Recognition: unknown
One Algorithm, Two Goals: Dual Scoring for Parameter and Data Selection in LLM Fine-Tuning
Pith reviewed 2026-05-08 13:37 UTC · model grok-4.3
The pith
Parameter importance and data utility for LLM fine-tuning both emerge as column-wise and row-wise sums from one shared gradient interaction matrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
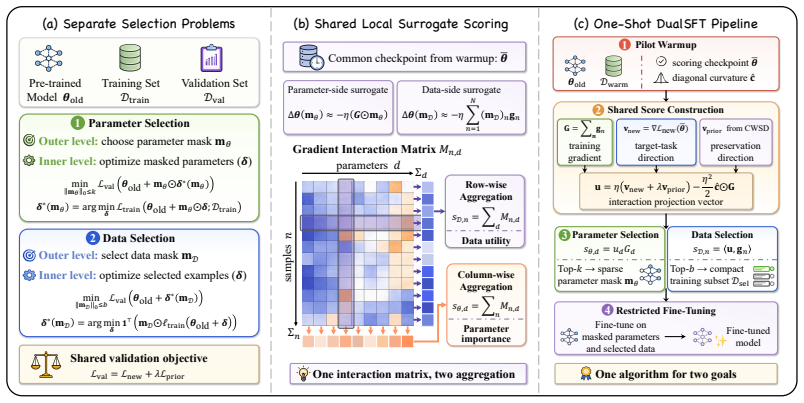
Under first- and second-order validation-improvement approximations, parameter importance and data utility emerge as column-wise and row-wise aggregations of a single gradient interaction matrix, yielding a closed-form row-column correspondence for co-extracting both signals. Building on this structure, DualSFT produces a parameter mask and data subset from shared gradient statistics in one shot.
What carries the argument
The gradient interaction matrix, whose column-wise sums yield parameter importance scores and whose row-wise sums yield data utility scores.
If this is right
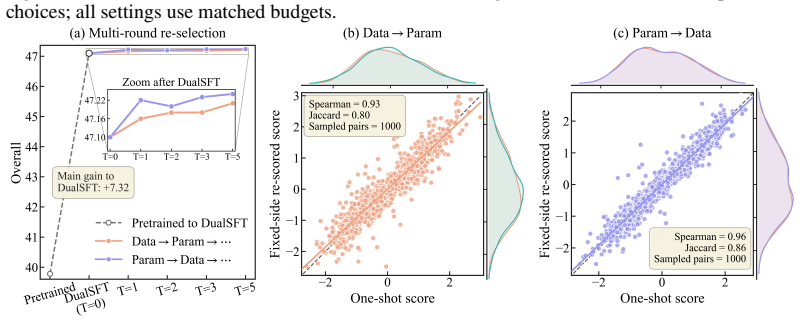
- Single-axis DualSFT variants raise target-task performance and improve stability-plasticity trade-offs within their comparison groups.
- Full DualSFT produces a more favorable joint-constrained trade-off than sequential hybrid baselines under identical budgets.
- The shared matrix eliminates redundant gradient computations that separate parameter and data scorers normally require.
- Closed-form row-column correspondence allows simultaneous extraction without iterative re-scoring.
Where Pith is reading between the lines
- The same matrix structure could be reused for other paired selection tasks such as pruning plus quantization or task selection plus model selection.
- If the first-order term dominates in practice, even cheaper first-order-only variants might retain most of the benefit on larger models.
- The approach might extend to continual learning settings where both parameter retention and replay data choice must be decided together.
Load-bearing premise
The first- and second-order approximations of validation improvement remain accurate enough for the bilevel selection problems that appear in restricted fine-tuning.
What would settle it
Measure actual validation loss reduction after fine-tuning with the DualSFT mask and subset versus the reduction predicted by the matrix aggregations; a large mismatch would show the approximations have broken down.
Figures







read the original abstract
In Large Language Model (LLM) fine-tuning, parameter and data selection are common strategies for reducing fine-tuning cost, yet they are typically driven by separate scoring mechanisms. When a parameter mask and data subset jointly determine restricted fine-tuning, this separation incurs redundant overhead and makes coordinated selection difficult. We cast parameter and data selection as two bilevel selection problems under a common validation objective and derive a shared local response-surrogate scoring rule. Under first- and second-order validation-improvement approximations, parameter importance and data utility emerge as column-wise and row-wise aggregations of a single gradient interaction matrix, yielding a closed-form row-column correspondence for co-extracting both signals. Building on this structure, we propose DualSFT (Dual-Selection Fine-Tuning), a one-shot dual-scoring algorithm that produces a parameter mask and data subset from shared gradient statistics. On 3B-9B LLMs, single-axis DualSFT variants strengthen target-task performance and stability-plasticity trade-offs within their comparison groups, while full DualSFT yields a more favorable joint-constrained trade-off than sequential hybrid baselines under matched budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that parameter and data selection in LLM fine-tuning can be unified via a single gradient interaction matrix derived from first- and second-order approximations of validation improvement. Under these local surrogates, parameter importance scores arise as column-wise aggregations and data utility scores as row-wise aggregations, enabling a one-shot DualSFT algorithm that jointly extracts both signals and yields improved task performance and stability-plasticity trade-offs compared to sequential baselines on 3B-9B models.
Significance. If the approximations hold, the work provides an efficient, closed-form unification of two common fine-tuning reduction strategies under a shared bilevel objective, reducing redundant computation while improving joint-constrained outcomes. The reported empirical gains on models up to 9B parameters, including stronger single-axis variants and favorable full DualSFT trade-offs, constitute a practical strength that could be extended if the surrogate fidelity is confirmed.
major comments (2)
- Abstract and derivation of the scoring rule: the central row-column correspondence is obtained only under first- and second-order Taylor approximations of the validation objective; no direct quantification of the approximation error (e.g., ||actual post-selection validation change - surrogate prediction||) or comparison against exact bilevel optimization is provided, leaving the load-bearing link between the gradient interaction matrix and the claimed co-extraction unverified in non-convex LLM landscapes.
- §4 (empirical evaluation): while gains versus sequential hybrids are shown under matched budgets, there is no ablation of approximation order (first vs. second) nor measurement of how the one-shot mask/subset alters the subsequent optimization trajectory relative to the assumed local surrogate, which is required to substantiate that the bilevel coupling does not amplify higher-order terms.
minor comments (2)
- Notation section: the gradient interaction matrix entries should be given an explicit equation number and a short derivation sketch to clarify how the row and column aggregations are computed from the same statistics.
- Experimental tables: add error bars or multiple random seeds for the reported performance and stability metrics to allow assessment of whether the observed improvements are statistically reliable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the work's significance. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: Abstract and derivation of the scoring rule: the central row-column correspondence is obtained only under first- and second-order Taylor approximations of the validation objective; no direct quantification of the approximation error (e.g., ||actual post-selection validation change - surrogate prediction||) or comparison against exact bilevel optimization is provided, leaving the load-bearing link between the gradient interaction matrix and the claimed co-extraction unverified in non-convex LLM landscapes.
Authors: We agree that the row-column correspondence is derived under local first- and second-order Taylor approximations of the validation objective, as is standard for rendering bilevel selection tractable in high-dimensional non-convex settings. Exact bilevel optimization remains computationally prohibitive for LLMs, which is why the surrogate approach is adopted. The empirical gains on 3B-9B models provide indirect support for the utility of the gradient interaction matrix. To directly address the concern, we will add a new subsection in the theoretical analysis discussing the approximation assumptions and their potential limitations in non-convex landscapes. We will also include a targeted experiment on a smaller-scale model to quantify surrogate prediction error by comparing predicted versus actual post-selection validation changes. revision: yes
-
Referee: §4 (empirical evaluation): while gains versus sequential hybrids are shown under matched budgets, there is no ablation of approximation order (first vs. second) nor measurement of how the one-shot mask/subset alters the subsequent optimization trajectory relative to the assumed local surrogate, which is required to substantiate that the bilevel coupling does not amplify higher-order terms.
Authors: We concur that an ablation on approximation order and trajectory analysis would provide stronger substantiation. In the revised manuscript, we will expand the empirical section with an ablation comparing first-order, second-order, and combined scoring variants under identical budgets. We will additionally report optimization trajectory metrics, including validation loss curves and stability-plasticity indicators during fine-tuning, to examine how the one-shot selections interact with the assumed local surrogate and to check for amplification of higher-order effects. revision: yes
Circularity Check
Derivation from Taylor approximations is self-contained and independent
full rationale
The paper derives the dual-scoring rule by applying first- and second-order Taylor expansions directly to the validation-improvement objective and then extracting row- and column-wise aggregations of the resulting gradient interaction matrix. This is a standard local-surrogate construction whose output follows mathematically from the chosen expansion order and the definition of the bilevel objective; it does not rename a fitted quantity as a prediction, invoke a self-citation as the sole justification, or smuggle an ansatz through prior work. No load-bearing step reduces to its own inputs by construction. The computation of the matrix on training data is the usual prerequisite for any gradient-based method and does not create circular dependence on the final selection masks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption First- and second-order approximations of validation-improvement are valid for the bilevel parameter and data selection problems
Reference graph
Works this paper leans on
-
[1]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remez et al., “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Llemma: An open language model for mathematics,
Z. Azerbayev, H. Schoelkopf, K. Paster, M. D. Santos, S. M. McAleer, A. Q. Jiang, J. Deng, S. Biderman, and S. Welleck, “Llemma: An open language model for mathematics,” in The Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge
Y . Li, Z. Li, K. Zhang, R. Dan, S. Jiang, and Y . Zhang, “Chatdoctor: A medical chat model fine- tuned on a large language model meta-ai (llama) using medical domain knowledge,” arXiv preprint arXiv:2303.14070, 2023
-
[4]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P . Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in International Conference on Learning Representations , 2022
2022
-
[5]
QLoRA: Efficient finetuning of quantized LLMs,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized LLMs,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[6]
PiCa: Parameter-Efficient Fine-Tuning with Column Space Projection
J. Hwang, W. Cho, and T. Kim, “Pica: Parameter-efficient fine-tuning with column space projection,” arXiv preprint arXiv:2505.20211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
QWHA: Quantization-aware walsh-hadamard adapta- tion for parameter-efficient fine-tuning on large language models,
H. Jeon, S. Lee, B. Kang, Y . Kim, and J.-J. Kim, “QWHA: Quantization-aware walsh-hadamard adapta- tion for parameter-efficient fine-tuning on large language models,” in The Fourteenth International Con- ference on Learning Representations, 2026
2026
-
[8]
Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment,
L. Xu, H. Xie, S. J. Qin, X. Tao, and F. L. Wang, “Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[9]
Parameter-efficient tuning with special token adaptation,
X. Y ang, J. Y . Huang, W. Zhou, and M. Chen, “Parameter-efficient tuning with special token adaptation,” in Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, 2023, pp. 865–872
2023
-
[10]
Multitask prompt tuning enables parameter-efficient transfer learning,
Z. Wang, R. Panda, L. Karlinsky, R. Feris, H. Sun, and Y . Kim, “Multitask prompt tuning enables parameter-efficient transfer learning,” in The Eleventh International Conference on Learning Represen- tations, 2023
2023
-
[11]
Galore: Memory-efficient LLM training by gradient low-rank projection,
J. Zhao, Z. Zhang, B. Chen, Z. Wang, A. Anandkumar, and Y . Tian, “Galore: Memory-efficient LLM training by gradient low-rank projection,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[12]
DoRA: Weight-decomposed low-rank adaptation,
S. yang Liu, C.- Y . Wang, H. Yin, P . Molchanov, Y .-C. F. Wang, K.-T. Cheng, and M.-H. Chen, “DoRA: Weight-decomposed low-rank adaptation,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[13]
Make pre-trained model reversible: From parameter to memory efficient fine-tuning,
B. Liao, S. Tan, and C. Monz, “Make pre-trained model reversible: From parameter to memory efficient fine-tuning,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[14]
SVFT: Parameter-efficient fine-tuning with singular vectors,
V . Lingam, A. T. Neerkaje, A. Vavre, A. Shetty, G. K. Gudur, J. Ghosh, E. Choi, A. Dimakis, A. Bo- jchevski, and S. Sanghavi, “SVFT: Parameter-efficient fine-tuning with singular vectors,” in 2nd Work- shop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Opti- mization (WANT@ICML 2024), 2024
2024
-
[15]
Increasing model capacity for free: A simple strategy for parameter efficient fine-tuning,
H. SONG, H. Zhao, S. Majumder, and T. Lin, “Increasing model capacity for free: A simple strategy for parameter efficient fine-tuning,” in The Twelfth International Conference on Learning Representations , 2024
2024
-
[16]
LESS: Selecting influential data for targeted instruction tuning,
M. Xia, S. Malladi, S. Gururangan, S. Arora, and D. Chen, “LESS: Selecting influential data for targeted instruction tuning,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[17]
Upweighting easy samples in fine-tuning mitigates forgetting,
S. Sanyal, H. Prairie, R. Das, A. Kavis, and S. Sanghavi, “Upweighting easy samples in fine-tuning mitigates forgetting,” in Forty-second International Conference on Machine Learning , 2025
2025
-
[18]
Skrull: Towards efficient long context fine-tuning through dynamic data scheduling,
H. Xu, W. Shen, Y . Wei, A. Wang, G. Runfan, T. Wang, Y . Li, M. Li, and W. Jia, “Skrull: Towards efficient long context fine-tuning through dynamic data scheduling,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[19]
Difficulty is not enough: Curriculum learning for llms fine-tuning must consider utility,
Z. Jiang, J. Han, T. Li, X. Wang, S. Jiang, X. Meng, J. Wei, J. Liang, and Y . Xiao, “Difficulty is not enough: Curriculum learning for llms fine-tuning must consider utility,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 37, 2026, pp. 31 365–31 373
2026
-
[20]
Deft-ucs: Data efficient fine-tuning for pre-trained language models via unsuper- vised core-set selection for text-editing,
D. Das and V . Khetan, “Deft-ucs: Data efficient fine-tuning for pre-trained language models via unsuper- vised core-set selection for text-editing,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 20 296–20 312
2024
-
[21]
DELIFT: Data efficient language model in- struction fine-tuning,
I. Agarwal, K. Killamsetty, L. Popa, and M. Danilevsky, “DELIFT: Data efficient language model in- struction fine-tuning,” in The Thirteenth International Conference on Learning Representations , 2025. 10
2025
-
[22]
Task-specific skill localization in fine-tuned language models,
A. Panigrahi, N. Saunshi, H. Zhao, and S. Arora, “Task-specific skill localization in fine-tuned language models,” in Proceedings of the 40th International Conference on Machine Learning , ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 23–29 Jul 2023, pp. 27 011–27 033
2023
-
[23]
Sparse is enough in fine-tuning pre-trained large language models,
W . Song, Z. Li, L. Zhang, H. Zhao, and B. Du, “Sparse is enough in fine-tuning pre-trained large language models,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[24]
S$^{2}$FT: Efficient, scalable and generalizable LLM fine-tuning by structured sparsity,
X. Y ang, J. Leng, G. Guo, J. Zhao, R. Nakada, L. Zhang, H. Y ao, and B. Chen, “S$^{2}$FT: Efficient, scalable and generalizable LLM fine-tuning by structured sparsity,” in The Thirty-eighth Annual Confer- ence on Neural Information Processing Systems , 2024
2024
-
[25]
LISA: Layerwise importance sampling for memory-efficient large language model fine-tuning,
R. Pan, X. Liu, S. Diao, R. Pi, J. Zhang, C. Han, and T. Zhang, “LISA: Layerwise importance sampling for memory-efficient large language model fine-tuning,” in The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[26]
SMT: Fine-tuning large language models with sparse matrices,
H. He, J. B. Li, X. Jiang, and H. Miller, “SMT: Fine-tuning large language models with sparse matrices,” in The Thirteenth International Conference on Learning Representations , 2025
2025
-
[27]
LIFT the veil for the truth: Principal weights emerge after rank reduction for reasoning-focused supervised fine-tuning,
Z. Liu, T. Pang, O. Balabanov, C. Y ang, T. Huang, L. Yin, Y . Y ang, and S. Liu, “LIFT the veil for the truth: Principal weights emerge after rank reduction for reasoning-focused supervised fine-tuning,” in Forty-second International Conference on Machine Learning , 2025
2025
-
[28]
Pay attention to small weights,
C. Zhou, T. Jacobs, A. Gadhikar, and R. Burkholz, “Pay attention to small weights,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
- [29]
-
[30]
Gast: Gradient-aligned sparse tuning of large language models with data-layer selection,
K. Y ao, Z. Song, K. Wu, M. Zhong, D. Cheng, Z. Tan, Y . Ji, and P . Gao, “Gast: Gradient-aligned sparse tuning of large language models with data-layer selection,” in Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , 2026, pp. 4401–4416
2026
-
[31]
FisherSFT: Data-efficient supervised fine-tuning of language models using information gain,
R. Deb, K. K. Thekumparampil, K. Kalantari, G. Hiranandani, S. Sabach, and B. Kveton, “FisherSFT: Data-efficient supervised fine-tuning of language models using information gain,” in Forty-second Inter- national Conference on Machine Learning , 2025
2025
-
[32]
Boosting multi-domain fine-tuning of large language models through evolving interactions between samples,
X. Liang, L. Y ang, J. Wang, Y . Lu, R. Wu, H. Chen, and J. HAO, “Boosting multi-domain fine-tuning of large language models through evolving interactions between samples,” in Forty-second International Conference on Machine Learning, 2025
2025
-
[33]
Joint selection for large-scale pre-training data via policy gradient-based mask learning,
Z. Fan, Y . Xian, Y . Sun, L. Shen, and K. Shen, “Joint selection for large-scale pre-training data via policy gradient-based mask learning,” in The Fourteenth International Conference on Learning Representations, 2026
2026
-
[34]
Gist: Targeted data selection for instruction tuning via coupled optimization geometry, 2026
G. Min, T. Huang, K. Wan, and C. Chen, “Gist: Targeted data selection for instruction tuning via coupled optimization geometry,” arXiv preprint arXiv:2602.18584, 2026
-
[35]
SPICE: Submodular penalized information–conflict selection for efficient large language model training,
P . Chang, J. Zhang, B. Chen, C. Wang, C. Guo, Y . Zhang, Y . Gao, J. Xiang, Y . Gao, C. Sun, Y . Chen, and D. Kong, “SPICE: Submodular penalized information–conflict selection for efficient large language model training,” in The Fourteenth International Conference on Learning Representations , 2026
2026
-
[36]
Tuning layernorm in attention: Towards efficient multi-modal LLM finetuning,
B. Zhao, H. Tu, C. Wei, J. Mei, and C. Xie, “Tuning layernorm in attention: Towards efficient multi-modal LLM finetuning,” in The Twelfth International Conference on Learning Representations , 2024
2024
-
[37]
SparseloRA: Accelerating LLM fine-tuning with contextual sparsity,
S. Khaki, X. Li, J. Guo, L. Zhu, K. N. Plataniotis, A. Y azdanbakhsh, K. Keutzer, S. Han, and Z. Liu, “SparseloRA: Accelerating LLM fine-tuning with contextual sparsity,” in Forty-second International Conference on Machine Learning, 2025
2025
-
[38]
Tr-pts: Task-relevant parameter and token selection for efficient tuning,
S. Luo, H. Y ang, Y . Xin, M. Yi, G. Wu, G. Zhai, and X. Liu, “Tr-pts: Task-relevant parameter and token selection for efficient tuning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4360–4369
2025
-
[39]
AI progress should be measured by capability-per-resource, not scale alone: A framework for gradient-guided resource allocation in LLMs,
D. McCoy, Y . Wu, and Z. Butzin-Dozier, “AI progress should be measured by capability-per-resource, not scale alone: A framework for gradient-guided resource allocation in LLMs,” in The Thirty-Ninth Annual Conference on Neural Information Processing Systems Position Paper Track, 2025
2025
-
[40]
Mitigating forgetting in LLM fine- tuning via low-perplexity token learning,
C.-C. Wu, Z. R. Tam, C.- Y . Lin, Y .-N. Chen, S.-H. Sun, and H. yi Lee, “Mitigating forgetting in LLM fine- tuning via low-perplexity token learning,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[41]
On the loss of context awareness in general instruction fine-tuning,
Y . Wang, A. Bai, N. Peng, and C.-J. Hsieh, “On the loss of context awareness in general instruction fine-tuning,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems , 2025
2025
-
[42]
Mapping post-training forgetting in language models at scale,
J. Harmon, A. Hochlehnert, M. Bethge, and A. Prabhu, “Mapping post-training forgetting in language models at scale,” in The Fourteenth International Conference on Learning Representations , 2026. 11
2026
-
[43]
Don’t make it up: Preserving ignorance awareness in LLM fine-tuning,
W . F. Shen, X. Qiu, N. Cancedda, and N. D. Lane, “Don’t make it up: Preserving ignorance awareness in LLM fine-tuning,” in NeurIPS 2025 Workshop: Reliable ML from Unreliable Data , 2025
2025
-
[44]
SFT doesn’t always hurt general capa- bilities: Revisiting domain-specific fine-tuning in LLMs,
J. Lin, Z. Wang, K. Qian, T. Wang, A. Srinivasan, H. Zeng, R. Jiao, X. Zhou, J. Gesi, D. Wang, Y . Guo, K. Zhong, W. Zhang, S. Sanghavi, C. Chen, H. Yun, and L. Li, “SFT doesn’t always hurt general capa- bilities: Revisiting domain-specific fine-tuning in LLMs,” in The Fourteenth International Conference on Learning Representations, 2026
2026
-
[45]
Mitigating catastrophic forgetting in large language models with forgetting-aware pruning,
W . Huang, A. Cheng, and Y . Wang, “Mitigating catastrophic forgetting in large language models with forgetting-aware pruning,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, 2025, pp. 21 853–21 867
2025
-
[46]
Magicoder: Empowering code generation with OSS- instruct,
Y . Wei, Z. Wang, J. Liu, Y . Ding, and L. ZHANG, “Magicoder: Empowering code generation with OSS- instruct,” in Forty-first International Conference on Machine Learning, 2024
2024
-
[47]
Metamath: Bootstrap your own mathematical questions for large language models,
L. Yu, W. Jiang, H. Shi, J. YU, Z. Liu, Y . Zhang, J. Kwok, Z. Li, A. Weller, and W. Liu, “Metamath: Bootstrap your own mathematical questions for large language models,” in The Twelfth International Conference on Learning Representations, 2024
2024
-
[48]
Lofit: Localized fine-tuning on LLM representations,
F. Yin, X. Y e, and G. Durrett, “Lofit: Localized fine-tuning on LLM representations,” in The Thirty- eighth Annual Conference on Neural Information Processing Systems , 2024
2024
-
[49]
Scaling sparse fine-tuning to large language models,
A. Ansell, I. Vulić, H. Sterz, A. Korhonen, and E. M. Ponti, “Scaling sparse fine-tuning to large language models,” arXiv preprint arXiv:2401.16405, 2024
-
[50]
Taso: Task-aligned sparse optimization for parameter-efficient model adaptation,
D. Miao, Y . Liu, J. Wang, C. Sun, Y . Zhang, D. Y an, S. Dong, Q. Zhang, and Y . Wu, “Taso: Task-aligned sparse optimization for parameter-efficient model adaptation,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , 2025, pp. 22 746–22 758
2025
-
[51]
S. Song, H. Xu, J. Ma, S. Li, L. Peng, Q. Wan, X. Liu, and J. Yu, “How to alleviate catastrophic forgetting in llms finetuning? hierarchical layer-wise and element-wise regularization,” arXiv preprint arXiv:2501.13669, 2025
-
[52]
Floe: Fisher-based layer selection for efficient sparse adaptation of low-rank experts,
X. Wang, L. Gao, H. Wang, Y . Zhang, and J. Zhao, “Floe: Fisher-based layer selection for efficient sparse adaptation of low-rank experts,” arXiv preprint arXiv:2506.00495, 2025
-
[53]
Hft: Half fine-tuning for large language models,
T. Hui, Z. Zhang, S. Wang, W. Xu, Y . Sun, and H. Wu, “Hft: Half fine-tuning for large language models,” in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 12 791–12 819
2025
-
[54]
Recurrent knowledge identification and fusion for language model continual learning,
Y . Feng, X. Wang, Z. Lu, S. Fu, G. Shi, Y . Xu, Y . Wang, P . S. Yu, X. Chu, and X.-M. Wu, “Recurrent knowledge identification and fusion for language model continual learning,” in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 2025, pp. 27 396–27 413
2025
-
[55]
Parameter importance-driven continual learning for foundation mod- els,
L. Wang, H. Zhang, and Z. Zheng, “Parameter importance-driven continual learning for foundation mod- els,” arXiv preprint arXiv:2511.15375, 2025
-
[56]
MODEL SHAPLEY : Find your ideal parameter player via one gradient backpropagation,
X. Chu, X. Jiang, R. Qiu, J. Gao, and J. Zhao, “MODEL SHAPLEY : Find your ideal parameter player via one gradient backpropagation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[57]
ShaploRA: Allocation of low-rank adaption on large language models via shapley value inspired importance estimation,
C. Zhao, Q. Y ao, X. Song, and W. Zhu, “ShaploRA: Allocation of low-rank adaption on large language models via shapley value inspired importance estimation,” in The Third Conference on Parsimony and Learning (Proceedings Track), 2026
2026
-
[58]
Pruning as a cooperative game: Surrogate- assisted layer contribution estimation for large language models,
X. Ding, P . Tong, R. Duan, Y . Zhang, R. Sun, and Y . Zhu, “Pruning as a cooperative game: Surrogate- assisted layer contribution estimation for large language models,” in The Fourteenth International Con- ference on Learning Representations, 2026
2026
-
[59]
Token cleaning: Fine-grained data selec- tion for LLM supervised fine-tuning,
J. Pang, N. Di, Z. Zhu, J. Wei, H. Cheng, C. Qian, and Y . Liu, “Token cleaning: Fine-grained data selec- tion for LLM supervised fine-tuning,” in Forty-second International Conference on Machine Learning , 2025
2025
-
[60]
Token-level data selection for safe LLM fine-tuning,
Y . Li, Z. Liu, Z. Li, Z. Lin, and J. Zhang, “Token-level data selection for safe LLM fine-tuning,” in The Fourteenth International Conference on Learning Representations, 2026
2026
-
[61]
sstoken: Self-modulated and semantic-aware token selection for LLM fine-tuning,
X. Qin, X. Wang, N. Liao, C. Zhang, X. Zhang, M. Feng, J. Wang, and J. Y an, “sstoken: Self-modulated and semantic-aware token selection for LLM fine-tuning,” in The Fourteenth International Conference on Learning Representations, 2026
2026
-
[62]
Train on validation (tov): Fast data selection with applications to fine-tuning,
A. Jain, A. Montanari, and E. Sasoglu, “Train on validation (tov): Fast data selection with applications to fine-tuning,” in The Fourteenth International Conference on Learning Representations , 2026
2026
-
[63]
MATES: Model-aware data selection for efficient pretraining with data influence models,
Z. Yu, S. Das, and C. Xiong, “MATES: Model-aware data selection for efficient pretraining with data influence models,” in The Thirty-eighth Annual Conference on Neural Information Processing Systems , 2024. 12
2024
-
[64]
Learn more, forget less: A gradient-aware data selection approach for llm,
Z. Liu, Y . Liu, S. Wang, Z. Song, J. Wang, J. Liu, Q. Liu, G. Chen, and Y . Wang, “Learn more, forget less: A gradient-aware data selection approach for llm,” Signal Processing, p. 110611, 2026
2026
-
[65]
SEAL: Safety-enhanced aligned LLM fine-tuning via bilevel data selection,
H. Shen, P .- Y . Chen, P . Das, and T. Chen, “SEAL: Safety-enhanced aligned LLM fine-tuning via bilevel data selection,” in The Thirteenth International Conference on Learning Representations , 2025
2025
-
[66]
Data shapley in one training run,
J. T. Wang, P . Mittal, D. Song, and R. Jia, “Data shapley in one training run,” in The Thirteenth Interna- tional Conference on Learning Representations , 2025
2025
-
[67]
CoIDO: Efficient data selection for visual instruc- tion tuning via coupled importance-diversity optimization,
Y . Y an, M. Zhong, Q. Zhu, X. Gu, J. Chen, and H. Li, “CoIDO: Efficient data selection for visual instruc- tion tuning via coupled importance-diversity optimization,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[68]
Diversity as a reward: Fine-tuning LLMs on a mixture of domain-undetermined data,
Z. Ling, D. Chen, L. Y ao, Q. Shen, Y . Li, and Y . Shen, “Diversity as a reward: Fine-tuning LLMs on a mixture of domain-undetermined data,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[69]
Matched data, better mod- els: Target aligned data filtering with sparse features,
A. M. Das, G. Bhatt, S. Verma, Y . Wang, V . V . Muppirala, and J. Bilmes, “Matched data, better mod- els: Target aligned data filtering with sparse features,” in The Fourteenth International Conference on Learning Representations, 2026
2026
-
[70]
PASER: Post-training data selection for efficient pruned large language model recovery,
B. He, L. Yin, H.-L. Zhen, X. Zhang, M. Yuan, and C. Ma, “PASER: Post-training data selection for efficient pruned large language model recovery,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[71]
LoRA learns less and forgets less,
D. Biderman, J. Portes, J. J. G. Ortiz, M. Paul, P . Greengard, C. Jennings, D. King, S. Havens, V . Chiley, J. Frankle, C. Blakeney, and J. P . Cunningham, “LoRA learns less and forgets less,” Transactions on Machine Learning Research, 2024
2024
-
[72]
CorDA: Context-oriented de- composition adaptation of large language models for task-aware parameter-efficient fine-tuning,
Y . Y ang, X. Li, Z. Zhou, S. L. Song, J. Wu, L. Nie, and B. Ghanem, “CorDA: Context-oriented de- composition adaptation of large language models for task-aware parameter-efficient fine-tuning,” in The Thirty-eighth Annual Conference on Neural Information Processing Systems , 2024
2024
-
[73]
Milora: Harnessing minor singular components for parameter-efficient llm finetuning,
H. Wang, Y . Li, S. Wang, G. Chen, and Y . Chen, “Milora: Harnessing minor singular components for parameter-efficient llm finetuning,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 4823–4836
2025
-
[74]
Lora-null: Low-rank adaptation via null space for large language models,
P . Tang, Y . Liu, D. Zhang, X. Wu, and D. Zhang, “Lora-null: Low-rank adaptation via null space for large language models,” arXiv e-prints arXiv:2503.02659, 2025
-
[75]
Sc-lora: Balancing efficient fine-tuning and knowledge preservation via subspace-constrained lora,
M. Luo, F. Kuang, Y . Wang, Z. Liu, and T. He, “Sc-lora: Balancing efficient fine-tuning and knowledge preservation via subspace-constrained lora,” arXiv preprint arXiv:2505.23724, 2025
-
[76]
Slim: Let llm learn more and forget less with soft lora and identity mixture,
J. Han, L. Du, H. Du, X. Zhou, Y . Wu, Y . Zhang, W. Zheng, and D. Han, “Slim: Let llm learn more and forget less with soft lora and identity mixture,” in Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 4792–4804
2025
-
[77]
MoFO: Momentum-filtered optimizer for mitigating forgetting in LLM fine-tuning,
Y . Chen, S. Wang, Y . Zhang, Z. Lin, H. Zhang, W. Sun, T. Ding, and R. Sun, “MoFO: Momentum-filtered optimizer for mitigating forgetting in LLM fine-tuning,” Transactions on Machine Learning Research , 2025, j2C Certification
2025
-
[78]
Loki: Low-damage knowledge implant- ing of large language models,
R. Wang, P . Ping, Z. Guo, X. Zhang, Q. Shi, L. Zhou, and T. Ji, “Loki: Low-damage knowledge implant- ing of large language models,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 40, no. 39, 2026, pp. 33 620–33 628
2026
-
[79]
Damoc: Efficiently selecting the optimal large language model for fine-tuning domain tasks based on data and model compression,
W . Huang, H. Wei, and Y . Wang, “Damoc: Efficiently selecting the optimal large language model for fine-tuning domain tasks based on data and model compression,” in Findings of the Association for Com- putational Linguistics: EMNLP 2025 , 2025, pp. 13 012–13 027
2025
-
[80]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P . Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in International conference on machine learning . PMLR, 2017, pp. 1126–1135
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.