcement learning to learn the optimal batch-size vs. prefix-homogeneity tradeoff, paired with a new Chunked Hash Tree (CHT) data structure for low-overhead prefix detection that avoids expensive radix-tree traversals. When integrated into vLLM and SGLang, Feather is reported to deliver 2–10× higher end-to-end throughput on prefix-sharing workloads while matching baseline performance when sharing is low, with the gains attributed to fewer KV cache accesses.
Significance. If the throughput gains and 'no worse than baseline' guarantee hold under broader conditions, the work would meaningfully advance practical LLM serving efficiency for common prefix-sharing scenarios such as multi-turn chat or RAG. The RL-driven scheduler and CHT represent concrete engineering contributions that directly target an overlooked locality tradeoff; the open integration into two production engines is a positive for reproducibility.
major comments (2)
- [Evaluation (implied by abstract claims and § on RL scheduler)] The headline 2–10× throughput claim and the 'no worse than status quo' guarantee both depend on the RL policy learning a transferable mapping between batch size and prefix homogeneity. The evaluation provides no held-out workload testing, cross-model, or cross-hardware transfer experiments, leaving open the possibility that the learned policy overfits the training traces and reverts to baseline behavior on new prefix-sharing statistics.
- [Abstract and Evaluation section] The abstract states that Feather surpasses prefix-aware attention kernels by reducing total KV cache accesses, yet supplies no workload details, baseline scheduler configurations, statistical tests, or ablation results isolating the contribution of the RL policy versus CHT. Without these, the central performance numbers cannot be independently verified.
minor comments (2)
- [CHT design subsection] The description of CHT overhead as 'negligible' relative to radix trees would benefit from a direct CPU-cycle or latency comparison table against the radix-tree baseline used in vLLM/SGLang.
- [RL scheduler description] Notation for the RL state (batch size, prefix homogeneity metrics) and reward function is introduced without an explicit equation or pseudocode listing, making the policy learning process harder to reproduce.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical contributions of Feather. We address the major comments point by point below. Where the evaluation can be strengthened, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation (implied by abstract claims and § on RL scheduler)] The headline 2–10× throughput claim and the 'no worse than status quo' guarantee both depend on the RL policy learning a transferable mapping between batch size and prefix homogeneity. The evaluation provides no held-out workload testing, cross-model, or cross-hardware transfer experiments, leaving open the possibility that the learned policy overfits the training traces and reverts to baseline behavior on new prefix-sharing statistics.
Authors: We agree that explicit transfer experiments would strengthen the claims. The current evaluation already covers workloads with varying prefix-sharing statistics (including low-sharing cases where Feather matches baseline), and the RL state/reward formulation uses only observable, hardware-agnostic metrics (batch size and prefix homogeneity). Nevertheless, to directly address the concern, we will add held-out workload tests and limited cross-model results in the revised manuscript, along with a discussion of why the learned policy is expected to generalize. revision: yes
-
Referee: [Abstract and Evaluation section] The abstract states that Feather surpasses prefix-aware attention kernels by reducing total KV cache accesses, yet supplies no workload details, baseline scheduler configurations, statistical tests, or ablation results isolating the contribution of the RL policy versus CHT. Without these, the central performance numbers cannot be independently verified.
Authors: We acknowledge that additional detail is needed for independent verification. In the revised manuscript we will expand the evaluation section with: (1) precise workload descriptions including prefix-sharing ratios and request arrival patterns, (2) exact vLLM/SGLang baseline configurations, (3) results with statistical tests and error bars from repeated runs, and (4) ablations that isolate the RL scheduler contribution from the CHT data structure. These additions will clarify how the reported 2–10× gains and KV-cache-access reductions are obtained. revision: yes
Circularity Check
No circularity: empirical throughput claims rest on direct measurements
full rationale
The paper introduces Feather, an RL-based prefix-aware scheduler, and the Chunked Hash Tree data structure. All central claims (2-10x end-to-end throughput gains, reduced KV cache accesses, and 'no worse than status quo' behavior) are supported solely by experimental integration into vLLM and SGLang plus benchmarking on request traces. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the RL policy is trained on finite traces and its performance is reported from held-out runs rather than forced by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Chunked Hash Tree (CHT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming throughput-latency tradeoff in LLM inference with sarathi-serve. In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation. USENIX Associa- tion
2024
-
[2]
AI@Meta. 2024. Llama 3 Model Card. (2024).https://github.com/meta- llama/llama3/blob/main/MODEL_CARD.md
2024
-
[3]
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2024. L-Eval: Insti- tuting Standardized Evaluation for Long Context Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics. doi:10....
-
[4]
Anthropic. 2024. Claude.https://claude.ai
2024
-
[5]
Peter Auer, Nicolò Cesa-Bianchi, and Paul Fischer. 2002. Finite-time Analysis of the Multiarmed Bandit Problem. Machine Learning (2002). doi:10.1023/A:1013689704352
-
[6]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review arXiv 2023
-
[7]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2025. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
-
[8]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[9]
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa
-
[10]
In Proceedings of the 37th International Conference on Neural Information Processing Systems
QuIP: 2-bit quantization of large language models with guaran- tees. In Proceedings of the 37th International Conference on Neural Information Processing Systems. Curran Associates Inc
- [11]
-
[12]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FLASHATTENTION: fast and memory-efficient exact at- tention with IO-awareness. In Proceedings of the 36th International Conference on Neural Information Processing Systems. Curran Asso- ciates Inc
2022
-
[13]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review arXiv 2025
-
[14]
Xin Luna Dong, Seungwhan Moon, Yifan Ethan Xu, Kshitiz Malik, and Zhou Yu. 2023. Towards Next-Generation Intelligent Assistants Lever- aging LLM Techniques. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery. doi:10.1145/3580305.3599572
-
[15]
Google. 2024. Gemini.https://gemini.google.com
2024
-
[16]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report. arXiv:2409.12186 [cs.CL...
work page internal anchor Pith review arXiv 2024
-
[17]
Kamath, Ramya Prabhu, Jayashree Mohan, Simon Pe- ter, Ramachandran Ramjee, and Ashish Panwar
Aditya K. Kamath, Ramya Prabhu, Jayashree Mohan, Simon Pe- ter, Ramachandran Ramjee, and Ashish Panwar. 2025. POD- Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM In- ference. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. Association for Computing...
-
[18]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[19]
and Zhang, Hao and Stoica, Ion , booktitle =
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. In Proceedings of the 29th Symposium on Operating Systems Principles. Association for Computing Machinery. doi:10.1145/3600006.3613165
-
[20]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems. Curran As- sociates, Inc.https://proceedi...
2020
-
[21]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems. C...
2020
-
[22]
Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang
Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. 2023. How Long Can Open-Source LLMs Truly Promise on Context Length? https://lmsys.org/blog/2023-06-29-longchat
2023
- [23]
-
[24]
Zejia Lin, Hongxin Xu, Guanyi Chen, Zhiguang Chen, Yutong Lu, and Xianwei Zhang. 2026. Bullet: Boosting GPU Utilization for LLM Serving via Dynamic Spatial-Temporal Orchestration. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. As- sociation for Computing Machinery...
-
[25]
2024.NVIDIA RTX 6000 Ada Generation Datasheet
NVIDIA Corporation. 2024.NVIDIA RTX 6000 Ada Generation Datasheet. https://resources.nvidia.com/en-us-briefcase-for-datasheets/proviz- print-rtx6000-1?ncid=no-ncidAccessed: January 25, 2026
2024
-
[26]
NVIDIA Corporation. 2026. NVIDIA Data Center GPU Manager (DCGM) Documentation.https://docs.nvidia.com/datacenter/dcgm/ latest/user-guide/
2026
-
[27]
OpenAI. 2024. ChatGPT.https://chatgpt.com
2024
-
[28]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page internal anchor Pith review arXiv 2024
-
[29]
Zaifeng Pan, Yitong Ding, Yue Guan, Zheng Wang, Zhongkai Yu, Xulong Tang, Yida Wang, and Yufei Ding. 2025. FastTree: Op- timizing Attention Kernel and Runtime for Tree-Structured LLM Inference. In Proceedings of Machine Learning and Systems. ML- Sys.https://proceedings.mlsys.org/paper_files/paper/2025/file/ 96894468eb44631a32d7ebd56f9892c7-Paper-Conference.pdf
2025
- [30]
-
[31]
Ivy Bo Peng, Roberto Gioiosa, Gokcen Kestor, Pietro Cicotti, Er- win Laure, and Stefano Markidis. 2017. Exploring the Performance Benefit of Hybrid Memory System on HPC Environments. In 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE. doi:10.1109/ipdpsw.2017.115
-
[32]
Ethan Perez, Douwe Kiela, and Kyunghyun Cho. 2021. True Few-Shot Learning with Language Models. In Advances in Neural Information Processing Systems. Curran Associates, Inc.https://proceedings.neurips.cc/paper_files/paper/2021/file/ 5c04925674920eb58467fb52ce4ef728-Paper.pdf
2021
-
[33]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, and Ashish Panwar. 2025. vAttention: Dynamic Memory Manage- ment for Serving LLMs without PagedAttention. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. Associa- tion for Computing Machinery. doi:10.1...
- [34]
-
[35]
The Big Prompt Library Contributors. 2024. The Big Prompt Library: A Collection of Prompts, System Prompts and LLM Instructions.https: //github.com/0xeb/TheBigPromptLibrary. GitHub repository
2024
-
[36]
vLLM Project Contributors. 2024. Automatic Prefix Caching.https:// docs.vllm.ai/en/stable/design/prefix_caching/. vLLM Documentation. Accessed: 2026-03-10
2024
-
[37]
Christopher J. C. H. Watkins and Peter Dayan. 1992. Q-Learning. Machine Learning (1992). doi:10.1007/BF00992698
-
[38]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebas- tian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022. Emergent Abilities of Large Lan- guage Models. Transactions on Machine Learning Research (2022). https://openreview.ne...
2022
-
[39]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. LoongServe: Efficiently Serving Long-Context Large Language Models with Elastic Sequence Parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. Association for Computing Machinery. doi:10.1145/3694715.3695948
-
[40]
Jinwei Yao, Kaiqi Chen, Kexun Zhang, Jiaxuan You, Binhang Yuan, Zeke Wang, and Tao Lin. 2024. DeFT: Decoding with Flash Tree-attention for Efficient Tree-structured LLM Inference. In International Conference on Learning Representations.https: //api.semanticscholar.org/CorpusID:268819748
2024
-
[41]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowl- edge Fusion. In Proceedings of the Twentieth European Conference on Computer Systems. Association for Computing Machinery. doi:10. 1145/3689031.3696098
-
[42]
Lu Ye, Ze Tao, Yong Huang, and Yang Li. 2024. ChunkAttention: Effi- cient Self-Attention with Prefix-Aware KV Cache and Two-Phase Par- tition. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics. doi:10.18653/v1/2024.acl-long.623
-
[43]
Jinjun Yi, Zhixin Zhao, Yitao Hu, Ke Yan, Weiwei Sun, Hao Wang, Laiping Zhao, Yuhao Zhang, Wenxin Li, and Keqiu Li. 2026. PAT: Accelerating LLM Decoding via Prefix-Aware Attention with Re- source Efficient Multi-Tile Kernel. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vo...
-
[44]
Chen Zhang, Kuntai Du, Shu Liu, Woosuk Kwon, Xiangxi Mo, Yufeng Wang, Xiaoxuan Liu, Kaichao You, Zhuohan Li, Mingsheng Long, Jidong Zhai, Joseph Gonzalez, and Ion Stoica. 2025. Jenga: Effec- tive Memory Management for Serving LLM with Heterogeneity. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. Association for Computing ...
-
[45]
Yilong Zhao, Shuo Yang, Kan Zhu, Lianmin Zheng, Baris Kasikci, Yifan Qiao, Yang Zhou, Jiarong Xing, and Ion Stoica. 2026. Blend- Serve: Optimizing Offline Inference with Resource-Aware Batch- ing. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. Association for Comp...
-
[46]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Sto- ica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: efficient execution of structured language model programs. In Proceedings of the 38th International Conference on Neural Information Processing Systems. Curran Assoc...
2024
- [47]
-
[48]
Zhen Zheng, Xin Ji, Taosong Fang, Fanghao Zhou, Chuanjie Liu, and Gang Peng. 2025. BatchLLM: Optimizing Large Batched LLM Inference with Global Prefix Sharing and Throughput-oriented Token Batching. arXiv:2412.03594 [cs.CL]https://arxiv.org/abs/2412.03594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregat- ing prefill and decoding for goodput-optimized large language model serving. In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation. USENIX Association. A Experimental Setup of §3.1 A.1 Two L...
2024
-
[50]
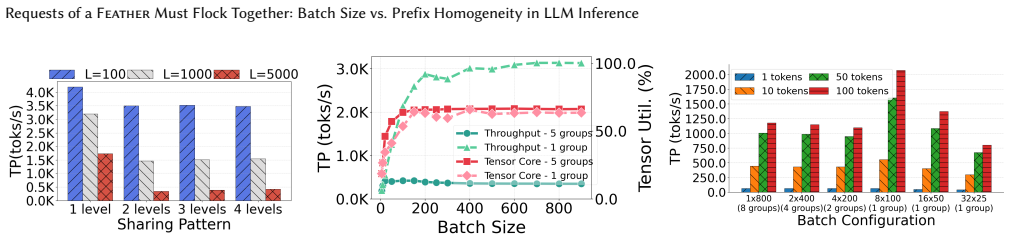
Throughput is significantly lower at smaller values of 𝑓1, primarily because limited GPU memory leads to frequent cache evictions
This occurs because at 𝑓2 = 1, the entire batch becomes homogeneous, resulting in fully aligned KV cache traversal. Throughput is significantly lower at smaller values of 𝑓1, primarily because limited GPU memory leads to frequent cache evictions. This is further supported by the increase in throughput with rising 𝑓2 at low 𝑓1, as more requests share the s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.