Recognition: unknown
Crafting Reversible SFT Behaviors in Large Language Models
Pith reviewed 2026-05-08 12:12 UTC · model grok-4.3
The pith
SFT-induced behaviors in large language models can be compressed into sparse carriers that enable selective reversal without weight changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Loss-Constrained Dual Descent (LCDD) constructs sparse carriers for SFT-induced behaviors by jointly optimizing routing masks and model weights under an explicit utility budget. These carriers preserve the target behaviors while allowing reversal through SFT-Eraser, a soft prompt optimized via activation matching on extracted carrier channels. Ablations confirm that the sparse structure is the key precondition for successful reversal, as the same optimization fails on standard SFT models. This establishes that the learned carriers are causally necessary for the behaviors.
What carries the argument
Loss-Constrained Dual Descent (LCDD), which forces an SFT behavior into a sparse carrier by jointly optimizing routing masks and model weights under a utility budget, paired with SFT-Eraser for activation-matched reversal.
Load-bearing premise
That jointly optimizing under an explicit utility budget forces the behavior into a mechanistically necessary sparse subnetwork rather than merely a correlated one, and that reversal via SFT-Eraser does not degrade unrelated model capabilities.
What would settle it
An experiment in which SFT-Eraser reverses the target behavior equally well on a standard dense SFT model, or in which reversal on the LCDD carrier degrades unrelated capabilities.
Figures

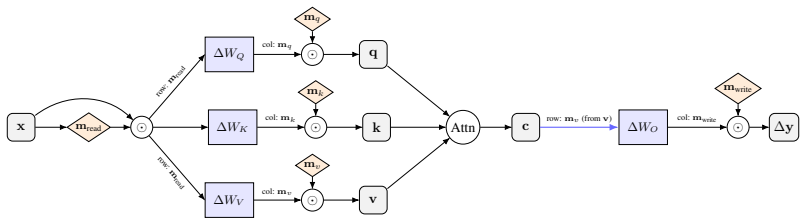
read the original abstract
Supervised fine-tuning (SFT) induces new behaviors in large language models, yet imposes no structural constraint on how these behaviors are distributed within the model. Existing behavior interpretation methods, such as circuit attribution approaches, identify sparse subnetworks correlated with SFT-induced behaviors post-hoc. However, such correlations do not imply *causal necessity*, limiting the ability to selectively control SFT-induced behaviors at inference time. We pursue an alternative by asking: can an SFT-induced behavior be deliberately compressed into a sparse, mechanistically necessary subnetwork, termed a *carrier*, while remaining controllable at inference time without weight modification? We propose (a) **Loss-Constrained Dual Descent (LCDD)**, which constructs such carriers by jointly optimizing routing masks and model weights under an explicit utility budget, and (b) **SFT-Eraser**, a soft prompt optimized via activation matching on extracted carrier channels, to reverse the SFT-induced behavior. Across safety, fixed-response, and style behaviors on multiple model families, LCDD yields sparse carriers that preserve target behaviors while enabling strong reversion when triggered by SFT-Eraser. Ablations further establish that the sparse structure is the key precondition for reversal: the same trigger optimization fails on standard SFT models, confirming that structure rather than trigger design is the operative factor. These results provide direct evidence that the learned carriers are causally necessary for the behaviors, pointing to a new direction for systematically localizing and selectively suppressing SFT-induced behaviors in deployed models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Loss-Constrained Dual Descent (LCDD) to compress SFT-induced behaviors into sparse subnetworks termed 'carriers' that are claimed to be mechanistically necessary, paired with SFT-Eraser (an activation-matching soft prompt on carrier channels) to reverse the behaviors at inference time without weight changes. Experiments across safety, fixed-response, and style behaviors on multiple model families report that LCDD produces carriers preserving target behaviors while enabling strong reversal, with ablations showing the same trigger fails on standard SFT models, which the authors interpret as direct evidence that the carriers are causally necessary.
Significance. If the central claim of causal necessity holds, the work would offer a constructive method for localizing and selectively suppressing SFT behaviors in deployed models, moving beyond post-hoc attribution methods. The comparative ablations isolating sparsity as the precondition for reversal are a positive feature, and the approach of joint mask-weight optimization under a utility budget is a clear technical contribution.
major comments (2)
- [Abstract] Abstract: The claim that the results 'provide direct evidence that the learned carriers are causally necessary for the behaviors' overreaches the reported evidence. The key ablation demonstrates that SFT-Eraser succeeds on LCDD carriers but fails on standard SFT models, showing that the sparse structure enables control. However, this establishes only that the optimizer found a controllable localization, not necessity: no experiment is described that zeros or removes the carrier weights to test whether the target behavior is eliminated, nor checks for redundant pathways outside the mask that could sustain the behavior independently.
- [Abstract] Abstract: The manuscript provides no quantitative metrics (e.g., exact reversal rates, behavior preservation accuracy, or utility-budget trade-offs), no baselines (e.g., comparisons to post-hoc circuit discovery or other localization techniques), and no details on model scales, dataset sizes, or the precise definition and enforcement of the 'utility budget' in LCDD. These omissions make it impossible to evaluate effect sizes, reproducibility, or whether the joint optimization truly forces mechanistic necessity rather than correlation.
minor comments (2)
- The terms 'carrier' and 'SFT-Eraser' are introduced in the abstract without inline definitions or references to their formal definitions in the main text; adding a brief parenthetical explanation on first use would improve accessibility.
- No evaluation is mentioned of whether SFT-Eraser degrades unrelated capabilities (e.g., general language modeling performance or other behaviors); including such checks would strengthen the claim of selective control.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We value the recognition of the technical contribution of LCDD and the ablations isolating the role of sparsity. Below we provide point-by-point responses to the major comments, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the results 'provide direct evidence that the learned carriers are causally necessary for the behaviors' overreaches the reported evidence. The key ablation demonstrates that SFT-Eraser succeeds on LCDD carriers but fails on standard SFT models, showing that the sparse structure enables control. However, this establishes only that the optimizer found a controllable localization, not necessity: no experiment is described that zeros or removes the carrier weights to test whether the target behavior is eliminated, nor checks for redundant pathways outside the mask that could sustain the behavior independently.
Authors: We appreciate the referee's careful distinction between controllability and necessity. Our ablation shows that the reversal trigger is effective only in the presence of the LCDD-induced sparse structure, which we argue indicates that the behavior has been localized such that redundant pathways do not sustain it independently (otherwise the trigger would succeed on standard SFT as well). Nevertheless, we agree that a direct test by zeroing the carrier weights would provide more conclusive evidence of necessity. We will add this ablation experiment to the revised manuscript and modify the abstract to state that the results demonstrate the carriers enable causal control and are necessary for the observed reversal, rather than claiming 'direct evidence' of necessity outright. revision: yes
-
Referee: [Abstract] Abstract: The manuscript provides no quantitative metrics (e.g., exact reversal rates, behavior preservation accuracy, or utility-budget trade-offs), no baselines (e.g., comparisons to post-hoc circuit discovery or other localization techniques), and no details on model scales, dataset sizes, or the precise definition and enforcement of the 'utility budget' in LCDD. These omissions make it impossible to evaluate effect sizes, reproducibility, or whether the joint optimization truly forces mechanistic necessity rather than correlation.
Authors: We agree that the submitted manuscript lacks explicit quantitative metrics, baselines, and implementation details. We will revise the abstract and add a new subsection or table detailing exact reversal rates (to be reported as percentages with standard deviations), behavior preservation accuracy, utility-budget trade-offs, comparisons to post-hoc localization techniques such as activation patching and circuit discovery, model scales and families used, dataset sizes, and the precise definition of the utility budget as the maximum allowable degradation in a proxy task under the loss constraint during optimization. This will allow readers to assess effect sizes and reproducibility. revision: yes
Circularity Check
No significant circularity; central claim rests on empirical ablation contrast rather than definitional reduction.
full rationale
The paper defines LCDD as joint optimization of masks and weights under a utility budget to produce sparse carriers, then reports that SFT-Eraser reversal succeeds on those carriers but fails on standard SFT models. This contrast is an external empirical test against a non-optimized baseline; it does not reduce the necessity claim to the optimization procedure by construction. No self-definitional equations, fitted parameters renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the abstract or described method. The result is therefore self-contained against the provided baseline comparison.
Axiom & Free-Parameter Ledger
free parameters (1)
- utility budget
invented entities (2)
-
carrier
no independent evidence
-
SFT-Eraser
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[4]
Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023
2023
-
[5]
Injecting new knowledge into large language models via supervised fine-tuning
Nick Mecklenburg, Yiyou Lin, Xiaoxiao Li, Daniel Holstein, Leonardo Nunes, Sara Mal- var, Bruno Silva, Ranveer Chandra, Vijay Aski, Pavan Kumar Reddy Yannam, et al. Inject- ing new knowledge into large language models via supervised fine-tuning.arXiv preprint arXiv:2404.00213, 2024
-
[6]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
2021
-
[7]
Zoom in: An introduction to circuits.Distill, 5(3):e00024–001, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 5(3):e00024–001, 2020
2020
-
[8]
Superficial safety alignment hypothesis.arXiv preprint arXiv:2410.10862, 2024
Jianwei Li and Jung-Eun Kim. Superficial safety alignment hypothesis.arXiv preprint arXiv:2410.10862, 2024
-
[9]
A Layer-wise Analysis of Supervised Fine-Tuning
Qinghua Zhao, Xueling Gong, Xinyu Chen, Zhongfeng Kang, and Xinlu Li. A layer-wise analysis of supervised fine-tuning.arXiv preprint arXiv:2604.11838, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Yang Zhao, Li Du, Xiao Ding, Kai Xiong, Ting Liu, and Bing Qin. Supervised fine-tuning achieve rapid task adaption via alternating attention head activation patterns.arXiv preprint arXiv:2409.15820, 2024. 10
-
[11]
Fei Ding and Baiqiao Wang. Improved supervised fine-tuning for large language models to mitigate catastrophic forgetting.arXiv preprint arXiv:2506.09428, 2025
-
[12]
Talking to yourself: Defying forgetting in large language models
Yutao Sun, Mingshuai Chen, Tiancheng Zhao, Phillip Miao, Zilun Zhang, Haozhan Shen, Ruizhe Zhu, and Jianwei Yin. Talking to yourself: Defying forgetting in large language models. arXiv preprint arXiv:2602.20162, 2026
-
[13]
UFT: Unifying Fine-Tuning of SFT and RLHF/DPO/UNA through a Generalized Implicit Reward Function
Zhichao Wang, Bin Bi, Zixu Zhu, Xiangbo Mao, Jun Wang, and Shiyu Wang. Uft: Unifying fine-tuning of sft and rlhf/dpo/una through a generalized implicit reward function.arXiv preprint arXiv:2410.21438, 2024
work page internal anchor Pith review arXiv 2024
-
[14]
Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
2023
-
[15]
Attribution patching outperforms automated circuit discovery
Aaquib Syed, Can Rager, and Arthur Conmy. Attribution patching outperforms automated circuit discovery. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 407–416, 2024
2024
-
[16]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv preprint arXiv:2403.19647, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Safeseek: Universal attribution of safety circuits in language models
Miao Yu, Siyuan Fu, Moayad Aloqaily, Zhenhong Zhou, Safa Otoum, Kun Wang, Yufei Guo, Qingsong Wen, et al. Safeseek: Universal attribution of safety circuits in language models. arXiv preprint arXiv:2603.23268, 2026
-
[18]
arXiv preprint arXiv:2511.13653 , year=
Leo Gao, Achyuta Rajaram, Jacob Coxon, Soham V Govande, Bowen Baker, and Dan Mossing. Weight-sparse transformers have interpretable circuits.arXiv preprint arXiv:2511.13653, 2025
-
[19]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review arXiv 2022
-
[20]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review arXiv 2022
-
[21]
Task arithmetic in the tangent space: Improved editing of pre-trained models.Advances in Neural Information Processing Systems, 36:66727–66754, 2023
Guillermo Ortiz-Jimenez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models.Advances in Neural Information Processing Systems, 36:66727–66754, 2023
2023
-
[22]
Causal scrubbing: A method for rigorously testing interpretability hy- potheses
Lawrence Chan, Adrià Garriga-Alonso, Nicholas Goldowsky-Dill, Ryan Green- blatt, Jenny Nitishinskaya, Ansh Radhakrishnan, Buck Shlegeris, and Nate Thomas. Causal scrubbing: A method for rigorously testing interpretability hy- potheses. https://www.alignmentforum.org/posts/JvZhhzycHu2Yd57RN/ causal-scrubbing-a-method-for-rigorously-testing , Dec 2022. AI A...
2022
-
[23]
Badnets: Evaluating backdooring attacks on deep neural networks.Ieee Access, 7:47230–47244, 2019
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Evaluating backdooring attacks on deep neural networks.Ieee Access, 7:47230–47244, 2019
2019
-
[24]
Jinman Wu, Yi Xie, Shiqian Zhao, and Xiaofeng Chen. Depth charge: Jailbreak large language models from deep safety attention heads.arXiv preprint arXiv:2603.05772, 2026
-
[25]
Piggyback: Adapting a single network to multiple tasks by learning to mask weights
Arun Mallya, Dillon Davis, and Svetlana Lazebnik. Piggyback: Adapting a single network to multiple tasks by learning to mask weights. InProceedings of the European conference on computer vision (ECCV), pages 67–82, 2018
2018
-
[26]
Learning sparse neural net- works throughl 0regularization.arXiv preprint arXiv:1712.01312,
Christos Louizos, Max Welling, and Diederik P Kingma. Learning sparse neural networks throughl_0regularization.arXiv preprint arXiv:1712.01312, 2017
-
[27]
Low-complexity probing via finding subnet- works
Steven Cao, Victor Sanh, and Alexander M Rush. Low-complexity probing via finding subnet- works. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 960–966, 2021. 11
2021
-
[28]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[29]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Advances in Neural Information Processing Systems, 37:47094–47165, 2024
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, et al. Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Advances in Neural Information Processing Systems, 37:47094–47165, 2024
2024
-
[30]
Shakespearean and modern english conversa- tional dataset
Roudranil. Shakespearean and modern english conversa- tional dataset. https://huggingface.co/datasets/Roudranil/ shakespearean-and-modern-english-conversational-dataset, 2023
2023
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Albert Q Jiang, A Sablayrolles, A Mensch, C Bamford, D Singh Chaplot, Ddl Casas, F Bressand, G Lengyel, G Lample, L Saulnier, et al. Mistral 7b. arxiv.arXiv preprint arXiv:2310.06825, 10: 3, 2023
work page internal anchor Pith review arXiv 2023
-
[34]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[35]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.Advances in neural information processing systems, 37:8093–8131, 2024
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.Advances in neural information processing systems, 37:8093–8131, 2024
2024
-
[36]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review arXiv 2009
-
[38]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
2019
-
[39]
Modeling by shortest data description.Automatica, 14(5):465–471, 1978
Jorma Rissanen. Modeling by shortest data description.Automatica, 14(5):465–471, 1978
1978
-
[40]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013. A Gate–Weight Equivalence: Full Derivations We prove that the activation-gating formulation used in LCDD is equivalent to the structured weight masking in Section 3.1. Throug...
work page internal anchor Pith review arXiv 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.