Recognition: unknown
When Graph Language Models Go Beyond Memorization
Pith reviewed 2026-05-08 13:21 UTC · model grok-4.3
The pith
Graph language models acquire structural regularities beyond memorization at large scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
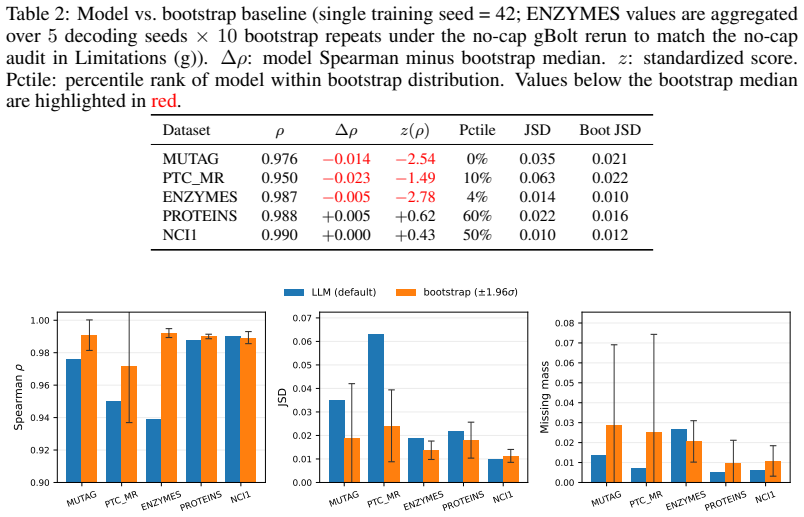
Using the new diagnostic, the authors establish that graph language models acquire structural regularities beyond memorization at scale, primarily for high-frequency patterns. This appears as high subgraph-rank correlations that the memorization bootstrap matches at small scale but cannot explain at large scale, with the novel-only subset analysis confirming that the alignment is not driven solely by recall of seen graphs. High-frequency subgraphs are reproduced reliably across scales while rare ones remain poorly covered with little gain from added capacity.
What carries the argument
The calibrated diagnostic protocol that combines frequent subgraph mining, a graph-level bootstrap baseline, and three-level frequency stratification to separate memorization effects from structural alignment.
If this is right
- Verbatim memorization drops sharply at large scale while rank correlation with structural patterns remains near ceiling.
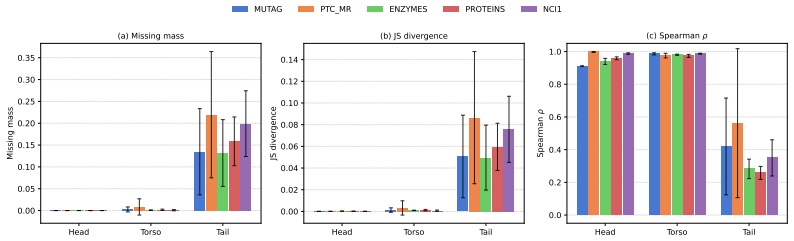
- High-frequency patterns are reproduced well at all scales; rare patterns stay poorly covered with only marginal improvement as capacity grows.
- The scale-dependent separation from memorization holds under both canonical DFS code and action-sequence graph serializations.
- On five TU benchmarks, models reach high subgraph-rank correlations that the bootstrap matches or exceeds at small scales.
Where Pith is reading between the lines
- Scaling may therefore be more effective for capturing common motifs than for covering the tail of rare structures.
- The same diagnostic protocol could be applied to sequence or tree generators to test whether similar scale-dependent generalization occurs.
- Data curation that balances subgraph frequencies might reduce the persistent gap for rare patterns.
Load-bearing premise
The graph-level bootstrap baseline correctly models pure verbatim recall without capturing any structural regularities on its own.
What would settle it
If frequent subgraph mining applied only to the novel-only generated graphs produced Spearman correlations that no longer tracked the full-set correlations at the 3.75-million-graph scale, the claim of structural learning beyond memorization would be falsified.
Figures




read the original abstract
It remains unclear whether graph language models learn structural regularities or merely memorize training graphs; this cannot be resolved by current aggregate fidelity metrics alone. We develop a calibrated diagnostic protocol that combines frequent subgraph mining, a graph-level bootstrap baseline, and three-level frequency stratification to disentangle memorization from structural alignment. Using this framework, we show that graph language models can acquire structural regularities beyond memorization at scale, primarily in the high-frequency regime. This is supported by the following empirical evidence: On five TU benchmarks, LLaMA-style graph language models reach high subgraph-rank correlation, yet their alignment is matched or exceeded by the memorization bootstrap in most cases. At small scale, under our bootstrap diagnostic, fidelity is largely indistinguishable from verbatim recall. In contrast, at large scale with 3.75M graphs, verbatim memorization drops sharply while rank correlation remains near ceiling. Crucially, in a separate fixed-subsample analysis, frequent subgraph mining restricted to the novel-only subset closely tracks the corresponding all-generation Spearman correlation, providing evidence that the alignment is not driven solely by verbatim recall. Across all scales, high-frequency patterns are well reproduced, while rare patterns remain poorly covered, and this deficit narrows only marginally as capacity increases. We observe the same scale-dependent crossover under two distinct graph serializations (canonical DFS code and action sequences), providing evidence of robustness in our analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a diagnostic protocol combining frequent subgraph mining, a graph-level bootstrap baseline, and three-level frequency stratification to test whether graph language models acquire structural regularities or merely memorize training graphs. On five TU benchmarks, it reports that LLaMA-style models achieve high subgraph-rank correlation that, at small scales, is matched by the memorization bootstrap, but at 3.75M graphs verbatim memorization drops sharply while rank correlation remains high; crucially, frequent subgraph mining on a novel-only subset tracks the all-generation Spearman correlation, with the pattern holding under two serializations and concentrated in the high-frequency regime.
Significance. If the central scale-dependent crossover holds, the work supplies concrete empirical evidence that graph LMs can move beyond verbatim recall toward structural alignment at sufficient scale, particularly for frequent patterns. The use of an external bootstrap and novel-subset controls, together with the reported rank correlations, strengthens the claim relative to aggregate fidelity metrics alone.
major comments (2)
- [Methods / Bootstrap definition] The graph-level bootstrap baseline (described in the methods and used for the small-scale vs. large-scale comparison) samples from training graphs without incorporating the model's learned distribution or the exact serialization constraints (DFS code or action sequences). This risks under-modeling the frequency-rank profile that pure verbatim recall would produce, which could artifactually produce the observed crossover at 3.75M graphs rather than demonstrate structural learning.
- [Results / Novel-subset FSM analysis] The novel-only subset analysis (fixed-subsample results) claims that FSM restricted to novel graphs tracks the full-set Spearman correlation. However, without explicit quantification of residual structural overlap (e.g., shared high-frequency subgraphs between novel test graphs and the training corpus), indirect leakage cannot be ruled out; this directly affects whether the alignment is shown to be non-memorized.
minor comments (2)
- [Abstract / Methods] Clarify the precise definition of 'verbatim memorization' versus 'rank correlation' and how the three-level frequency stratification is operationalized (e.g., exact thresholds for high/medium/rare).
- [Results] The manuscript states the same scale-dependent pattern holds under two serializations; include a direct side-by-side table or figure quantifying any differences in the crossover point or correlation values.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our diagnostic protocol for distinguishing memorization from structural learning in graph language models. We address each major comment below, offering clarifications on our methodological choices and committing to revisions where they strengthen the evidence.
read point-by-point responses
-
Referee: [Methods / Bootstrap definition] The graph-level bootstrap baseline (described in the methods and used for the small-scale vs. large-scale comparison) samples from training graphs without incorporating the model's learned distribution or the exact serialization constraints (DFS code or action sequences). This risks under-modeling the frequency-rank profile that pure verbatim recall would produce, which could artifactually produce the observed crossover at 3.75M graphs rather than demonstrate structural learning.
Authors: The bootstrap baseline is designed to provide a direct empirical estimate of the subgraph rank profile that would arise from verbatim recall of the training set, by resampling graphs from the training distribution. Because frequent subgraph mining operates on the underlying graph structures (independent of serialization), this approach captures the structural frequencies without introducing model-specific generative biases. We acknowledge that a bootstrap that also respects the exact serialization format used by the model could offer a more precise null model. To address this, we will perform an additional experiment in the revision where bootstrapped graphs are serialized using the same DFS code or action sequence format before mining, allowing us to compare the resulting rank correlations more closely to the model's output distribution. This will clarify whether the observed scale-dependent crossover is robust to these factors. revision: partial
-
Referee: [Results / Novel-subset FSM analysis] The novel-only subset analysis (fixed-subsample results) claims that FSM restricted to novel graphs tracks the full-set Spearman correlation. However, without explicit quantification of residual structural overlap (e.g., shared high-frequency subgraphs between novel test graphs and the training corpus), indirect leakage cannot be ruled out; this directly affects whether the alignment is shown to be non-memorized.
Authors: We recognize the importance of quantifying potential structural overlap to strengthen the claim that the alignment in the novel subset is not due to indirect leakage of frequent patterns from the training corpus. While the graphs in the novel subset are distinct from those in training, high-frequency subgraphs may indeed be shared across the dataset. In the revised manuscript, we will include a new analysis that computes the overlap (e.g., via set intersection or rank correlation of subgraph frequencies) between the frequent subgraphs mined from the novel-only subset and those from the training set, particularly focusing on the high-frequency regime. This addition will provide a more rigorous check on the extent of shared structure and support the interpretation of structural alignment beyond memorization. revision: yes
Circularity Check
No significant circularity in empirical diagnostic framework
full rationale
The paper's central claims rest on direct empirical measurements: subgraph rank correlations computed via frequent subgraph mining on model-generated graphs, compared against a graph-level bootstrap baseline that resamples from the training corpus to simulate verbatim recall, plus a fixed-subsample analysis restricted to novel-only generations. These quantities are independently observed from the data and controls rather than defined in terms of each other or fitted to produce the reported scale-dependent crossover. No self-definitional equations, fitted inputs renamed as predictions, load-bearing self-citations, imported uniqueness theorems, smuggled ansatzes, or renamings of known results appear in the derivation chain. The protocol is self-contained against external benchmarks and falsifiable via the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The graph-level bootstrap baseline using random or permuted graphs accurately models the output distribution expected from pure verbatim memorization.
Reference graph
Works this paper leans on
-
[1]
MolGPT: Molecular generation using a transformer-decoder model.Journal of Chemical Information and Modeling, 62(9):2064– 2076,
Viraj Bagal, Rishal Aggarwal, P K Vinod, and U Deva Priyakumar. MolGPT: Molecular generation using a transformer-decoder model.Journal of Chemical Information and Modeling, 62(9):2064– 2076,
2064
-
[3]
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi
URLhttps: //arxiv.org/abs/2502.02216. Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Talk like a graph: Encoding graphs for large language models. InInternational Conference on Learning Representations,
-
[4]
Graphgen: A scalable approach to domain- agnostic labeled graph generation
Nikhil Goyal, Harsh Vardhan Jain, and Sayan Ranu. Graphgen: A scalable approach to domain- agnostic labeled graph generation. InProceedings of The Web Conference 2020, pages 1253– 1263,
2020
-
[5]
Learning deep generative models of graphs.arXiv preprint arXiv:1803.03324, 2018
Yujia Li, Oriol Vinyals, Chris Dyer, Razvan Pascanu, and Peter W. Battaglia. Learning deep gener- ative models of graphs.arXiv preprint arXiv:1803.03324,
-
[6]
Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann
Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. TUDataset: A collection of benchmark datasets for learning with graphs. InICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+),
2020
-
[7]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review arXiv
-
[8]
Jiaxuan You, Bowen Liu, Rex Ying, Vijay Pande, and Jure Leskovec
doi: 10.1109/ICDM.2002.1184038. Jiaxuan You, Bowen Liu, Rex Ying, Vijay Pande, and Jure Leskovec. Graph convolutional pol- icy network for goal-directed molecular graph generation. InAdvances in Neural Information Processing Systems, 2018a. Jiaxuan You et al. Graphrnn: Generating realistic graphs with deep auto-regressive models. In Proceedings of the 35t...
-
[9]
URL https://arxiv.org/abs/2401.00529. Keren Zhou. gBolt: a C++ implementation of the gspan algorithm.https://github.com/ Jokeren/gBolt,
-
[10]
Reproducibility Statement We aim to make every reported number reproducible from the public companion repository
BSD 2-Clause License. Reproducibility Statement We aim to make every reported number reproducible from the public companion repository. Datasets.TU-benchmark graphs (MUTAG, ENZYMES, NCI1, PROTEINS, PTC_MR) are ob- tained through PyTorch Geometric’sTUDatasetloader using the canonical splits. PCQM4Mv2 is obtained from the OGB v1.3.5 release; we use the 2D-g...
2017
-
[11]
Mean / MaxL
Dataset Degree Clustering Orbit Spectral MUTAG 0.15 0.38 0.22 0.41 PTC_MR 0.04 0.01 0.16 0.36 ENZYMES 0.28 0.52 0.35 0.48 PROTEINS 0.24 0.45 0.30 0.52 NCI1 0.08 0.12 0.10 0.25 These low values are consistent with high memorization: if most generated graphs are exact copies of training graphs, their aggregate statistics will trivially match training statis...
2021
-
[12]
synchronization
J gSpan Minimum Support Sensitivity Table 17 contrastsσ= 0.1(the main-text default) with the more permissiveσ= 0.01on three TU datasets (MUTAG, ENZYMES, NCI1). Loweringσexposes more low-support patterns but leaves the qualitative conclusions (strong head alignment, degraded tail) intact, as discussed below. Table 17: Effect of gSpan minimum support ratio ...
2024
-
[13]
Head and Torsoρsit near0.91and0.97with much narrower CI, mirroring the saturation visible in the main-text single-seed results
is consistent with the seed-42 value (0.82) reported in Table 13: both lie within between-seed variance, and the wide CI is dominated by the small sample size (t0.975(1) = 12.7forn= 2). Head and Torsoρsit near0.91and0.97with much narrower CI, mirroring the saturation visible in the main-text single-seed results. A definitive seed-stability claim awaits th...
2024
-
[14]
Scaling memorization across training-set sizes.Table 29 contrasts the LLaMA-SMALLexact- match recall and distribution-alignment metrics across the five TU corpora and PCQM4Mv2 under the same architecture andboth_defaultdecoding, supporting the headline crossover of the main- text PCQM4Mv2 scaling (§6). Subsampled evaluation.Table 30 reports gSpan-based me...
2018
-
[15]
1.00/–” rows. “−
are provided for reference in the main paper. Memorization-based gSpan pattern Structural MMD Dataset Model Mem. rate Novelty SharedρJSD WL deg orb MUTAG DiGress 0.000 1.000 92 0.621 0.217 0.0780 0.00475 0.07332 MUTAG GraphRNN 0.000 1.000 16 0.063 0.554 0.2373 0.00023 0.00011 MUTAG DGMG-official 0.000 1.000 16 0.069 0.549 0.2216 0.00108 0.00163 PTC_MR DiG...
1934
-
[16]
ρ∩”: intersection Spearman, “ρtk
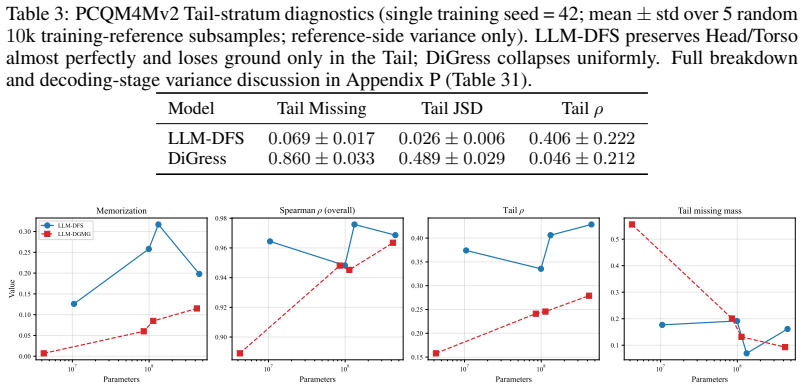
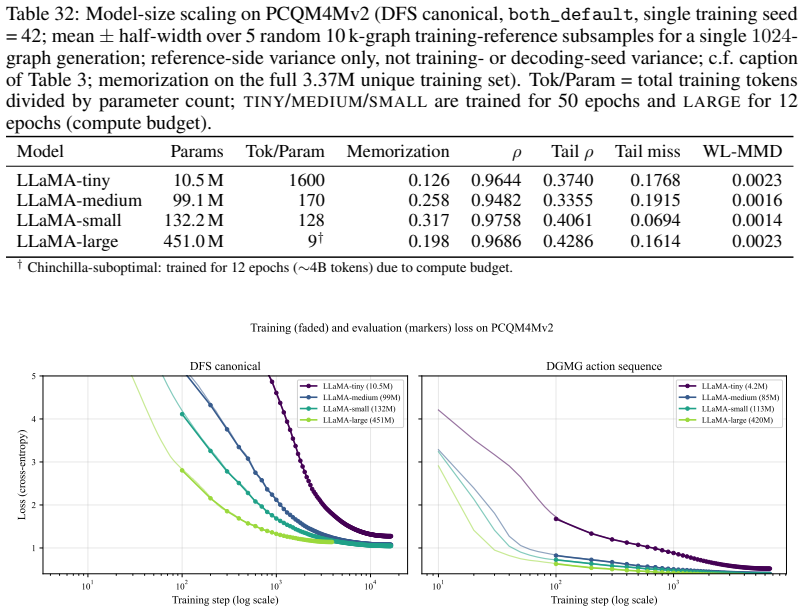
Subgraph-level alignment (ρ, JSD) and whole-graph similarity (WL-MMD) stay in narrow bands across the43×parameter range. Tail rank correlation improves with capacity, reaching its best value atLARGE(Tailρ≈0.43); theMEDIUMpoint (0.34) sits within two standard deviations ofTINYand does not break the upward trend. memorization and missing mass instead track ...
2024
-
[17]
All-genρ
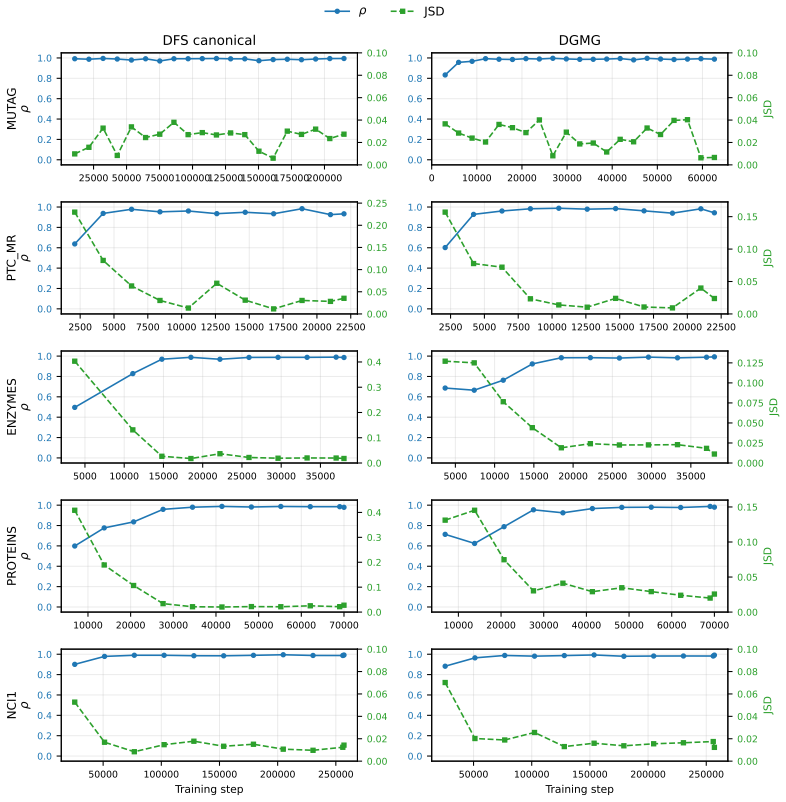
Left: DFS canonical (TINY/MEDIUM/SMALLshare a 50-epoch schedule,LARGEa 12-epoch schedule). Right: DGMG action sequence (TINY/MEDIUM/SMALLshare a 20-epoch schedule,LARGEa 12-epoch schedule). Loss separation by capacity is consistent across both serializations: larger models reach lower train and eval loss in every regime we examine. 103 104 Training step (...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.