Recognition: no theorem link
A Reproducible Optimisation Protocol for Calibrating Prompt-Based Large Language Model Workflows in Evidence Synthesis
Pith reviewed 2026-05-11 00:48 UTC · model grok-4.3
The pith
Separating fixed scientific rules from adjustable prompt harnesses lets researchers calibrate LLM workflows for evidence synthesis reproducibly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that evidence-synthesis workflows based on prompt-driven large language models become reproducible when the immutable scientific task rules are isolated from a mutable prompt harness, the harness is optimised through metric-guided search on reference data, and the result is compiled into a preserved artefact that contains the full specification, metric, settings, and traces. The protocol is instantiated with one smaller student model executing the task and one larger reflection model steering the optimisation; the demonstration covers compilation, artefact round-tripping, and the impact of optimisation budget on the student model.
What carries the argument
The prompt harness, the separable and mutable framing layer placed around fixed scientific task rules, which is tuned by metric-guided optimisation and compiled into a reusable, inspectable workflow artefact.
If this is right
- The calibrated artefact can be reused or transferred to other evidence-synthesis tasks that share the same underlying rules.
- A smaller student model can execute the task at lower cost once the harness has been calibrated by a larger reflection model.
- Adjusting the optimisation budget produces measurable changes in the quality of the final workflow without altering the task rules.
- Full recording of traces and settings allows independent auditing of how the optimised workflow was produced.
Where Pith is reading between the lines
- The same separation of rules from harness could be tested on other structured research tasks such as data extraction or risk-of-bias assessment to check transferability.
- Artefact round-tripping suggests that calibrated workflows might be shared between research groups as standardised, version-controlled components.
- Using a distinct reflection model for optimisation may offer a general route to improve smaller models without retraining them.
Load-bearing premise
Optimising the prompt harness against labelled examples and an explicit task metric will produce workflows that transfer reliably to new tasks without embedding hidden biases from the optimisation process itself.
What would settle it
Apply the calibrated artefact to a new evidence-synthesis task with different characteristics and observe whether its performance falls substantially below the metric achieved during calibration or whether inspection of the traces reveals systematic deviations not explained by the original task rules.
Figures

read the original abstract
This methods article presents a reproducible calibration workflow for prompt-based large language models (LLMs) in structured evidence-synthesis tasks. The method separates the rules that define the scientific task from the mutable prompt harness that frames and applies them. It optimises that harness against labelled or reference examples and an explicit task metric, then preserves the calibrated workflow as an inspectable artefact with its specification, metric, settings, and evaluation traces. The example code instantiates the protocol with DSPy and GEPA tools, but the underlying logic can transfer to other prompt-optimisation frameworks that support structured task definitions, metric-guided search, and artefact reuse. Title and abstract screening is the worked validation case because it provides labelled benchmark data and clear evaluation metrics. The demonstrated workflow uses a smaller student LLM for performing the scientific task execution and a larger reflection LLM to steer the prompt optimisation process during calibration. This work shows compilation, artefact round-tripping, and how optimisation budget affects a smaller student model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This methods article presents a reproducible calibration workflow for prompt-based LLMs in structured evidence-synthesis tasks. It separates fixed scientific task rules from a mutable prompt harness, optimizes the harness against labelled examples and an explicit task metric, and preserves the result as an inspectable artefact containing specification, metric, settings, and traces. The protocol is instantiated with DSPy and GEPA for a title/abstract screening validation case using a smaller student LLM for task execution and a larger reflection LLM for optimisation steering, with demonstrations of compilation, artefact round-tripping, and optimisation budget effects.
Significance. If the protocol's generalizability holds, it would offer a structured, reusable approach to prompt calibration that improves transparency and reproducibility in AI-assisted evidence synthesis. The conceptual separation of immutable task rules from the optimizable harness is a clear strength, as is the emphasis on artefact preservation for inspection. However, the current manuscript provides only a descriptive account of the workflow and a single unquantified validation case, so its significance remains prospective rather than demonstrated.
major comments (2)
- Abstract and validation case description: the central claim that the protocol yields reproducible and effective workflows rests on description alone; no quantitative results, error rates, baseline comparisons, or statistical analysis from the title/abstract screening case are supplied, leaving effectiveness and reproducibility unverified.
- Validation case and generalizability discussion: the claim that metric-guided optimisation produces transferable, bias-free workflows across tasks and model sizes is load-bearing, yet the manuscript reports neither cross-task transfer experiments, held-out task evaluations, nor explicit checks for optimisation artefacts such as metric hacking or reflection-LLM prior leakage.
minor comments (2)
- The manuscript would benefit from a formal notation or diagram distinguishing the fixed task rules from the mutable harness components to improve clarity for readers implementing the protocol in other frameworks.
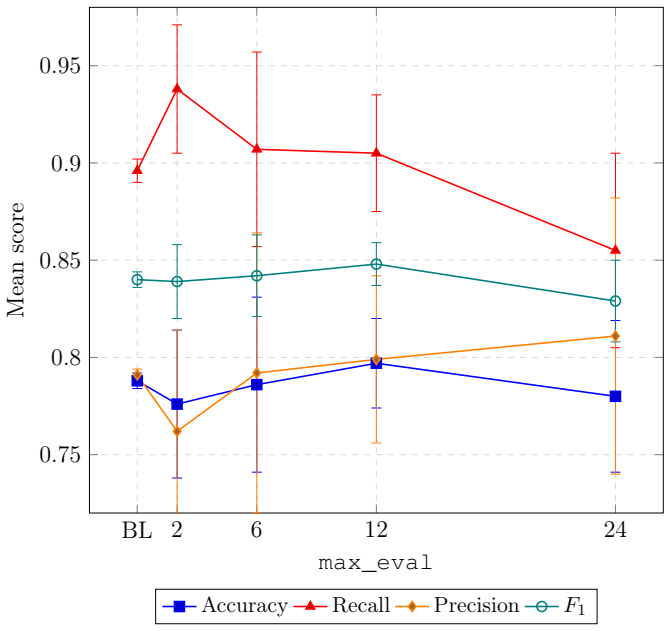
- Explicit discussion of the optimisation budget's impact on the student model should include at least one illustrative table or figure showing performance versus budget, even if preliminary.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our methods paper. We respond to the major comments point by point, clarifying the manuscript's scope as a description of the protocol with an illustrative case, and indicating revisions to improve clarity on claims and limitations.
read point-by-point responses
-
Referee: Abstract and validation case description: the central claim that the protocol yields reproducible and effective workflows rests on description alone; no quantitative results, error rates, baseline comparisons, or statistical analysis from the title/abstract screening case are supplied, leaving effectiveness and reproducibility unverified.
Authors: We clarify that the manuscript positions the protocol as a means to achieve reproducible calibration of prompt-based workflows, with the title/abstract screening case serving to illustrate the steps of task separation, harness optimization, and artefact preservation. The reproducibility claim pertains to the workflow process and its inspectable output, not to unvarying performance metrics across runs. The description of optimisation budget effects on the student model provides a qualitative demonstration of the protocol in action. We do not claim quantitative effectiveness or provide error rates because the focus is methodological. We will revise the abstract to better reflect this scope and avoid any implication of verified effectiveness. revision: yes
-
Referee: Validation case and generalizability discussion: the claim that metric-guided optimisation produces transferable, bias-free workflows across tasks and model sizes is load-bearing, yet the manuscript reports neither cross-task transfer experiments, held-out task evaluations, nor explicit checks for optimisation artefacts such as metric hacking or reflection-LLM prior leakage.
Authors: The manuscript does not assert that the optimisation produces transferable or bias-free workflows as an empirical finding; it describes the protocol's design to support such outcomes through explicit metrics and separation of concerns, with the example showing feasibility for one task and model size. Discussions of generalizability are conceptual, noting that the logic can transfer to other frameworks. We acknowledge the absence of cross-task experiments and checks for artefacts like metric hacking or leakage, which would require additional studies. We will update the generalizability discussion to explicitly state the limitations of the current validation case and suggest directions for future work on transfer and bias mitigation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a methods article that defines a calibration protocol as an external procedure to be applied to independent labelled data and task metrics. It explicitly separates fixed scientific task rules from a mutable prompt harness and optimises the latter against external references without any internal equations, fitted parameters, or self-referential reductions that would make the claimed outcomes equivalent to the protocol's own inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify the core separation or generalizability claims; the validation example on title/abstract screening is presented as a demonstration on external benchmarks rather than a tautological result. The derivation chain therefore remains self-contained against external data and does not reduce to its own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimizing a prompt harness against labelled examples and an explicit task metric produces workflows that are both more effective and more reproducible than hand-crafted prompts.
Reference graph
Works this paper leans on
-
[1]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
O. Khattab, A. Singhvi, P. Maheshwari, et al., DSPy: Compiling declarative language model calls into self-improving pipelines, arXiv preprint arXiv:2310.03714 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Opsahl-Ong, M
K. Opsahl-Ong, M. J. Ryan, J. Purtell, D. Broman, C. Potts, M. Zaharia, O. Khattab, Optimiz- ing instructions and demonstrations for multi-stage language model programs, in: 2024 Con- ference on Empirical Methods in Natural Language Processing, EMNLP 2024, Hybrid, Miami, United States of America, Nov 12 2024-Nov 16 2024, Association for Computational Ling...
2024
-
[3]
L. A. Agrawal, S. Tan, D. Soylu, N. Ziems, R. Khare, K. Opsahl-Ong, A. Singhvi, H. Shandilya, M. J. Ryan, M. Jiang, C. Potts, K. Sen, A. G. Dimakis, I. Stoica, D. Klein, M. Zaharia, O. Khattab, Gepa: Reflective prompt evolution can outperform reinforcement learning (2025). arXiv:2507.19457. URLhttps://arxiv.org/abs/2507.19457
work page internal anchor Pith review arXiv 2025
-
[4]
J.-L. Lieberum, M. Töws, M. Metzendorf, F. Heilmeyer, W. Siemens, C. Haverkamp, D. Böhringer, J. Meerpohl, A. Eisele-Metzger, Large language models for conducting systematic reviews: on the rise, but not yet ready for use—a scoping review, Journal of Clinical Epidemi- ology 181 (2025) 111746.doi:10.1016/j.jclinepi.2025.111746
-
[5]
M. Sujau, M. Wada, E. Vallée, N. Hillis, T. Sušnjak, Accelerating disease model parameter ex- traction: Anllm-basedrankingapproachtoselectinitialstudiesforliteraturereviewautomation, Machine Learning and Knowledge Extraction 7 (2) (2025).doi:10.3390/make7020028. URLhttps://www.mdpi.com/2504-4990/7/2/28 17
-
[6]
L. Li, A. Mathrani, T. Susnjak, What level of automation is “good enough”? a benchmark of large language models for meta-analysis data extraction, Research Synthesis Methods (2026) 1–22doi:10.1017/rsm.2025.10066
- [7]
-
[8]
T. Susnjak, P. Hwang, N. Reyes, A. L. C. Barczak, T. McIntosh, S. Ranathunga, Automating research synthesis with domain-specific large language model fine-tuning, ACM Trans. Knowl. Discov. Data 19 (3) (Mar. 2025).doi:10.1145/3715964. URLhttps://doi.org/10.1145/3715964
-
[9]
J. Zhuo, S. Zhang, X. Fang, H. Duan, D. Lin, K. Chen, ProSA: Assessing and understanding the prompt sensitivity of LLMs, in: Findings of the Association for Computational Linguistics: EMNLP 2024, Association for Computational Linguistics, Miami, Florida, USA, 2024, pp. 1950– 1976.doi:10.18653/v1/2024.findings-emnlp.108. URLhttps://aclanthology.org/2024.fi...
-
[10]
POSIX : A Prompt Sensitivity Index For Large Language Models
A. Chatterjee, H. S. V. N. S. K. Renduchintala, S. Bhatia, T. Chakraborty, POSIX: A prompt sensitivity index for large language models, in: Findings of the Association for Computational Linguistics: EMNLP 2024, Association for Computational Linguistics, Miami, Florida, USA, 2024, pp. 14550–14565.doi:10.18653/v1/2024.findings-emnlp.852. URLhttps://aclantho...
-
[11]
L. Zhou, W. Schellaert, F. Martínez-Plumed, Y. Moros-Daval, C. Ferri, J. Hernández-Orallo, Larger and more instructable language models become less reliable, Nature (634) (2024) 61–68. doi:10.1038/s41586-024-07930-y
-
[12]
R. J. Gallo, M. Baiocchi, T. R. Savage, J. H. Chen, Establishing best practices in large lan- guage model research: an application to repeat prompting, Journal of the American Medical Informatics Association 32 (2) (2025) 386–390.doi:10.1093/jamia/ocae294. URLhttps://doi.org/10.1093/jamia/ocae294
-
[13]
Kearns, Responsible ai in the generative era, accessed: 2025-08-01 (May 2023)
M. Kearns, Responsible ai in the generative era, accessed: 2025-08-01 (May 2023). URLhttps://www.amazon.science/blog/responsible-ai-in-the-generative-era
2025
-
[14]
Staudinger, W
M. Staudinger, W. Kusa, F. Piroi, A. Lipani, A. Hanbury, A reproducibility and generalizability study of large language models for query generation, in: Proceedings of the 2024 Annual Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, 2024, pp. 186–196
2024
-
[15]
Spiess, M
C. Spiess, M. Vaziri, L. Mandel, M. Hirzel, Autopdl: Automatic prompt optimization for llm agents, in: L. Akoglu, C. Doerr, J. N. van Rijn, R. Garnett, J. R. Gardner (Eds.), Proceedings of the Fourth International Conference on Automated Machine Learning, Vol. 293 of Proceedings of Machine Learning Research, PMLR, 2025, pp. 13/1–20. URLhttps://proceedings...
2025
-
[16]
Y. Zhao, P. Wang, H. F. Yang, How to auto-optimize prompts for domain tasks? adaptive prompting and reasoning through evolutionary domain knowledge adaptation, in: Proceedings of the 39th Conference on Neural Information Processing Systems, 2025
2025
-
[17]
S. Stradowski, L. Madeyski, Machine learning in software defect prediction: A business-driven systematic mapping study, Information and Software Technology 155 (2023) 107128.doi: 10.1016/j.infsof.2022.107128. URLhttps://doi.org/10.1016/j.infsof.2022.107128
-
[18]
A. Huotala, M. Kuutila, M. Mäntylä, SESR-Eval: Dataset for evaluating LLMs in the title- abstract screening of systematic reviews (2025).arXiv:2507.19027. URLhttps://arxiv.org/abs/2507.19027
-
[19]
"".strip() Listing 6: Frozen criteria block used in the validation comparison. CRITERIA_TEXT =
S. Matwin, A. Kouznetsov, D. Inkpen, O. Frunza, P. O’Blenis, A new algorithm for reducing the workload of experts in performing systematic reviews, Journal of the American Medical Informatics Association 17 (4) (2010) 446–453.doi:10.1136/jamia.2010.004325. URLhttps://doi.org/10.1136/jamia.2010.004325 Appendix A. Prompt references and prompt harnesses The ...
-
[20]
It scores label correctness, but in a cost-sensitive way rather than a symmetric exact-match way
-
[21]
It distinguishes false negatives from false positives, so GEPA can prefer prompt variants that preserve recall. 23
-
[22]
It enforces the output schema, because semantically plausible but structurally invalid labels are unusable in an executable DSPy program
-
[23]
It preserves a boundedcheckstrace, which acts as a compact criteria checklist rather than unrestricted reasoning
-
[24]
falsenegative
It returns failure-specific textual feedback grounded in the actual case, which gives the reflection model more useful revision material than a bare scalar score. Thecaseblock is especially important in reflective optimisation. The metric attaches the trun- catedcriteria, title, andabstracttothefeedback. Thisturnsagenericmessagesuchas“falsenegative” into ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.