Recognition: 2 theorem links
· Lean TheoremLearned Lagrangian Models of PDEs via Euler-Lagrange Residual Minimization
Pith reviewed 2026-05-11 01:13 UTC · model grok-4.3
The pith
A learned continuous Lagrangian can forecast PDE dynamics stably over long times by minimizing the Euler-Lagrange residual on local patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
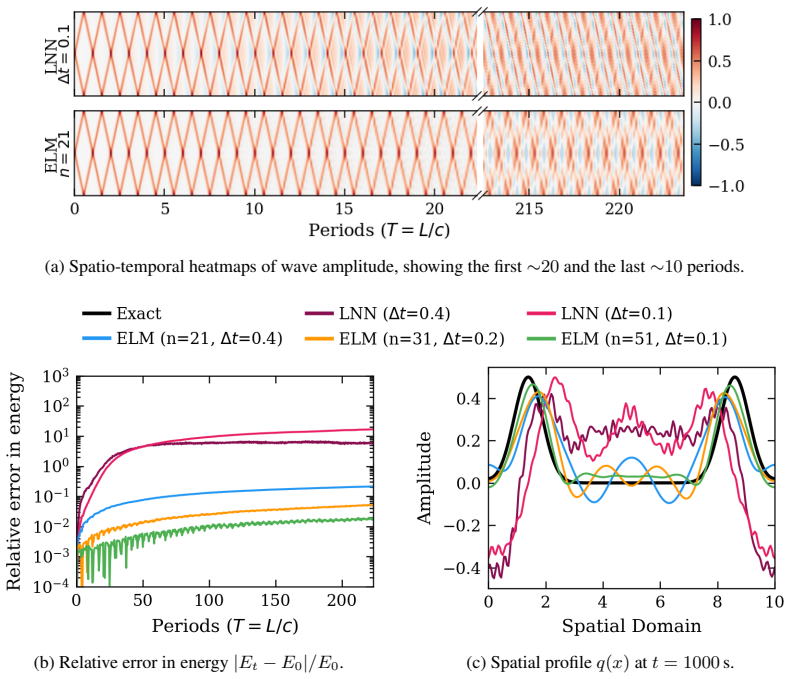
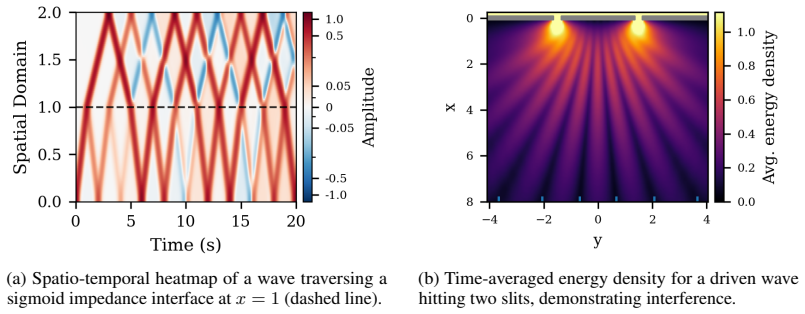
The central claim is that a neural network representing a continuous Lagrangian can be trained and then integrated by repeatedly solving a local optimization problem that drives the Euler-Lagrange residual to zero on mesh-free space-time patches; this near-symplectic construction decouples model error from integration error, yields forecasts whose accuracy matches classical symplectic integrators on the double pendulum and on one- and two-dimensional wave equations, and extends without retraining to spatially varying dynamics or arbitrary boundaries.
What carries the argument
The optimization-based integrator that minimizes the squared Euler-Lagrange residual via a mesh-free near-symplectic construction on local space-time patches, solved by Jacobi iteration.
If this is right
- The learned model achieves error levels comparable to classical symplectic integrators on the tested wave equations and double pendulum.
- The same trained network works for spatially varying dynamics and arbitrary boundary conditions without retraining.
- The integrator scales linearly with domain size because it relies on local patches and Jacobi iteration.
- No special architectural constraints are placed on the neural network, so the method can be combined with existing physics-guided learning techniques.
- Model error and integration error remain separable because the integrator is formulated as an optimization problem rather than a fixed time-stepping scheme.
Where Pith is reading between the lines
- The local-patch optimization could be applied to other conservative systems whose Lagrangians are harder to discretize globally, such as certain fluid or plasma models.
- Because the method does not enforce a particular network structure, it may allow simpler or more expressive architectures to be used for Lagrangian learning than current physics-informed approaches require.
- If the residual minimization is stable under mesh refinement, the same framework might serve as a general-purpose integrator for any learned conservative model, not only neural ones.
- The linear scaling suggests that the approach could be useful for very large spatial domains where global implicit solvers become prohibitive.
Load-bearing premise
Minimizing the squared Euler-Lagrange residual via Jacobi iteration on local patches will reliably separate model error from integration error and produce stable long-range forecasts without introducing new instabilities or requiring global coupling.
What would settle it
Train the network on snapshots from a 2D wave equation whose coefficients vary in space, then run the integrator forward for many hundreds of time units and check whether the integrated solution conserves total energy to within a small tolerance while matching a high-fidelity reference solver.
Figures






read the original abstract
We present the first method to directly use a learned continuous Lagrangian to forecast the dynamics of systems governed by partial differential equations, exploiting the inherent conservative structure to achieve stable long-range predictions. We develop an optimization-based integrator that minimizes the squared Euler--Lagrange residual via a mesh-free near-symplectic construction on local space-time patches. Different from integrators for analytical models, integrators for learned models should decouple model error (phase error) from integration error (conservation error). By relying on optimization rather than time-stepping, we bypass the global coupling inherent to fixed discretizations, which slows time- and space-stepping and complicates learning. Our method scales linearly with domain size via Jacobi iteration, and places no structural requirements on the learned network, allowing it to be coupled with existing physics-guided machine learning (ML) methods. We validate our approach on a learned representation of a double pendulum, a one-dimensional wave equation, and a two-dimensional wave equation. Our method achieves error comparable to classical symplectic methods while generalizing to spatially varying dynamics and arbitrary boundary conditions without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first method for directly using a learned continuous Lagrangian to forecast dynamics of PDE-governed systems. It develops a mesh-free near-symplectic integrator that minimizes the squared Euler-Lagrange residual via Jacobi iteration on local space-time patches, aiming to decouple model (phase) error from integration (conservation) error. This bypasses global coupling of fixed discretizations, scales linearly with domain size, imposes no structural requirements on the neural network, and is validated on a double pendulum, 1D wave equation, and 2D wave equation, achieving errors comparable to classical symplectic methods while generalizing to spatially varying dynamics and arbitrary boundary conditions.
Significance. If the central claims hold, the work would be significant for physics-informed machine learning by enabling stable long-term forecasting in conservative PDE systems through direct use of learned Lagrangians. It credits the mesh-free construction, linear scaling, and compatibility with existing methods as practical advantages over time-stepping approaches. The approach addresses a genuine gap in applying variational principles to learned models for fields.
major comments (2)
- [Abstract] Abstract: The claim that the integrator 'decouples model error (phase error) from integration error (conservation error)' by relying on optimization rather than time-stepping is load-bearing for the central contribution, yet no convergence analysis, error bounds, or proof of global consistency is provided for the local Jacobi iteration when the Lagrangian is only approximately learned. For PDEs the EL operator includes spatial derivatives, so local patches must consistently approximate derivatives and interface conditions; without this, residual mismatches could recouple errors and introduce instabilities.
- [Validation] Validation (on double pendulum, 1D/2D wave equations): The abstract states that the method 'achieves error comparable to classical symplectic methods' and 'generalizing to spatially varying dynamics,' but reports no quantitative error metrics (e.g., L2 norms, long-term drift), ablation studies on patch size/Jacobi iterations, or optimization convergence details. This leaves the support for stable long-range predictions and the decoupling assumption only moderately substantiated.
minor comments (2)
- [Abstract] The abstract could specify the neural network architectures, training losses, and hyperparameter choices used for the learned Lagrangians to aid reproducibility.
- [Methods] Notation for the Euler-Lagrange residual and the precise form of the Jacobi update on patches would benefit from an explicit equation or pseudocode in the methods section for clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. The comments highlight important aspects of the theoretical foundations and empirical validation that we address point by point below. We have revised the manuscript to strengthen the presentation where possible while maintaining an honest account of the work's scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the integrator 'decouples model error (phase error) from integration error (conservation error)' by relying on optimization rather than time-stepping is load-bearing for the central contribution, yet no convergence analysis, error bounds, or proof of global consistency is provided for the local Jacobi iteration when the Lagrangian is only approximately learned. For PDEs the EL operator includes spatial derivatives, so local patches must consistently approximate derivatives and interface conditions; without this, residual mismatches could recouple errors and introduce instabilities.
Authors: We agree that the decoupling claim is central and that the manuscript lacks a formal convergence analysis or error bounds for the approximate-Lagrangian case. Deriving such guarantees is difficult without strong assumptions on network approximation quality that may not hold in practice. The local patch-wise minimization is intended to avoid the sequential error accumulation of time-stepping integrators, and the mesh-free construction permits the learned model to adapt to spatial derivatives and boundaries without explicit interface enforcement. Experiments on the wave equations show no observed instabilities over long horizons. In the revised manuscript we have added a dedicated limitations paragraph in the discussion section that qualifies the decoupling statement, notes the absence of theoretical bounds, and summarizes the empirical evidence from the reported trajectories. revision: partial
-
Referee: [Validation] Validation (on double pendulum, 1D/2D wave equations): The abstract states that the method 'achieves error comparable to classical symplectic methods' and 'generalizing to spatially varying dynamics,' but reports no quantitative error metrics (e.g., L2 norms, long-term drift), ablation studies on patch size/Jacobi iterations, or optimization convergence details. This leaves the support for stable long-range predictions and the decoupling assumption only moderately substantiated.
Authors: We accept that the original validation relied primarily on qualitative trajectory plots and that explicit quantitative metrics, ablations, and convergence diagnostics would strengthen the claims. The revised manuscript now includes a table of L2 error norms and long-term drift statistics for all three test systems, with direct numerical comparison to classical symplectic integrators. Additional ablation experiments varying patch size and Jacobi iteration count have been added to the supplementary material, confirming robustness within the ranges used in the main results. Residual norms at convergence are also reported for each experiment to document optimization behavior. revision: yes
- A rigorous convergence analysis or error bounds for the local Jacobi iteration under approximate learned Lagrangians cannot be supplied in the current revision.
Circularity Check
Optimization-based EL residual minimization is constructed directly from variational principles; no reduction of performance claims to self-defined fits or self-citations
full rationale
The derivation chain begins from the standard Euler-Lagrange equations and applies an optimization procedure (Jacobi iteration on local patches) to minimize the residual. This construction is independent of the learned Lagrangian parameters and does not rename or refit any input quantity as an output prediction. The claimed decoupling of phase error from conservation error follows from the choice of optimization over time-stepping, which is a standard design choice rather than a tautology. No load-bearing step invokes a self-citation whose uniqueness theorem or ansatz is required to justify the central result; the method is self-contained against external benchmarks such as classical symplectic integrators. Minor self-citations on related Lagrangian learning may be present but do not carry the performance claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network hyperparameters
axioms (2)
- standard math The Euler-Lagrange equations correctly describe the dynamics of the underlying conservative system
- domain assumption Local patch optimization via Jacobi iteration converges to a near-symplectic update
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
minimizes the squared Euler–Lagrange residual via a mesh-free near-symplectic construction on local space-time patches... When the residual is driven to zero, the integrator becomes symplectic
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ELM is an optimization-based integrator... scales linearly with domain size via Jacobi iteration
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Discrete mechanics and variational integrators , author=. Acta Numerica , volume=. 2001 , publisher=
work page 2001
-
[2]
ICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations , year=
Lagrangian Neural Networks , author=. ICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations , year=
work page 2020
-
[3]
Lutter, Michael and Ritter, Christian and Peters, Jan , booktitle=. Deep
-
[4]
Finzi, Marc and Wang, Ke Alexander and Wilson, Andrew Gordon , booktitle=. Simplifying
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
Hamiltonian Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[6]
SIAM Journal on Numerical Analysis , volume=
Backward Error Analysis for Numerical Integrators , author=. SIAM Journal on Numerical Analysis , volume=. 1999 , doi=
work page 1999
-
[7]
International Conference on Learning Representations (ICLR) , year=
Symplectic Recurrent Neural Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[8]
Journal of Computational Physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational Physics , volume=. 2019 , doi=
work page 2019
-
[9]
Learning nonlinear operators via
Lu, Lu and Jin, Pengzhan and Pang, Guofei and Zhang, Zhongqiang and Karniadakis, George Em , journal=. Learning nonlinear operators via. 2021 , doi=
work page 2021
-
[10]
Marsden, Jerrold E. and Patrick, George W. and Shkoller, Steve , journal=. Multisymplectic Geometry, Variational Integrators, and Nonlinear. 1998 , doi=
work page 1998
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
Neural Ordinary Differential Equations , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[12]
International Conference on Machine Learning (ICML) , year=
Learning to Simulate Complex Physics with Graph Networks , author=. International Conference on Machine Learning (ICML) , year=
-
[13]
International Conference on Learning Representations (ICLR) , year=
Fourier Neural Operator for Parametric Partial Differential Equations , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
Brandstetter, Johannes and Worrall, Daniel E. and Welling, Max , booktitle=. Message Passing Neural
-
[15]
International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
Variational Integrator Networks for Physically Structured Embeddings , author=. International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[16]
Learning of discrete models of variational
Offen, Christian and Ober-Bl. Learning of discrete models of variational. Chaos , volume=. 2024 , doi=
work page 2024
-
[17]
Learning Relativistic Geodesics and Chaotic Dynamics via Stabilized
Hamzaogullari, Abdullah Umut and Ozakin, Arkadas , journal=. Learning Relativistic Geodesics and Chaotic Dynamics via Stabilized. 2026 , doi=
work page 2026
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Characterizing possible failure modes in physics-informed neural networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[19]
International Conference on Learning Representations (ICLR) , year=
Learning Mesh-Based Simulation with Graph Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[20]
Physics-based Deep Learning , author=. arXiv preprint arXiv:2109.05237 , year=
-
[21]
Lippe, Phillip and Veeling, Bastiaan S and Perdikaris, Paris and Turner, Richard E and Brandstetter, Johannes , booktitle=
-
[22]
Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations , author=. 2006 , publisher=
work page 2006
-
[23]
Frontiers of Mathematics in China , volume=
General Techniques for Constructing Variational Integrators , author=. Frontiers of Mathematics in China , volume=. 2012 , doi=
work page 2012
-
[24]
Numerische Mathematik , volume=
Spectral Variational Integrators , author=. Numerische Mathematik , volume=. 2015 , doi=
work page 2015
-
[25]
Learning the solution operator of parametric partial differential equations with physics-informed
Wang, Sifan and Wang, Hanwen and Perdikaris, Paris , journal=. Learning the solution operator of parametric partial differential equations with physics-informed. 2021 , doi=
work page 2021
-
[26]
ACM / IMS Journal of Data Science , volume=
Physics-Informed Neural Operator for Learning Partial Differential Equations , author=. ACM / IMS Journal of Data Science , volume=. 2024 , doi=
work page 2024
-
[27]
Li, Yaojun and Yang, Yulong and Allen-Blanchette, Christine , journal=. Frequency-Separable
-
[28]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Yash Katariya and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
- [29]
-
[30]
IEEE transactions on Electromagnetic Compatibility , number=
Absorbing boundary conditions for the finite-difference approximation of the time-domain electromagnetic-field equations , author=. IEEE transactions on Electromagnetic Compatibility , number=. 1981 , publisher=
work page 1981
-
[31]
Proceedings of the National Academy of Sciences , volume=
Learning dynamical systems from data: An introduction to physics-guided deep learning , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.