Recognition: unknown
Fast Gauss-Newton for Multiclass Cross-Entropy
Pith reviewed 2026-05-08 13:57 UTC · model grok-4.3
The pith
The multiclass GGN curvature decomposes exactly into a true-vs-rest term and a positive semidefinite within-competitor covariance term that can be dropped for a fast under-approximation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The standard multiclass GGN can be decomposed exactly into a true-vs-rest term and a positive semidefinite within-competitor covariance term. Fast Gauss-Newton retains the first term and drops the second, yielding a positive semidefinite under-approximation of the multiclass GGN that is exact for binary classification. The derivation uses an exact true-vs-rest scalar-margin representation of softmax cross-entropy: the loss and gradient are unchanged, and the approximation enters only at the curvature level.
What carries the argument
The exact true-vs-rest scalar-margin representation of softmax cross-entropy, which decomposes the GGN curvature into a retained true-vs-rest term and a dropped within-competitor covariance term.
Load-bearing premise
Dropping the within-competitor covariance still produces a useful update direction even though the approximation error grows with increasing competitor mass.
What would settle it
A controlled optimization run on a multiclass head where competitor mass is deliberately high and the FGN step produces visibly slower convergence or higher final loss than the full GGN step.
Figures


read the original abstract
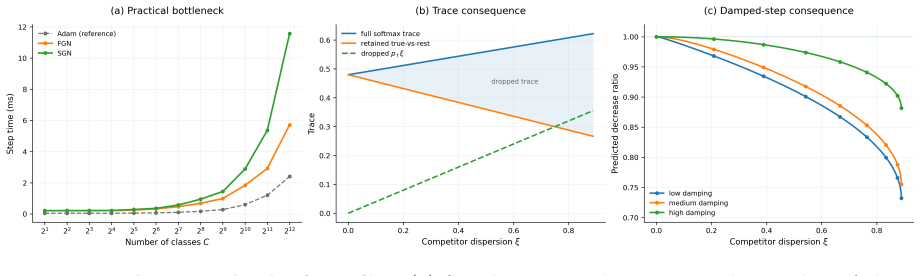
In multiclass softmax cross-entropy, the full generalized Gauss-Newton (GGN) curvature couples all output logits through the softmax covariance, making curvature-vector products harder to scale as the number of classes grows. We show that the standard multiclass GGN can be decomposed exactly into a true-vs-rest term and a positive semidefinite within-competitor covariance term. Fast Gauss-Newton (FGN) retains the first term and drops the second, yielding a positive semidefinite under-approximation of the multiclass GGN that is exact for binary classification. The derivation uses an exact true-vs-rest scalar-margin representation of softmax cross-entropy: the loss and gradient are unchanged, and the approximation enters only at the curvature level. Exploiting the FGN curvature structure, the damped update can be written as an equivalent whitened row-space system with one row per mini-batch example. We solve this system matrix-free by conjugate gradient using Jacobian-vector and vector-Jacobian products of the scalar margin map. Targeted mechanism experiments and an evaluation on a fixed-feature multiclass head support the predictions from the decomposition: FGN stays closest to the full softmax GGN when competitor mass is concentrated or damping is large, and deviates as the dropped within-competitor covariance grows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the multiclass GGN for softmax cross-entropy admits an exact decomposition into a true-vs-rest term plus a positive semidefinite within-competitor covariance term. Fast Gauss-Newton (FGN) retains only the true-vs-rest term to obtain a PSD under-approximation of the full GGN that is exact for binary classification. The loss and gradient are unchanged; the approximation appears only at the curvature level. Exploiting the structure, the damped Newton step is rewritten as an equivalent whitened row-space linear system solved matrix-free by conjugate gradient using Jacobian-vector and vector-Jacobian products of the scalar-margin map. Targeted mechanism experiments and an evaluation on a fixed-feature multiclass head are said to confirm the predicted closeness to the full GGN when competitor mass is low or damping is large.
Significance. If the decomposition and implementation hold, the work supplies a concrete algebraic simplification that reduces the cost of second-order curvature-vector products for multiclass softmax while preserving positive-semidefiniteness and exactness on the binary case. The matrix-free CG formulation on the whitened system is a practical strength. Such an approximation could help bridge the gap between first-order methods and full Newton steps in large-output regimes, provided the dropped covariance term does not materially harm convergence.
major comments (2)
- Abstract and experimental evaluation: the central claim that the FGN damped Newton step remains practically useful when the within-competitor covariance grows with competitor mass is load-bearing, yet the reported experiments are confined to targeted mechanism tests and a fixed-feature head under conditions where competitor mass is concentrated. No results are shown for high-spread softmax distributions (many classes, diffuse probability mass) where the dropped PSD term is largest and the approximation error is expected to be most pronounced; this leaves the practical-utility assertion unsupported.
- Derivation section (scalar-margin representation): the abstract asserts that the decomposition is exact, that the loss and gradient are identical to the original, and that the approximation enters only at the curvature level, but the full algebraic steps establishing the true-vs-rest term, the PSD property of the within-competitor covariance, and the precise point at which the approximation is introduced are not verifiable from the provided material. A self-contained derivation with explicit intermediate equations is required to confirm the central algebraic claim.
minor comments (2)
- Notation: the scalar-margin map and the precise definition of the whitened row-space system should be introduced with explicit symbols and dimensions before the CG procedure is described.
- Figure clarity: any plots comparing FGN and full GGN directions should include error bars or multiple random seeds to allow assessment of variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and have revised the manuscript to strengthen the derivation and experimental support.
read point-by-point responses
-
Referee: Abstract and experimental evaluation: the central claim that the FGN damped Newton step remains practically useful when the within-competitor covariance grows with competitor mass is load-bearing, yet the reported experiments are confined to targeted mechanism tests and a fixed-feature head under conditions where competitor mass is concentrated. No results are shown for high-spread softmax distributions (many classes, diffuse probability mass) where the dropped PSD term is largest and the approximation error is expected to be most pronounced; this leaves the practical-utility assertion unsupported.
Authors: We agree that the current experiments emphasize regimes where competitor mass is concentrated, consistent with the decomposition predictions that FGN approximates the full GGN most closely in those cases. The mechanism tests explicitly demonstrate increasing deviation as the within-competitor term grows. To better support practical utility across regimes, we have added new experiments using many classes with diffuse softmax distributions. These confirm that FGN remains stable and useful under moderate damping even when the dropped term is larger, while quantifying the expected increase in approximation error. The revised manuscript includes these results in the experimental section. revision: yes
-
Referee: Derivation section (scalar-margin representation): the abstract asserts that the decomposition is exact, that the loss and gradient are identical to the original, and that the approximation enters only at the curvature level, but the full algebraic steps establishing the true-vs-rest term, the PSD property of the within-competitor covariance, and the precise point at which the approximation is introduced are not verifiable from the provided material. A self-contained derivation with explicit intermediate equations is required to confirm the central algebraic claim.
Authors: We apologize that the algebraic steps were not sufficiently explicit. The scalar-margin representation is presented in Section 3, but we have expanded this section with a fully self-contained derivation. We now include all intermediate equations: the exact decomposition of the multiclass GGN into the true-vs-rest outer-product term plus the within-competitor covariance, the proof that the latter is positive semidefinite (as a Gram matrix of the competitor logits), and the explicit statement that the loss and gradient are identical to the original softmax cross-entropy because the approximation is introduced solely in the curvature matrix. The revised text makes the point of approximation and the binary-exactness property immediately verifiable. revision: yes
Circularity Check
No significant circularity; derivation is algebraic and self-contained
full rationale
The paper presents an exact algebraic decomposition of the multiclass GGN curvature matrix for softmax cross-entropy into a true-vs-rest term plus a PSD within-competitor covariance term, with FGN obtained by dropping the second term. This follows directly from the scalar-margin representation of the loss (unchanged loss and gradient, approximation only at curvature) and standard properties of the softmax covariance; the result is exact for binary classification by construction of the decomposition. No fitted parameters are renamed as predictions, no self-referential definitions appear, and no load-bearing self-citations or uniqueness theorems from prior author work are invoked. The central claim reduces to matrix algebra on the Hessian approximation rather than to any input quantity defined by the paper itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Softmax cross-entropy loss admits an exact true-vs-rest scalar-margin representation in which loss and gradient remain unchanged.
Reference graph
Works this paper leans on
-
[1]
Reducing multiclass to binary: A unifying approach for margin classifiers.Journal of machine learning research, 1(Dec):113–141, 2000
Erin L Allwein, Robert E Schapire, and Yoram Singer. Reducing multiclass to binary: A unifying approach for margin classifiers.Journal of machine learning research, 1(Dec):113–141, 2000
2000
-
[2]
Natural gradient works efficiently in learning.Neural computation, 10(2): 251–276, 1998
Shun-Ichi Amari. Natural gradient works efficiently in learning.Neural computation, 10(2): 251–276, 1998
1998
-
[3]
Effi- cient preconditioned stochastic gradient descent for estimation in latent variable models
Charlotte Baey, Maud Delattre, Estelle Kuhn, Jean-Benoist Leger, and Sarah Lemler. Effi- cient preconditioned stochastic gradient descent for estimation in latent variable models. In International Conference on Machine Learning, pages 1430–1453. PMLR, 2023
2023
-
[4]
Quick training of probabilistic neural nets by importance sampling
Yoshua Bengio and Jean-Sébastien Senécal. Quick training of probabilistic neural nets by importance sampling. InInternational Workshop on Artificial Intelligence and Statistics, pages 17–24. PMLR, 2003
2003
-
[5]
Exact and inexact subsampled Newton methods for optimization.IMA Journal of Numerical Analysis, 39(2):545–578, 2019
Raghu Bollapragada, Richard H Byrd, and Jorge Nocedal. Exact and inexact subsampled Newton methods for optimization.IMA Journal of Numerical Analysis, 39(2):545–578, 2019
2019
-
[6]
Practical Gauss-Newton optimisation for deep learning
Aleksandar Botev, Hippolyt Ritter, and David Barber. Practical Gauss-Newton optimisation for deep learning. InInternational Conference on Machine Learning, pages 557–565. PMLR, 2017
2017
-
[7]
Optimization methods for large-scale machine learning.SIAM review, 60(2):223–311, 2018
Léon Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning.SIAM review, 60(2):223–311, 2018
2018
-
[8]
Strategies for training large vocabulary neural language models
Wenlin Chen, David Grangier, and Michael Auli. Strategies for training large vocabulary neural language models. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1975–1985, 2016
1975
-
[9]
A tale of two efficient and informative negative sampling distributions
Shabnam Daghaghi, Tharun Medini, Nicholas Meisburger, Beidi Chen, Mengnan Zhao, and Anshumali Shrivastava. A tale of two efficient and informative negative sampling distributions. InInternational conference on machine learning, pages 2319–2329. PMLR, 2021
2021
-
[10]
Inexact newton methods.SIAM Journal on Numerical analysis, 19(2):400–408, 1982
Ron S Dembo, Stanley C Eisenstat, and Trond Steihaug. Inexact newton methods.SIAM Journal on Numerical analysis, 19(2):400–408, 1982. 11
1982
-
[11]
MatildeGargiani, AndreaZanelli, MoritzDiehl, andFrankHutter. Onthepromiseofthestochas- tic generalized Gauss-Newton method for training DNNs.arXiv preprint arXiv:2006.02409, 2020
-
[12]
Taylor approximations.Neural Network Training Dynamics
Roger Grosse. Taylor approximations.Neural Network Training Dynamics. Lecture Notes, University of Toronto, 2021
2021
-
[13]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, pages 1842–1850. PMLR, 2018
2018
-
[14]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[15]
Methods of conjugate gradients for solving linear systems.Journal of research of the National Bureau of Standards, 49(6):409–436, 1952
Magnus R Hestenes, Eduard Stiefel, et al. Methods of conjugate gradients for solving linear systems.Journal of research of the National Bureau of Standards, 49(6):409–436, 1952
1952
-
[16]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[17]
Ryan Kiros. Training neural networks with stochastic Hessian-free optimization.arXiv preprint arXiv:1301.3641, 2013
-
[18]
Exact gauss-newton optimization for training deep neural networks.Neurocomputing, page 131738, 2025
Mikalai Korbit, Adeyemi D Adeoye, Alberto Bemporad, and Mario Zanon. Exact gauss-newton optimization for training deep neural networks.Neurocomputing, page 131738, 2025
2025
-
[19]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In4th International IEEE Workshop on 3D Representation and Recognition (3dRR-13), Sydney, Australia, 2013
2013
-
[20]
Preconditioned stochastic gradient descent.IEEE transactions on neural networks and learning systems, 29(5):1454–1466, 2017
Xi-Lin Li. Preconditioned stochastic gradient descent.IEEE transactions on neural networks and learning systems, 29(5):1454–1466, 2017
2017
-
[21]
Hessian eigenspectra of more realistic nonlinear models
Zhenyu Liao and Michael W Mahoney. Hessian eigenspectra of more realistic nonlinear models. Advances in Neural Information Processing Systems, 34:20104–20117, 2021
2021
-
[22]
Hong Liu, Zhiyuan Li, David Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training.arXiv preprint arXiv:2305.14342, 2023
-
[23]
New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
James Martens. New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
2020
-
[24]
Optimizing neural networks with kronecker-factored approx- imate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approx- imate curvature. InInternational conference on machine learning, pages 2408–2417. PMLR, 2015
2015
-
[25]
Learning recurrent neural networks with Hessian-free optimization
James Martens and Ilya Sutskever. Learning recurrent neural networks with Hessian-free optimization. InProceedings of the 28th international conference on machine learning (ICML- 11), pages 1033–1040, 2011
2011
-
[26]
Deep learning via Hessian-free optimization
James Martens et al. Deep learning via Hessian-free optimization. InICML, volume 27, pages 735–742, 2010. 12
2010
-
[27]
Nocedal and S
J. Nocedal and S. Wright.Numerical Optimization. Springer Series in Operations Research and Financial Engineering. Springer New York, 2006. ISBN 9780387400655
2006
-
[28]
The full spectrum of deep net Hessians at scale: Dynamics with sample size
Vardan Papyan. The full spectrum of deep net Hessians at scale: Dynamics with sample size. arXiv preprint arXiv:1811.07062, 2018
-
[29]
Fast exact multiplication by the hessian.Neural computation, 6(1): 147–160, 1994
Barak A Pearlmutter. Fast exact multiplication by the hessian.Neural computation, 6(1): 147–160, 1994
1994
-
[30]
Yi Ren and Donald Goldfarb. Efficient subsampled gauss-newton and natural gradient methods for training neural networks.arXiv preprint arXiv:1906.02353, 2019
-
[31]
In defense of one-vs-all classification.Journal of machine learning research, 5(Jan):101–141, 2004
Ryan Rifkin and Aldebaro Klautau. In defense of one-vs-all classification.Journal of machine learning research, 5(Jan):101–141, 2004
2004
-
[32]
A convergence theorem for non negative almost supermartingales and some applications
Herbert Robbins and David Siegmund. A convergence theorem for non negative almost supermartingales and some applications. InOptimizing methods in statistics, pages 233–257. Elsevier, 1971
1971
-
[33]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Levent Sagun, Utku Evci, V Ugur Guney, Yann Dauphin, and Leon Bottou. Empirical analysis of the hessian of over-parametrized neural networks.arXiv preprint arXiv:1706.04454, 2017
work page Pith review arXiv 2017
-
[34]
A deeper look at the Hessian eigenspectrum of deep neural networks and its applications to regularization
Adepu Ravi Sankar, Yash Khasbage, Rahul Vigneswaran, and Vineeth N Balasubramanian. A deeper look at the Hessian eigenspectrum of deep neural networks and its applications to regularization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 9481–9488, 2021
2021
-
[35]
Fast curvature matrix-vector products for second-order gradient descent
Nicol N Schraudolph. Fast curvature matrix-vector products for second-order gradient descent. Neural computation, 14(7):1723–1738, 2002
2002
-
[36]
Investigations on Hessian-free optimization for cross- entropy training of deep neural networks
Simon Wiesler, Jinyu Li, and Jian Xue. Investigations on Hessian-free optimization for cross- entropy training of deep neural networks. InInterspeech, pages 3317–3321, 2013
2013
-
[37]
On the power-law hessian spectrums in deep learning, 2022
Zeke Xie, Qian-Yuan Tang, Yunfeng Cai, Mingming Sun, and Ping Li. On the power-law hessian spectrums in deep learning, 2022. URLhttps://arxiv.org/abs/2201.13011
-
[38]
Adahessian: An adaptive second order optimizer for machine learning
Zhewei Yao, Amir Gholami, Sheng Shen, Mustafa Mustafa, Kurt Keutzer, and Michael Mahoney. Adahessian: An adaptive second order optimizer for machine learning. Inproceedings of the AAAI conference on artificial intelligence, volume 35, pages 10665–10673, 2021. A Related Work This appendix reviews prior work through the lens of the paper’s central technical...
2021
-
[39]
∞∑ t=0 αt E [ ∥∇R(wt)∥2] <∞;(D.26)
the sequence{R(wt)}converges almost surely to a finite random variable; 2. ∞∑ t=0 αt E [ ∥∇R(wt)∥2] <∞;(D.26)
-
[40]
in particular, lim inf t→∞ E [ ∥∇R(wt)∥2] = 0.(D.27) Proof.ByL g-smoothness ofR, R(wt+1)≤R(wt) +∇R(wt)⊤(wt+1−wt) +Lg 2∥wt+1−wt∥2.(D.28) Substitutingw t+1−wt =−αtPtgt gives R(wt+1)≤R(wt)−αt∇R(wt)⊤Ptgt + Lgα2 t 2 ∥Ptgt∥2.(D.29) Taking conditional expectation givenFt and using Assumption D.2 yields E [ R(wt+1)|Ft ] ≤R(wt)−αt∇R(wt)⊤Pt∇R(wt) +Lgα2 t 2 E [ ∥Ptg...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.