Recognition: 2 theorem links
· Lean TheoremBoostLLM: Boosting-inspired LLM Fine-tuning for Few-shot Tabular Classification
Pith reviewed 2026-05-12 03:22 UTC · model grok-4.3
The pith
BoostLLM recasts parameter-efficient LLM fine-tuning as a boosting process that trains sequential adapters on residuals and adds decision-tree paths as an auxiliary input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
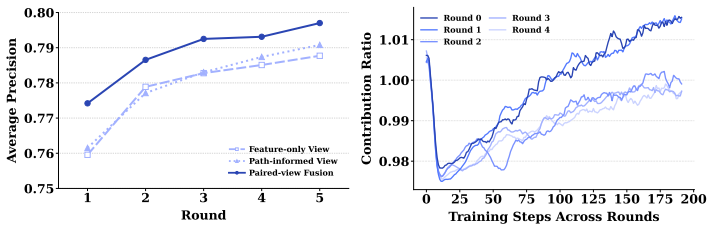
BoostLLM transforms parameter-efficient fine-tuning into a multi-round residual optimization process by training sequential adapters as weak learners while feeding decision-tree paths as a second input view; the path view supplies structured inductive bias that guides early steps before the model transitions to feature-driven learning, yielding consistent gains over standard fine-tuning that match or surpass XGBoost across shot counts and outperform GPT-4o methods with a 4B model.
What carries the argument
Sequential parameter-efficient adapters trained as weak learners on residuals, with decision-tree paths supplied as an auxiliary input view that provides early structured guidance.
If this is right
- Performance improvements appear across multiple LLM backbones and tabular datasets.
- The path view functions as an early teacher that later gives way to raw-feature representations.
- Gains increase when stronger tree models or longer boosting horizons are used, provided stabilization is applied.
- A 4B model under this regime can exceed GPT-4o-based methods on few-shot tabular tasks.
Where Pith is reading between the lines
- The residual-adapter pattern could be tested on other structured modalities or non-classification tasks where data is scarce.
- Hybrid tree-derived signals might help stabilize fine-tuning in other low-resource LLM settings beyond tabular data.
- One could measure whether the observed shift from path-guided to feature-driven learning occurs at predictable training steps across different datasets.
Load-bearing premise
The boosting idea of sequential residual correction transfers stably to LLM adapters and decision-tree paths supply a reliable early teacher signal without causing instability or harming later feature learning.
What would settle it
An ablation that removes either the residual training schedule or the decision-tree path inputs and shows no remaining advantage over ordinary single-round fine-tuning on the same datasets and backbones.
Figures




read the original abstract
Large language models (LLMs) have recently been adapted to tabular prediction by serializing structured features into natural language, but their performance in low-data regimes remains limited compared to gradient-boosted decision trees (GBDTs). In this work, we revisit the boosting paradigm, traditionally associated with tree ensembles, and ask whether it can be applied as a general training principle for LLM fine-tuning. We propose BoostLLM, a framework that transforms parameter-efficient fine-tuning into a multi-round residual optimization process by training sequential PEFT adapters as weak learners. To incorporate tabular inductive bias, BoostLLM integrates decision-tree paths as a second input view alongside raw features; analysis reveals that the path view acts as a structured teacher in early training steps before the model shifts toward feature-driven representations. Empirically, BoostLLM achieves consistent improvements over standard fine-tuning across multiple LLM backbones and datasets, matching or surpassing XGBoost across a wide range of shot counts and outperforming GPT-4o-based methods with a 4B model. We further show that the framework scales: pairing with stronger tree models and extended boosting horizons yields additional gains under appropriate stabilization. These results suggest that boosting can serve as a general training principle for LLM fine-tuning, particularly in low-data regimes for structured data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BoostLLM, a framework that transfers the boosting paradigm to LLM parameter-efficient fine-tuning for few-shot tabular classification. Sequential PEFT adapters are trained as weak learners in a multi-round residual optimization process, with decision-tree paths provided as a second input view that serves as a structured teacher signal in early rounds before the model shifts to feature-driven learning. The work reports consistent gains over standard fine-tuning across LLM backbones and datasets, matching or surpassing XGBoost across shot counts, and outperforming GPT-4o-based methods using a 4B model; it also shows scaling benefits when paired with stronger trees and longer horizons.
Significance. If the core mechanism holds, the result would be significant for low-data tabular learning: it offers a principled way to adapt boosting-style residual fitting to PEFT, potentially closing the gap between LLMs and GBDTs where standard fine-tuning falls short. The path-view analysis and multi-backbone empirical scope are constructive contributions. Credit is due for the explicit attempt to make boosting a general training principle rather than an ad-hoc multi-stage procedure.
major comments (2)
- [§3.2] §3.2 (multi-round training procedure): the description of residual optimization must include the precise target for the k-th adapter (e.g., an equation showing logit or probability residuals from the current ensemble). If each adapter instead minimizes standard cross-entropy on the original labels, the reported gains could arise from extra optimization steps or the auxiliary path input alone, undermining the claim that boosting serves as the operative training principle.
- [§4.2] §4.2 and Table 2 (main results): the comparison to XGBoost and GPT-4o requires explicit confirmation that the same few-shot data splits, feature serialization, and evaluation protocol are used; without this, the claim of matching or surpassing XGBoost across shot counts cannot be assessed as a fair head-to-head test of the boosting transfer.
minor comments (2)
- [Figure 3] Figure 3 (path-view transition analysis): the metric used to quantify the shift from path-driven to feature-driven representations should be stated explicitly in the caption or text.
- [§5] §5 (scaling experiments): the stabilization techniques applied when extending the boosting horizon are mentioned but not detailed; a short algorithmic box or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
Thank you for the detailed review and the positive assessment of the significance of our work. We appreciate the suggestions for improving the clarity of the boosting mechanism and the fairness of the comparisons. We address the major comments point by point below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (multi-round training procedure): the description of residual optimization must include the precise target for the k-th adapter (e.g., an equation showing logit or probability residuals from the current ensemble). If each adapter instead minimizes standard cross-entropy on the original labels, the reported gains could arise from extra optimization steps or the auxiliary path input alone, undermining the claim that boosting serves as the operative training principle.
Authors: We agree that an explicit mathematical formulation of the residual target is necessary to substantiate the boosting claim. In the revised manuscript, we will include an equation in Section 3.2 that defines the target for the k-th adapter as the residual (specifically, the difference between the current ensemble's output and the target, or equivalently the negative gradient of the loss) from the previous rounds. This will distinguish our approach from merely performing additional optimization steps or relying solely on the path input. The current description already indicates a multi-round residual optimization process, but we acknowledge the need for greater precision. revision: yes
-
Referee: [§4.2] §4.2 and Table 2 (main results): the comparison to XGBoost and GPT-4o requires explicit confirmation that the same few-shot data splits, feature serialization, and evaluation protocol are used; without this, the claim of matching or surpassing XGBoost across shot counts cannot be assessed as a fair head-to-head test of the boosting transfer.
Authors: We confirm that the comparisons in Section 4.2 and Table 2 employ identical few-shot data splits, feature serialization methods, and evaluation protocols as those used for our method and the baselines, as specified in the experimental setup in Section 4.1. To address this concern, we will add an explicit statement in Section 4.2 and a reference in the caption of Table 2 to ensure the fairness of the head-to-head comparison is clear to readers. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper presents BoostLLM as an empirical method that applies the boosting paradigm to sequential PEFT adapters for LLM fine-tuning on tabular data, incorporating tree-path views as an auxiliary signal. All central claims rest on reported performance comparisons across multiple backbones, datasets, and shot counts rather than any closed mathematical derivation, self-referential definition, or load-bearing self-citation. No equations reduce a prediction to a fitted input by construction, and the residual-optimization description is framed as an implementation choice whose effectiveness is tested experimentally rather than assumed. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Boosting can serve as a general training principle for LLM fine-tuning
- domain assumption Decision-tree paths act as a structured teacher in early training steps for tabular data
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBoostLLM trains a sequence of weak learners implemented as PEFT-adapted LLMs in a stage-wise manner, where each learner focuses on correcting the residual errors of the ensemble prediction formed by previous ones... Fr(c|xi) = Fr−1(c|xi) + η fr(c|xi)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt uncleardecision-tree paths as a second input view... path view acts as a structured teacher in early training steps before the model shifts toward feature-driven representations
Reference graph
Works this paper leans on
-
[1]
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Nikhil Abhyankar, Parshin Shojaee, and Chandan K Reddy. Llm-fe: Automated feature engi- neering for tabular data with llms as evolutionary optimizers.arXiv preprint arXiv:2503.14434, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2623–2631, 2019
work page 2019
-
[3]
Sarkis Badirli, Tianyu Liu, Gérard Biau, and V . Y . F. Tan. Grownet: Improving deep neural networks with gradient boosting. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[4]
Knowledge acquisition and explanation for multiat- tribute decision making
Marko Bohanec and Vladislav Rajkovic. Knowledge acquisition and explanation for multiat- tribute decision making. In8th International Workshop on Expert Systems and their Applications, pages 59–78, Avignon, France, 1988
work page 1988
-
[5]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
work page 2016
-
[6]
Tuan Dinh, Yuchen Zeng, Ruisu Zhang, Ziqian Lin, Michael Gira, Shashank Rajput, Jy-yong Sohn, Dimitris Papailiopoulos, and Kangwook Lee. Lift: Language-interfaced fine-tuning for non-language machine learning tasks.Advances in Neural Information Processing Systems, 35: 11763–11784, 2022
work page 2022
-
[7]
Seyedsaman Emami and Gonzalo Martínez-Muñoz. A gradient boosting approach for training convolutional and deep neural networks.IEEE Open Journal of Signal Processing, 4:313–321,
-
[8]
doi: 10.1109/OJSP.2023.3279011
-
[9]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, et al. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791, 2025
-
[10]
Jerome Friedman, Trevor Hastie, and Robert Tibshirani. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors).The Annals of Statistics, 28(2):337–407, 2000
work page 2000
-
[11]
Boyan Gao, Xin Wang, Yibo Yang, and David Clifton. Optimization-inspired few-shot adapta- tion for large language models.arXiv preprint arXiv:2505.19107, 2025
-
[12]
Josh Gardner, Juan C Perdomo, and Ludwig Schmidt. Large scale transfer learning for tabular data via language modeling.Advances in Neural Information Processing Systems, 37:45155– 45205, 2024
work page 2024
-
[13]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[14]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? InAdvances in Neural Information Processing Systems (NeurIPS Datasets and Benchmarks), 2022
work page 2022
-
[15]
Large language models can automatically engineer features for few-shot tabular learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, and Tomas Pfister. Large language models can automatically engineer features for few-shot tabular learning. InInternational Conference on Machine Learning, pages 17454–17479. PMLR, 2024
work page 2024
-
[16]
Tabllm: Few-shot classification of tabular data with large language models
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. Tabllm: Few-shot classification of tabular data with large language models. In International Conference on Artificial Intelligence and Statistics (AISTATS), 2023
work page 2023
-
[17]
Hans Hofmann. Statlog (german credit data). UCI Machine Learning Repository, 1994. URL https://doi.org/10.24432/C5NC77
-
[18]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[19]
Andras Janosi, William Steinbrunn, Matthias Pfisterer, and Robert Detrano. Heart disease. uci machine learning repository.UCI Machine Learning Repository, 1988. 10
work page 1988
-
[20]
Gjergji Kasneci and Enkelejda Kasneci. Enriching tabular data with contextual llm embeddings: A comprehensive ablation study for ensemble classifiers.arXiv preprint arXiv:2411.01645, 2024
-
[21]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
work page 2017
-
[22]
Ferg-llm: Feature en- gineering by reason generation large language models
Jeonghyun Ko, Gyeongyun Park, Donghoon Lee, and Kyunam Lee. Ferg-llm: Feature en- gineering by reason generation large language models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 4211–4228, 2025
work page 2025
-
[23]
Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid
Ron Kohavi. Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD), pages 202–207, 1996
work page 1996
-
[24]
Wen Lai, Alexander Fraser, and Ivan Titov. Joint localization and activation editing for low- resource fine-tuning.arXiv preprint arXiv:2502.01179, 2025
-
[25]
Baohao Liao and Christof Monz. 3-in-1: 2d rotary adaptation for efficient finetuning, efficient batching and composability.Advances in Neural Information Processing Systems, 37:35018– 35048, 2024
work page 2024
-
[26]
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[27]
Ruoxue Liu, Linjiajie Fang, Wenjia Wang, and Bing-Yi Jing. D2r2: Diffusion-based repre- sentation with random distance matching for tabular few-shot learning.Advances in Neural Information Processing Systems, 37:36890–36913, 2024
work page 2024
- [28]
-
[29]
David Mease and Abraham Wyner. Evidence contrary to the statistical view of boosting.Journal of Machine Learning Research, 9:131–156, 2008
work page 2008
-
[30]
Sérgio Moro, Paulo Cortez, and Paulo Rita. A data-driven approach to predict the success of bank telemarketing.Decision Support Systems, 62:22–31, 2014
work page 2014
-
[31]
Jaehyun Nam, Kyuyoung Kim, Seunghyuk Oh, Jihoon Tack, Jaehyung Kim, and Jinwoo Shin. Optimized feature generation for tabular data via llms with decision tree reasoning.Advances in neural information processing systems, 37:92352–92380, 2024
work page 2024
-
[32]
Tabular transfer learning via prompting llms
Jaehyun Nam, Woomin Song, Seong Hyeon Park, Jihoon Tack, Sukmin Yun, Jaehyung Kim, Kyu Hwan Oh, and Jinwoo Shin. Tabular transfer learning via prompting llms. InConference on Language Modeling (COLM), 2024
work page 2024
-
[33]
Stunt: Few-shot tabular learning with self-generated tasks
Joonseok Nam et al. Stunt: Few-shot tabular learning with self-generated tasks. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[34]
Anri Patron, Ayush Prasad, Hoang Phuc Hau Luu, and Kai Puolamà ¯Iki. Gradient boosting mapping for dimensionality reduction and feature extraction.arXiv preprint arXiv:2405.08486, 2024
-
[35]
Leveraging structural information in tree ensembles for table representation learning
Nikhil Pattisapu, Siva Rajesh Kasa, Sumegh Roychowdhury, Karan Gupta, Anish Bhanushali, and Prasanna Srinivasa Murthy. Leveraging structural information in tree ensembles for table representation learning. InCompanion Proceedings of the ACM on Web Conference 2025, pages 1244–1248, 2025
work page 2025
-
[36]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
work page 2018
-
[37]
Tabred: Analyzing pitfalls and filling the gaps in tabular deep learning benchmarks
Ivan Rubachev et al. Tabred: Analyzing pitfalls and filling the gaps in tabular deep learning benchmarks. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[38]
Using the adap learning algorithm to forecast the onset of diabetes mellitus
Jack W Smith, James E Everhart, William C Dickson, William C Knowler, and Robert Scott Johannes. Using the adap learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the annual symposium on computer application in medical care, page 261, 1988. 11
work page 1988
-
[39]
Aboozar Taherkhani, Georgina Cosma, and T. M. McGinnity. AdaBoost-CNN: An adaptive boosting algorithm for convolutional neural networks to classify multi-class imbalanced datasets using transfer learning.Neurocomputing, 404:351–366, 2020. doi: 10.1016/j.neucom.2020.03. 064
-
[40]
A data-centric perspective on evaluating machine learning models for tabular data
Anton Tschalzev et al. A data-centric perspective on evaluating machine learning models for tabular data. InAdvances in Neural Information Processing Systems (NeurIPS Datasets and Benchmarks), 2024
work page 2024
-
[41]
Endgame analysis of dou shou qi.ICGA journal, 37(2): 120–124, 2014
Jan N van Rijn and Jonathan K Vis. Endgame analysis of dou shou qi.ICGA journal, 37(2): 120–124, 2014
work page 2014
-
[42]
Functional frank-wolfe boosting for general loss functions.arXiv preprint arXiv:1510.02558, 2015
Chu Wang, Yingfei Wang, Robert Schapire, et al. Functional frank-wolfe boosting for general loss functions.arXiv preprint arXiv:1510.02558, 2015
-
[43]
Ruiyu Wang, Zifeng Wang, and Jimeng Sun. Unipredict: Large language models are universal tabular classifiers.arXiv preprint arXiv:2310.03266, 2023
-
[44]
From supervised to generative: A novel paradigm for tabular deep learning with large language models
Xumeng Wen, Han Zhang, Shun Zheng, Wei Xu, and Jiang Bian. From supervised to generative: A novel paradigm for tabular deep learning with large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3323–3333, 2024
work page 2024
-
[45]
Herun Xia et al. Ress: Learning reasoning models for tabular data prediction via symbolic scaffold.arXiv preprint arXiv:2505.00562, 2025
-
[46]
Adarank: a boosting algorithm for information retrieval
Jun Xu and Hang Li. Adarank: a boosting algorithm for information retrieval. InProceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval, pages 391–398, 2007
work page 2007
-
[47]
Making pre-trained language models great on tabular prediction
Jiahuan Yan, Bo Zheng, Hongxia Xu, Yiheng Zhu, Danny Z Chen, Jimeng Sun, Jian Wu, and Jintai Chen. Making pre-trained language models great on tabular prediction. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Can Yaras, Peng Wang, Laura Balzano, and Qing Qu. Compressible dynamics in deep overpa- rameterized low-rank learning & adaptation.arXiv preprint arXiv:2406.04112, 2024
-
[50]
A closer look at deep learning methods on tabular datasets, 2025
Han-Jia Ye, Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and De-Chuan Zhan. A closer look at deep learning methods on tabular datasets.arXiv preprint arXiv:2407.00956, 2024
-
[51]
Llm meeting decision trees on tabular data.arXiv preprint arXiv:2505.17918, 2025
Hangting Ye, Jinmeng Li, He Zhao, Dandan Guo, and Yi Chang. Llm meeting decision trees on tabular data.arXiv preprint arXiv:2505.17918, 2025
-
[52]
Blood transfusion service center
I-Cheng Yeh. Blood transfusion service center. UCI Machine Learning Repository, 2008. URL https://doi.org/10.24432/C5GS39
-
[53]
Cat.” indicates language-heavy (lang) or OCR/document (ocr) sources. “%>1024
Biao Zhang, Paul Suganthan, Gaël Liu, Ilya Philippov, Sahil Dua, Ben Hora, Kat Black, Gus Martins, Omar Sanseviero, Shreya Pathak, et al. T5gemma 2: Seeing, reading, and understanding longer.arXiv preprint arXiv:2512.14856, 2025
-
[54]
J. Zhang et al. One LLM is not enough: Harnessing the power of ensemble learning for medical question answering.medRxiv, 2023. URL https://www.medrxiv.org/content/10.1101/ 2023.12.21.23300380v1
work page 2023
-
[55]
Bingchen Zhao, Haoqin Tu, Chen Wei, Jieru Mei, and Cihang Xie. Tuning layernorm in attention: Towards efficient multi-modal LLM finetuning. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=YR3ETaElNK. 12 A Decision-Path Compression Example We provide a concrete example of the decision-path compr...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.