Recognition: 2 theorem links
· Lean TheoremStreaming Adversarial Robustness in Fuzzy ARTMAP: Mechanism-Aligned Evaluation, Progressive Training, and Interpretable Diagnostics
Pith reviewed 2026-05-11 01:19 UTC · model grok-4.3
The pith
Progressive two-stage selective training delivers the strongest replay-free adversarial robustness for Fuzzy ARTMAP under mechanism-aligned white-box attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
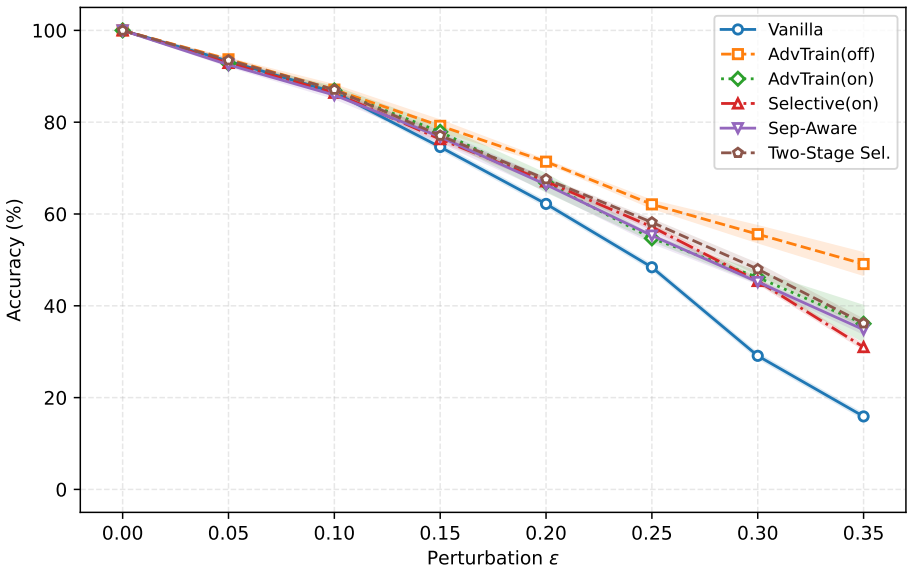
Fuzzy ARTMAP models trained in a strict single-pass streaming manner are highly vulnerable to WB-Softmax, a white-box attack surrogate aligned with the architecture's category-competition and map-field prediction mechanisms, reaching 89-100 percent success on vanilla versions across four image benchmarks. When robustness is measured only on the final model after streaming updates, defense rankings reverse across protocols: offline adversarial training appears effective under transfer attacks yet collapses under adaptive white-box evaluation, whereas progressive two-stage selective training supplies the strongest replay-free robustness. The explicit geometry of ART categories further permits
What carries the argument
WB-Softmax, a differentiable white-box attack surrogate aligned with Fuzzy ARTMAP's category-competition and map-field prediction mechanism
If this is right
- Defense rankings reverse when evaluation shifts from transfer attacks to adaptive white-box attacks under the streaming protocol.
- Offline adversarial training collapses when subjected to adaptive white-box evaluation in single-pass streaming settings.
- Progressive two-stage selective training achieves the strongest overall replay-free robustness across the tested benchmarks.
- ART category geometry enables direct diagnosis of attack success through separation collapse and match-score inversion.
Where Pith is reading between the lines
- Similar mechanism-aligned attacks and progressive defenses may prove necessary for other streaming or prototype-based learners that operate without replay.
- The interpretable geometric diagnostics could support automated detection and correction of vulnerable categories during ongoing streaming updates.
- The observed reversal in defense performance suggests that results from offline deep-network robustness literature may not transfer directly to single-pass online learners.
Load-bearing premise
The claim rests on the premise that robustness should be judged exclusively on the final model after all single-pass streaming updates, using only the four image benchmarks as representative threat models for prototype-based networks.
What would settle it
An experiment in which an adaptive WB-Softmax attack on a progressively trained model achieves attack success rates above 70 percent on one of the four benchmarks would falsify the superiority of progressive two-stage selective training under the streaming protocol.
Figures


read the original abstract
Adversarial robustness has been studied extensively for offline deep networks, but less is known about strict single-pass streaming neural learners. This paper studies adversarial robustness in Fuzzy ARTMAP, an Adaptive Resonance Theory architecture based on category competition, complement coding, match tracking, and replay-free prototype updates. We introduce WB-Softmax, a differentiable white-box attack surrogate aligned with ARTMAP's category-competition and map-field prediction mechanism, and formalize a streaming evaluation principle requiring robustness to be assessed on the final deployed model. Across four image benchmarks, WB-Softmax achieves 89-100% attack success on vanilla Fuzzy ARTMAP models. We show that defense rankings can reverse across protocols: offline adversarial training may appear strong under transfer attacks yet collapse under adaptive white-box evaluation, whereas progressive two-stage selective training provides the strongest overall replay-free robustness. We further show that ART's explicit category geometry enables interpretable diagnosis of separation collapse and match-score inversion. These results provide a mechanism-aligned, protocol-aware framework for adversarial robustness in streaming prototype-based learners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Fuzzy ARTMAP, a prototype-based streaming learner using category competition, complement coding, match tracking, and replay-free updates, is vulnerable to a new mechanism-aligned white-box attack (WB-Softmax) that achieves 89-100% success on vanilla models across four image benchmarks. It formalizes a streaming evaluation principle (robustness measured only on the final model after single-pass training) and shows that defense rankings reverse across protocols: offline adversarial training appears strong under transfer attacks but collapses under adaptive white-box evaluation, while progressive two-stage selective training yields the strongest replay-free robustness. The work also provides interpretable diagnostics of separation collapse and match-score inversion via ART's explicit category geometry.
Significance. If the central empirical claims hold under a strictly single-pass protocol, the paper offers a useful mechanism-aligned framework for assessing and improving adversarial robustness in streaming prototype-based networks, where most prior work focuses on offline deep networks. The concrete attack-success numbers, protocol-reversal demonstration, and geometry-based diagnostics are strengths that could inform future streaming defenses; the absence of free parameters or invented entities in the core claims is also positive.
major comments (2)
- [Progressive Training Description] Progressive two-stage selective training section: the claim that this procedure delivers the strongest replay-free robustness requires an explicit demonstration that the selective stage performs only single-pass updates with no data buffering, prototype rehearsal, or multi-epoch revisits to earlier stream elements. Any such mechanism would invalidate both the replay-free assertion in the abstract and the direct comparison to offline adversarial training under the streaming evaluation principle.
- [Evaluation Protocol] Streaming evaluation principle and methods: the central ranking-reversal result depends on the precise definition of 'final deployed model' and the exclusion of any post-hoc data selection or hyper-parameter tuning that could affect the reported 89-100% WB-Softmax success rates and defense comparisons; without these details the protocol-aware claims rest on an assumption whose appropriateness for real-world streaming learners is not fully justified by the four benchmarks alone.
minor comments (1)
- [Attack Formulation] Notation for WB-Softmax surrogate loss should be introduced with an equation number and contrasted explicitly with standard cross-entropy to clarify the alignment with category competition and map-field prediction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help clarify key aspects of our streaming evaluation framework and progressive training procedure. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Progressive Training Description] Progressive two-stage selective training section: the claim that this procedure delivers the strongest replay-free robustness requires an explicit demonstration that the selective stage performs only single-pass updates with no data buffering, prototype rehearsal, or multi-epoch revisits to earlier stream elements. Any such mechanism would invalidate both the replay-free assertion in the abstract and the direct comparison to offline adversarial training under the streaming evaluation principle.
Authors: We agree that the description of the selective stage requires greater explicitness to confirm strict single-pass compliance. The original manuscript states that progressive training is replay-free and operates on the incoming stream, but we will revise the section to include a formal algorithmic specification and pseudocode. This will demonstrate that the selective stage performs only one update per stream element with no buffering, rehearsal, or revisits, thereby supporting the replay-free claim and the validity of comparisons to offline adversarial training under the streaming protocol. revision: yes
-
Referee: [Evaluation Protocol] Streaming evaluation principle and methods: the central ranking-reversal result depends on the precise definition of 'final deployed model' and the exclusion of any post-hoc data selection or hyper-parameter tuning that could affect the reported 89-100% WB-Softmax success rates and defense comparisons; without these details the protocol-aware claims rest on an assumption whose appropriateness for real-world streaming learners is not fully justified by the four benchmarks alone.
Authors: We will expand the methods section to provide a precise definition of the 'final deployed model' as the network state immediately after single-pass processing of the full stream, with all hyperparameters fixed in advance and no post-hoc data selection or tuning permitted. The absence of such mechanisms in the reported experiments will be stated explicitly. Regarding real-world justification, the four benchmarks serve to illustrate the protocol reversal and the utility of the mechanism-aligned framework; while additional diverse streaming scenarios would strengthen generalizability, the formalized streaming evaluation principle itself is independent of any specific benchmark count and we will highlight this distinction more clearly in the discussion. revision: partial
Circularity Check
No significant circularity; claims rest on empirical evaluation
full rationale
The paper defines a streaming evaluation principle and introduces WB-Softmax as a mechanism-aligned attack surrogate, then reports empirical attack success rates (89-100%) and comparative defense performance across four benchmarks. Progressive two-stage selective training is presented as replay-free by description of its single-pass prototype updates, with robustness gains shown via direct measurement rather than any equation that reduces the reported outcome to a fitted input or self-citation by construction. No load-bearing step equates a prediction to its own training data or imports uniqueness solely from prior self-work without independent verification. The central results remain falsifiable through external replication on the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robustness must be evaluated on the final deployed model after all single-pass updates (streaming evaluation principle).
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WB-Softmax: softmax-relaxed class loss... aligned with ARTMAP’s category competition and map-field structure
-
IndisputableMonolith.Foundation.RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Principle 1 (Offline Distribution Mismatch in Streaming Learners)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, R. Fergus, Intrigu- ing properties of neural networks, in: International Conference on Learning Representations (ICLR), 2014
work page 2014
-
[2]
I. J. Goodfellow, J. Shlens, C. Szegedy, Explaining and harnessing adversarial examples, arXiv preprint arXiv:1412.6572 (2014)
work page internal anchor Pith review arXiv 2014
- [3]
-
[4]
N. Carlini, D. Wagner, Towards evaluating the robustness of neural networks, in: IEEE Sym- posium on Security and Privacy (SP), IEEE, 2017, pp. 39–57
work page 2017
- [5]
- [6]
-
[7]
M. Andriushchenko, F. Croce, N. Flammarion, M. Hein, Square attack: a query-efficient black-box adversarial attack via random search, in: European Conference on Computer Vi- sion (ECCV), Springer, 2020, pp. 484–501
work page 2020
-
[8]
D. Zhao, H. Li, Q. Luo, W. Hu, Hölder Network for Improved Adversarial Robustness, Neural Networks (2025) 108145doi:10.1016/j.neunet.2025.108145
-
[9]
A. Athalye, N. Carlini, D. Wagner, Obfuscated gradients give a false sense of security: Circum- venting defenses to adversarial examples, in: International Conference on Machine Learning (ICML), PMLR, 2018, pp. 274–283
work page 2018
- [10]
- [11]
-
[12]
Z. Qian, K. Huang, Q.-F. Wang, X.-Y. Zhang, A survey of robust adversarial training in pattern recognition: Fundamental, theory, and methodologies, Pattern Recognition 131 (2022) 108889. doi:10.1016/j.patcog.2022.108889
- [13]
-
[14]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Mi- lan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, R. Hadsell, Overcoming catastrophic forgetting in neural networks, Proceedings of the Na- tional Academy of Sciences 114 (13) (2017) 3521–3526.doi:10.1073/pnas.1611835114
-
[15]
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, S. Wermter, Continual lifelong learning with neural networks: A review, Neural Networks 113 (2019) 54–71
work page 2019
-
[16]
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, T. Tuytelaars, A continual learning survey: Defying forgetting in classification tasks, IEEE Transactions on Pattern Analysis and Machine Intelligence 44 (7) (2022) 3366–3385.doi: 10.1109/TPAMI.2021.3057446
-
[17]
Z. Li, D. Hoiem, Learning without forgetting, IEEE Transactions on Pattern Analysis and Machine Intelligence 40 (12) (2018) 2935–2947.doi:10.1109/TPAMI.2017.2773081
-
[18]
D. Lopez-Paz, M. Ranzato, Gradient episodic memory for continual learning, in: Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[19]
A. Chaudhry, M. Ranzato, M. Rohrbach, M. Elhoseiny, Efficient lifelong learning with a-gem, in: International Conference on Learning Representations (ICLR), 2019
work page 2019
-
[20]
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, C. H. Lampert, iCaRL: Incremental classifier and rep- resentation learning, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5533–5542.doi:10.1109/CVPR.2017.587
-
[21]
X. Mi, F. Tang, Z. Yang, D. Wang, J. Cao, P. Li, Y. Liu, Adversarial robust memory-based continual learner, in: IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[22]
J. Bang, H. Koh, S. Park, H. Song, J.-W. Ha, J. Choi, Online continual learning on a con- taminated data stream with blurry task boundaries, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 9265–9274
work page 2022
-
[23]
S. Grossberg, Adaptive resonance theory: How a brain learns to consciously attend, learn, and recognize a changing world, Neural Networks 37 (2013) 1–47
work page 2013
-
[24]
S. Grossberg, Conscious Mind, Resonant Brain: How Each Brain Makes a Mind, Oxford Uni- versity Press, New York, 2021
work page 2021
-
[25]
L. E. Brito da Silva, I. Elnabarawy, D. C. Wunsch II, A survey of adaptive resonance theory neural network models for engineering applications, Neural Networks 120 (2019) 167–203.doi: 10.1016/j.neunet.2019.09.012
-
[26]
G. A. Carpenter, S. Grossberg, N. Markuzon, J. H. Reynolds, D. B. Rosen, Fuzzy ARTMAP: A neural network architecture for incremental supervised learning of analog multidimensional maps, IEEE Transactions on Neural Networks 3 (5) (1992) 698–713
work page 1992
-
[27]
N. M. Melton, D. Tanksley, D. C. Wunsch II, Adaptive resonance lib: A Python package for adaptive resonance theory (ART) models, Journal of Open Source Software 10 (114) (2025) 7764.doi:10.21105/joss.07764. 29
- [28]
-
[29]
S. Petrenko, L. E. Brito da Silva, D. C. Wunsch II, DeepART: Deep gradient-free local learning with adaptive resonance, Neural Networks 190 (2025) 107580.doi:10.1016/j.neunet.2025. 107580
-
[30]
N. M. Melton, L. E. Brito da Silva, D. C. Wunsch II, An extensive analysis of match-tracking methods for ARTMAP, in: 2025 IEEE Symposium on Computational Intelligence in Health and Medicine (CIHM), IEEE, 2025, pp. 1–8.doi:10.1109/CIHM64979.2025.10969482
-
[31]
V. Mygdalis, A. Iosifidis, A. Tefas, I. Pitas, Hyperspherical class prototypes for adversarial robustness, Pattern Recognition 125 (2022) 108527.doi:10.1016/j.patcog.2022.108527
-
[32]
M.Huai, X.Li, C.Miao, L.Sun, A.Zhang, Ontherobustnessofmetriclearning: Anadversarial perspective, ACM Transactions on Knowledge Discovery from Data 16 (5) (2022).doi:10. 1145/3502726
work page 2022
- [33]
- [34]
-
[35]
S. Cairns, L. E. Brito da Silva, S. Petrenko, D. C. Wunsch II, J. Liu, Robustness of Fuzzy ARTMAP to Adversarial Attacks and Progressive Adversarial Training for Streaming Learning, in: Proceedings of the International Joint Conference on Neural Networks (IJCNN), 2026, accepted for presentation
work page 2026
-
[36]
C. K. Chow, On optimum recognition error and reject tradeoff, IEEE Transactions on Infor- mation Theory 16 (1) (1970) 41–46.doi:10.1109/TIT.1970.1054406
-
[37]
Y. Geifman, R. El-Yaniv, Selective classification for deep neural networks, in: Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[38]
Y. Geifman, R. El-Yaniv, Selectivenet: A deep neural network with an integrated reject option, in: International Conference on Machine Learning (ICML), PMLR, 2019, pp. 2151–2159
work page 2019
-
[39]
D. Hendrycks, K. Gimpel, A baseline for detecting misclassified and out-of-distribution ex- amples in neural networks, in: International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[40]
G.A.Carpenter, S.Grossberg, D.B.Rosen, FuzzyART:Faststablelearningandcategorization of analog patterns by an adaptive resonance system, Neural Networks 4 (6) (1991) 759–771
work page 1991
-
[41]
M. Moshtaghi, J. C. Bezdek, S. M. Erfani, C. Leckie, J. Bailey, Online cluster validity indices for performance monitoring of streaming data clustering, International Journal of Intelligent Systems 34 (4) (2019) 541–563. 30
work page 2019
-
[42]
L. E. Brito da Silva, N. M. Melton, D. C. Wunsch II, Incremental cluster validity indices for online learning of hard partitions: Extensions and comparative study, IEEE Access 8 (2020) 22025–22047.doi:10.1109/ACCESS.2020.2969849
-
[43]
L. E. Brito da Silva, N. Rayapati, D. C. Wunsch II, iCVI-ARTMAP: Using incremental cluster validity indices and adaptive resonance theory reset mechanism to accelerate validation and achieve multiprototype unsupervised representations, IEEE Transactions on Neural Networks and Learning Systems 34 (12) (2023) 9757–9770.doi:10.1109/TNNLS.2022.3160381
-
[44]
T. Wu, T. Luo, D. C. Wunsch II, LRS: Enhancing adversarial transferability through Lips- chitz regularized surrogate, in: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Vol. 38, 2024, pp. 6135–6143.doi:10.1609/aaai.v38i6.28430. 31 Appendix This appendix provides additional theoretical and empirical details referenced in the main pa-...
-
[45]
an inputx 1 attains relatively high post-training match to an absorbed or newly created category, yet is still misclassified because a competing category wins the global competition or maps to a different class; while
-
[46]
Therefore, it is possible to have Mj1(I(x1))> M j2(I(x2)), f(x 1)̸=y 1, f(x 2) =y 2
another inputx 2 attains lower post-training match, yet is correctly classified because the winning category and map-field assignment are favorable. Therefore, it is possible to have Mj1(I(x1))> M j2(I(x2)), f(x 1)̸=y 1, f(x 2) =y 2. Combining Steps 1–3 yields the claim of Proposition 1: after selective adversarial training, post- training match need not ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.