Recognition: no theorem link
Target-Aware Data Augmentation for SAT Prediction
Pith reviewed 2026-05-11 01:15 UTC · model grok-4.3
The pith
A target-aware framework generates correctly labeled SAT instances by construction and aligns them with benchmark structures, bypassing expensive solver labeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a target-aware, solver-free procedure can produce SAT and UNSAT instances with correct labels by construction while matching the structural statistics of a target benchmark, and that feeding linear-programming constraint-violation residuals into message passing lets the resulting GNN capture optimization structure that standard architectures miss.
What carries the argument
The target-aware data augmentation procedure that constructs instances with known satisfiability and enforces benchmark-aligned statistics, together with the LPGNN architecture that injects constraint-violation residuals directly into graph message passing.
If this is right
- Training data for GNN-based SAT predictors can be produced at scales previously blocked by solver runtime.
- Solver-labeled datasets can be augmented with aligned synthetic instances without additional labeling cost.
- The LPGNN can exploit optimization residuals that standard message-passing GNNs ignore.
- A data-centric workflow becomes viable for other NP-hard domains where labeling is the dominant expense.
- Structural alignment between synthetic and benchmark instances becomes the primary design criterion for useful training data.
Where Pith is reading between the lines
- The same target-aware construction could be adapted to generate training data for other combinatorial problems whose feasibility can be encoded as linear programs.
- Reducing dependence on specific solver implementations for labeling may allow faster iteration over model architectures.
- Measuring distribution shift between generated and real instances on graph statistics such as clause-variable degree distributions would provide a direct test of the alignment step.
- Combining the generated data with active learning loops that query the solver only on uncertain instances could further cut labeling cost.
Load-bearing premise
Synthetic instances must share structural statistics with real benchmarks closely enough for models trained on them to generalize to actual solver instances.
What would settle it
Train identical GNNs on equal volumes of synthetic versus solver-labeled data and test both on held-out real benchmark instances; a large accuracy gap favoring the solver-labeled set would falsify the claim that the synthetic data is effective for augmentation.
Figures

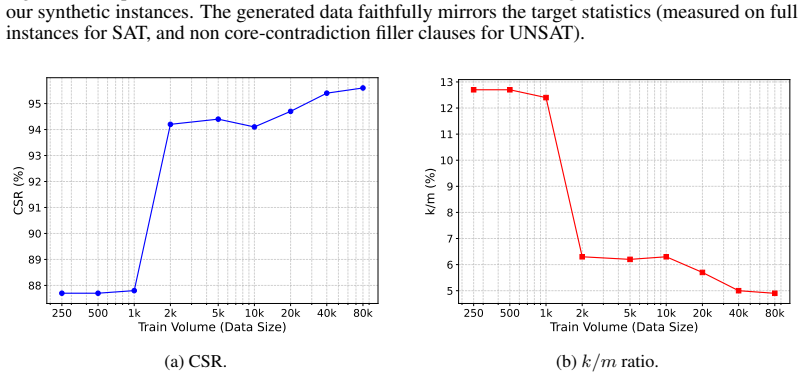
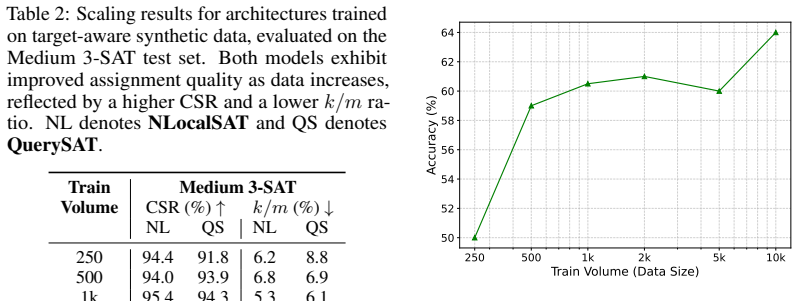





read the original abstract
Learning-based approaches to NP-hard problems have shown increasing promise, but their progress is fundamentally constrained by the high cost of generating labeled training data. In domains such as Boolean satisfiability (SAT), standard pipelines rely on solver-in-the-loop labeling, which scales poorly with problem size and limits the amount of usable supervision. This bottleneck hinders the broader goal of leveraging machine learning to capture structure in hard combinatorial problems. In this work, we propose a target-aware, solver-free data generation framework for SAT that produces correctly labeled SAT and UNSAT instances by construction, eliminating the need for expensive solver calls. Our method aligns generated instances with the structural properties of a target benchmark, making synthetic data effective for downstream learning. We further develop a linear-programming-aware graph neural network (LPGNN) architecture that incorporates constraint-violation residuals into message passing, enabling the model to exploit underlying optimization structure. Together, these contributions support a data-centric paradigm for learning on NP-hard problems, where scalable, task-aligned data generation is as critical as model design. Our approach yields orders-of-magnitude speedups in data generation, demonstrating that benchmark-aligned synthetic data can effectively augment solver-labeled datasets for GNN-based SAT prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a target-aware, solver-free framework for generating correctly labeled SAT/UNSAT instances that align with the structural properties of a target benchmark (e.g., clause-variable ratios, community structure). It introduces an LPGNN architecture that injects linear-programming constraint-violation residuals into GNN message passing. The central claims are that this yields orders-of-magnitude speedups over solver-in-the-loop labeling and that the resulting synthetic data effectively augments real solver-labeled datasets for downstream GNN-based SAT prediction.
Significance. If the generalization and speedup claims are substantiated, the work would meaningfully advance data-centric approaches to learning on NP-hard problems by removing the labeling bottleneck. The by-construction labeling and LP-residual injection are conceptually clean ideas that could scale training data for combinatorial optimization models.
major comments (3)
- [Abstract, §4] Abstract and §4: The manuscript asserts 'orders-of-magnitude speedups in data generation' and that 'benchmark-aligned synthetic data can effectively augment' solver-labeled datasets, yet supplies no wall-clock timings, instance-generation throughput numbers, ablation tables, or downstream SAT-prediction accuracy deltas relative to baselines.
- [§3.1] §3.1 (target-aware generation): The claim that alignment on low-order statistics (clause-variable ratio, community structure) suffices for GNN transfer is load-bearing but unsupported; no metrics are reported on higher-order properties (backbone size, resolution width, or proximity to the phase transition) that are known to affect SAT hardness and GNN generalization.
- [§3.2] §3.2 (LPGNN): The residual-injection mechanism is presented as capturing 'underlying optimization structure,' but no ablation isolates its contribution versus a standard GNN trained on identical synthetic graphs; without this, it is unclear whether the architecture adds value beyond the data-generation contribution.
minor comments (2)
- [§3] Figure 1 or §3: A diagram illustrating the target-alignment procedure and the exact LPGNN message-passing update rule would improve clarity.
- [§3.2] Notation: The definition of the residual vector r and its injection point into the GNN layers should be stated explicitly with an equation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will revise the manuscript to incorporate additional empirical support where the current version is lacking.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4: The manuscript asserts 'orders-of-magnitude speedups in data generation' and that 'benchmark-aligned synthetic data can effectively augment' solver-labeled datasets, yet supplies no wall-clock timings, instance-generation throughput numbers, ablation tables, or downstream SAT-prediction accuracy deltas relative to baselines.
Authors: We agree that the claims require quantitative backing. The revised manuscript will add wall-clock timings, generation throughput measurements, ablation tables, and downstream SAT-prediction accuracy improvements relative to baselines in Section 4. revision: yes
-
Referee: [§3.1] §3.1 (target-aware generation): The claim that alignment on low-order statistics (clause-variable ratio, community structure) suffices for GNN transfer is load-bearing but unsupported; no metrics are reported on higher-order properties (backbone size, resolution width, or proximity to the phase transition) that are known to affect SAT hardness and GNN generalization.
Authors: This observation is fair. While the method targets alignment on clause-variable ratios and community structure, the revision will include explicit comparisons of higher-order properties such as backbone size, resolution width, and phase-transition proximity between generated and target instances to better justify transfer performance. revision: yes
-
Referee: [§3.2] §3.2 (LPGNN): The residual-injection mechanism is presented as capturing 'underlying optimization structure,' but no ablation isolates its contribution versus a standard GNN trained on identical synthetic graphs; without this, it is unclear whether the architecture adds value beyond the data-generation contribution.
Authors: We acknowledge the need for this isolation. The revised version will include an ablation study comparing LPGNN against a standard GNN (e.g., GCN or GraphSAGE) trained on the identical synthetic data to quantify the contribution of the LP-residual injection. revision: yes
Circularity Check
No circularity: labels by construction and LP residuals are external
full rationale
The paper's derivation chain generates labeled instances explicitly by construction via target-aware alignment to benchmark statistics and feeds external LP relaxation residuals into message passing. No prediction reduces to a fitted parameter by definition, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled. The central claims rest on the practical speedup and augmentation effectiveness, which are presented as empirical outcomes rather than tautological reductions. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graph neural networks can usefully process SAT formulas represented as bipartite graphs of variables and clauses.
invented entities (1)
-
LPGNN
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Armin Biere, Katalin Fazekas, Mathias Fleury, and Maximilian Heisinger
doi: 10.1007/3-540-49059-0_14. Armin Biere, Katalin Fazekas, Mathias Fleury, and Maximilian Heisinger. Cadical, kissat, paracooba, plingeling and treengeling entering the sat competition
-
[2]
of SAT Competition 2020 - Solver and Benchmark Descriptions, volume vol
InProc. of SAT Competition 2020 - Solver and Benchmark Descriptions, volume vol. B-2020-1 ofDepartment of Computer Science Report Series B, pages 50–53. University of Helsinki,
work page 2020
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901,
work page 1901
-
[4]
MILP-SAT-GNN: Yet another neural SAT solver.arXiv preprint arXiv:2507.01825,
Franco Alberto Cardillo, Hamza Khyari, and Umberto Straccia. MILP-SAT-GNN: Yet another neural SAT solver.arXiv preprint arXiv:2507.01825,
-
[5]
Quadratic binary optimization with graph neural networks.arXiv preprint arXiv:2404.04874,
Moshe Eliasof and Eldad Haber. Quadratic binary optimization with graph neural networks.arXiv preprint arXiv:2404.04874,
-
[6]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Scaling Laws for Neural Language Models
11 Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[8]
doi: 10.1145/378239.379017. Emils Ozolins, Karlis Freivalds, Andis Draguns, Eliza Gaile, Ronalds Zakovskis, and Sergejs Kozlovics. Goal-aware neural sat solver. In2022 International joint conference on neural networks (IJCNN), pages 1–8. IEEE,
-
[9]
Christopher R Serrano, Jonathan Gallagher, Kenji Yamada, Alexei Kopylov, and Michael A War- ren. Self-satisfied: An end-to-end framework for sat generation and prediction.arXiv preprint arXiv:2410.14888,
-
[10]
Wenxi Wang, Yang Hu, Mohit Tiwari, Sarfraz Khurshid, Kenneth McMillan, and Risto Miikkulainen
doi: 10.1007/978-3-642-02777-2_24. Wenxi Wang, Yang Hu, Mohit Tiwari, Sarfraz Khurshid, Kenneth McMillan, and Risto Miikkulainen. Neuroback: Improving cdcl sat solving using graph neural networks
-
[11]
Graph data augmentation for graph machine learning: A survey.arXiv preprint arXiv:2202.08871,
Tong Zhao, Wei Jin, Yozen Liu, Yingheng Wang, Gang Liu, Stephan Günnemann, Neil Shah, and Meng Jiang. Graph data augmentation for graph machine learning: A survey.arXiv preprint arXiv:2202.08871,
-
[12]
13 A Additional Related Work Optimization-aware signals in graph learning.A related line of work enriches graph neural networks with optimization-derived information. BPGNN [Eliasof and Haber, 2024] incorporates a Quadratic Binary Optimization (QUBO) residual of the form r=h⊙(Ah+b) , thereby coupling message passing to an energy-based feasibility signal. ...
work page 2024
-
[13]
This gap highlights the importance of data alignment: the same architecture and loss function produce qualitatively different scaling behavior depending on the structural properties of the training data. 16 250 500 1k 2k 5k 10k Train Volume (Data Size) 50 52 54 56 58 60 62 64Accuracy (%) Generic T arget-aware Figure 6: Comparison of Accuracy (%) scaling f...
work page 2024
-
[14]
Hyperparameter NLocalSAT QuerySAT Message-passing steps 16 32 Hidden dimension 128 128 Query dimension — 128 Optimiser Adam [Kingma and Ba, 2015] Adam [Kingma and Ba, 2015] Learning rate10 −3 10−3 Weight decay10 −6 10−6 Batch size (easy / medium) 256 / 64 256 / 64 Max epochs 100 100 Early-stopping patience 15 15 G Limitations While our target-aware framew...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.