Recognition: 1 theorem link
· Lean TheoremBeyond Linear Attention: Softmax Transformers Implement In-Context Reinforcement Learning
Pith reviewed 2026-05-11 01:09 UTC · model grok-4.3
The pith
Softmax attention in Transformers computes iterative updates of a weighted softmax TD learning algorithm across layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
With carefully chosen parameters, the layerwise forward pass of a softmax Transformer is mathematically identical to iterative updates of a weighted softmax TD algorithm that performs policy evaluation in kernel space; under an additional contraction condition the policy evaluation error decreases with the number of layers; and those same parameters are a global minimizer of the pretraining loss.
What carries the argument
The exact algebraic equivalence between each softmax attention layer and one step of the weighted softmax TD update rule, where attention scores implement the softmax over kernel-space value estimates.
If this is right
- Policy evaluation error contracts toward zero as the number of layers increases whenever the contraction condition holds.
- The parameters that implement the TD equivalence also emerge as the global solution to the pretraining objective.
- Weighted softmax TD recovers both ordinary linear TD and tabular TD as special cases.
- A pretrained Transformer can adapt to new tasks by processing context alone, without any gradient updates.
Where Pith is reading between the lines
- Deeper Transformers could solve more complex in-context RL tasks provided the contraction condition scales with depth.
- The same equivalence might be used to design pretraining losses that deliberately encourage RL-like behavior in attention layers.
- Practical models could be inspected layer by layer to verify whether their internal computations align with TD-style updates on real tasks.
Load-bearing premise
There exist parameters that simultaneously realize the exact layerwise equivalence to the TD updates, satisfy the contraction condition needed for error decay, and globally minimize the pretraining loss.
What would settle it
Fix the identified parameters in a Transformer and check whether each layer's output vector matches the formula for one weighted softmax TD update applied to the preceding layer's output; mismatch at any layer would refute the claimed equivalence.
Figures




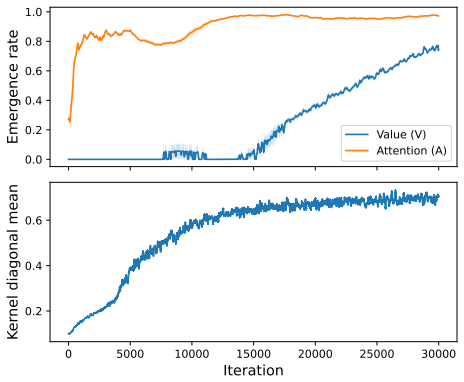


read the original abstract
In-context reinforcement learning (ICRL) studies agents that, after pretraining, adapt to new tasks by conditioning on additional context without parameter updates. Existing theoretical analyses of ICRL largely rely on linear attention, which replaces the softmax function in the standard attention with an identity mapping. This paper provides the first theoretical understanding of ICRL without making the unrealistic linear attention simplification. In particular, we consider the standard softmax attention used in practice. We show that, with certain parameters, the layerwise forward pass of a Transformer with such softmax attention is equivalent to iterative updates of a weighted softmax temporal difference (TD) learning algorithm. Here, weighted softmax TD is a new RL algorithm that performs policy evaluation in kernel space and adopts both linear TD and tabular TD as special cases. We also prove that under a certain contraction condition, the policy evaluation error decays as the number of layers grows, with the identified parameters above. Finally, we prove that those parameters are a global minimizer of a pretraining loss, explaining their emergence in our numerical experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that, with certain parameters, the layerwise forward pass through a Transformer using standard softmax attention is mathematically equivalent to iterative updates of a newly introduced weighted softmax temporal difference (TD) learning algorithm for policy evaluation in kernel space (which subsumes linear and tabular TD as special cases). It further asserts that under a contraction condition these parameters ensure the policy evaluation error decays with network depth, and that the same parameters globally minimize a pretraining loss, thereby explaining their emergence in experiments. This is positioned as the first theoretical account of in-context RL that avoids the linear-attention simplification.
Significance. If the equivalences, contraction, and global-minimizer results hold, the work would be significant for providing the first rigorous bridge between practical softmax Transformers and in-context reinforcement learning. It introduces a new RL algorithm (weighted softmax TD) whose fixed-point and contraction properties are tied directly to Transformer layers, offers a mathematical explanation for why certain parameters arise during pretraining, and removes a key unrealistic assumption from prior ICRL theory.
major comments (2)
- [Abstract] Abstract: the central claim requires a single set of parameters that simultaneously (1) realize the exact forward-pass equivalence to weighted softmax TD iterations, (2) satisfy the contraction condition guaranteeing error decay with depth, and (3) globally minimize the pretraining loss. The abstract states these parameters are identified and proven to be global minimizers, but does not indicate whether the loss minimizer is shown to coincide with the contraction-satisfying equivalence parameters or whether the loss is constructed around the same in-context RL objective, leaving a potential circularity that is load-bearing for the explanation of parameter emergence.
- [Abstract] Abstract: the contraction condition under which the policy evaluation error decays with the number of layers is asserted but neither stated explicitly nor accompanied by the required assumptions on the kernel or weighting function; without these details the error-decay claim cannot be verified and is load-bearing for the depth-dependent convergence result.
minor comments (2)
- The manuscript introduces the weighted softmax TD algorithm; a short paragraph contrasting it with standard linear TD and tabular TD (including how the kernel and weighting recover each as special cases) would improve accessibility.
- Notation for the attention weights, value-function embeddings, and TD update operators should be introduced once in a dedicated preliminaries section and used consistently thereafter to avoid redefinition across sections.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below, clarifying the logical structure of our results and indicating revisions to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim requires a single set of parameters that simultaneously (1) realize the exact forward-pass equivalence to weighted softmax TD iterations, (2) satisfy the contraction condition guaranteeing error decay with depth, and (3) globally minimize the pretraining loss. The abstract states these parameters are identified and proven to be global minimizers, but does not indicate whether the loss minimizer is shown to coincide with the contraction-satisfying equivalence parameters or whether the loss is constructed around the same in-context RL objective, leaving a potential circularity that is load-bearing for the explanation of parameter emergence.
Authors: The parameters identified for the exact forward-pass equivalence to the weighted softmax TD iterations are the same set shown to satisfy the contraction condition (ensuring error decay with depth) and proven to be global minimizers of the pretraining loss. The proof proceeds sequentially: the equivalence is derived first from the attention mechanism and TD update rules, the contraction is established for these parameters under the stated kernel and weighting assumptions, and only then is the global minimization result shown for the pretraining loss (which is defined on the in-context policy evaluation objective). This ordering avoids circularity. We will revise the abstract to explicitly note that the same parameters achieve all three properties and to outline this logical flow. revision: yes
-
Referee: [Abstract] Abstract: the contraction condition under which the policy evaluation error decays with the number of layers is asserted but neither stated explicitly nor accompanied by the required assumptions on the kernel or weighting function; without these details the error-decay claim cannot be verified and is load-bearing for the depth-dependent convergence result.
Authors: The contraction condition (a bound on the operator norm of the weighted softmax TD update) and the supporting assumptions (the kernel is positive semi-definite and the weighting function is non-negative and integrates to one) are stated explicitly in Section 3 and Theorem 4. We agree the abstract is too terse on this point. We will revise the abstract to include a concise statement of the contraction condition together with the key assumptions on the kernel and weighting function. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper first identifies specific parameter settings that make the softmax attention forward pass mathematically equivalent to one step of weighted softmax TD (via direct substitution into the attention equations). It then proves contraction of the value error under those parameters as depth increases. Finally, it proves those same parameters globally minimize the pretraining loss by showing that any other parameters yield strictly higher loss on the in-context prediction task, using the fact that the TD fixed point is the unique minimizer of the Bellman residual in the kernel space. These are three sequential, independent mathematical arguments; the loss is the standard next-token prediction loss on RL trajectories and is not defined in terms of the TD algorithm itself. No self-citations, no fitted parameters renamed as predictions, and no ansatz smuggled via prior work. The central claim therefore rests on explicit derivations rather than reduction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- certain parameters
axioms (1)
- domain assumption contraction condition
invented entities (1)
-
weighted softmax TD learning algorithm
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
with certain parameters, the layerwise forward pass of a Transformer with such softmax attention is equivalent to iterative updates of a weighted softmax temporal difference (TD) learning algorithm
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Reward Is Enough: LLMs Are In-Context Reinforcement Learners , author=. 2026 , booktitle =
work page 2026
-
[2]
Transformers Learn to Implement Multi-step Gradient Descent with Chain of Thought , author=. 2025 , booktitle =
work page 2025
-
[3]
Zixuan Xie and Xinyu Liu and Rohan Chandra and Shangtong Zhang , title =. ArXiv Preprint , year =
-
[4]
Ortega, James M. and Rheinboldt, Werner C. , title =. 2000 , note =
work page 2000
-
[5]
Journal of Machine Learning Research , year =
Jianqing Fan and Bai Jiang and Qiang Sun , title =. Journal of Machine Learning Research , year =
-
[6]
High-Dimensional Probability: An Introduction with Applications in Data Science , author=. 2018 , publisher=
work page 2018
-
[7]
Estimating the Mixing Coefficients of Geometrically Ergodic Markov Processes , author=. 2024 , journal =
work page 2024
-
[8]
A Survey and Some Open Questions , author =
Basic Properties of Strong Mixing Conditions. A Survey and Some Open Questions , author =. Probability Surveys , year =
-
[9]
Softmax Linear: Transformers May Learn to Classify In-Context by Kernel Gradient Descent , author =. 2025 , journal =
work page 2025
-
[10]
Advances in Neural Information Processing Systems , year =
Towards Understanding How Transformers Learn In-Context Through a Representation Learning Lens , author =. Advances in Neural Information Processing Systems , year =
-
[11]
and Cao, Yuan and Narasimhan, Karthik , title =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , title =. 2023 , booktitle=
work page 2023
-
[12]
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , booktitle=
work page 2023
-
[13]
Artificial Generational Intelligence: Cultural Accumulation in Reinforcement Learning , author=. 2024 , booktitle=
work page 2024
-
[14]
Transformers are Meta-Reinforcement Learners , author=. 2022 , booktitle=
work page 2022
-
[15]
VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning , author=. 2020 , booktitle=
work page 2020
-
[16]
Some Considerations on Learning to Explore via Meta-Reinforcement Learning , author=. 2018 , journal=
work page 2018
-
[17]
International Conference on Machine Learning , year=
Been There, Done That: Meta-Learning with Episodic Recall , author=. International Conference on Machine Learning , year=
-
[18]
A Simple Neural Attentive Meta-Learner , author=. 2018 , booktitle=
work page 2018
-
[19]
Theory of Probability and its Applications , year=
On estimating regression , author=. Theory of Probability and its Applications , year=
-
[20]
Smooth regression analysis , author=. Sankhy
-
[21]
Learning with Kernels , author=
-
[22]
Gaussian Processes for Machine Learning , author=
-
[23]
Transformers learn to implement preconditioned gradient descent for in-context learning , year =
Ahn, Kwangjun and Cheng, Xiang and Daneshmand, Hadi and Sra, Suvrit , journal =. Transformers learn to implement preconditioned gradient descent for in-context learning , year =
-
[24]
Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Natalia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burovski, Evgeni and Chauhan, Geeta and Chourdia, Anjali and Constable, Will and Desmaison, Alban and DeVito, Zachary and Ellison, Elias and Feng, Will and Gong, Jiong and Gschwind, Michael and ...
-
[25]
International conference on machine learning , title =
Azar, Mohammad Gheshlaghi and Osband, Ian and Munos, R. International conference on machine learning , title =
-
[26]
Proceedings of the International Conference on Machine Learning , year=
Human-timescale adaptation in an open-ended task space , author=. Proceedings of the International Conference on Machine Learning , year=
-
[27]
A survey of meta-reinforcement learning , year =
Beck, Jacob and Vuorio, Risto and Liu, Evan Zheran and Xiong, Zheng and Zintgraf, Luisa and Finn, Chelsea and Whiteson, Shimon , journal =. A survey of meta-reinforcement learning , year =
-
[28]
Boyan, Justin A. , booktitle =. Least-Squares Temporal Difference Learning , year =
-
[29]
Proceedings of the International Conference on Learning Representations , year=
Randomized ensembled double q-learning: Learning fast without a model , author=. Proceedings of the International Conference on Learning Representations , year=
-
[30]
Contextual bandits with linear payoff functions , year =
Chu, Wei and Li, Lihong and Reyzin, Lev and Schapire, Robert , booktitle =. Contextual bandits with linear payoff functions , year =
-
[31]
In-context Exploration-Exploitation for Reinforcement Learning , author=. 2024 , booktitle =
work page 2024
-
[32]
Duan, Yan and Schulman, John and Chen, Xi and Bartlett, Peter L and Sutskever, Ilya and Abbeel, Pieter , journal =
-
[33]
AMAGO: Scalable In-Context Reinforcement Learning for Adaptive Agents , author=. 2024 , booktitle =
work page 2024
-
[34]
AMAGO-2: Breaking the Multi-Task Barrier in Meta-Reinforcement Learning with Transformers , author=. 2024 , booktitle =
work page 2024
-
[35]
Harris, Charles R. and Millman, K. Jarrod and van der Walt, St. Nature , title =
-
[36]
Proceedings of the International Conference on Machine Learning , year=
In-context decision transformer: reinforcement learning via hierarchical chain-of-thought , author=. Proceedings of the International Conference on Machine Learning , year=
-
[37]
Decision Mamba: Reinforcement Learning via Hybrid Selective Sequence Modeling , author=. 2024 , booktitle =
work page 2024
-
[38]
Hunter, J. D. , journal =. Matplotlib: A 2D graphics environment , year =
-
[39]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Introducing symmetries to black box meta reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[40]
Proceedings of the International Conference on Learning Representations , year=
In-context reinforcement learning with algorithm distillation , author=. Proceedings of the International Conference on Learning Representations , year=
-
[41]
Proceedings of the International Conference on Learning Representations , year=
Transformers as decision makers: Provable in-context reinforcement learning via supervised pretraining , author=. Proceedings of the International Conference on Learning Representations , year=
-
[42]
Proceedings of the International Conference on Machine Learning , year=
Emergent agentic transformer from chain of hindsight experience , author=. Proceedings of the International Conference on Machine Learning , year=
-
[43]
Advances in Neural Information Processing Systems , year=
Structured state space models for in-context reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[44]
and Veness, Joel and Bellemare, Marc G
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Rusu, Andrei A. and Veness, Joel and Bellemare, Marc G. and Graves, Alex and Riedmiller, Martin A. and Fidjeland, Andreas and Ostrovski, Georg and Petersen, Stig and Beattie, Charles and Sadik, Amir and Antonoglou, Ioannis and King, Helen and Kumaran, Dharshan and Wierstra, Daan and Legg, Shane ...
-
[45]
Proceedings of the International Conference on Machine Learning , title =
Mnih, Volodymyr and Badia, Adri. Proceedings of the International Conference on Machine Learning , title =
-
[46]
Safe in-context reinforcement learning , author=. ArXiv Preprint , year=
-
[47]
A Survey of In-Context Reinforcement Learning , author=. 2025 , journal =
work page 2025
-
[48]
and Zhang, Kaiqing , booktitle=
Park, Chanwoo and Liu, Xiangyu and Ozdaglar, Asuman E. and Zhang, Kaiqing , booktitle=. Do
-
[49]
Proceedings of the International Conference on Machine Learning , year=
Vintix: Action model via in-context reinforcement learning , author=. Proceedings of the International Conference on Machine Learning , year=
-
[50]
Markov decision processes: discrete stochastic dynamic programming , year =
Puterman, Martin L , publisher =. Markov decision processes: discrete stochastic dynamic programming , year =
-
[51]
A tutorial on thompson sampling , year =
Russo, Daniel J and Van Roy, Benjamin and Kazerouni, Abbas and Osband, Ian and Wen, Zheng and others , journal =. A tutorial on thompson sampling , year =
-
[52]
and Moritz, Philipp , booktitle =
Schulman, John and Levine, Sergey and Abbeel, Pieter and Jordan, Michael I. and Moritz, Philipp , booktitle =. Trust Region Policy Optimization , year =
-
[53]
Proximal Policy Optimization Algorithms , year =
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , journal =. Proximal Policy Optimization Algorithms , year =
-
[54]
A primal-dual perspective of online learning algorithms , author=. Machine Learning , year=
-
[55]
Advances in Neural Information Processing Systems , year=
Cross-episodic curriculum for transformer agents , author=. Advances in Neural Information Processing Systems , year=
-
[56]
Sutton, Richard S. , journal =. Learning to Predict by the Methods of Temporal Differences , year =
-
[57]
Reinforcement Learning: An Introduction (2nd Edition) , year =
Sutton, Richard S and Barto, Andrew G , publisher =. Reinforcement Learning: An Introduction (2nd Edition) , year =
-
[58]
Sutton, Richard S. and Maei, Hamid R. and Szepesv. Advances in Neural Information Processing Systems , title =
-
[59]
and Maei, Hamid Reza and Precup, Doina and Bhatnagar, Shalabh and Silver, David and Szepesv
Sutton, Richard S. and Maei, Hamid Reza and Precup, Doina and Bhatnagar, Shalabh and Silver, David and Szepesv. Proceedings of the International Conference on Machine Learning , title =
-
[60]
Tarasov, Denis and Nikulin, Alexander and Zisman, Ilya and Klepach, Albina and Polubarov, Andrei and Nikita, Lyubaykin and Derevyagin, Alexander and Kiselev, Igor and Kurenkov, Vladislav , booktitle=. Yes,
-
[61]
Attention is All you Need , year =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , year =
-
[62]
Learning to reinforcement learn , year =
Wang, Jane X and Kurth-Nelson, Zeb and Tirumala, Dhruva and Soyer, Hubert and Leibo, Joel Z and Munos, Remi and Blundell, Charles and Kumaran, Dharshan and Botvinick, Matt , journal =. Learning to reinforcement learn , year =
-
[63]
Proceedings of the International Conference on Learning Representations , year=
Transformers can learn temporal difference methods for in-context reinforcement learning , author=. Proceedings of the International Conference on Learning Representations , year=
-
[64]
Proceedings of the International Conference on Machine Learning , year =
Meta-Reinforcement Learning Robust to Distributional Shift Via Performing Lifelong In-Context Learning , author =. Proceedings of the International Conference on Machine Learning , year =
-
[65]
Journal of Machine Learning Research , year=
Trained transformers learn linear models in-context , author=. Journal of Machine Learning Research , year=
-
[66]
Proceedings of the International Conference on Machine Learning , year=
Emergence of in-context reinforcement learning from noise distillation , author=. Proceedings of the International Conference on Machine Learning , year=
-
[67]
Ilya Zisman and Alexander Nikulin and Viacheslav Sinii and Denis Tarasov and Nikita Lyubaykin and Andrei Polubarov and Igor Kiselev and Vladislav Kurenkov , booktitle =
-
[68]
Proceedings of the International Conference on Machine Learning , year=
Human-Timescale Adaptation in an Open-Ended Task Space , author =. Proceedings of the International Conference on Machine Learning , year=
-
[69]
NeurIPS Foundation Models for Decision Making Workshop , year=
Towards General-Purpose In-Context Learning Agents , author=. NeurIPS Foundation Models for Decision Making Workshop , year=
-
[70]
Generalized Decision Transformer for Offline Hindsight Information Matching , author=. 2022 , booktitle=
work page 2022
-
[71]
Prompting Decision Transformer for Few-Shot Policy Generalization , author=. 2022 , booktitle=
work page 2022
-
[72]
RvS: What is Essential for Offline RL via Supervised Learning? , author=. 2022 , booktitle=
work page 2022
-
[73]
Transactions on Machine Learning Research , year=
Random Policy Enables In-Context Reinforcement Learning within Trust Horizons , author=. Transactions on Machine Learning Research , year=
-
[74]
Proceedings of the International Conference on Machine Learning , year=
Generalization to New Sequential Decision Making Tasks with In-Context Learning , author =. Proceedings of the International Conference on Machine Learning , year=
-
[75]
Scaling Algorithm Distillation for Continuous Control with Mamba , author=. ArXiv preprint , year=
-
[76]
Ahmad Elawady and Gunjan Chhablani and Ram Ramrakhya and Karmesh Yadav and Dhruv Batra and Zsolt Kira and Andrew Szot , journal=
-
[77]
Proceedings of the Conference on Robot Learning , year=
LocoFormer: Generalist Locomotion via Long-context Adaptation , author=. Proceedings of the Conference on Robot Learning , year=
-
[78]
Can Looped Transformers Learn to Implement Multi-step Gradient Descent for In-context Learning? , author=. 2024 , booktitle =
work page 2024
-
[79]
A Tutorial on Meta-Reinforcement Learning , author=. 2025 , journal =
work page 2025
-
[80]
Huang, Sili and Hu, Jifeng and Chen, Hechang and Sun, Lichao and Yang, Bo , title =. 2024 , booktitle =
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.