Recognition: no theorem link
Sparse Attention as a Range Searching Problem: Towards an Inference-Efficient Index for KV Cache
Pith reviewed 2026-05-12 02:40 UTC · model grok-4.3
The pith
Reformulating sparse attention as halfspace range searching yields an index that guarantees zero false negatives for critical KV entries in LLM decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
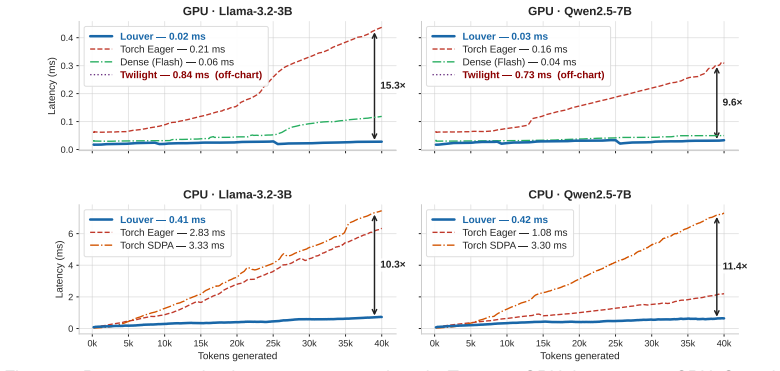
Louver is a novel index structure that reformulates sparse attention as the halfspace range searching problem, guaranteeing zero false negatives with respect to a specified threshold in both theory and practice, remaining lightweight for integration into existing LLM pipelines, and incorporating hardware-aware optimizations for CPU and GPU executions that together deliver higher accuracy and lower runtime than previous sparse attention methods while also running faster than highly optimized dense attention such as FlashAttention.
What carries the argument
Louver, an index structure for KV cache retrieval that solves halfspace range queries to enforce full recall of keys above a fixed importance threshold.
If this is right
- Louver can be dropped into existing LLM inference pipelines with only lightweight changes.
- It eliminates the risk of sharp error spikes caused by omitted critical keys in long reasoning sequences.
- Hardware-aware CPU and GPU implementations make the index faster than prior sparse methods and than FlashAttention.
- Recall guarantees become a first-class design criterion for future KV cache management techniques.
Where Pith is reading between the lines
- The halfspace formulation could be extended to other dynamic token-selection problems such as retrieval-augmented generation or multimodal attention.
- Combining Louver-style guarantees with quantization or speculative decoding may produce even larger efficiency gains while preserving correctness.
- The same range-query view might inspire theoretically grounded indices for other memory-intensive inference workloads beyond attention.
Load-bearing premise
Relevance of KV entries can be captured by halfspace range queries defined from the current query and a fixed threshold on key importance is sufficient to prevent accuracy degradation even when critical tokens change across steps.
What would settle it
A long-context reasoning trace in which Louver still produces output errors after retrieving every key above the stated threshold, or direct measurement showing that a key with importance above the threshold lies outside the computed halfspace.
Figures








read the original abstract
Sparse attention improves LLM inference efficiency by selecting a subset of key-value entries, but at the cost of potential accuracy degradation. In particular, omitting critical KV entries can induce substantial errors in model outputs. Existing methods typically operate under fixed or adaptive token budgets and provide empirical robustness or partial theoretical guarantees, yet they do not ensure zero false negatives in decoding steps, particularly since the set of relevant tokens is both query- and step-dependent. Our empirical observations confirm that missing even one critical key can lead to sharp error spikes, especially in long reasoning tasks where the set of important tokens varies throughout decoding. This observation motivates the need for indexing methods that dynamically adapt to these variations across decoding steps while guaranteeing a full recall of the relevant keys above a certain threshold. We address this challenge by reformulating sparse attention as the halfspace range searching problem. However, existing range searching indices are not suitable for modern LLM inference due to their computational and implementation overheads. To overcome this, we introduce Louver, a novel index structure tailored for efficient KV cache retrieval. Louver (i) guarantees zero false negatives with respect to a specified threshold in both theory and practice, (ii) is lightweight to integrate into existing LLM pipelines, and (iii) incorporates hardware-aware optimizations for both CPU and GPU executions. Our experiments demonstrate that Louver outperforms prior sparse attention methods in both accuracy and runtime, and is faster than highly optimized dense attentions such as FlashAttention. These results highlight that recall guarantees are a critical and overlooked dimension of sparse attention, and open a new direction for building theoretically grounded, efficient KV cache indices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sparse attention can be reformulated as a halfspace range searching problem to enable an index (Louver) for KV cache retrieval during LLM inference. Louver is asserted to guarantee zero false negatives for keys above a specified importance threshold (in both theory and practice), to be lightweight for integration into existing pipelines, and to include hardware-aware optimizations for CPU and GPU. Experiments are said to show outperformance over prior sparse attention methods in accuracy and runtime, as well as being faster than optimized dense attention such as FlashAttention.
Significance. If the zero false-negative guarantees and empirical outperformance hold, the work would be significant for LLM inference, as it targets the overlooked issue of missing critical, query- and step-dependent tokens in long reasoning tasks and provides a theoretically grounded alternative to budget-based sparse attention.
major comments (2)
- Abstract: The central claim that Louver 'guarantees zero false negatives with respect to a specified threshold in both theory and practice' is load-bearing for the contribution, yet the abstract supplies no derivation, proof sketch, construction of the halfspaces, or argument showing why a fixed threshold suffices when relevant tokens vary across decoding steps.
- Abstract: The claim that 'Louver outperforms prior sparse attention methods in both accuracy and runtime, and is faster than highly optimized dense attentions such as FlashAttention' is load-bearing for the practical significance, yet the abstract provides no experimental setup, baselines, metrics, datasets, or quantitative results to support the comparison.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our work. We address the two major comments point by point below.
read point-by-point responses
-
Referee: Abstract: The central claim that Louver 'guarantees zero false negatives with respect to a specified threshold in both theory and practice' is load-bearing for the contribution, yet the abstract supplies no derivation, proof sketch, construction of the halfspaces, or argument showing why a fixed threshold suffices when relevant tokens vary across decoding steps.
Authors: We agree that the abstract does not contain a proof sketch or halfspace construction; abstracts are length-constrained summaries. The reformulation of sparse attention as halfspace range searching, the explicit construction of the halfspaces used by Louver, the proof that all keys above the chosen threshold are retrieved (zero false negatives), and the justification that a single fixed threshold suffices despite query- and step-dependent relevance (via the observation that importance scores can be bounded relative to the current query) appear in the theoretical analysis section of the manuscript. The abstract states the guarantee and the motivating observation that missing even one critical key produces sharp error spikes; the supporting arguments are in the body. revision: no
-
Referee: Abstract: The claim that 'Louver outperforms prior sparse attention methods in both accuracy and runtime, and is faster than highly optimized dense attentions such as FlashAttention' is load-bearing for the practical significance, yet the abstract provides no experimental setup, baselines, metrics, datasets, or quantitative results to support the comparison.
Authors: The abstract summarizes the outcome of the experiments without the full protocol, which is conventional to respect length limits. The experimental setup (including the precise sparse-attention baselines, FlashAttention implementation, accuracy and latency metrics, long-reasoning datasets, and quantitative speedups and accuracy deltas) is reported in full in the Experiments section. The abstract therefore highlights only the headline result that the recall guarantee translates into measurable gains over both prior sparse methods and optimized dense attention. revision: no
Circularity Check
No significant circularity
full rationale
The abstract presents a reformulation of sparse attention as halfspace range searching followed by the introduction of a new index (Louver) with stated theoretical and practical guarantees of zero false negatives above a threshold. No equations, fitted parameters, self-citations, or derivation steps are supplied that would reduce any claimed result to its own inputs by construction. The guarantees and performance claims are asserted as outcomes of the newly constructed index rather than as tautological restatements of prior fits or definitions, rendering the derivation chain self-contained on the basis of the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The set of relevant KV entries for a query can be exactly represented as the result of a halfspace range query in the embedding space.
invented entities (1)
-
Louver index
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.