Recognition: no theorem link
Dataset Watermarking for Closed LLMs with Provable Detection
Pith reviewed 2026-05-11 00:48 UTC · model grok-4.3
The pith
By rephrasing text to boost specific word-pair co-occurrences, a dataset can be watermarked for closed LLMs with statistical detection provable even after mixed fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that increasing the co-occurrence frequency of randomly selected word pairs through rephrasing embeds a dataset-level watermark signal that can be recovered from model outputs via a statistical test on those same co-occurrence patterns. This signal remains detectable after fine-tuning, including in realistic mixtures where the watermarked data accounts for roughly 1 percent of total tokens, and the rephrasing step does not degrade the original utility or semantic properties of the benchmark data.
What carries the argument
Rephrasing to raise co-occurrence rates of chosen word pairs, which creates the detectable statistical signal tested on model-generated outputs.
If this is right
- Detection remains reliable throughout the fine-tuning stage with p-value below 0.01.
- The signal persists when the watermarked dataset forms only approximately 1 percent of the total fine-tuning tokens.
- Original benchmark performance and semantic content are preserved after the rephrasing step.
- The method applies across multiple base models and standard benchmark datasets.
Where Pith is reading between the lines
- Dataset owners could apply this technique to later verify whether their proprietary data appeared in training runs of closed models.
- The same co-occurrence boosting idea might be tested for robustness against deliberate removal attempts such as adversarial fine-tuning or data filtering.
- Related signals could be explored for non-text training data where statistical patterns in outputs are still observable.
Load-bearing premise
That the boosted word-pair co-occurrences will reliably appear in the model's generated text after fine-tuning and can be distinguished from natural variation or other training influences.
What would settle it
A controlled experiment in which a model fine-tuned on the watermarked data produces outputs whose word-pair statistics show no significant elevation relative to an identical model trained on the non-watermarked version of the same data.
Figures



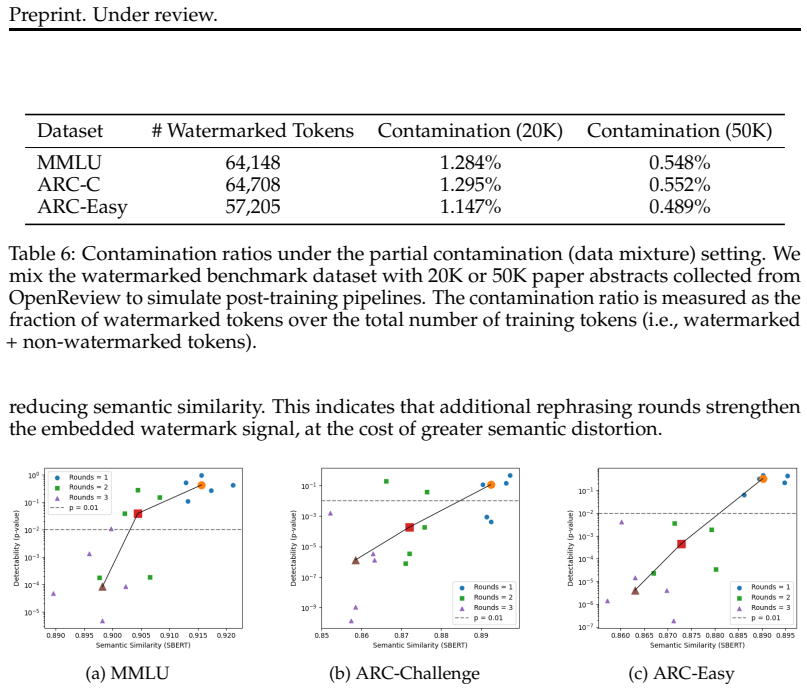
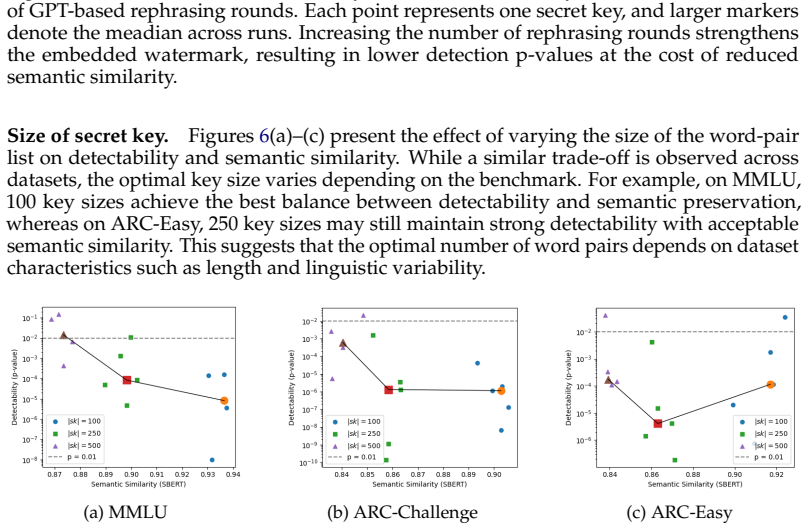
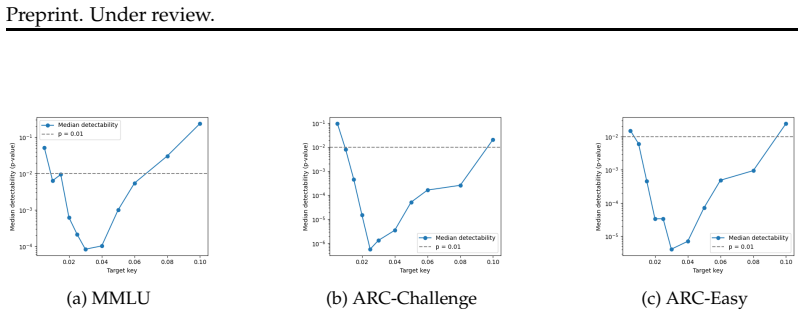
read the original abstract
Large language models (LLMs) are pre-trained and post-trained on vast amounts of loosely curated data, raising the possibility that these models may have been trained on proprietary datasets or the same benchmarks used for evaluation. This motivates the need for dataset watermarking: designing datasets such that training on them leaves detectable signatures in the resulting model. Prior work has explored this problem for open models. We introduce the first dataset watermarking method for closed LLMs with provable detection. In particular, we embed a dataset-level watermark signal by increasing the co-occurrence frequency of randomly selected word pairs through rephrasing, and detect it using a statistical test on co-occurrence patterns in model-generated outputs. We evaluate our method with multiple base models and benchmark datasets and show that it reliably detects the watermark ($p <0.01$) in the fine-tuning stage. Notably, our method remains effective in a data mixture setting where the watermarked dataset constitutes only approximately $1\%$ of the total fine-tuning tokens. Furthermore, we show that our method preserves the utility and semantic integrity of the benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first dataset watermarking method for closed LLMs. It embeds a signal by rephrasing text to increase co-occurrence frequencies of randomly selected word pairs, then detects the watermark via a statistical test on co-occurrence patterns in model outputs. Experiments claim reliable detection (p<0.01) after fine-tuning, including when watermarked data is only ~1% of tokens, while preserving benchmark utility and semantics.
Significance. If the central claims hold with full experimental and statistical details, the work would provide a practical tool for detecting unauthorized use of proprietary datasets in closed-model training, filling a gap left by prior open-model watermarking. The low-mixture effectiveness and utility preservation are potentially impactful for real-world deployment, though the absence of explicit bounds or test specifications limits immediate adoption.
major comments (2)
- [Abstract] Abstract: the claim of 'provable detection' with p<0.01 success lacks any description of the exact statistical test, null distribution, multiple-testing correction, or power analysis. This is load-bearing for the core contribution, as the detection method must be shown to distinguish the induced signal from natural variation without excessive false positives.
- [Abstract] Abstract and evaluation: no derivation, bound, or controlled ablation demonstrates that the rephrasing-induced co-occurrence delta survives gradient updates when the watermarked data is only ~1% of fine-tuning tokens. The central claim that the signal imprints reliably enough for detection therefore rests on unverified propagation from dataset statistics to model behavior.
minor comments (1)
- [Abstract] The abstract mentions 'multiple base models and benchmark datasets' but provides no table or section reference listing them or reporting per-model variance in detection rates.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, agreeing to expand the description of the statistical test and to strengthen the empirical evidence for signal persistence with additional ablations. These changes will be incorporated in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'provable detection' with p<0.01 success lacks any description of the exact statistical test, null distribution, multiple-testing correction, or power analysis. This is load-bearing for the core contribution, as the detection method must be shown to distinguish the induced signal from natural variation without excessive false positives.
Authors: We agree that the abstract and main text require a more explicit description of the detection procedure. In the revision we will add a dedicated subsection detailing the exact hypothesis test (a one-sided test on elevated co-occurrence counts for the chosen word pairs), the null distribution (binomial with parameters fitted from non-watermarked reference outputs), the multiple-testing correction (Bonferroni across the fixed set of pairs), and a power analysis confirming that the number of generations used in our experiments yields p < 0.01 with high probability under the observed signal strength. This will make the 'provable detection' claim fully transparent. revision: yes
-
Referee: [Abstract] Abstract and evaluation: no derivation, bound, or controlled ablation demonstrates that the rephrasing-induced co-occurrence delta survives gradient updates when the watermarked data is only ~1% of fine-tuning tokens. The central claim that the signal imprints reliably enough for detection therefore rests on unverified propagation from dataset statistics to model behavior.
Authors: The manuscript already reports consistent detection (p < 0.01) across multiple models and benchmarks at the 1 % mixture level, providing direct empirical evidence that the co-occurrence signal reaches the fine-tuned model. We acknowledge, however, the absence of a theoretical bound or controlled ablation that isolates the effect of gradient updates on the delta. We will therefore add a new set of controlled experiments that vary the watermarked-token fraction while measuring the co-occurrence statistics both in the training data and in the model's generated outputs before and after fine-tuning. While a closed-form propagation bound is difficult given the non-convex training dynamics, the expanded ablation will substantially strengthen the empirical support for the low-mixture claim. revision: partial
Circularity Check
No circularity: embedding via rephrasing and detection via output statistics are independent empirical steps
full rationale
The paper proposes a concrete procedure—select random word pairs, rephrase data to raise their co-occurrence frequency, fine-tune, then apply a statistical test to generated outputs—without any equation, parameter, or uniqueness claim that reduces to its own inputs by definition or self-citation. The detection result is an observed empirical outcome on held-out generations, not a fitted quantity renamed as a prediction or a bound derived from the same rephrasing statistics. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the described chain; the method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- word pair selection
- rephrasing parameters
axioms (2)
- domain assumption Training on data with elevated word-pair co-occurrence causes the model to generate outputs with similarly elevated co-occurrence rates.
- domain assumption The statistical test on output co-occurrence patterns can achieve low false-positive rates under the null hypothesis of no watermark.
Reference graph
Works this paper leans on
-
[1]
Extracting training data from large language models
URL https://arxiv.org/abs/2012.07805. Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, et al. Benchmarking large language models under data contamination: A survey from static to dynamic evaluation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp...
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
URLhttps://arxiv.org/abs/1803.05457. Maria Eriksson, Erasmo Purificato, Arman Noroozian, Joao Vinagre, Guillaume Chaslot, Emilia Gomez, and David Fernandez-Llorca. Can we trust ai benchmarks? an interdis- ciplinary review of current issues in ai evaluation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URL https://arxiv.org/abs/ 2502.06559. Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang...
-
[4]
URL https://zenodo.org/ records/12608602. Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, November
-
[5]
ISSN 2522-5839. doi: 10.1038/ s42256-020-00257-z. URLhttp://dx.doi.org/10.1038/s42256-020-00257-z. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s42256-020-00257-z
-
[6]
Measuring Massive Multitask Language Understanding
URL https://arxiv.org/abs/2009.03300. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
URLhttps://arxiv.org/abs/2106.09685. 10 Preprint. Under review. Minhao Jiang, Ken Ziyu Liu, Ming Zhong, Rylan Schaeffer, Siru Ouyang, Jiawei Han, and Sanmi Koyejo. Investigating data contamination for pre-training language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein
URLhttps://arxiv.org/abs/2401.06059. John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational conference on machine learning, pp. 17061–17084. PMLR,
-
[9]
On the reliability of watermarks for large language models,
URLhttps://arxiv.org/abs/2306.04634. Gregory Kang Ruey Lau, Xinyuan Niu, Hieu Dao, Jiangwei Chen, Chuan-Sheng Foo, and Bryan Kian Hsiang Low. Waterfall: Framework for robust and scalable text watermarking and provenance for llms,
-
[10]
Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic
URLhttps://arxiv.org/abs/2407.04411. Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic. Llm dataset inference: Did you train on my dataset?,
-
[11]
Casey Meehan, Florian Bordes, Pascal Vincent, Kamalika Chaudhuri, and Chuan Guo
URLhttps://arxiv.org/abs/2406.06443. Casey Meehan, Florian Bordes, Pascal Vincent, Kamalika Chaudhuri, and Chuan Guo. Do ssl models have déjà vu? a case of unintended memorization in self-supervised learning,
-
[12]
Niels Mündler, Jasper Dekoninck, Nikola Jovanovi´ c, Ivo Petrov, and Martin Vechev
URLhttps://arxiv.org/abs/2304.13850. Niels Mündler, Jasper Dekoninck, Nikola Jovanovi´ c, Ivo Petrov, and Martin Vechev. De- bunking the claims of k2-think. https://www.sri.inf.ethz.ch/blog/k2think,
- [13]
-
[14]
Detecting benchmark contamination through watermarking.arXiv preprint arXiv:2502.17259,
URL https://arxiv.org/abs/ 2502.17259. Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models,
-
[15]
Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
URLhttps://arxiv.org/abs/2310.16789. Aaditya K. Singh, Muhammed Yusuf Kocyigit, Andrew Poulton, David Esiobu, Maria Lomeli, Gergely Szilvasy, and Dieuwke Hupkes. Evaluation data contamination in llms: how do we measure it and (when) does it matter?,
-
[16]
URL https://arxiv.org/abs/ 2411.03923. Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
-
[17]
URL https://arxiv.org/abs/2006. 09994. Cheng Xu, Shuhao Guan, Derek Greene, and M-Tahar Kechadi. Benchmark data contamina- tion of large language models: A survey,
2006
-
[18]
arXiv preprint arXiv:2406.04244 , year=
URL https://arxiv.org/abs/2406.04244. 11 Preprint. Under review. Yao-Yuan Yang, Chi-Ning Chou, and Kamalika Chaudhuri. Understanding rare spurious correlations in neural networks,
-
[19]
arXiv preprint arXiv:2202.05189 , year=
URLhttps://arxiv.org/abs/2202.05189. Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting,
-
[20]
URL https://arxiv.org/abs/ 1709.01604. Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele Lunati, and Summer Yue. A careful examination of large language model performance on grade school arithmetic,
- [21]
-
[22]
BERTScore: Evaluating Text Generation with BERT
URLhttps://arxiv.org/abs/1904.09675. Appendix Overview This appendix provides additional details, experimental results, and analyses that comple- ment the main text. • Appendix A:We provide the prompts used for dataset rephrasing, along with illustrative examples of watermarked samples. • Appendix B:We describe baseline details and data mixture ratios for...
work page internal anchor Pith review Pith/arXiv arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.