Recognition: unknown
Understanding diffusion models requires rethinking (again) generalization
Pith reviewed 2026-05-08 13:50 UTC · model grok-4.3
The pith
Diffusion models that fully memorize training data generate only copies, not novel samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that memorization and generalization are incompatible in diffusion models: a model that has fully memorized its training set generates copies of those examples instead of novel data. This incompatibility means that frameworks developed for supervised learning do not apply, so new theory is required that focuses on the pre-memorization regime rather than on why the model avoids memorization.
What carries the argument
The incompatibility between memorization (producing exact copies) and generalization (producing novel samples) during diffusion model training.
If this is right
- Existing explanations based on capacity limits, implicit regularization, or architectural biases must be re-examined for their interactions rather than treated separately.
- Research focus should move from explaining avoidance of memorization to characterizing learning dynamics in the pre-memorization phase.
- Empirical probes on datasets such as CIFAR-10 can be used to formulate precise open questions that guide new theory.
- Theoretical tools for diffusion models will need to be built from scratch rather than adapted from supervised learning.
Where Pith is reading between the lines
- If the pre-memorization phase determines output diversity, then training schedules could be tuned to extend that phase deliberately.
- The same memorization-generalization tension may appear in other score-based or flow-based generative models.
- Capacity and regularization measures will likely need to be redefined for the generative setting rather than imported from classification.
Load-bearing premise
That a diffusion model which has memorized every training example must output only exact replicas rather than any new variations of them.
What would settle it
Train a diffusion model on a small dataset until it reproduces every training image exactly when conditioned on the corresponding noise, then sample new images from fresh noise inputs and check whether any outputs differ from the training set.
Figures

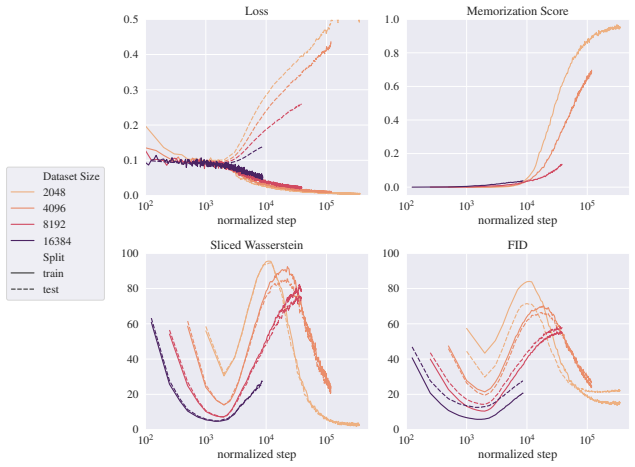
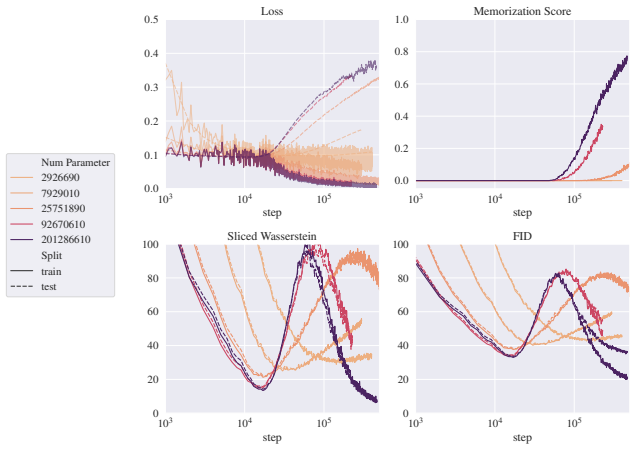

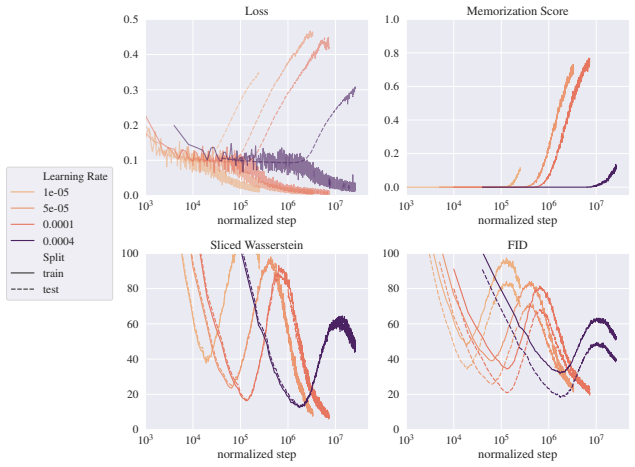

read the original abstract
This position paper argues that understanding generalization in diffusion models requires fundamentally new theoretical frameworks that go beyond both classical statistical learning theory and the benign overfitting paradigm developed for supervised learning. In diffusion models, unlike in supervised learning, memorization of training data and generalization to novel samples are incompatible: a model that has fully memorized its training set generates copies rather than novel data. Several theoretical explanations for why practical diffusion models nevertheless generalize have been proposed, based on capacity limitations, implicit regularization from optimization, or architectural inductive biases, but their interactions remain unclear. We argue that the field should pivot from explaining why the diffusion models do not memorize to investigating what the model actually learns during pre-memorization phase. To highlight our stance, we conduct empirical study of diffusion models trained on CIFAR-10, and we distill the findings into concrete open questions that we believe are key to improve understanding of generalization in diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that understanding generalization in diffusion models requires new theoretical frameworks beyond classical statistical learning theory and the benign overfitting paradigm from supervised learning. It claims that memorization and generalization are incompatible in diffusion models: a fully memorized model generates exact copies of training data rather than novel samples. The authors critique proposed explanations (capacity limits, implicit regularization, architectural biases) and advocate pivoting research to investigate what models learn in the pre-memorization phase. They support the position with a CIFAR-10 empirical study whose findings are distilled into open questions.
Significance. If the core incompatibility claim holds and can be formalized, the paper could meaningfully redirect research on generative models toward diffusion-specific mechanisms of generalization. The distillation of concrete open questions is a constructive element that may guide subsequent theoretical and empirical work, even if the current argument remains largely logical rather than derived from proofs or fully detailed experiments.
major comments (2)
- [Abstract / Introduction] The central claim that full memorization necessarily produces exact copies (rather than novel samples) under the stochastic reverse process is stated without a formal definition of memorization (e.g., via the learned score function) or a quantitative criterion distinguishing copies from novel outputs. This premise is load-bearing for the incompatibility argument and the call for entirely new frameworks.
- [Empirical Study] The CIFAR-10 empirical study is invoked to highlight the stance and distill open questions, yet the manuscript provides no details on memorization metrics, sampling temperature, novelty quantification, or experimental controls. Without these, the study cannot be evaluated as support for the position that practical diffusion models generalize despite the claimed incompatibility.
minor comments (1)
- [Title] The title's parenthetical '(again)' is unclear without explicit reference to prior 'rethinkings' of generalization that the authors have in mind.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our position paper. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Introduction] The central claim that full memorization necessarily produces exact copies (rather than novel samples) under the stochastic reverse process is stated without a formal definition of memorization (e.g., via the learned score function) or a quantitative criterion distinguishing copies from novel outputs. This premise is load-bearing for the incompatibility argument and the call for entirely new frameworks.
Authors: We agree that a more precise formalization of the central claim would improve rigor. In the revised manuscript we will add a dedicated paragraph defining memorization via convergence of the learned score function to the empirical data distribution, such that the stochastic reverse process recovers training samples with high probability when initialized at the appropriate noise scale. We will also introduce a quantitative criterion based on reconstruction error and perceptual similarity thresholds to distinguish exact copies from novel outputs. These additions will make explicit why full memorization is incompatible with novel generation and thereby support the argument for diffusion-specific generalization frameworks. revision: yes
-
Referee: [Empirical Study] The CIFAR-10 empirical study is invoked to highlight the stance and distill open questions, yet the manuscript provides no details on memorization metrics, sampling temperature, novelty quantification, or experimental controls. Without these, the study cannot be evaluated as support for the position that practical diffusion models generalize despite the claimed incompatibility.
Authors: The CIFAR-10 study is presented as an illustrative example to motivate the distilled open questions rather than as a comprehensive experimental validation. We nevertheless accept that greater transparency is required. In the revision we will expand the relevant section to specify the memorization metrics (nearest-neighbor distances in feature space with exact-match thresholds), sampling temperature and other inference hyperparameters, novelty quantification procedures (FID combined with perceptual similarity checks), and experimental controls (model architecture, training schedule, and comparison baselines). These details will allow readers to assess the study in the context of our position. revision: yes
Circularity Check
Position paper with no derivations, equations, or self-referential predictions
full rationale
The manuscript is a position paper that advances an argument by direct logical contrast: memorization in diffusion models produces copies rather than novel samples, unlike in supervised learning. No equations, fitted parameters, or derivation chains appear in the provided text. The central claim is presented as a premise to motivate new frameworks, not as a result obtained from prior results or self-citations. The CIFAR-10 study is described only at the level of distilling open questions, without quantitative metrics or modeling steps that could reduce to inputs by construction. Consequently no load-bearing step satisfies any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A fully memorized diffusion model generates exact copies of training samples rather than novel outputs.
- domain assumption Classical statistical learning theory and the benign overfitting paradigm do not suffice to explain generalization in diffusion models.
Reference graph
Works this paper leans on
-
[1]
Alquier, P. (2024). User-friendly introduction to PAC - B ayes bounds. Foundations and Trends in Machine Learning , 17(2):174--303
2024
-
[2]
S., Maharaj, T., Fischer, A., Courville, A., Bengio, Y., and Lacoste-Julien, S
Arpit, D., Jastrzebski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M. S., Maharaj, T., Fischer, A., Courville, A., Bengio, Y., and Lacoste-Julien, S. (2017). A closer look at memorization in deep networks. In International Conference on Machine Learning , pages 233--242. PMLR
2017
- [3]
- [4]
-
[5]
L., Long, P
Bartlett, P. L., Long, P. M., Lugosi, G., and Tsigler, A. (2020). Benign overfitting in linear regression. Proceedings of the National Academy of Sciences , 117(48):30063--30070
2020
-
[6]
Bartlett, P. L. and Mendelson, S. (2002). Rademacher and G aussian complexities: Risk bounds and structural results. Journal of Machine Learning Research , 3:463--482
2002
-
[7]
Belkin, M., Hsu, D., Ma, S., and Mandal, S. (2019). Reconciling modern machine-learning practice and the classical bias--variance trade-off. Proceedings of the National Academy of Sciences , 116(32):15849--15854
2019
-
[8]
D., Doucet, A., and Deligiannidis, G
Benton, J., Bortoli, V. D., Doucet, A., and Deligiannidis, G. (2024). Nearly \ d\ -linear convergence bounds for diffusion models via stochastic localization. In The Twelfth International Conference on Learning Representations
2024
-
[9]
Beyler, E. and Bach, F. (2025). Convergence of deterministic and stochastic diffusion-model samplers: A simple analysis in Wasserstein distance. arXiv:2508.03210
-
[10]
Biroli, G., Bonnaire, T., De Bortoli, V., and M \'e zard, M. (2024). Dynamical regimes of diffusion models. Nature Communications , 15(1):9957
2024
-
[11]
and Michaeli, T
Blau, Y. and Michaeli, T. (2018). The perception-distortion tradeoff. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 6228--6237. IEEE Computer Society
2018
-
[12]
Bonnaire, T., Urfin, R., Biroli, G., and Mezard, M. (2025). Why diffusion models don’t memorize: The role of implicit dynamical regularization in training. In Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., and Chen, N., editors, Advances in Neural Information Processing Systems , volume 38, pages 141266--141286. Curran Associates, Inc
2025
-
[13]
and Elisseeff, A
Bousquet, O. and Elisseeff, A. (2002). Stability and generalization. Journal of Machine Learning Research , 2:499--526
2002
-
[14]
Buchanan, S., Pai, D., Ma, Y., and De Bortoli, V. (2025). On the edge of memorization in diffusion models. In Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., and Chen, N., editors, Advances in Neural Information Processing Systems , volume 38, pages 96113--96157. Curran Associates, Inc
2025
-
[15]
Carlini, N., Hayes, J., Nasr, M., Jagielski, M., Sehwag, V., Tram \`e r, F., Balle, B., Ippolito, D., and Wallace, E. (2023). Extracting training data from diffusion models. In USENIX Security Symposium
2023
-
[16]
and Bach, F
Chizat, L. and Bach, F. (2020). Implicit bias of gradient descent for wide two-layer neural networks trained with the logistic loss. In Abernethy, J. and Agarwal, S., editors, Proceedings of Thirty Third Conference on Learning Theory , volume 125 of Proceedings of Machine Learning Research , pages 1305--1338. PMLR
2020
-
[17]
Z., and Lee, J
Cohen, J., Damian, A., Talwalkar, A., Kolter, J. Z., and Lee, J. D. (2025). Understanding optimization in deep learning with central flows. In The Thirteenth International Conference on Learning Representations
2025
-
[18]
Z., and Talwalkar, A
Cohen, J., Kaur, S., Li, Y., Kolter, J. Z., and Talwalkar, A. (2021). Gradient descent on neural networks typically occurs at the edge of stability. In The Ninth International Conference on Learning Representations
2021
-
[19]
Conforti, G., Durmus, A., and Silveri, M. G. (2025). KL convergence guarantees for score diffusion models under minimal data assumptions. SIAM Journal on Mathematics of Data Science , 7(1):86--109
2025
-
[20]
Cui, H., Krzakala, F., Vanden-Eijnden, E., and Zdeborov \'a , L. (2024). Analysis of learning a flow-based generative model from limited sample complexity. In The Twelfth International Conference on Learning Representations
2024
-
[21]
Dziugaite, G. K. and Roy, D. M. (2017). Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. In Proceedings of the 33rd Conference on Uncertainty in Artificial Intelligence
2017
-
[22]
Farghly, T., Potaptchik, P., Howard, S., Deligiannidis, G., and Pidstrigach, J. (2025). Diffusion models and the manifold hypothesis: Log-domain smoothing is geometry adaptive. In Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., and Chen, N., editors, Advances in Neural Information Processing Systems , volume 38, pages 122795--122...
2025
-
[23]
Farghly, T., Rebeschini, P., Deligiannidis, G., and Doucet, A. (2026). Implicit regularisation in diffusion models: An algorithm-dependent generalisation analysis. In The Fourteenth International Conference on Learning Representations
2026
- [24]
-
[25]
Gu, X., Du, C., Pang, T., Li, C., Lin, M., and Wang, Y. (2025). On memorization in diffusion models. Transactions on Machine Learning Research
2025
-
[26]
E., Bhojanapalli, S., Neyshabur, B., and Srebro, N
Gunasekar, S., Woodworth, B. E., Bhojanapalli, S., Neyshabur, B., and Srebro, N. (2017). Implicit regularization in matrix factorization. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., editors, Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc
2017
-
[27]
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc
2017
-
[28]
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H., editors, Advances in Neural Information Processing Systems , volume 33, pages 6840--6851. Curran Associates, Inc
2020
-
[29]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. (2022). Classifier-free diffusion guidance. arXiv:2207.12598
work page internal anchor Pith review arXiv 2022
-
[30]
and Dayan, P
Hyv \"a rinen, A. and Dayan, P. (2005). Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research , 6(4)
2005
-
[31]
Kadkhodaie, Z., Guth, F., Simoncelli, E., and Mallat, S. (2024). Generalization in diffusion models arises from geometry-adaptive harmonic representations. In The Twelfth International Conference on Learning Representations
2024
-
[32]
and Ganguli, S
Kamb, M. and Ganguli, S. (2025). An analytic theory of creativity in convolutional diffusion models. In International Conference on Machine Learning , pages 28795--28831. PMLR
2025
-
[33]
and Hinton, G
Krizhevsky, A. and Hinton, G. (2009). Learning multiple layers of features from tiny images. Technical report, University of Toronto
2009
-
[34]
Kynk \"a \"a nniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. (2019). Improved precision and recall metric for assessing generative models. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché Buc, F., Fox, E., and Garnett, R., editors, Advances in Neural Information Processing Systems , volume 32. Curran Associates, Inc
2019
- [35]
- [36]
-
[37]
Liu, X., Gong, C., and Liu, Q. (2023). Flow straight and fast: Learning to generate and transfer data with rectified flow. In The Eleventh International Conference on Learning Representations
2023
-
[38]
Lyu, Y., Nguyen, T. M., Qian, Y., and Tong, X. T. (2025). Resolving memorization in empirical diffusion model for manifold data in high-dimensional spaces. arXiv:2505.02508
-
[39]
McAllester, D. A. (1999). PAC - B ayesian model averaging. Proceedings of the 12th Annual Conference on Computational Learning Theory , pages 164--170
1999
-
[40]
Generalization dynamics of linear diffusion models
Merger, C. and Goldt, S. (2025). Generalization dynamics of linear diffusion models. arXiv:2505.24769
-
[41]
and Michaeli, T
Mulayoff, R. and Michaeli, T. (2020). Unique properties of flat minima in deep networks. In International Conference on Machine Learning , pages 7108--7118. PMLR
2020
-
[42]
and Michaeli, T
Mulayoff, R. and Michaeli, T. (2024). Exact mean square linear stability analysis for SGD . In The Thirty Seventh Annual Conference on Learning Theory , pages 3915--3969. PMLR
2024
-
[43]
Nakkiran, P., Kaplun, G., Bansal, Y., Yang, T., Barak, B., and Sutskever, I. (2021). Deep double descent: Where bigger models and more data hurt. Journal of Statistical Mechanics: Theory and Experiment , 2021(12):124003
2021
-
[44]
Neyshabur, B., Bhojanapalli, S., McAllester, D., and Srebro, N. (2017). Exploring generalization in deep learning. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., editors, Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc
2017
-
[45]
Oko, K., Akiyama, S., and Suzuki, T. (2023). Diffusion models are minimax optimal distribution estimators. In International Conference on Machine Learning , pages 26517--26582. PMLR
2023
-
[46]
D., Ravindra, S
Pizzi, E., Roy, S. D., Ravindra, S. N., Goyal, P., and Douze, M. (2022). A self-supervised descriptor for image copy detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 14532--14542
2022
-
[47]
Qiao, D., Zhang, K., Singh, E., Soudry, D., and Wang, Y.-X. (2024). Stable minima cannot overfit in univariate ReLU networks: Generalization by large step sizes. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C., editors, Advances in Neural Information Processing Systems , volume 37, pages 94163--94208. Curran Ass...
2024
-
[48]
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-Net : Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention , pages 234--241. Springer
2015
-
[49]
and Ben-David, S
Shalev-Shwartz, S. and Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms . Cambridge University Press
2014
- [50]
-
[51]
Somepalli, G., Singla, V., Goldblum, M., Geiping, J., and Goldstein, T. (2023a). Diffusion art or digital forgery? I nvestigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 6048--6058
-
[52]
Somepalli, G., Singla, V., Goldblum, M., Geiping, J., and Goldstein, T. (2023b). Understanding and mitigating copying in diffusion models. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S., editors, Advances in Neural Information Processing Systems , volume 36, pages 47783--47803. Curran Associates, Inc
-
[53]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. (2021). Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations
2021
- [54]
-
[55]
L., and Lemaire, V
Strasman, S., Ocello, A., Boyer, C., Corff, S. L., and Lemaire, V. (2025). An analysis of the noise schedule for score-based generative models. Transactions on Machine Learning Research
2025
-
[56]
and Yang, Y
Tang, R. and Yang, Y. (2024). Adaptivity of diffusion models to manifold structures. In International Conference on Artificial Intelligence and Statistics , pages 1648--1656. PMLR
2024
-
[57]
Theis, L., Oord, A. v. d., and Bethge, M. (2016). A note on the evaluation of generative models. In The Fourth International Conference on Learning Representations
2016
-
[58]
Vincent, P. (2011). A connection between score matching and denoising autoencoders. Neural Computation , 23(7):1661--1674
2011
-
[59]
M., and Barak, B
Vyas, N., Kakade, S. M., and Barak, B. (2023). On provable copyright protection for generative models. In Proceedings of the 40th International Conference on Machine Learning , volume 202, pages 35277--35299. PMLR
2023
-
[60]
Wu, Y.-H., Marion, P., Biau, G., and Boyer, C. (2025). Taking a big step: Large learning rates in denoising score matching prevent memorization. In Haghtalab, N. and Moitra, A., editors, Proceedings of Thirty Eighth Conference on Learning Theory , volume 291 of Proceedings of Machine Learning Research , pages 5718--5756. PMLR
2025
-
[61]
Yamaguchi, S. and Fukuda, T. (2023). On the limitation of diffusion models for synthesizing training datasets. arXiv:2311.13090
-
[62]
Y., Kwon, S., and Ryu, E
Yoon, T., Choi, J. Y., Kwon, S., and Ryu, E. K. (2023). Diffusion probabilistic models generalize when they fail to memorize. In ICML 2023 Workshop on Structured Probabilistic Inference & Generative Modeling
2023
-
[63]
Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. (2017). Understanding deep learning requires rethinking generalization. In The Fifth International Conference on Learning Representations
2017
-
[64]
Zhang, Y., Tzun, T. T., Hern, L. W., Wang, H., and Kawaguchi, K. (2023). On copyright risks of text-to-image diffusion models. arXiv:2311.12803
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.