Recognition: unknown
A Flow Matching Algorithm for Many-Shot Adaptation to Unseen Distributions
Pith reviewed 2026-05-08 13:08 UTC · model grok-4.3
The pith
FP-FM adapts flow matching models to new target distributions by projecting their velocity fields onto a basis learned from training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FP-FM learns basis functions to span the velocity fields corresponding to a set of training distributions, and adapts to new distributions by computing a simple least-squares projection onto this basis. This enables efficient generation of samples from diverse target distributions without additional training at inference time.
What carries the argument
Basis functions spanning velocity fields of training distributions, with new targets handled by least-squares coefficient projection.
If this is right
- Samples can be generated from new distributions at inference time with only a projection step and no model updates.
- Precision and recall improve over baselines on both synthetic and image datasets, with largest gains on unseen targets.
- Variants that let the projection coefficients depend on time trade higher expressivity for added compute.
- The same learned basis supports adaptation to many different target distributions without retraining.
Where Pith is reading between the lines
- Similar projection ideas could reduce adaptation cost in other velocity-based or score-based generative methods beyond flow matching.
- Precomputing a broad basis once from many training distributions might enable practical zero-shot adaptation pipelines.
- The linear-span assumption suggests testing whether low-dimensional bases suffice for entire families of image or sensor distributions.
Load-bearing premise
The velocity field of an unseen target distribution lies approximately inside the linear span of the basis functions learned from the training distributions.
What would settle it
A new distribution whose velocity field is nearly orthogonal to the learned basis produces generated samples whose statistics diverge sharply from the target.
Figures






read the original abstract
While generative modeling has achieved remarkable success on tasks like natural language-conditioned image generation, enabling model adaptation from example data points remains a relatively underexplored and challenging problem. To this end, we propose Function Projection for Flow Matching (FP-FM), an algorithm that directly conditions generation on samples from the target distribution. FP-FM learns basis functions to span the velocity fields corresponding to a set of training distributions, and adapts to new distributions by computing a simple least-squares projection onto this basis. This enables efficient generation of samples from diverse target distributions without additional training at inference time. We further introduce multiple variants of FP-FM that provide a trade-off in expressivity and compute by enriching the coefficient calculation, e.g., by making the coefficients dependent on time. FP-FM achieves greatly improved precision and recall relative to baselines across synthetic and image-based datasets, with especially strong gains on unseen distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Function Projection for Flow Matching (FP-FM), which learns a finite set of basis functions spanning the velocity fields of training distributions in a flow-matching generative model. For adaptation to new (unseen) target distributions, it computes coefficients via least-squares projection of the target velocity field onto this basis and generates samples without retraining. Variants are proposed that make the coefficients time-dependent to trade off expressivity against compute. Experiments on synthetic and image datasets report improved precision and recall relative to baselines, with particular gains on unseen distributions.
Significance. If the central span assumption holds with low projection error, FP-FM would offer a computationally lightweight mechanism for many-shot distribution adaptation in flow-based generative models, avoiding per-target fine-tuning. The approach is simple and leverages standard least-squares, which is a strength for reproducibility. However, the significance is tempered by the lack of direct evidence that the learned basis generalizes beyond the specific training distributions tested.
major comments (2)
- [§3] §3 (method): The core claim that adaptation succeeds for arbitrary unseen distributions rests on the unverified assumption that the required velocity field lies approximately in the linear span of the learned basis functions. No analysis, bound, or empirical measurement of the projection residual norm ||v_target - P_B v_target|| is provided for the test distributions; this is load-bearing because a large orthogonal component would produce incorrect flow trajectories.
- [§5] §5 (experiments): The abstract and results claim 'greatly improved precision and recall' and 'especially strong gains on unseen distributions,' yet no quantitative assessment of basis coverage (e.g., residual norms, effective rank of the basis, or diversity metrics between train and test distributions) is reported. Without these, the generality of the adaptation cannot be assessed, and the experimental setup details (number of basis functions, data splits, error bars, exact baselines) remain insufficient for verification.
minor comments (2)
- [Abstract] The abstract would benefit from a one-sentence statement of the key modeling assumption (linear span of velocity fields) to set reader expectations.
- [§3] Notation for the basis functions and the projection operator should be introduced with an explicit equation number in §3 for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (method): The core claim that adaptation succeeds for arbitrary unseen distributions rests on the unverified assumption that the required velocity field lies approximately in the linear span of the learned basis functions. No analysis, bound, or empirical measurement of the projection residual norm ||v_target - P_B v_target|| is provided for the test distributions; this is load-bearing because a large orthogonal component would produce incorrect flow trajectories.
Authors: We agree that an empirical measurement of the projection residual would directly support the span assumption. While the performance gains on unseen distributions provide indirect evidence that the basis is effective, we will add in the revision an analysis of ||v_target - P_B v_target|| for the test distributions, including residual norms for both seen and unseen cases and the effective rank of the basis matrix. A general theoretical bound for arbitrary distributions is not provided, as the method is empirical. revision: partial
-
Referee: [§5] §5 (experiments): The abstract and results claim 'greatly improved precision and recall' and 'especially strong gains on unseen distributions,' yet no quantitative assessment of basis coverage (e.g., residual norms, effective rank of the basis, or diversity metrics between train and test distributions) is reported. Without these, the generality of the adaptation cannot be assessed, and the experimental setup details (number of basis functions, data splits, error bars, exact baselines) remain insufficient for verification.
Authors: We will expand §5 to include all requested details: the number of basis functions, data splits, error bars from multiple runs, and exact baseline specifications. We will also report quantitative basis coverage metrics, including the residual norms, effective rank, and diversity measures (e.g., distribution distances) between train and test sets to better substantiate the generality claims. revision: yes
- A theoretical bound or guarantee that the velocity field of arbitrary unseen distributions lies approximately in the linear span of the basis learned from training distributions.
Circularity Check
No significant circularity; derivation relies on standard basis learning and projection without self-referential reduction.
full rationale
The FP-FM approach learns basis functions spanning velocity fields from a finite set of training distributions and performs least-squares projection for unseen targets. This chain is mathematically independent: the basis is fitted to training data, the projection is a standard linear algebra operation, and adaptation performance is evaluated empirically on held-out distributions rather than being forced by definition or prior self-citation. No step equates a prediction to its own fitted input, imports uniqueness via author overlap, or renames a known result as novel. The span assumption is an empirical hypothesis tested via metrics, not a tautology. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of basis functions
- time-dependence in coefficients
axioms (2)
- domain assumption Velocity fields of target distributions can be approximated as linear combinations of basis functions learned from training distributions
- domain assumption Least-squares projection yields valid velocity fields for sampling from the target distribution
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020
2020
-
[2]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InICLR. OpenReview.net, 2023
2023
-
[3]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InCVPR, pages 10674–10685. IEEE, 2022
2022
-
[4]
Understanding world or predicting future? A comprehensive survey of world models.ACM Comput
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, Fengli Xu, and Yong Li. Understanding world or predicting future? A comprehensive survey of world models.ACM Comput. Surv., 58(3): 57:1–57:38, 2026
2026
-
[5]
Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal M
Jake Bruce, Michael D. Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal M. P. Behbahani, Stephanie C. Y . Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott E. Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de F...
2024
-
[6]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with CLIP latents.CoRR, abs/2204.06125, 2022
work page internal anchor Pith review arXiv 2022
-
[7]
Denton, Seyed Kamyar Seyed Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Seyed Kamyar Seyed Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. InNeurIPS, 2022
2022
-
[8]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.CoRR, abs/2207.12598, 2022
work page internal anchor Pith review arXiv 2022
-
[9]
Thorpe, and Ufuk Topcu
Tyler Ingebrand, Adam J. Thorpe, and Ufuk Topcu. Function encoders: A principled approach to transfer learning in hilbert spaces. InICML, Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025
2025
-
[10]
Gradient-based learning applied to document recognition.Proc
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proc. IEEE, 86(11):2278–2324, 1998
1998
-
[11]
Bernstein, Alexander C
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Li Fei- Fei. Imagenet large scale visual recognition challenge.Int. J. Comput. Vis., 115(3):211–252, 2015
2015
-
[12]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat gans on image synthesis. InNeurIPS, pages 8780–8794, 2021. 10
2021
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review arXiv 2021
-
[14]
Improved precision and recall metric for assessing generative models
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. InNeurIPS, pages 3929–3938, 2019
2019
-
[15]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNIPS, pages 6626–6637, 2017
2017
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR. OpenReview.net, 2021
2021
-
[17]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748, 2022
work page internal anchor Pith review arXiv 2022
-
[18]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR. OpenReview.net, 2021
2021
-
[19]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR. OpenReview.net, 2023
2023
-
[20]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations, 2018
2018
-
[21]
Learning likelihoods with conditional normalizing flows.CoRR, abs/1912.00042,
Christina Winkler, Daniel E. Worrall, Emiel Hoogeboom, and Max Welling. Learning likeli- hoods with conditional normalizing flows.CoRR, abs/1912.00042, 2019
-
[22]
ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Karras, and Ming-Yu Liu. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers.CoRR, abs/2211.01324, 2022
-
[23]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In CVPR, pages 22500–22510. IEEE, 2023
2023
-
[24]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. InNeurIPS, pages 11895–11907, 2019
2019
-
[25]
Model-agnostic meta-learning for fast adapta- tion of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adapta- tion of deep networks. InICML, Proceedings of Machine Learning Research, pages 1126–1135. PMLR, 2017
2017
-
[26]
Marta Garnelo, Dan Rosenbaum, Christopher Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Yee Whye Teh, Danilo Jimenez Rezende, and S. M. Ali Eslami. Conditional neural processes. InICML, Proceedings of Machine Learning Research, pages 1690–1699. PMLR, 2018
2018
-
[27]
Harrison Edwards and Amos J. Storkey. Towards a neural statistician. InICLR, 2017
2017
- [28]
-
[29]
Henriques, Philip H
Luca Bertinetto, João F. Henriques, Philip H. S. Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers. InICLR (Poster). OpenReview.net, 2019
2019
-
[30]
Thorpe, and Ufuk Topcu
Tyler Ingebrand, Adam J. Thorpe, and Ufuk Topcu. Zero-shot transfer of neural odes. In NeurIPS, 2024. 11
2024
-
[31]
U-net: Convolutional networks for biomedical image segmentation
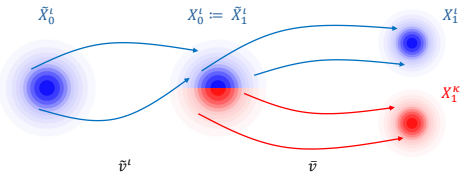
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI (3), Lecture Notes in Computer Science, pages 234–241. Springer, 2015. 12 A Derivation of Theorem 1 In this section, we show the derivation for Theorem 1, and additionally provide a diagram which makes the intuition clear. See Figu...
2015
-
[32]
Typically, this consists of the provided samples from the new distribution
1 |(1−t)n| p(x∗ 0)p(x1)dx1 R X 1 |(1−t)n| p(x∗ 0)p(x1)dx1 (20) = R X (x1 −x ∗ 0)p(x∗ 0)p(x1)dx1R X p(x∗ 0)p(x1)dx1 (21) =E X1[(X1 −X ∗ 0 ) p(X ∗ 0 ) EX1[p(X ∗ 0 )]](22) Sampling ProcedureTo approximate this expectation for a given xι t, we first sample a set of xι 1’s. Typically, this consists of the provided samples from the new distribution. Then, for e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.