Recognition: no theorem link
On Training in Imagination
Pith reviewed 2026-05-13 01:32 UTC · model grok-4.3
The pith
In model-based RL, an optimal ratio of samples for learning dynamics versus rewards minimizes a bound on return error, while zero-mean noise in rewards adds only variance that shrinks with more imagined trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Extending error propagation analysis to MDPs that include a learned reward model produces a bound on return error whose minimum, under power-law scaling of model errors with sample counts, occurs at a specific ratio of dynamics samples to reward samples. Separately, the REINFORCE estimator applied to noisy but zero-mean rewards incurs no bias and only an additive variance penalty that falls as the number of imagined rollouts increases, turning the choice between noisy-cheap and accurate-expensive rewards into a one-dimensional optimization over rollout count.
What carries the argument
The return-error bound obtained by propagating Lipschitz constants of the learned dynamics, reward, and policy through the imagined trajectory; its minimization under power-law scaling yields the optimal sample allocation.
If this is right
- Allocating a larger fraction of samples to dynamics learning than to reward learning reduces the overall return error bound for any fixed total budget.
- Reducing the Lipschitz constants of the learned dynamics, reward function, or policy tightens the same bound and improves the guaranteed performance of the resulting policy.
- Zero-mean noise in the reward model can be offset by increasing the number of imagined rollouts, since the resulting variance in the gradient estimate decreases with rollout count.
- The optimal allocation can be found by solving a one-dimensional optimization problem once the power-law exponents and relative costs are known.
Where Pith is reading between the lines
- If the power-law exponents differ across environments, the optimal ratio itself becomes a quantity that can be estimated online during training.
- Representations that reduce Lipschitz constants may improve not only the error bound but also the sample efficiency of the overall pipeline.
- The same allocation logic could be applied to decide how many real-environment samples to interleave with imagined ones when a hybrid training loop is feasible.
Load-bearing premise
Model prediction errors decrease with the number of training samples according to power-law scaling.
What would settle it
In a synthetic MDP where dynamics and reward models are trained on increasing sample counts and their prediction errors are measured, check whether the observed return error is smallest at the allocation ratio predicted by minimizing the derived bound.
Figures


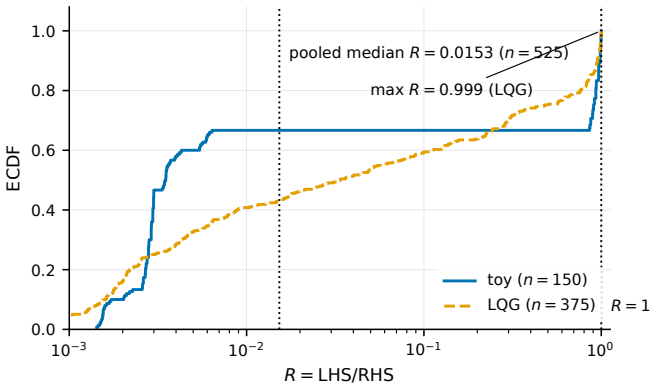
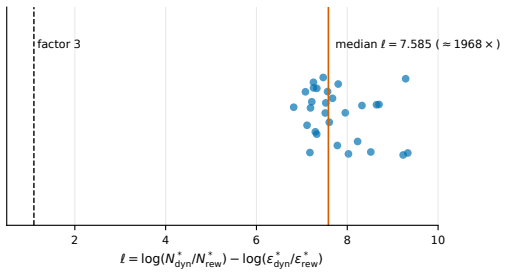

read the original abstract
State-of-the-art model-based reinforcement learning methods train policies on imagined rollouts. These rollouts are trajectories generated by a learned dynamics model and are scored by a learned reward model, but without querying the true environment during policy updates. We study this training paradigm by quantifying how errors in learned dynamics and reward models affect returns and policy optimization. First, we extend the analysis of Asadi et al. (2018) to MDPs with learned reward models, and derive the optimal sample allocation--the ratio of dynamics samples to reward samples that minimizes a bound on return error under power-law scaling assumptions. We identify lower Lipschitz constants of the learned dynamics, reward, and policy as a representation desideratum that tightens this bound, and we connect this perspective to the temporal-straightening objective of Wang et al. (2026). Second, we examine how policy optimization with REINFORCE tolerates noisy rewards, which are often cheaper to obtain. We show that zero-mean reward noise leaves the gradient estimator unbiased and adds at most a variance term that decreases with the number of rollouts. This introduces a practical tradeoff: given a fixed budget, should one buy more rollouts with cheaper but noisier rewards, or fewer rollouts with more expensive but less noisy rewards? We reduce this choice to a one-dimensional optimization problem and characterize the optimum.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies policy training on imagined rollouts generated by learned dynamics and reward models in model-based RL. It extends the analysis of Asadi et al. (2018) to MDPs with learned reward models, derives the optimal ratio of dynamics samples to reward samples that minimizes a bound on return error under power-law scaling assumptions on model errors, identifies lower Lipschitz constants of the learned models and policy as a representation desideratum, and connects this to the temporal-straightening objective of Wang et al. (2026). It further shows that zero-mean reward noise leaves the REINFORCE gradient estimator unbiased (adding only a variance term that decreases with the number of rollouts) and reduces the resulting sample-allocation tradeoff under a fixed budget to a one-dimensional optimization problem.
Significance. If the power-law scaling assumptions hold and the derived bound is tight, the optimal sample-allocation result would provide a concrete, theoretically grounded guideline for resource allocation between dynamics and reward modeling in imagination-based MBRL, which is a practical contribution. The unbiasedness result for noisy rewards is a clean, self-contained finding that clarifies when cheaper noisy rewards can be substituted without biasing policy gradients. The Lipschitz-constant perspective and link to Wang et al. (2026) are interesting but secondary. The work is strengthened by its explicit extension of prior analysis and reduction of the noise tradeoff to a simple optimization, but the lack of verification for the scaling laws limits immediate applicability.
major comments (1)
- [extension of Asadi et al. (2018) and optimal sample allocation derivation] The derivation of the optimal dynamics-to-reward sample ratio (first main contribution, extending Asadi et al. (2018)) minimizes a return-error bound that is constructed under the assumption that both dynamics and reward model errors decay as power laws with sample count, with the exponents treated as known constants. The manuscript provides neither an empirical fit of these exponents for learned reward models nor a demonstration that the bound remains valid when the models are trained jointly with the policy; if the actual scaling saturates or follows a different form, the claimed optimum no longer minimizes the true error.
minor comments (2)
- [REINFORCE with noisy rewards section] The characterization of the one-dimensional optimum for the noisy-reward tradeoff is stated but would benefit from an explicit statement of the objective function and the conditions under which the optimum is interior versus at a boundary.
- [notation and bound definition] Notation for the return-error bound and the Lipschitz constants could be introduced with a short reminder of the relevant definitions from Asadi et al. (2018) to improve readability for readers who have not recently consulted that reference.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comment below, providing a point-by-point response while remaining honest about the scope of the current theoretical analysis.
read point-by-point responses
-
Referee: [extension of Asadi et al. (2018) and optimal sample allocation derivation] The derivation of the optimal dynamics-to-reward sample ratio (first main contribution, extending Asadi et al. (2018)) minimizes a return-error bound that is constructed under the assumption that both dynamics and reward model errors decay as power laws with sample count, with the exponents treated as known constants. The manuscript provides neither an empirical fit of these exponents for learned reward models nor a demonstration that the bound remains valid when the models are trained jointly with the policy; if the actual scaling saturates or follows a different form, the claimed optimum no longer minimizes the true error.
Authors: We agree that the optimal ratio minimizes the derived bound under the explicit power-law scaling assumption with known exponents, as stated in the manuscript (see Section 3 and the extension of Asadi et al.). This is a theoretical result providing a guideline when the assumption holds, rather than an empirical claim that the scaling always applies. The manuscript does not contain empirical fits of the exponents for reward models because the contribution is analytic; we treat the exponents as parameters that can be estimated from data in practice. We will revise the paper to add an explicit discussion paragraph acknowledging this limitation and noting that empirical estimation of the exponents (e.g., via log-log plots of model error vs. sample count) would be a natural next step for applicability. On joint training with the policy: the return-error bound is derived conditionally on the realized model errors after a given number of samples; the power-law assumption governs how those errors decrease with additional samples. Joint optimization may alter the effective exponents but does not invalidate the minimization step for any fixed exponents. We will add a clarifying sentence in the discussion to make this conditional nature explicit. revision: partial
Circularity Check
No circularity: derivations are conditional on external power-law assumptions and extend independent prior work.
full rationale
The paper's central derivation of optimal sample allocation explicitly minimizes a return-error bound under stated power-law scaling assumptions on model error decay (error ~ N^{-α}), which are treated as given constants rather than fitted or self-defined within the paper. This is an extension of Asadi et al. (2018) to learned reward models, with no reduction of the optimum to quantities defined by the authors' own parameters or results. The REINFORCE noise analysis is a standard unbiasedness argument that adds a variance term without circularity. No self-citations are load-bearing, no ansatz is smuggled, and no prediction reduces by construction to its inputs; the claims remain conditional on the external assumptions and prior analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Error in learned dynamics and reward models scales as a power law with the number of samples
- domain assumption The MDP setting and Lipschitz continuity assumptions from Asadi et al. (2018) extend to learned reward models
Reference graph
Works this paper leans on
-
[1]
Kavosh Asadi, Evan Cater, Dipendra Misra, and Michael L Littman. Equivalence between wasserstein and value-aware loss for model-based reinforcement learning.arXiv preprint arXiv:1806.01265, 2018a. Kavosh Asadi, Dipendra Misra, and Michael Littman. Lipschitz continuity in model-based rein- forcement learning. InInternational conference on machine learning,...
-
[2]
Colin Bellinger, Rory Coles, Mark Crowley, and Isaac Tamblyn. Active measure reinforcement learning for observation cost minimization.arXiv preprint arXiv:2005.12697,
-
[3]
Xin-Qiang Cai, Wei Wang, Feng Liu, Tongliang Liu, Gang Niu, and Masashi Sugiyama. Rein- forcement learning with verifiable yet noisy rewards under imperfect verifiers.arXiv preprint arXiv:2510.00915,
-
[4]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Agents Inside of Scalable World Models
URLhttps://openreview.net/forum?id=S1lOTC4tDS. Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025a. Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models. arXiv preprint arXiv:2509.24527, 2025b. Haoyu Han and He...
work page internal anchor Pith review arXiv
-
[6]
Mikael Henaff, Arthur Szlam, and Yann LeCun
URLhttps://proceedings.mlr.press/v162/hansen22a.html. Mikael Henaff, Arthur Szlam, and Yann LeCun. Recurrent orthogonal networks and long-memory tasks. InInternational Conference on Machine Learning, pages 2034–2042. PMLR,
work page 2034
-
[7]
Scaling laws for single-agent reinforcement learning
Jacob Hilton, Jie Tang, and John Schulman. Scaling laws for single-agent reinforcement learning. arXiv preprint arXiv:2301.13442,
-
[8]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[10]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62,
work page 2022
-
[11]
Richard S Sutton. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. InMachine learning proceedings 1990, pages 216–224. Elsevier,
work page 1990
-
[12]
Temporal straightening for latent planning.arXiv preprint arXiv:2603.12231, 2026
Ying Wang, Oumayma Bounou, Gaoyue Zhou, Randall Balestriero, Tim GJ Rudner, Yann LeCun, and Mengye Ren. Temporal straightening for latent planning.arXiv preprint arXiv:2603.12231,
-
[13]
learn a latent dynamics model from pixels and train a policy primarily inside this learned model. Dreamer [Hafner et al., 2020] learns a latent-space dynamics model together with a learned reward predictor and optimizes the policy entirely on imagined latent rollouts. Schrittwieser et al
work page 2020
-
[14]
recently establish optimal tightness for the simulation lemma. A parallel line of work asks whether the model loss should target value prediction rather than raw transition accuracy: value-aware model learning [Farahmand et al., 2017] replaces the next-state likelihood objective with a loss measuring the worst-case discrepancy between the true and learned...
work page 2017
-
[15]
addresses how to learn the reward function on states drawn from a misspecified dynamics model. 12 Active observation and simulation budget allocation.Active-measure reinforcement learning chooses when to pay for an observation under explicit observation costs [Bellinger et al., 2020]. In the simulation-optimization literature, optimal computing budget all...
work page 2020
-
[16]
have since been reported for single-agent reinforcement learning and for pre-training of agents and world models [Hilton et al., 2023, Pearce et al., 2025]. Policy-gradient theory and reward modeling.Beyond Williams [1992], the policy-gradient theorem of Sutton et al
work page 2023
-
[17]
characterize how theREINFORCEnoise-to-signal ratio varies non-uniformly across the parameter landscape. Reinforcement learning from human feedback trains reward models from preferences [Christiano et al., 2017, Stiennon et al., 2020], the empirical setting in which Gao et al
work page 2017
-
[18]
tanh-value and sin-value configurations (n= 9 each, panel (a) of Figure 2).For each of these two value-function families, the Cartesian product is sigma_ratio∈ {0.3,1.0,3.0} crossed with cost_ratio∈ {0.1,1.0,10.0}, withL f =L r =λ= 1fixed. Quadratic-value sup-norm-control configurations (n= 9 , panel (b) of Figure 2).The Cartesian product is the same sigm...
work page 1968
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.