Recognition: no theorem link
Breaking the Illusion: When Positive Meets Negative in Multimodal Decoding
Pith reviewed 2026-05-11 01:22 UTC · model grok-4.3
The pith
Positive-and-Negative Decoding steers vision-language models toward visual evidence by contrasting amplified and counterfactual paths during inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that object hallucination in VLMs arises from under-weighting of visual features in attention mechanisms, and that a dual-path decoding strategy can correct this. Specifically, the positive path amplifies visual evidence while the negative path constructs counterfactuals to penalize generations driven by linguistic priors. Contrasting the logits or probabilities from these two paths during autoregressive decoding enforces visual fidelity, leading to improved performance on hallucination benchmarks without requiring model fine-tuning or additional data.
What carries the argument
Positive-and-Negative Decoding (PND), a training-free dual-path contrast that amplifies visual evidence in one path and penalizes prior-dominant generation in the other.
Load-bearing premise
The attention imbalance favoring linguistic priors is the primary driver of hallucination, and the dual-path contrast will reliably enforce visual fidelity without introducing new errors or biases.
What would settle it
Applying PND to a VLM and measuring equal or higher hallucination rates on POPE or CHAIR compared to standard decoding would disprove the method's effectiveness.
Figures

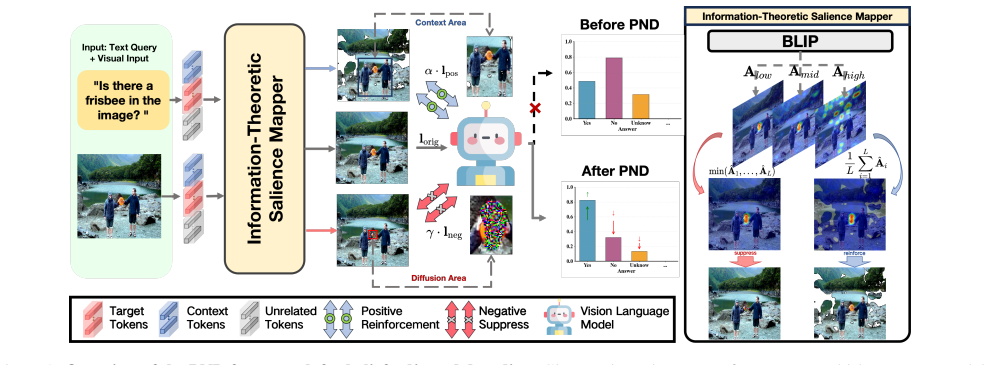
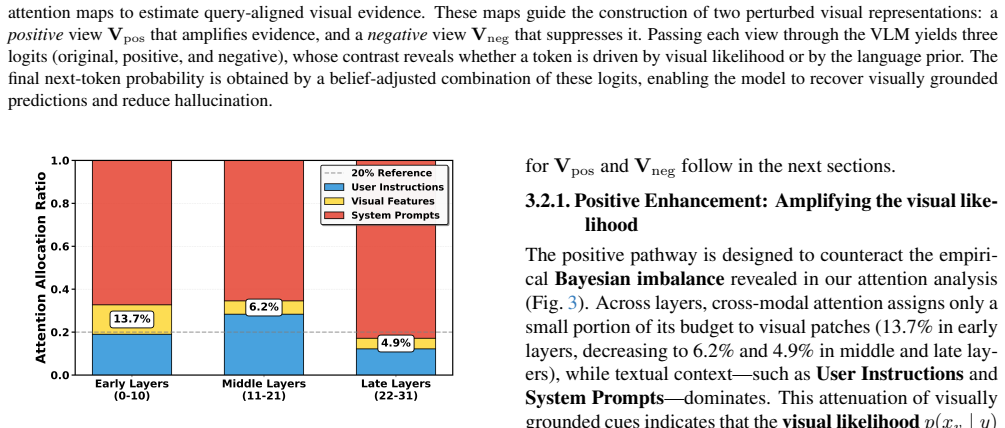
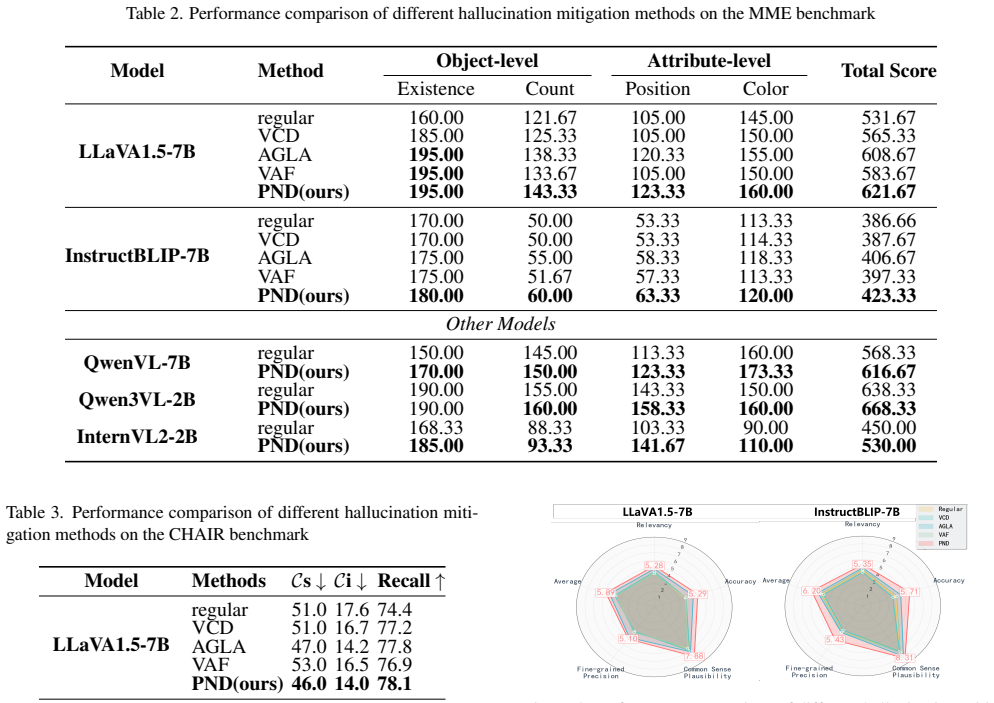

read the original abstract
Vision-Language Models (VLMs) are frequently undermined by object hallucination, generating content that contradicts visual reality, due to an over-reliance on linguistic priors. We introduce Positive-and-Negative Decoding (PND), a training-free inference framework that intervenes directly in the decoding process to enforce visual fidelity. PND is motivated by our finding of an attention imbalance in VLMs, where visual features are under-weighted. Our framework introduces a dual-path contrast: a positive path that amplifies visual evidence and a negative path that constructs counterfactuals to penalize prior-dominant generation. By contrasting outputs from both paths during decoding, PND steers generation toward visually grounded results. Experiments on POPE, MME, and CHAIR demonstrate state-of-the-art performance without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Positive-and-Negative Decoding (PND), a training-free inference framework for Vision-Language Models to reduce object hallucination caused by over-reliance on linguistic priors and under-weighting of visual features in attention. PND uses a dual-path approach during decoding: a positive path that amplifies visual evidence and a negative path that constructs counterfactuals to penalize prior-dominant generation, steering outputs toward visually grounded results. It reports state-of-the-art performance on the POPE, MME, and CHAIR benchmarks without any retraining.
Significance. If the empirical claims hold, PND would represent a significant advance as a simple, training-free method to mitigate a common failure mode in VLMs. The inference-time intervention could be widely applicable and the identification of attention imbalance provides a new perspective on hallucination causes.
major comments (2)
- [Abstract] Abstract: The assertion of 'state-of-the-art performance' on POPE, MME, and CHAIR is presented without any quantitative metrics, baseline comparisons, ablation studies, or statistical details. This absence prevents verification or replication of the central claim.
- [Abstract] Abstract: The framework assumes that the identified attention imbalance is the primary driver of hallucination and that contrasting the negative-path counterfactuals will selectively enforce visual fidelity without introducing new errors or biases, but no derivation, isolation experiment, or control (e.g., neutral baseline replacing the negative path) is supplied to support this.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below, clarifying the content of the full paper and committing to revisions that strengthen the abstract without altering our core claims or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of 'state-of-the-art performance' on POPE, MME, and CHAIR is presented without any quantitative metrics, baseline comparisons, ablation studies, or statistical details. This absence prevents verification or replication of the central claim.
Authors: We agree that the abstract would be more informative with explicit metrics. The full manuscript reports detailed quantitative results in Section 4 and Tables 1-3, including direct comparisons to prior methods on POPE (accuracy and F1), MME (perception and cognition scores), and CHAIR (hallucination rate), along with ablation studies on the dual-path components. We will revise the abstract to include the key performance deltas and main baseline references while keeping it concise. revision: yes
-
Referee: [Abstract] Abstract: The framework assumes that the identified attention imbalance is the primary driver of hallucination and that contrasting the negative-path counterfactuals will selectively enforce visual fidelity without introducing new errors or biases, but no derivation, isolation experiment, or control (e.g., neutral baseline replacing the negative path) is supplied to support this.
Authors: Section 3.1 of the manuscript presents attention visualizations and quantitative analysis confirming the visual-linguistic imbalance as a key factor in hallucination. The experimental section (4.3) includes ablations that isolate the negative path's contribution by comparing full PND against positive-path-only and neutral (no-contrast) variants; these controls demonstrate that the dual-path contrast improves visual grounding without adding new biases or errors, as measured by consistent gains across all benchmarks. We will add a brief reference to these controls in the abstract and expand the description of the neutral baseline if needed for clarity. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper frames PND as a training-free inference-time intervention motivated by an observed attention imbalance, using dual-path contrast (positive amplification of visual evidence and negative counterfactual penalization) to steer decoding. No equations, fitted parameters, or results are presented that reduce by construction to inputs, self-definitions, or self-citation chains. The central mechanism is described as an empirical contrast during decoding, with performance claims resting on external benchmark experiments (POPE, MME, CHAIR) rather than any internal loop or renamed known result. The derivation remains self-contained as a practical intervention without load-bearing reductions to prior assumptions or author-specific uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs exhibit an attention imbalance in which visual features are under-weighted relative to linguistic priors.
invented entities (2)
-
Positive path
no independent evidence
-
Negative path
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, and Shi- jian Lu. Mitigating object hallucinations in large vision- language models with assembly of global and local attention. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 29915–29926, 2025. 2, 6
work page 2025
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023. 2, 6
work page 2023
-
[3]
Hallucination of multimodal large language models: A survey.arXiv e-prints, pages arXiv–2404, 2024
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv e-prints, pages arXiv–2404, 2024. 2
work page 2024
-
[4]
Comment: Microarrays, empirical bayes and the two-group model.Statist
T Tony Cai. Comment: Microarrays, empirical bayes and the two-group model.Statist. Sci., 23(1):29–33, 2008. 1, 3
work page 2008
-
[5]
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Shengyi Qian, Jianing Yang, David Fouhey, and Joyce Chai. Multi-object hallucination in vision language mod- els.Advances in Neural Information Processing Systems, 37:44393–44418, 2024. 5
work page 2024
-
[6]
Nicolas Chopin, S ´ebastien Gadat, Benjamin Guedj, Arnaud Guyader, and Elodie Vernet. On some recent advances on high dimensional bayesian statistics.ESAIM: Proceedings and Surveys, 51:293–319, 2015. 2
work page 2015
-
[7]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023. 1, 6
work page 2023
-
[8]
Plug and play language models: A simple approach to controlled text generation
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. InInternational Conference on Learning Representations, 2020. 2
work page 2020
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, G Heigold, S Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2020. 2
work page 2020
-
[10]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnos- tic suite for entangled language hallucination and visual il- lusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,...
work page 2024
-
[11]
Detecting and preventing hallucinations in large vision language models
Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and preventing hallucinations in large vision language models. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 18135–18143, 2024. 1, 2
work page 2024
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 5
work page 2020
-
[13]
Bliva: A simple multimodal llm for better handling of text-rich visual questions
Wenbo Hu, Yifan Xu, Yi Li, Weiyue Li, Zeyuan Chen, and Zhuowen Tu. Bliva: A simple multimodal llm for better handling of text-rich visual questions. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2256– 2264, 2024. 2
work page 2024
-
[14]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hal- lucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Infor- mation Systems, 43(2):1–55, 2025. 1
work page 2025
-
[15]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Con- ghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418–13427, 2024. 2
work page 2024
-
[16]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 6700–6709, 2019. 5
work page 2019
-
[17]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shi- jian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through vi- sual contrastive decoding.arXiv preprint arXiv:2311.16922,
-
[18]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 3
work page 2022
-
[19]
Streamlining prediction in bayesian deep learning
Rui Li, Marcus Klasson, Arno Solin, and Martin Trapp. Streamlining prediction in bayesian deep learning. InThe Thirteenth International Conference on Learning Represen- tations. 3
-
[20]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing, pages 292–305, 2023. 1, 5
work page 2023
-
[21]
Zhenwei Li, Mengying Xu, Xiaoli Yang, Yanqi Han, and Ji- awen Wang. A multi-label detection deep learning model with attention-guided image enhancement for retinal images. Micromachines, 14(3):705, 2023. 4
work page 2023
-
[22]
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Ser- ena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning.Advances in Neural Information Processing Sys- tems, 35:17612–17625, 2022. 1
work page 2022
-
[23]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 5
work page 2014
-
[24]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2
work page 2023
-
[25]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 2, 6
work page 2024
-
[26]
Reducing hallucina- tions in large vision-language models via latent space steer- ing
Sheng Liu, Haotian Ye, and James Zou. Reducing hallucina- tions in large vision-language models via latent space steer- ing. InThe Thirteenth International Conference on Learning Representations, 2025. 2
work page 2025
-
[27]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review arXiv
-
[28]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 2
work page 2022
-
[29]
Jiaren Peng, Wenzhong Yang, Fuyuan Wei, Liang He, Long Yao, and Hongzhen Lv. Event co-occurrences for prompt- based generative event argument extraction.Scientific Re- ports, 14(1):31377, 2024. 2
work page 2024
-
[30]
Sahadev Poudel and Sang-Woong Lee. Deep multi-scale at- tentional features for medical image segmentation.Applied Soft Computing, 109:107445, 2021. 4
work page 2021
-
[31]
Object hallucination in image cap- tioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image cap- tioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045,
work page 2018
-
[32]
A-okvqa: A benchmark for visual question answering using world knowl- edge
Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowl- edge. InEuropean conference on computer vision, pages 146–162. Springer, 2022. 5
work page 2022
-
[33]
Towards understanding the modality gap in clip
Peiyang Shi, Michael C Welle, M ˚arten Bj¨orkman, and Dan- ica Kragic. Towards understanding the modality gap in clip. InICLR 2023 workshop on multimodal representation learn- ing: perks and pitfalls, 2023. 1, 5
work page 2023
-
[34]
Large vision-language model alignment and misalignment: A survey through the lens of explainability
Dong Shu, Haiyan Zhao, Jingyu Hu, Weiru Liu, Ali Payani, Lu Cheng, and Mengnan Du. Large vision-language model alignment and misalignment: A survey through the lens of explainability.arXiv preprint arXiv:2501.01346, 2025. 2
-
[35]
Shuyuan Tang, Yiqing Zhou, Jintao Li, Chang Liu, and Jinglin Shi. Attention-guided sample-based feature enhance- ment network for crowded pedestrian detection using vision sensors.Sensors, 24(19):6350, 2024. 4, 5
work page 2024
-
[36]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
arXiv preprint arXiv:2411.10442 , year=
Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, et al. Enhancing the reasoning ability of multimodal large language models via mixed preference optimization.arXiv preprint arXiv:2411.10442, 2024. 6
-
[38]
Sumio Watanabe. Recent advances in algebraic geometry and bayesian statistics.Information Geometry, 7(Suppl 1): 187–209, 2024. 1
work page 2024
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jia- long Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang...
work page 2025
-
[40]
Tianyun Yang, Ziniu Li, Juan Cao, and Chang Xu. Mitigat- ing hallucination in large vision-language models via mod- ular attribution and intervention. InAdaptive Foundation Models: Evolving AI for Personalized and Efficient Learn- ing, 2025. 1
work page 2025
-
[41]
Hao Yin, Guangzong Si, and Zilei Wang. Clearsight: Vi- sual signal enhancement for object hallucination mitigation in multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14625–14634, 2025. 2, 6
work page 2025
-
[42]
A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024. 5
work page 2024
-
[43]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625–5644, 2024. 1
work page 2024
-
[44]
Weihong Zhong, Xiaocheng Feng, Liang Zhao, Qiming Li, Lei Huang, Yuxuan Gu, Weitao Ma, Yuan Xu, and Bing Qin. Investigating and mitigating the multimodal halluci- nation snowballing in large vision-language models. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11991–12011, 2024. 2
work page 2024
-
[45]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[46]
Ibd: Alleviating hallucinations in large vision- language models via image-biased decoding
Lanyun Zhu, Deyi Ji, Tianrun Chen, Peng Xu, Jieping Ye, and Jun Liu. Ibd: Alleviating hallucinations in large vision- language models via image-biased decoding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1624–1633, 2025. 1, 2
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.