Recognition: unknown
On the Safety of Graph Representation Learning
Pith reviewed 2026-05-08 12:13 UTC · model grok-4.3
The pith
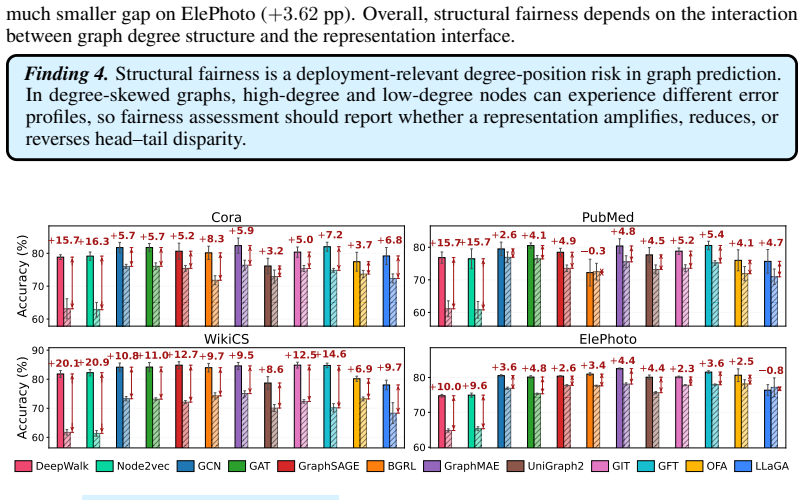
Safety in graph representation learning depends on how a method's design interacts with the specific graph stress rather than on which family the method belongs to.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce GRL-Safety, a multi-axis safety evaluation benchmark for graph representation learning. It evaluates twelve methods spanning topology-only embeddings, supervised GNNs, self-supervised models, and graph foundation models on twenty-five datasets under standardized conditions that preserve each method's native adaptation. The benchmark reports per-axis and per-sub-condition results on corruption robustness, out-of-distribution generalization, class imbalance, fairness, and interpretation. Analysis of the outcomes yields three cross-axis insights: safety behavior is shaped by the interaction between representation design and the stressed graph factor rather than by method family; so
What carries the argument
The GRL-Safety benchmark, which applies five safety axes (corruption robustness, OOD generalization, class imbalance, fairness, interpretation) to twelve methods on twenty-five datasets while preserving method-native adaptation and reporting disaggregated scores.
If this is right
- Method selection for deployment must account for the expected graph stresses rather than defaulting to a single family.
- Graph foundation models exhibit strengths on particular axes but do not dominate across all of them.
- Several regimes, including certain corruption and fairness settings, remain difficult for all evaluated methods and therefore require new robustness or adaptation techniques.
- Future evaluations should continue to report per-axis and per-sub-condition results instead of single aggregate scores.
- Representation design choices can be tuned to anticipated stresses once the interaction pattern is understood.
Where Pith is reading between the lines
- Designers could build stress-aware selection tools that map expected deployment factors to the representation features shown to handle them best.
- The same multi-axis testing approach could be applied to other representation-learning domains such as images or sequences to check whether similar design-stress interactions appear.
- Training pipelines might incorporate explicit objectives that encourage robustness across multiple axes simultaneously rather than optimizing for one at a time.
Load-bearing premise
The twenty-five chosen datasets and five safety axes, run under standardized conditions, are sufficient to capture the deployment stresses that matter for graph representation methods.
What would settle it
A new or existing GRL method that ranks first on every safety axis and every sub-condition without any axis-specific tuning or additional objectives.
Figures







read the original abstract
Graph representation learning (GRL) has evolved from topology-only graph embeddings to task-specific supervised GNNs, and more recently to reusable representations and graph foundation models (GFMs). However, existing evaluations mainly measure clean transfer, adaptation, and task coverage. It remains unclear whether GRL methods stay reliable when deployment stresses affect graph signals, graph contexts, label support, structural groups, or predictive evidence. We introduce GRL-Safety, a multi-axis safety evaluation benchmark for GRL. GRL-Safety evaluates twelve representative methods, spanning topology-only embedding methods, supervised GNNs, self-supervised graph models, and GFMs, on twenty-five graph datasets under standardized evaluation conditions while preserving method-native adaptation. The evaluation covers five safety axes: corruption robustness, OOD generalization, class imbalance, fairness, and interpretation, with per-axis and sub-condition reporting rather than a single aggregate score. Our analysis yields three cross-axis insights that can inspire future research. First, safety behavior is shaped by the interaction between representation design and the stressed graph factor, rather than by method family alone. Second, foundation-era methods show axis-specific strengths rather than broad safety dominance. Third, several deployment regimes remain difficult even for the best evaluated method, revealing capability gaps that require new robustness, adaptation, or training objectives beyond model selection. The benchmark, evaluation protocols, and code are available at: https://github.com/GXG-CS/GRL-Safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRL-Safety, a multi-axis benchmark that evaluates twelve GRL methods (topology-only embeddings, supervised GNNs, self-supervised models, and GFMs) on twenty-five datasets under standardized conditions that preserve method-native adaptation. It reports results across five safety axes—corruption robustness, OOD generalization, class imbalance, fairness, and interpretation—with per-axis and sub-condition breakdowns rather than aggregate scores. The analysis yields three cross-axis insights: safety behavior arises from representation-design × stressed-factor interactions rather than method family; foundation-era methods exhibit axis-specific strengths; and several deployment regimes remain difficult for all evaluated methods.
Significance. If the evaluation protocol is free of selection confounds, the work supplies a reproducible, multi-axis safety lens on GRL that moves beyond clean-task performance. The public release of the benchmark, protocols, and code is a clear strength that supports follow-on research. The interaction insight, if substantiated, would shift focus from family-level comparisons toward design-factor pairings and would usefully identify concrete capability gaps.
major comments (3)
- [Abstract and §4.3] Abstract and §4.3 (Cross-axis Insights): The central claim that 'safety behavior is shaped by the interaction between representation design and the stressed graph factor, rather than by method family alone' is load-bearing. The manuscript does not report a quantitative decomposition (e.g., variance partitioning or interaction-term significance in a mixed-effects model) that isolates design choices (message-passing vs. contrastive objectives, positional encodings) from family-level effects while controlling for dataset domain. Without this, the observed patterns could still be driven by correlations between the 25 datasets and the method families evaluated on them.
- [§3.1 and Table 1] §3.1 and Table 1: The claim that the twenty-five datasets and five axes 'sufficiently capture the relevant deployment stresses' is not supported by an explicit diversity analysis. No table or appendix quantifies domain coverage (citation, social, molecular, etc.), stress orthogonality (e.g., correlation between corruption type and method family), or balance across graph properties that could interact with the evaluated designs. This leaves the interaction insight vulnerable to selection bias.
- [§3.2] §3.2 (Evaluation Protocol): The description of 'standardized evaluation conditions while preserving method-native adaptation' is insufficiently detailed for reproducibility of the fairness and interpretation axes. For instance, it is unclear how contrastive or self-supervised objectives are adapted to fairness constraints without introducing protocol-level bias that could favor or disfavor particular families, undermining cross-family comparisons.
minor comments (3)
- [Figure 3 and §4.2] Figure 3 and §4.2: The per-sub-condition plots are informative but dense; a compact summary heatmap aggregating the five axes would improve readability without loss of information.
- [Related Work] Related Work section: Prior safety benchmarks in graph learning (e.g., robustness surveys or fairness toolkits) are cited, but the positioning relative to non-graph safety evaluation frameworks (e.g., those for language or vision models) could be sharpened to clarify the unique contribution of GRL-Safety.
- [Appendix B] Appendix B: The list of hyperparameters and adaptation choices for each of the twelve methods is welcome, but a single consolidated table mapping each method to its exact adaptation procedure per axis would reduce cross-referencing.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the empirical basis for our claims and committing to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and §4.3] The central claim that 'safety behavior is shaped by the interaction between representation design and the stressed graph factor, rather than by method family alone' is load-bearing. The manuscript does not report a quantitative decomposition (e.g., variance partitioning or interaction-term significance in a mixed-effects model) that isolates design choices (message-passing vs. contrastive objectives, positional encodings) from family-level effects while controlling for dataset domain. Without this, the observed patterns could still be driven by correlations between the 25 datasets and the method families evaluated on them.
Authors: The claim rests on systematic per-subcondition breakdowns across 25 datasets that reveal design-specific patterns (e.g., contrastive objectives outperforming message-passing under certain OOD stresses, independent of family). While we did not include a formal mixed-effects decomposition, the consistency of these patterns across domains supports the interaction view. In revision we will add a post-hoc variance partitioning analysis using mixed-effects models on the safety metrics, treating design choices and family as factors while controlling for dataset domain and properties. revision: yes
-
Referee: [§3.1 and Table 1] The claim that the twenty-five datasets and five axes 'sufficiently capture the relevant deployment stresses' is not supported by an explicit diversity analysis. No table or appendix quantifies domain coverage (citation, social, molecular, etc.), stress orthogonality (e.g., correlation between corruption type and method family), or balance across graph properties that could interact with the evaluated designs. This leaves the interaction insight vulnerable to selection bias.
Authors: Table 1 and the appendix already enumerate the datasets by domain and stress type, chosen to span citation, social, molecular, and other graphs with varying sizes and densities. To directly address potential selection bias, we will add an appendix with quantitative diversity metrics: domain distribution, pairwise correlations between stress types and method families, and balance statistics on key graph properties (e.g., degree distribution, homophily). revision: yes
-
Referee: [§3.2] The description of 'standardized evaluation conditions while preserving method-native adaptation' is insufficiently detailed for reproducibility of the fairness and interpretation axes. For instance, it is unclear how contrastive or self-supervised objectives are adapted to fairness constraints without introducing protocol-level bias that could favor or disfavor particular families, undermining cross-family comparisons.
Authors: Adaptations for fairness (e.g., group-aware reweighting or adversarial objectives for contrastive losses) and interpretation (gradient- or attention-based methods) are implemented in the released code and described at high level in the supplement. We agree the main-text description in §3.2 can be expanded. In revision we will add explicit step-by-step protocol details for each method family and axis, including how native objectives are preserved while incorporating fairness constraints, to eliminate any ambiguity. revision: yes
Circularity Check
Empirical benchmark with no circular derivation chain
full rationale
The paper introduces GRL-Safety as an empirical multi-axis benchmark, evaluates 12 methods on 25 datasets across 5 safety axes under standardized conditions, and draws three cross-axis insights directly from the resulting performance patterns. No mathematical derivations, equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or described structure; the claims rest on experimental outcomes with public code and datasets rather than any self-referential reduction. This is a standard empirical evaluation paper whose central results are independently falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five safety axes (corruption robustness, OOD generalization, class imbalance, fairness, interpretation) cover the primary deployment stresses for GRL.
Reference graph
Works this paper leans on
-
[1]
Evaluating explain- ability for graph neural networks.Scientific Data, 10(1):144, 2023
Chirag Agarwal, Owen Queen, Himabindu Lakkaraju, and Marinka Zitnik. Evaluating explain- ability for graph neural networks.Scientific Data, 10(1):144, 2023
2023
-
[2]
GraphFramEx: Towards systematic evaluation of explainability methods for graph neural networks
Kenza Amara, Rex Ying, Zitao Zhang, Zhihao Han, Yinan Shan, Ulrik Brandes, Sebastian Schemm, and Ce Zhang. GraphFramEx: Towards systematic evaluation of explainability methods for graph neural networks. InLearning on Graphs Conference (LoG), 2022
2022
-
[3]
GInX-Eval: Towards in-distribution evaluation of graph neural network explanations
Kenza Amara, Mennatallah El-Assady, and Rex Ying. GInX-Eval: Towards in-distribution evaluation of graph neural network explanations. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[4]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review arXiv 2021
-
[5]
LLaGA: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. LLaGA: Large language and graph assistant. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[6]
arXiv preprint arXiv:2406.10727 , year=
Zhikai Chen, Haitao Mao, Jingzhe Liu, Yu Song, Bingheng Li, Wei Jin, Bahare Fatemi, Anton Tsitsulin, Bryan Perozzi, Hui Liu, and Jiliang Tang. Text-space graph foundation models: Comprehensive benchmarks and new insights.arXiv preprint arXiv:2406.10727, 2024
-
[7]
A comprehensive survey on trustworthy graph neural networks: Privacy, robustness, fairness, and explainability.Machine Intelligence Research, 21(6):1011–1061, 2024
Enyan Dai, Tianxiang Zhao, Huaisheng Zhu, Junjie Xu, Zhimeng Guo, Hui Liu, Jiliang Tang, and Suhang Wang. A comprehensive survey on trustworthy graph neural networks: Privacy, robustness, fairness, and explainability.Machine Intelligence Research, 21(6):1011–1061, 2024
2024
-
[8]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2019
2019
-
[9]
A benchmark for fairness-aware graph learning.arXiv preprint arXiv:2407.12112, 2024
Yushun Dong, Song Wang, Zhenyu Lei, Zaiyi Zheng, Jing Ma, Chen Chen, and Jundong Li. A benchmark for fairness-aware graph learning.arXiv preprint arXiv:2407.12112, 2024
-
[10]
PyGDebias: A python library for debiasing in graph learning
Yushun Dong, Zhenyu Wang, Zaiyi Liu, Han Zhao, Suhang Wang, and Jundong Li. PyGDebias: A python library for debiasing in graph learning. InProceedings of the 17th ACM International Conference on Web Search and Data Mining (WSDM), 2024
2024
-
[11]
Yingtong Dou, Zhiwei Liu, Li Sun, Yutong Deng, Hao Peng, and Philip S. Yu. Enhancing graph neural network-based fraud detectors against camouflaged fraudsters. InProceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM), 2020
2020
-
[12]
Universal prompt tuning for graph neural networks
Taoran Fang, Yunchao Zhang, Yang Yang, Chunping Wang, and Lei Chen. Universal prompt tuning for graph neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
TAGLAS: An atlas of text-attributed graph datasets in the era of large graph and language models, 2024
Jiarui Feng, Hao Liu, Lecheng Kong, Mingfang Zhu, Yixin Chen, and Muhan Zhang. TAGLAS: An atlas of text-attributed graph datasets in the era of large graph and language models, 2024
2024
-
[14]
node2vec: Scalable feature learning for networks
Aditya Grover and Jure Leskovec. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages 855–864, 2016
2016
-
[15]
GOOD: A graph out-of-distribution benchmark
Shurui Gui, Xiner Li, Limei Wang, and Shuiwang Ji. GOOD: A graph out-of-distribution benchmark. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2022
2022
-
[16]
Generalizing gnns with tokenized mixture of experts.arXiv preprint arXiv:2602.09258, 2026
Xiaoguang Guo, Zehong Wang, Jiazheng Li, Shawn Spitzel, Qi Yang, Kaize Ding, Jundong Li, and Chuxu Zhang. Generalizing gnns with tokenized mixture of experts.arXiv preprint arXiv:2602.09258, 2026. 11
-
[17]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[18]
UniGraph2: Learning a unified embedding space to bind multimodal graphs
Yufei He, Yuan Sui, Xiaoxin He, Yue Liu, Yifei Sun, and Bryan Hooi. UniGraph2: Learning a unified embedding space to bind multimodal graphs. InProceedings of the ACM Web Conference (WWW), 2025
2025
-
[19]
GraphMAE: Self-supervised masked graph autoencoders
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. GraphMAE: Self-supervised masked graph autoencoders. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2022
2022
-
[20]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[21]
PRODIGY: Enabling in-context learning over graphs
Qian Huang, Hongyu Ren, Peng Chen, Gregor Kržmanc, Daniel Zeng, Percy Liang, and Jure Leskovec. PRODIGY: Enabling in-context learning over graphs. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[22]
Tem- poral graph benchmark for machine learning on temporal graphs
Shenyang Huang, Farimah Poursafaei, Jacob Danovitch, Matthias Fey, Weihua Hu, Emanuele Rossi, Jure Leskovec, Michael Bronstein, Guillaume Rabusseau, and Reihaneh Rabbany. Tem- poral graph benchmark for machine learning on temporal graphs. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
2023
-
[23]
Multi-task self-supervised graph neural networks enable stronger task generalization
Mingxuan Ju, Tong Zhao, Qianlong Wen, Wenhao Yu, Neil Shah, Yanfang Ye, and Chuxu Zhang. Multi-task self-supervised graph neural networks enable stronger task generalization. In International Conference on Learning Representations (ICLR), 2023
2023
-
[24]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[25]
DeepRobust: A platform for adversarial at- tacks and defenses
Yaxin Li, Wei Jin, Han Xu, and Jiliang Tang. DeepRobust: A platform for adversarial at- tacks and defenses. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), Demonstration Track, 2021
2021
-
[26]
ZeroG: Investigating cross- dataset zero-shot transferability in graphs
Yuhan Li, Peisong Wang, Zhixun Li, Jeffrey Xu Yu, and Jia Li. ZeroG: Investigating cross- dataset zero-shot transferability in graphs. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2024
2024
-
[27]
Newsp: A new search process for continuous subgraph matching over dynamic graphs
Ziming Li, Youhuan Li, Xinhuan Chen, Lei Zou, Yang Li, Xiaofeng Yang, and Hongbo Jiang. Newsp: A new search process for continuous subgraph matching over dynamic graphs. InIEEE International Conference on Data Engineering(ICDE), 2024
2024
-
[28]
Graph neural networks for databases: A survey
Ziming Li, Youhuan Li, Yuyu Luo, Guoliang Li, and Chuxu Zhang. Graph neural networks for databases: A survey. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence(IJCAI), 2025
2025
-
[29]
Graph is a substrate across data modalities.arXiv preprint arXiv:2601.22384, 2026
Ziming Li, Xiaoming Wu, Zehong Wang, Jiazheng Li, Yijun Tian, Jinhe Bi, Yunpu Ma, Yanfang Ye, and Chuxu Zhang. Graph is a substrate across data modalities.arXiv preprint arXiv:2601.22384, 2026
-
[30]
Holistic evaluation of language models.Transactions on Machine Learning Research, 2023
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, et al. Holistic evaluation of language models.Transactions on Machine Learning Research, 2023
2023
-
[31]
One for all: Towards training one graph model for all classification tasks
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[32]
Graph neural networks with adaptive residual
Xiaorui Liu, Jiayuan Ding, Wei Jin, Han Xu, Yao Ma, Zitao Liu, and Jiliang Tang. Graph neural networks with adaptive residual. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 12
2021
-
[33]
Yihong Ma, Yijun Tian, Nuno Moniz, and Nitesh V . Chawla. Class-imbalanced learning on graphs: A survey.ACM Computing Surveys, 57(8), 2025. doi: 10.1145/3718734
-
[34]
GraphENS: Neighbor-aware ego network synthesis for class-imbalanced node classification
Joonhyung Park, Jaeyun Song, and Eunho Yang. GraphENS: Neighbor-aware ego network synthesis for class-imbalanced node classification. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[35]
DeepWalk: Online learning of social repre- sentations
Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. DeepWalk: Online learning of social repre- sentations. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages 701–710, 2014
2014
-
[36]
GCC: Graph contrastive coding for graph neural network pre-training
Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. GCC: Graph contrastive coding for graph neural network pre-training. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2020
2020
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the 38th International Conference on Machine Learning (ICML), 2021
2021
-
[38]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 3982–3992, 2019
2019
-
[39]
Leonardo F. R. Ribeiro, Pedro H. P. Saverese, and Daniel R. Figueiredo. struc2vec: Learning node representations from structural identity. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages 385–394, 2017
2017
-
[40]
DropEdge: Towards deep graph convolutional networks on node classification
Yu Rong, Wenbing Huang, Tingyang Xu, and Junzhou Huang. DropEdge: Towards deep graph convolutional networks on node classification. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[41]
Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos-Ruiz, Nina M
Jonathan M. Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos-Ruiz, Nina M. Donghia, Craig R. MacNair, Shawn French, Lindsey A. Carfrae, Zohar Bloom-Ackermann, et al. A deep learning approach to antibiotic discovery.Cell, 180(4):688–702.e13, 2020. doi: 10.1016/j.cell.2020.01.021
-
[42]
GPPT: Graph pre-training and prompt tuning to generalize graph neural networks
Mingchen Sun, Kaixiong Zhou, Xin He, Ying Wang, and Xin Wang. GPPT: Graph pre-training and prompt tuning to generalize graph neural networks. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2022
2022
-
[43]
GraphGPT: Graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. GraphGPT: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2024
2024
-
[44]
LINE: Large- scale information network embedding
Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. LINE: Large- scale information network embedding. InProceedings of the 24th International Conference on World Wide Web (WWW), pages 1067–1077, 2015
2015
-
[45]
Investigating and mitigating degree-related biases in graph convolu- tional networks
Xianfeng Tang, Huaxiu Yao, Yiwei Sun, Yiqi Wang, Jiliang Tang, Charu Aggarwal, Prasenjit Mitra, and Suhang Wang. Investigating and mitigating degree-related biases in graph convolu- tional networks. InProceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM), pages 1435–1444, 2020
2020
-
[46]
Dyer, Rémi Munos, Petar Veliˇckovi´c, and Michal Valko
Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Mehdi Azabou, Eva L. Dyer, Rémi Munos, Petar Veliˇckovi´c, and Michal Valko. Large-scale representation learning on graphs via bootstrapping. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[47]
Heterogeneous graph masked autoencoders
Yijun Tian, Kaiwen Dong, Chunhui Zhang, Chuxu Zhang, and Nitesh V Chawla. Heterogeneous graph masked autoencoders. InProceedings of the AAAI conference on artificial intelligence (AAAI), volume 37, pages 9997–10005, 2023. 13
2023
-
[48]
Graph attention networks
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[49]
Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm
Petar Veliˇckovi´c, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. Deep graph infomax. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[50]
DecodingTrust: A comprehensive assess- ment of trustworthiness in GPT models
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, et al. DecodingTrust: A comprehensive assess- ment of trustworthiness in GPT models. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
2023
-
[51]
Song Wang, Zhen Tan, Yaochen Zhu, Chuxu Zhang, and Jundong Li. Generative risk mini- mization for out-of-distribution generalization on graphs.Transactions on Machine Learning Research, 2025. arXiv:2502.07968
-
[52]
Safety in graph machine learning: Threats and safeguards.IEEE Transactions on Knowledge and Data Engineering, 2026
Song Wang, Yushun Dong, Binchi Zhang, Zihan Chen, Xingbo Fu, Yinhan He, Cong Shen, Chuxu Zhang, Nitesh V Chawla, and Jundong Li. Safety in graph machine learning: Threats and safeguards.IEEE Transactions on Knowledge and Data Engineering, 2026
2026
-
[53]
Chawla, Chuxu Zhang, and Yanfang Ye
Zehong Wang, Zheyuan Zhang, Nitesh V . Chawla, Chuxu Zhang, and Yanfang Ye. GFT: Graph foundation model with transferable tree vocabulary. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[54]
Graph foundation models: A comprehensive survey,
Zehong Wang, Zheyuan Liu, Tianyi Ma, Jiazheng Li, Zheyuan Zhang, Xingbo Fu, Yiyang Li, Zhengqing Yuan, Wei Song, Yijun Ma, Qingkai Zeng, Xiusi Chen, Jianan Zhao, Jundong Li, Meng Jiang, Pietro Lio, Nitesh Chawla, Chuxu Zhang, and Yanfang Ye. Graph foundation models: A comprehensive survey.arXiv preprint arXiv:2505.15116, 2025
-
[55]
Chawla, Chuxu Zhang, and Yanfang Ye
Zehong Wang, Zheyuan Zhang, Tianyi Ma, Nitesh V . Chawla, Chuxu Zhang, and Yanfang Ye. Towards graph foundation models: Learning generalities across graphs via task-trees. In International Conference on Machine Learning (ICML), 2025
2025
-
[56]
Beyond message passing: Neural graph pattern machine
Zehong Wang, Zheyuan Zhang, Tianyi Ma, Nitesh V Chawla, Chuxu Zhang, and Yanfang Ye. Beyond message passing: Neural graph pattern machine. InInternational Conference on Machine Learning, pages 65496–65517. PMLR, 2025
2025
-
[57]
Generative graph pattern machine
Zehong Wang, Zheyuan Zhang, Tianyi Ma, Chuxu Zhang, and Yanfang Ye. Generative graph pattern machine. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[58]
NoisyGL: A comprehensive benchmark for graph neural networks under label noise
Zhonghao Wang, Danyu Sun, Sheng Zhou, Haobo Wang, Jiapei Fan, Longtao Huang, and Jiajun Bu. NoisyGL: A comprehensive benchmark for graph neural networks under label noise. In Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024
2024
-
[59]
A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
2020
- [60]
-
[61]
GraphFM: A comprehensive benchmark for graph foundation model.arXiv preprint arXiv:2406.08310, 2024
Yuhao Xu, Xinqi Liu, Keyu Duan, Yi Fang, Yu-Neng Chuang, Daochen Zha, and Qiaoyu Tan. GraphFM: A comprehensive benchmark for graph foundation model.arXiv preprint arXiv:2406.08310, 2024
-
[62]
Hamilton, and Jure Leskovec
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L. Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2018. 14
2018
-
[63]
Graph contrastive learning with augmentations
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[64]
Xingtong Yu, Shenghua Ye, Ruijuan Liang, Chang Zhou, Hong Cheng, Xinming Zhang, and Yuan Fang. Evaluating progress in graph foundation models: A comprehensive benchmark and new insights.arXiv preprint arXiv:2603.10033, 2026
-
[65]
Graph cross supervised learning via generalized knowledge
Xiangchi Yuan, Yijun Tian, Chunhui Zhang, Yanfang Ye, Nitesh V Chawla, and Chuxu Zhang. Graph cross supervised learning via generalized knowledge. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4083–4094, 2024. doi: 10.1145/3637528.3671830
-
[66]
Mitigating emergent robustness degradation while scaling graph learning
Xiangchi Yuan, Chunhui Zhang, Yijun Tian, Yanfang Ye, and Chuxu Zhang. Mitigating emergent robustness degradation while scaling graph learning. InInternational Conference on Learning Representations, 2024
2024
-
[67]
Het- erogeneous graph neural network
Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V Chawla. Het- erogeneous graph neural network. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining (KDD), pages 793–803, 2019
2019
-
[68]
Qihai Zhang, Xinyue Sheng, Yuanfu Sun, and Qiaoyu Tan. TrustGLM: Evaluating the robustness of graph LLMs against prompt, text, and structure attacks.arXiv preprint arXiv:2506.11844, 2025
-
[69]
GraphSMOTE: Imbalanced node classifi- cation on graphs with graph neural networks
Tianxiang Zhao, Xiang Zhang, and Suhang Wang. GraphSMOTE: Imbalanced node classifi- cation on graphs with graph neural networks. InProceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM), 2021
2021
-
[70]
Graph robustness benchmark: Benchmarking the adversarial robustness of graph machine learning
Qinkai Zheng, Xu Zou, Yuxiao Dong, Yukuo Cen, Da Yin, Jiarong Xu, Yang Yang, and Jie Tang. Graph robustness benchmark: Benchmarking the adversarial robustness of graph machine learning. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021. 15 A Datasets Dataset statistics.We use twenty-five text-attributed grap...
2021
-
[71]
For BGRL [ 46]: num_layers=2, num_hidden=768, lr=1e-4, weight_decay=1e-5, max_epoch=50, batch_size=1024, ema_tau=0.99, warmup_frac=0.1, drop_edge=0.2, drop_feat=0.2, predictor_hidden=512, optimizer=AdamW
-
[72]
For GraphMAE [ 19]: num_layers=2, num_hidden=768, num_heads=4, lr=1e-3, weight_decay=2e-4, max_epoch=50, batch_size=1024, mask_rate=0.5, replace_rate=0.0, loss=sce, alpha_l=3.0, in_drop=0.2, attn_drop=0.1, optimizer=AdamW
-
[73]
For GFT [ 53]: num_layers=2, hidden_dim=768, dropout=0.15, pretrain_lr=1e-4, pretrain_weight_decay=1e-5, pretrain_epochs=50, pretrain_batch_size=1024, codebook_size=128, codebook_head=4, codebook_decay=0.8, feat_p=0.2, edge_p=0.2, topo_recon_ratio=0.1, optimizer=AdamW
-
[74]
For GIT [ 55]: num_layers=2, hidden_dim=768, dropout=0.15, lr=1e-7, weight_decay=1e-8, epochs=20, batch_size=4096, fanout=10, ema=0.99, feat_p=0.2, edge_p=0.2, topo_recon_ratio=0.1, optimizer=AdamW
-
[75]
For UniGraph2 [ 18]: num_layers=3, num_hidden=768, num_experts=8, num_selected_experts=2, lr=1e-4, weight_decay=1e-5, max_epoch=50, batch_size=64, gamma=2.0, lambda_spd=0.5, feat_drop_rate=0.1, edge_mask_rate=0.1, fanout=10, optimizer=AdamW
-
[76]
For OFA [ 31]: num_layers=7, num_hidden=768, dropout=0.15, lr=1e-3, num_epochs=50, batch_size=128, num_relations=5, JK=none, optimizer=AdamW
-
[77]
C.2 Downstream adaptation hyperparameters For each method-dataset cell we apply the method’s native downstream adaptation procedure end-to- end with AdamW and five random seeds
For LLaGA [ 5], following the original two-stage recipe, only the projector is trained with the Vicuna-7B language model frozen: llm_backbone=Vicuna-7B (frozen), projector_type=2-layer-mlp, projector_hidden=4096, lr=5e-4, weight_decay=1e-4, epochs=10, batch_size=4, sample_size=10, use_hop=2, max_text_len=128, max_steps=5000, dtype=bfloat16, optimizer=Adam...
-
[78]
Predictions use a frozen- feature ℓ2-regularised logistic-regression head (scikit-learn, C=1.0, max_iter=1000, solver=lbfgs)
For DeepWalk [ 35], walk embeddings are fitted on the downstream graph with Skip-gram on uniform random walks ( p=q=1): emb_dim=128, walk_length=20, walks_per_node=10, context_size=10, num_negative=1, walk_epochs=100, batch_size=128, lr=1e-2, optimizer=SparseAdam . Predictions use a frozen- feature ℓ2-regularised logistic-regression head (scikit-learn, C=...
-
[79]
For Node2vec [14]: same Skip-gram and logistic-regression configuration as DeepWalk, with biased second-order walks (p=1.0, q=0.5, BFS-leaning)
-
[80]
For GCN, GAT, and GraphSAGE: num_layers=2, num_hidden=768, lr=1e-3, dropout=0.2, weight_decay=1e-4, max_epochs=500, patience=200. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.