Recognition: 2 theorem links
· Lean TheoremOn the Robustness of Distribution Support under Diffusion Guidance
Pith reviewed 2026-05-11 02:23 UTC · model grok-4.3
The pith
Guided diffusion processes keep samples close to the target support when given exact score functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
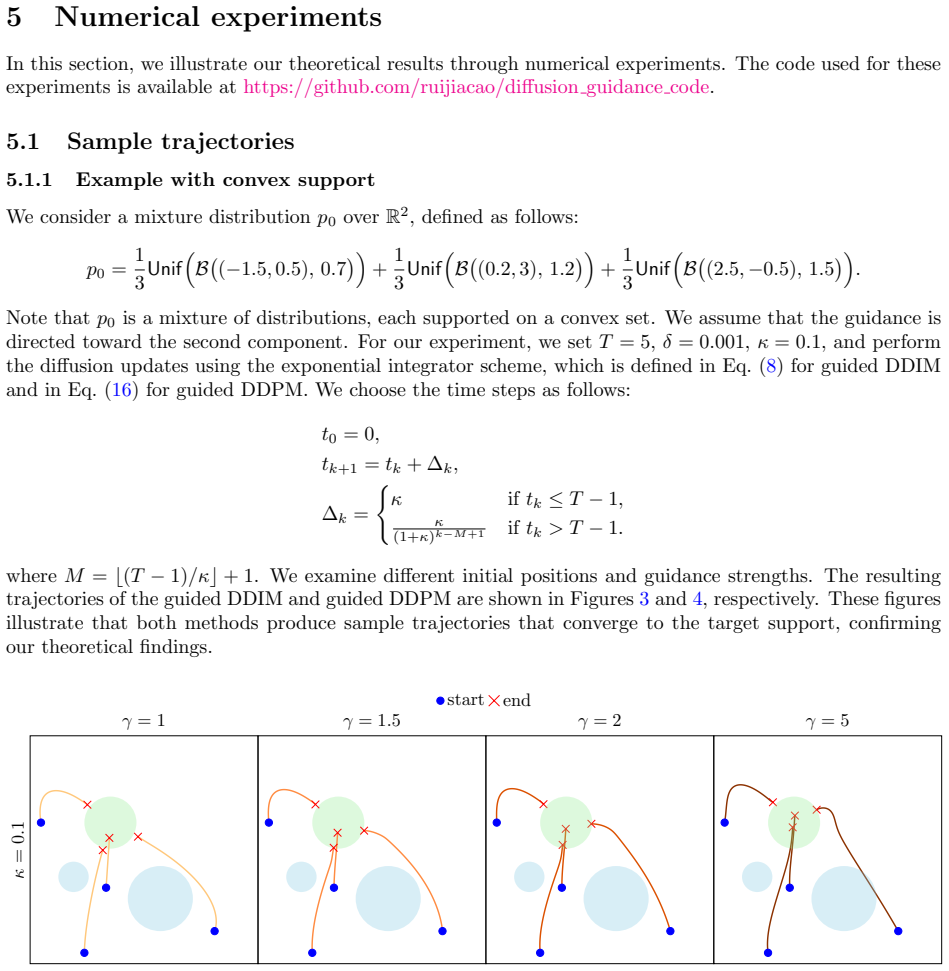
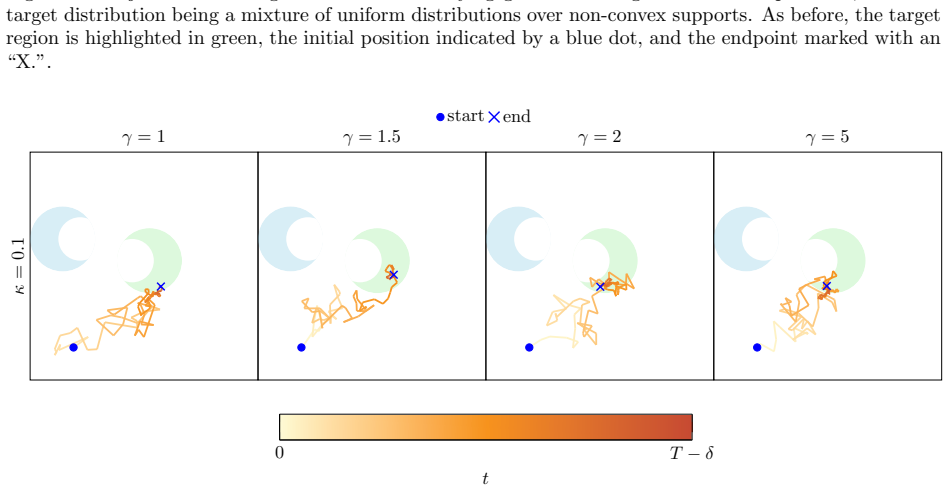
We show that, given exact access to the score functions, guided diffusion processes almost always generate samples that remain close to the target support. This property is particularly desirable, as samples that lie off the support are often structurally implausible and may adversely affect downstream tasks. Our analysis covers both Denoising Diffusion Implicit Models (DDIM) and Denoising Diffusion Probabilistic Models (DDPM), and applies to a wide range of discretization schemes induced by exponential integrators.
What carries the argument
The robustness of support property, shown by tracking how the guided score steers trajectories under exponential integrator discretizations for DDIM and DDPM.
If this is right
- Guidance can steer samples controllably without producing structurally invalid outputs.
- The support preservation holds across common discretization choices in DDIM and DDPM sampling.
- Off-support artifacts that harm downstream tasks are theoretically avoided under exact scores.
- The analysis supplies a foundation for why guided diffusion yields physically meaningful samples.
Where Pith is reading between the lines
- In practice, score estimates close to exact may inherit enough of the support robustness to explain observed stability.
- The same reasoning could be tested on other samplers or continuous-time limits to see if support adherence persists.
- This suggests training objectives that reduce score error could directly improve support fidelity in generated samples.
Load-bearing premise
The proof requires exact knowledge of the score functions and applies only to discretization schemes induced by exponential integrators.
What would settle it
A concrete numerical trajectory computed with exact scores on a known target distribution where the final sample lies far outside the support would disprove the claim.
Figures





read the original abstract
Diffusion guidance is a powerful technique that enables controllable and high-fidelity sample generation with diffusion models. At a high level, it modifies the score function by incorporating a guidance term that steers the generative process toward a desired condition. Despite its empirical success, the theoretical properties of diffusion guidance remain largely unexplored, and it is not well understood why it consistently produces high-quality samples. In this work, we explain the effectiveness of diffusion guidance by establishing a \emph{robustness of support} property. Specifically, we show that, given exact access to the score functions, guided diffusion processes almost always generate samples that remain close to the target support. This property is particularly desirable, as samples that lie off the support are often structurally implausible and may adversely affect downstream tasks. Our analysis covers both Denoising Diffusion Implicit Models (DDIM) and Denoising Diffusion Probabilistic Models (DDPM), and applies to a wide range of discretization schemes induced by exponential integrators. Our results provide a rigorous foundation for understanding why diffusion guidance produces physically meaningful and structurally plausible samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper establishes a 'robustness of support' property for diffusion guidance: with exact access to the score functions of the target and guidance distributions, guided reverse processes for both DDIM and DDPM produce samples that remain close to the target support. The result is proved for the class of discretization schemes obtained from exponential integrators, which permit exact integration of the linear drift term and thereby allow the exact-score guidance to cancel support deviations at each step.
Significance. If the derivation holds, the result supplies a concrete theoretical explanation for the empirical observation that guided diffusion samples are structurally plausible rather than off-manifold artifacts. It isolates the role of exact scores and the exponential-integrator discretization class, and it applies uniformly to the two most common diffusion samplers (DDIM, DDPM). The absence of free parameters or invented entities in the stated claim is a strength.
major comments (2)
- [§3 (discretization analysis)] The central claim is explicitly scoped to exponential-integrator discretizations (abstract and §3). Standard first-order schemes such as Euler-Maruyama introduce local truncation errors whose interaction with the guidance drift is not controlled by the same exact-cancellation mechanism; the manuscript provides no uniform bound or counter-example analysis showing whether the support-robustness property survives these errors. This limitation is load-bearing because most practical implementations do not use exponential integrators.
- [Theorem 1 / §4 (exact-score assumption)] The proof assumes exact access to both the unconditional and conditional score functions at every step. No quantitative error propagation is given for the case of approximate scores (e.g., learned neural-network estimators), even though the abstract highlights 'exact access' as a prerequisite. A perturbation analysis or Lipschitz-style bound on score error would be needed to assess practical relevance.
minor comments (2)
- [§2] Notation for the guidance scale and the target support indicator is introduced without a consolidated table; a short notation summary would improve readability.
- [Abstract / §1] The abstract states the result applies to 'a wide range of discretization schemes induced by exponential integrators,' but the precise class (e.g., which Runge-Kutta or linear multistep variants) is not enumerated until later; an explicit list in the introduction would clarify scope.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the paper's significance and for the constructive major comments. We address each point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3 (discretization analysis)] The central claim is explicitly scoped to exponential-integrator discretizations (abstract and §3). Standard first-order schemes such as Euler-Maruyama introduce local truncation errors whose interaction with the guidance drift is not controlled by the same exact-cancellation mechanism; the manuscript provides no uniform bound or counter-example analysis showing whether the support-robustness property survives these errors. This limitation is load-bearing because most practical implementations do not use exponential integrators.
Authors: We agree that the result is scoped to exponential-integrator discretizations, as stated in the abstract and Section 3. The proof technique relies on the exact integration of the linear drift, which enables precise cancellation of support deviations by the guidance term at each step. Standard first-order schemes such as Euler-Maruyama introduce truncation errors whose effect on the support-robustness property is not controlled by the same mechanism, and the manuscript contains neither a uniform bound nor a counter-example for those schemes. In the revised version we will add an explicit discussion paragraph in §3 acknowledging this scope limitation and noting that extending the analysis to first-order discretizations is an open direction. revision: partial
-
Referee: [Theorem 1 / §4 (exact-score assumption)] The proof assumes exact access to both the unconditional and conditional score functions at every step. No quantitative error propagation is given for the case of approximate scores (e.g., learned neural-network estimators), even though the abstract highlights 'exact access' as a prerequisite. A perturbation analysis or Lipschitz-style bound on score error would be needed to assess practical relevance.
Authors: The current work isolates the support-robustness mechanism under exact score access, which is explicitly stated as a prerequisite in the abstract and Theorem 1. We do not supply a perturbation or Lipschitz-style bound for approximate (learned) scores, as that analysis lies outside the scope of the present manuscript. In revision we will strengthen the wording in the abstract and the statement of Theorem 1 to emphasize the exact-access hypothesis and add a short remark in the discussion section on the implications for score-estimation error. revision: partial
Circularity Check
No circularity; derivation follows from standard diffusion score properties and exact integrator cancellation
full rationale
The paper derives a support-robustness property for guided DDIM/DDPM processes under exact score access, specifically for exponential-integrator discretizations. This follows directly from the exact integration of the linear drift term (allowing the score to cancel support deviations) and standard properties of the reverse SDE, without any reduction to fitted parameters, self-definitional loops, or load-bearing self-citations. The result is scoped to the stated discretization class but remains mathematically self-contained and externally verifiable from the diffusion literature.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Exact access to the score functions of the underlying diffusion process
- standard math Standard properties of DDIM and DDPM forward and reverse processes under exponential integrator discretizations
Reference graph
Works this paper leans on
-
[1]
Stochastic calculus, filtering, and stochastic control , author=. Course notes., URL http://www. princeton. edu/rvan/acm217/ACM217. pdf , volume=
-
[2]
Optimizing methods in statistics , pages=
A convergence theorem for non negative almost supermartingales and some applications , author=. Optimizing methods in statistics , pages=. 1971 , publisher=
work page 1971
-
[3]
Self-refining video sampling.arXiv preprint arXiv:2601.18577, 2026
Self-Refining Video Sampling , author=. arXiv preprint arXiv:2601.18577 , year=
-
[4]
On Malliavin's proof of H\"ormander's theorem , author=. 2011 , eprint=
work page 2011
-
[5]
Stroock, Daniel W. , year=. Partial Differential Equations for Probabilists , publisher=
-
[6]
Advances in Neural Information Processing Systems , volume=
The probability flow ode is provably fast , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Advances in Neural Information Processing Systems , volume=
What does guidance do? a fine-grained analysis in a simple setting , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Archiv der Mathematik , volume=
The nearest point mapping is single valued nearly everywhere , author=. Archiv der Mathematik , volume=. 1990 , publisher=
work page 1990
-
[9]
Proceedings of the 41st International Conference on Machine Learning , pages=
Theoretical insights for diffusion guidance: a case study for Gaussian mixture models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[10]
Emergence of Distortions in High-Dimensional Guided Diffusion Models , author=. 2026 , eprint=
work page 2026
-
[11]
NeurIPS 2024 Workshop on Mathematics of Modern Machine Learning , year=
Classifier-Free Guidance is a Predictor-Corrector , author=. NeurIPS 2024 Workshop on Mathematics of Modern Machine Learning , year=
work page 2024
-
[12]
arXiv preprint arXiv:2505.01382 , year=
Provable Efficiency of Guidance in Diffusion Models for General Data Distribution , author=. arXiv preprint arXiv:2505.01382 , year=
-
[13]
arXiv preprint arXiv:2512.04985 , year =
Towards a unified framework for guided diffusion models , author=. arXiv preprint arXiv:2512.04985 , year=
-
[14]
Elliptic partial differential equations of second order , author=
-
[15]
Brascamp, H. J. and Lieb, E. H. , journal=. On extensions of the
-
[16]
Differential Equations, Dynamical Systems, and an Introduction to Chaos , author=
-
[17]
Transactions of the American Mathematical Society , volume=
Curvature measures , author=. Transactions of the American Mathematical Society , volume=. 1959 , publisher=
work page 1959
-
[18]
Proceedings of the 32nd International Conference on Machine Learning , year=
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author=. Proceedings of the 32nd International Conference on Machine Learning , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Denoising Diffusion Probabilistic Models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[21]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[22]
Dhariwal, Prafulla and Nichol, Alex , booktitle=. Diffusion Models Beat
-
[23]
Classifier-Free Diffusion Guidance
Classifier-Free Diffusion Guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
High-Resolution Image Synthesis with Latent Diffusion Models , author=. Proceedings of the
-
[25]
Advances in Neural Information Processing Systems , volume=
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Controlled Diffusion Processes , author=
-
[27]
Stochastic Integration and Differential Equations , author=
-
[28]
Boundary Regularity For the Distance Functions, and the Eikonal Equation: N. Nikolov, PJ Thomas , author=. The Journal of Geometric Analysis , volume=. 2025 , publisher=
work page 2025
-
[29]
Aebi, Robert , journal=. It. 1992 , publisher=
work page 1992
-
[30]
Continuous martingales and Brownian motion , author=. 2013 , publisher=
work page 2013
-
[31]
Measure theory and fine properties of functions , author=. 2018 , publisher=
work page 2018
-
[32]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[33]
Runge-Kutta pairs of order 5(4) satisfying only the first column simplifying assumption , author=. Comput. Math. Appl. , year=
-
[34]
Patrick Kidger , year=
-
[35]
Advances in neural information processing systems , volume=
Generative modeling by estimating gradients of the data distribution , author=. Advances in neural information processing systems , volume=
-
[36]
Brownian motion and Riemannian geometry , author=. Contemp. Math , volume=
-
[37]
Communications on Pure and Applied Mathematics , volume=
On the behavior of the fundamental solution of the heat equation with variable coefficients , author=. Communications on Pure and Applied Mathematics , volume=. 1967 , publisher=
work page 1967
-
[38]
Probabilistic approach to geometry , volume=
The heat kernel and its estimates , author=. Probabilistic approach to geometry , volume=. 2010 , publisher=
work page 2010
-
[39]
SIAM Journal on Mathematical Analysis , volume=
Short-Time Asymptotics of the Heat Kernel on a Concave Boundary , author=. SIAM Journal on Mathematical Analysis , volume=. 1989 , publisher=
work page 1989
-
[40]
Principal Component Analyses (PCA)-based findings in population genetic studies are highly biased and must be reevaluated , author=. Scientific reports , volume=. 2022 , publisher=
work page 2022
-
[41]
arXiv preprint arXiv:2501.12982 , year=
Low-dimensional adaptation of diffusion models: Convergence in total variation , author=. arXiv preprint arXiv:2501.12982 , year=
-
[42]
Understanding diffusion models: A unified perspective , author=. arXiv preprint arXiv:2208.11970 , year=
-
[43]
Journal of functional analysis , volume=
Shape analysis via oriented distance functions , author=. Journal of functional analysis , volume=. 1994 , publisher=
work page 1994
-
[44]
Stochastic differential equations and diffusion processes , author=. 2014 , publisher=
work page 2014
-
[45]
Accurate structure prediction of biomolecular interactions with AlphaFold 3 , author=. Nature , volume=. 2024 , publisher=
work page 2024
- [46]
-
[47]
De novo design of protein structure and function with RFdiffusion , author=. Nature , volume=. 2023 , publisher=
work page 2023
-
[48]
The Eleventh International Conference on Learning Representations , year=
Fast Sampling of Diffusion Models with Exponential Integrator , author=. The Eleventh International Conference on Learning Representations , year=
-
[49]
Convex Analysis and Nonlinear Optimization: Theoryand Examples , author=. 2006 , publisher=
work page 2006
- [50]
- [51]
-
[52]
Archiv der Mathematik , volume=
Approximating convex bodies by algebraic ones , author=. Archiv der Mathematik , volume=. 1974 , publisher=
work page 1974
-
[53]
arXiv preprint arXiv:2403.04279 , year=
Controllable generation with text-to-image diffusion models: A survey , author=. arXiv preprint arXiv:2403.04279 , year=
-
[54]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
When and how can inexact generative models still sample from the data manifold? , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[55]
arXiv preprint arXiv:2601.21200 , year=
Provably Reliable Classifier Guidance via Cross-Entropy Control , author=. arXiv preprint arXiv:2601.21200 , year=
-
[56]
The Twelfth International Conference on Learning Representations , year=
Training Diffusion Models with Reinforcement Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[57]
arXiv preprint arXiv:2602.05533 , year=
Conditional Diffusion Guidance under Hard Constraint: A Stochastic Analysis Approach , author=. arXiv preprint arXiv:2602.05533 , year=
-
[58]
arXiv preprint arXiv:2409.04832 , year=
Reward-directed score-based diffusion models via q-learning , author=. arXiv preprint arXiv:2409.04832 , year=
-
[59]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[60]
The Twelfth International Conference on Learning Representations , year=
Nearly \ d\ -Linear Convergence Bounds for Diffusion Models via Stochastic Localization , author=. The Twelfth International Conference on Learning Representations , year=
-
[61]
Stochastic Processes and their Applications , volume=
Reverse-time diffusion equation models , author=. Stochastic Processes and their Applications , volume=. 1982 , publisher=
work page 1982
-
[62]
IEEE Transactions on Information Theory , year=
Convergence analysis of probability flow ode for score-based generative models , author=. IEEE Transactions on Information Theory , year=
-
[63]
International Conference on Algorithmic Learning Theory , pages=
Convergence of score-based generative modeling for general data distributions , author=. International Conference on Algorithmic Learning Theory , pages=. 2023 , organization=
work page 2023
-
[64]
From optimal score matching to optimal sampling.arXiv preprint arXiv:2409.07032,
From optimal score matching to optimal sampling , author=. arXiv preprint arXiv:2409.07032 , year=
-
[65]
The annals of Statistics , pages=
Estimation of the mean of a multivariate normal distribution , author=. The annals of Statistics , pages=. 1981 , publisher=
work page 1981
-
[66]
Posterior sampling in high dimension via diffusion processes
Posterior sampling in high dimension via diffusion processes , author=. arXiv preprint arXiv:2304.11449 , year=
-
[67]
arXiv preprint arXiv:2504.06566 , year=
Diffusion factor models: Generating high-dimensional returns with factor structure , author=. arXiv preprint arXiv:2504.06566 , year=
-
[68]
The Eleventh International Conference on Learning Representations , year=
Diffusion Posterior Sampling for General Noisy Inverse Problems , author=. The Eleventh International Conference on Learning Representations , year=
-
[69]
arXiv preprint arXiv:2403.13219 , year=
Diffusion model for data-driven black-box optimization , author=. arXiv preprint arXiv:2403.13219 , year=
-
[70]
Proceedings of the 41st International Conference on Machine Learning , pages=
Minimax optimality of score-based diffusion models: beyond the density lower bound assumptions , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[71]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Optimal score estimation via empirical bayes smoothing , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
work page 2024
-
[72]
International Conference on Machine Learning , pages=
Diffusion models are minimax optimal distribution estimators , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[73]
The Thirteenth International Conference on Learning Representations , year=
O(d/T) Convergence Theory for Diffusion Probabilistic Models under Minimal Assumptions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[74]
International Conference on Machine Learning , pages=
Accelerating Convergence of Score-Based Diffusion Models, Provably , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[75]
The Thirteenth International Conference on Learning Representations , year=
Unified Convergence Analysis for Score-Based Diffusion Models with Deterministic Samplers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[76]
The Thirteenth International Conference on Learning Representations , year=
Faster Diffusion Sampling with Randomized Midpoints: Sequential and Parallel , author=. The Thirteenth International Conference on Learning Representations , year=
-
[77]
The Eleventh International Conference on Learning Representations , year=
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions , author=. The Eleventh International Conference on Learning Representations , year=
-
[78]
arXiv preprint arXiv:2506.24042 , year=
Faster diffusion models via higher-order approximation , author=. arXiv preprint arXiv:2506.24042 , year=
-
[79]
A Connection Between Score Matching and Denoising Autoen- coders
Stochastic runge-kutta methods: Provable acceleration of diffusion models , author=. arXiv preprint arXiv:2410.04760 , year=
-
[80]
arXiv preprint arXiv:2506.13061 , year=
Fast convergence for high-order ode solvers in diffusion probabilistic models , author=. arXiv preprint arXiv:2506.13061 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.