Recognition: 2 theorem links
· Lean TheoremZero-Shot Neural Network Evaluation with Sample-Wise Activation Patterns
Pith reviewed 2026-05-11 01:58 UTC · model grok-4.3
The pith
Sample-wise activation patterns yield a zero-shot score that ranks neural networks by their eventual trained performance across CNNs and Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
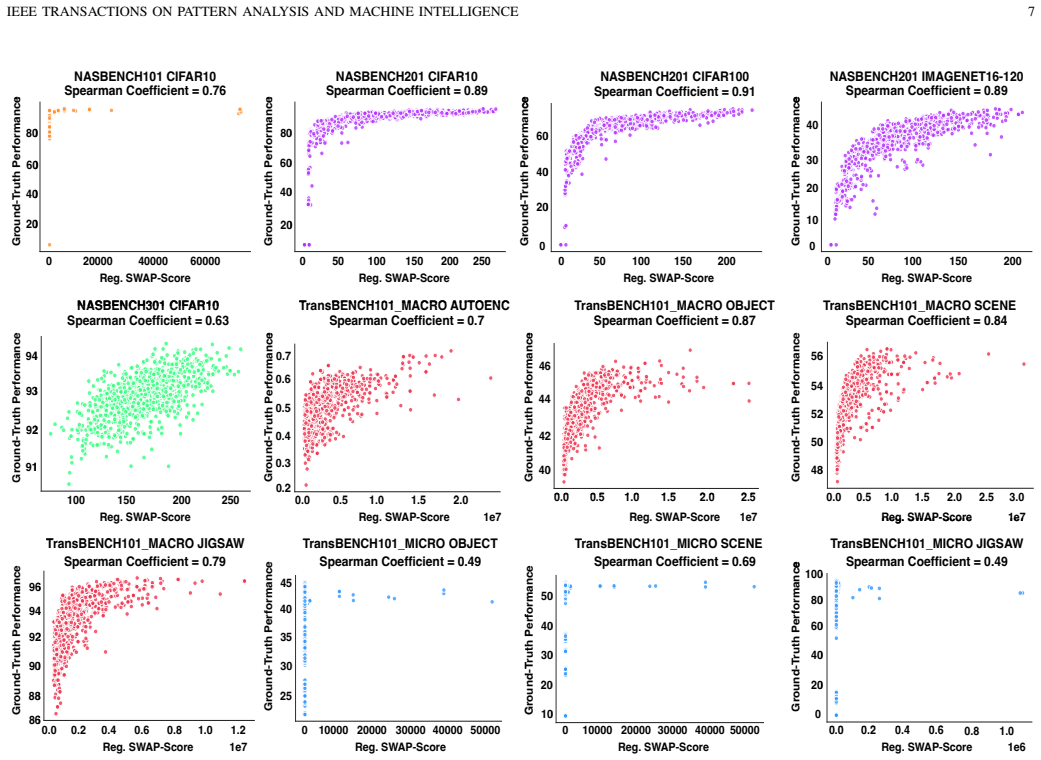
SWAP-Score, computed directly from the sample-wise activation patterns that arise when a network processes an unlabeled mini-batch, serves as a training-free predictor of a network's performance after full supervised training. The same formulation applies to both convolutional and transformer architectures and produces higher rank correlation with ground-truth accuracy than prior zero-shot proxies on CIFAR-10, ImageNet, and GLUE tasks.
What carries the argument
Sample-Wise Activation Patterns (SWAP), which record per-sample binary activation states across layers to quantify how distinctly a network separates the inputs in a mini-batch.
If this is right
- Networks can be ranked for Neural Architecture Search using only minutes of GPU time on CIFAR-10 and ImageNet while still reaching competitive final accuracy.
- Language models can be screened for downstream-task potential during pre-training because the metric does not require task labels.
- A single formulation works for both CNNs and Transformers, removing the need to maintain separate zero-shot proxies for each family.
- The metric supplies a concrete numerical signal for how much a network distinguishes individual samples, which can be inspected layer by layer.
Where Pith is reading between the lines
- If activation diversity on random samples is the dominant driver, then simple data-augmentation strategies that increase sample distinctness might raise SWAP-Score without changing the architecture.
- The same patterns could be monitored during training to detect when a network has stopped gaining new expressivity and training can be stopped early.
- Because the computation is label-independent, the score might serve as a quick filter for transfer-learning candidates before any fine-tuning begins.
Load-bearing premise
The activation patterns produced by an unlabeled mini-batch already encode enough information about a network's overall expressivity to forecast its accuracy after complete training on a specific downstream dataset.
What would settle it
A new architecture family or dataset in which the SWAP-Score ordering of networks disagrees sharply with the ordering obtained after full training and validation.
Figures












read the original abstract
Zero-shot proxies, also known as training-free metrics, are widely adopted to reduce the computational overhead in neural network evaluation for scenarios such as Neural Architecture Search (NAS), as they do not require any training. Existing zero-shot metrics have several limitations, including weak correlation with the true performance and poor generalisation across different networks or downstream tasks. For example, most of these metrics apply only to either convolutional neural networks (CNNs) or Transformers, but not both. To address these limitations, we propose Sample-Wise Activation Patterns (SWAP), and its derivative, SWAP-Score, a novel and highly effective zero-shot metric. SWAP-Score is broadly applicable across both architecture families and task domains, demonstrating strong predictive performance in the majority of tasks. This metric measures the expressivity of neural networks over a mini-batch of samples, showing a high correlation with the neural networks' ground-truth performance. For both CNNs and Transformers, the SWAP-Score outperforms existing zero-shot metrics across computer vision and natural language processing tasks. For instance, Spearman's correlation coefficient between the SWAP-Score and CIFAR-10 validation accuracy for DARTS CNNs is 0.93, and 0.71 for FlexiBERT Transformers on GLUE tasks. Moreover, SWAP-Score is label-independent, hence can be applied at the pre-training stage of language models to estimate their performance for downstream tasks. When applied to NAS, SWAP-empowered NAS, SWAP-NAS can achieve competitive performance using only approximately 6 and 9 minutes of GPU time, on CIFAR-10 and ImageNet respectively. Our code is available at: https://github.com/pym1024/SWAP_Universal
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sample-Wise Activation Patterns (SWAP) and its derivative SWAP-Score as a novel zero-shot, label-independent metric for neural network evaluation. It claims that activation patterns computed on an unlabeled mini-batch capture network expressivity, yielding high Spearman correlations with post-training accuracy (e.g., 0.93 for DARTS CNNs on CIFAR-10 and 0.71 for FlexiBERT Transformers on GLUE), outperforming prior zero-shot proxies across CNNs and Transformers in CV and NLP, and enabling competitive NAS in minutes of GPU time.
Significance. A reliable, architecture- and task-agnostic zero-shot metric would be a substantial contribution to NAS and model selection, as it could eliminate training costs while maintaining predictive power; the reported NAS timings (6 min on CIFAR-10, 9 min on ImageNet) and cross-domain applicability illustrate the potential practical impact if the correlations prove robust.
major comments (3)
- [Abstract] Abstract: the stated correlations (0.93 on DARTS/CIFAR-10, 0.71 on FlexiBERT/GLUE) and outperformance claims are presented without any definition of how SWAP is computed (which layers, how activation patterns are encoded or aggregated, mini-batch size), which samples are used, or any statistical tests/controls, rendering it impossible to evaluate whether the numbers support the expressivity claim.
- [Abstract] Abstract: no ablations or sensitivity analyses are referenced for mini-batch choice or data distribution, which is load-bearing for the central claim that SWAP-Score measures intrinsic network expressivity rather than alignment with the particular unlabeled samples; without such checks the reported correlations could be inflated by implicit data overlap.
- [Abstract] Abstract: the claim that SWAP-Score is 'broadly applicable across both architecture families and task domains' and 'outperforms existing zero-shot metrics' requires explicit baseline comparisons and quantitative tables in the results; the abstract alone supplies no such evidence.
minor comments (1)
- The abstract states that code is available at a GitHub link; ensure the repository contains the exact implementation used for the reported numbers to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly identify that the abstract is highly condensed and would benefit from additional context to make the central claims more evaluable on their own. We will revise the abstract to incorporate brief definitions, robustness notes, and references to the quantitative comparisons while preserving its length. Point-by-point responses are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the stated correlations (0.93 on DARTS/CIFAR-10, 0.71 on FlexiBERT/GLUE) and outperformance claims are presented without any definition of how SWAP is computed (which layers, how activation patterns are encoded or aggregated, mini-batch size), which samples are used, or any statistical tests/controls, rendering it impossible to evaluate whether the numbers support the expressivity claim.
Authors: We agree that the abstract does not define the computation of SWAP-Score. The full methodological details—including the layers from which activations are taken, the binary encoding and aggregation of sample-wise patterns, the unlabeled mini-batch size and sampling procedure, and the statistical controls—are provided in Section 3 of the manuscript. To address the concern, we will revise the abstract to include a concise, high-level definition of how SWAP is computed and note that statistical significance is reported via Spearman correlations with associated p-values. revision: yes
-
Referee: [Abstract] Abstract: no ablations or sensitivity analyses are referenced for mini-batch choice or data distribution, which is load-bearing for the central claim that SWAP-Score measures intrinsic network expressivity rather than alignment with the particular unlabeled samples; without such checks the reported correlations could be inflated by implicit data overlap.
Authors: This observation is fair; the abstract does not reference sensitivity checks. The manuscript contains ablations on mini-batch size and data distribution in Section 4.3 that demonstrate stable correlations across reasonable ranges of batch sizes and sampling strategies, supporting the expressivity interpretation. We will add a short clause to the revised abstract referencing these robustness results. revision: yes
-
Referee: [Abstract] Abstract: the claim that SWAP-Score is 'broadly applicable across both architecture families and task domains' and 'outperforms existing zero-shot metrics' requires explicit baseline comparisons and quantitative tables in the results; the abstract alone supplies no such evidence.
Authors: We accept that the abstract summarizes the outperformance without citing the supporting tables. Section 4 and Tables 1–3 provide the explicit comparisons to prior zero-shot proxies across CNN and Transformer benchmarks in both CV and NLP, with the reported Spearman values. We will revise the abstract to briefly note the outperformance relative to baselines and direct readers to the quantitative results. revision: yes
Circularity Check
No circularity: SWAP-Score defined independently from activation patterns
full rationale
The metric is constructed solely from sample-wise activation patterns over an unlabeled mini-batch, with no reference to downstream accuracy values or labels in its definition. Reported correlations (e.g., 0.93 on DARTS/CIFAR-10) are computed afterward as external validation, not embedded in the construction. No equations reduce the score to a fit on target performance, no self-citations bear the central claim, and the derivation does not rename or smuggle in prior results by construction. The chain remains self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDefinition III.3 (SWAP-Score Ψ): cardinality of the set of sample-wise binarized activation vectors ˆA_N,θ
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearSection III-A: linear regions and expressivity for ReLU/GELU networks
Reference graph
Works this paper leans on
-
[1]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review arXiv 2015
-
[2]
Learning both weights and con- nections for efficient neural network,
S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and con- nections for efficient neural network,”Advances in neural information processing systems, vol. 28, 2015
work page 2015
-
[3]
Neural architecture search without training,
J. Mellor, J. Turner, A. J. Storkey, and E. J. Crowley, “Neural architecture search without training,” inProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol. 139. PMLR, 2021, pp. 7588–7598
work page 2021
-
[4]
Zero- cost proxies for lightweight NAS,
M. S. Abdelfattah, A. Mehrotra, L. Dudziak, and N. D. Lane, “Zero- cost proxies for lightweight NAS,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021
work page 2021
-
[5]
On the number of linear regions of deep neural networks,
G. Mont ´ufar, R. Pascanu, K. Cho, and Y . Bengio, “On the number of linear regions of deep neural networks,” inAdvances in Neural Informa- tion Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, Ed...
work page 2014
-
[6]
Knowledge distillation via the target-aware transformer,
S. Lin, H. Xie, B. Wang, K. Yu, X. Chang, X. Liang, and G. Wang, “Knowledge distillation via the target-aware transformer,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 10 915–10 924
work page 2022
-
[7]
Distilling the Knowledge in a Neural Network
G. Hinton, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
FitNets: Hints for Thin Deep Nets
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y . Ben- gio, “Fitnets: Hints for thin deep nets,”arXiv preprint arXiv:1412.6550, 2014
work page internal anchor Pith review arXiv 2014
-
[9]
Mastering the game of go with deep neural networks and tree search,
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V . Panneershelvam, M. Lanctotet al., “Mastering the game of go with deep neural networks and tree search,”nature, vol. 529, no. 7587, pp. 484–489, 2016
work page 2016
-
[10]
Neural architecture search with reinforcement learning,
B. Zoph and Q. V . Le, “Neural architecture search with reinforcement learning,” inInternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[11]
A comprehensive survey of neural architecture search: Challenges and solutions,
P. Ren, Y . Xiao, X. Chang, P. Huang, Z. Li, X. Chen, and X. Wang, “A comprehensive survey of neural architecture search: Challenges and solutions,”ACM Comput. Surv., vol. 54, no. 4, pp. 76:1–76:34, 2022
work page 2022
- [12]
-
[13]
Y . Sun, H. Wang, B. Xue, Y . Jin, G. G. Yen, and M. Zhang, “Surrogate- assisted evolutionary deep learning using an end-to-end random forest- based performance predictor,”IEEE Trans. Evol. Comput., vol. 24, no. 2, pp. 350–364, 2020
work page 2020
-
[14]
Neural predictor for neural architecture search,
W. Wen, H. Liu, Y . Chen, H. H. Li, G. Bender, and P. Kindermans, “Neural predictor for neural architecture search,” inComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23- 28, 2020, Proceedings, Part XXIX, vol. 12374. Springer, 2020, pp. 660–676
work page 2020
-
[15]
Pre- nas: Evolutionary neural architecture search with predictor,
Y . Peng, A. Song, V . Ciesielski, H. M. Fayek, and X. Chang, “Pre- nas: Evolutionary neural architecture search with predictor,”IEEE Transactions on Evolutionary Computation, vol. 27, no. 1, pp. 26–36, 2023
work page 2023
-
[16]
Con- trastive neural architecture search with neural architecture comparators,
Y . Chen, Y . Guo, Q. Chen, M. Li, W. Zeng, Y . Wang, and M. Tan, “Con- trastive neural architecture search with neural architecture comparators,” inIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. Computer Vision Foundation / IEEE, 2021, pp. 9502–9511
work page 2021
-
[17]
Efficient neural architecture search via parameters sharing,
H. Pham, M. Guan, B. Zoph, Q. Le, and J. Dean, “Efficient neural architecture search via parameters sharing,” inProceedings of the 35th International Conference on Machine Learning (ICML), 2018, pp. 4095– 4104
work page 2018
-
[18]
DARTS: differentiable architec- ture search,
H. Liu, K. Simonyan, and Y . Yang, “DARTS: differentiable architec- ture search,” inInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[19]
Neural architecture search on imagenet in four GPU hours: A theoretically inspired perspective,
W. Chen, X. Gong, and Z. Wang, “Neural architecture search on imagenet in four GPU hours: A theoretically inspired perspective,” in 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
work page 2021
-
[20]
Zen-nas: A zero-shot NAS for high-performance image recognition,
M. Lin, P. Wang, Z. Sun, H. Chen, X. Sun, Q. Qian, H. Li, and R. Jin, “Zen-nas: A zero-shot NAS for high-performance image recognition,” in2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, 2021, pp. 337–346
work page 2021
-
[21]
Epe-nas: Efficient performance estimation without training for neural architecture search,
V . Lopes, S. Alirezazadeh, and L. A. Alexandre, “Epe-nas: Efficient performance estimation without training for neural architecture search,” inArtificial Neural Networks and Machine Learning–ICANN 2021: 30th International Conference on Artificial Neural Networks, Bratislava, Slovakia, September 14–17, 2021, Proceedings, Part V. Springer, 2021, pp. 552–563
work page 2021
-
[22]
J. Mok, B. Na, J. Kim, D. Han, and S. Yoon, “Demystifying the neural tangent kernel from a practical perspective: Can it be trusted for neural architecture search without training?” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 2022, pp. 11 851–11 860
work page 2022
-
[23]
Pruning neural networks without any data by iteratively conserving synaptic flow,
H. Tanaka, D. Kunin, D. L. K. Yamins, and S. Ganguli, “Pruning neural networks without any data by iteratively conserving synaptic flow,” in Advances in Neural Information Processing Systems 33: Annual Con- ference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, a...
work page 2020
-
[24]
Zico: Zero-shot NAS via inverse coefficient of variation on gradients,
G. Li, Y . Yang, K. Bhardwaj, and R. Marculescu, “Zico: Zero-shot NAS via inverse coefficient of variation on gradients,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 14
work page 2023
-
[25]
Nas-bench-suite-zero: Accelerating research on zero cost proxies,
A. Krishnakumar, C. White, A. Zela, R. Tu, M. Safari, and F. Hutter, “Nas-bench-suite-zero: Accelerating research on zero cost proxies,” inThirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022
work page 2022
-
[26]
On the number of linear regions of convolutional neural networks,
H. Xiong, L. Huang, M. Yu, L. Liu, F. Zhu, and L. Shao, “On the number of linear regions of convolutional neural networks,” inProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 2020, pp. 10 514–10 523
work page 2020
-
[27]
Nas-bench-101: Towards reproducible neural architecture search,
C. Ying, A. Klein, E. Christiansen, E. Real, K. Murphy, and F. Hutter, “Nas-bench-101: Towards reproducible neural architecture search,” in Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, vol. 97. PMLR, 2019, pp. 7105–7114
work page 2019
-
[28]
Nas-bench-201: Extending the scope of repro- ducible neural architecture search,
X. Dong and Y . Yang, “Nas-bench-201: Extending the scope of repro- ducible neural architecture search,” in8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26- 30, 2020, 2020
work page 2020
-
[29]
Nas-bench-301 and the case for surrogate benchmarks for neural architecture search,
J. Siems, L. Zimmer, A. Zela, J. Lukasik, M. Keuper, and F. Hutter, “Nas-bench-301 and the case for surrogate benchmarks for neural architecture search,”CoRR, vol. abs/2008.09777, 2020
-
[30]
Y . Duan, X. Chen, H. Xu, Z. Chen, X. Liang, T. Zhang, and Z. Li, “Transnas-bench-101: Improving transferability and generalizability of cross-task neural architecture search,” inIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. Computer Vision Foundation / IEEE, 2021, pp. 5251–5260
work page 2021
-
[31]
Flexibert: Are current trans- former architectures too homogeneous and rigid?
S. Tuli, B. Dedhia, S. Tuli, and N. K. Jha, “Flexibert: Are current trans- former architectures too homogeneous and rigid?”Journal of Artificial Intelligence Research, vol. 77, pp. 39–70, 2023
work page 2023
-
[32]
GLUE: A multi-task benchmark and analysis platform for natural language understanding,
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” inInternational Conference on Learning Rep- resentations, 2019
work page 2019
-
[33]
Regularized evolution for image classifier architecture search,
E. Real, A. Aggarwal, Y . Huang, and Q. V . Le, “Regularized evolution for image classifier architecture search,” inAAAI Conference on Artificial Intelligence, vol. 33, 2019, p. 4780–4789
work page 2019
-
[34]
Accelerating neural architecture search using performance prediction
B. Baker, O. Gupta, R. Raskar, and N. Naik, “Practical neural network performance prediction for early stopping,”CoRR, vol. abs/1705.10823, 2017
-
[35]
Darts+: Improved differentiable architecture search with early stopping,
H. Liang, S. Zhang, J. Sun, X. He, W. Huang, K. Zhuang, and Z. Li, “Darts+: Improved differentiable architecture search with early stopping,” 2019
work page 2019
-
[36]
Learning curve prediction with bayesian neural networks,
A. Klein, S. Falkner, J. T. Springenberg, and F. Hutter, “Learning curve prediction with bayesian neural networks,”International Conference on Learning Representations, 2017
work page 2017
-
[37]
Mnasnet: Platform-aware neural architecture search for mobile,
M. Tan, B. Chen, R. Pang, V . Vasudevan, M. Sandler, A. Howard, and Q. V . Le, “Mnasnet: Platform-aware neural architecture search for mobile,” inIEEE Conference on Computer Vision and Pattern Recognition, (CVPR), 2019, pp. 2820–2828
work page 2019
-
[38]
Progressive neural architecture search,
C. Liu, B. Zoph, M. Neumann, J. Shlens, W. Hua, L.-J. Li, L. Fei-Fei, A. Yuille, J. Huang, and K. Murphy, “Progressive neural architecture search,” inProceedings of the European Conference on Computer Vision (ECCV), September 2018
work page 2018
-
[39]
Semi- supervised neural architecture search,
R. Luo, X. Tan, R. Wang, T. Qin, E. Chen, and T. Liu, “Semi- supervised neural architecture search,” inAdvances in Neural Informa- tion Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020
work page 2020
-
[40]
Bridging the gap between sample-based and one-shot neural architecture search with bonas,
H. Shi, R. Pi, H. Xu, Z. Li, J. T. Kwok, and T. Zhang, “Bridging the gap between sample-based and one-shot neural architecture search with bonas,” inAdvances in Neural Information Processing Systems, vol. 33, 2020
work page 2020
-
[41]
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
H. Cai, L. Zhu, and S. Han, “Proxylessnas: Direct neural architecture search on target task and hardware,”CoRR, vol. abs/1812.00332, 2018
work page Pith review arXiv 2018
-
[42]
Fair DARTS: eliminating unfair advantages in differentiable architecture search,
X. Chu, T. Zhou, B. Zhang, and J. Li, “Fair DARTS: eliminating unfair advantages in differentiable architecture search,” inComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XV, vol. 12360. Springer, 2020, pp. 465–480
work page 2020
-
[43]
One-shot neural architecture search via self- evaluated template network,
X. Dong and Y . Yang, “One-shot neural architecture search via self- evaluated template network,” in2019 IEEE/CVF International Confer- ence on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019. IEEE, 2019, pp. 3680–3689
work page 2019
-
[44]
PC- DARTS: partial channel connections for memory-efficient differentiable architecture search,
Y . Xu, L. Xie, X. Zhang, X. Chen, G. Qi, Q. Tian, and H. Xiong, “PC- DARTS: partial channel connections for memory-efficient differentiable architecture search,” inInternational Conference on Learning Represen- tations (ICLR), 2020
work page 2020
-
[45]
Weight-sharing neural architecture search: A battle to shrink the optimization gap,
L. Xie, X. Chen, K. Bi, L. Wei, Y . Xu, L. Wang, Z. Chen, A. Xiao, J. Chang, X. Zhanget al., “Weight-sharing neural architecture search: A battle to shrink the optimization gap,”ACM Computing Surveys (CSUR), vol. 54, no. 9, pp. 1–37, 2021
work page 2021
-
[46]
Meco: zero-shot nas with one data and single forward pass via minimum eigenvalue of correlation,
T. Jiang, H. Wang, and R. Bie, “Meco: zero-shot nas with one data and single forward pass via minimum eigenvalue of correlation,”Advances in Neural Information Processing Systems, vol. 36, pp. 61 020–61 047, 2023
work page 2023
-
[47]
Neural tangent kernel: Conver- gence and generalization in neural networks,
A. Jacot, C. Hongler, and F. Gabriel, “Neural tangent kernel: Conver- gence and generalization in neural networks,” inAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montr ´eal, Canada, S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianc...
work page 2018
-
[48]
Training-free transformer architecture search,
Q. Zhou, K. Sheng, X. Zheng, K. Li, X. Sun, Y . Tian, J. Chen, and R. Ji, “Training-free transformer architecture search,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 894–10 903
work page 2022
-
[49]
Training-free neural architecture search for rnns and transformers,
A. Serianni and J. Kalita, “Training-free neural architecture search for rnns and transformers,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, A. Rogers, J. L. Boyd-Graber, and N. Okazaki, Eds. Association for Computational Linguistics, 2023, p...
work page 2023
-
[50]
On the number of response regions of deep feedforward networks with piecewise linear activa- tions,
R. Pascanu, G. Montufar, and Y . Bengio, “On the number of response re- gions of deep feed forward networks with piece-wise linear activations,” arXiv preprint arXiv:1312.6098, 2013
-
[51]
Rectified linear units improve restricted boltzmann machines,
V . Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” inProceedings of the 27th International Confer- ence on Machine Learning (ICML-10), June 21-24, 2010, Haifa, Israel, J. F ¨urnkranz and T. Joachims, Eds. Omnipress, 2010, pp. 807–814
work page 2010
-
[52]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),”arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[53]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[54]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[55]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA. IEEE Computer Society, 2009, pp. 248–255
work page 2009
-
[56]
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
P. Chrabaszcz, I. Loshchilov, and F. Hutter, “A downsampled variant of imagenet as an alternative to the CIFAR datasets,”CoRR, vol. abs/1707.08819, 2017
work page Pith review arXiv 2017
-
[57]
Taskonomy: Disentangling task transfer learning,
A. R. Zamir, A. Sax, W. B. Shen, L. J. Guibas, J. Malik, and S. Savarese, “Taskonomy: Disentangling task transfer learning,” in2018 IEEE Con- ference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. Computer Vision Foundation / IEEE Computer Society, 2018, pp. 3712–3722
work page 2018
-
[58]
Places: A 10 million image database for scene recognition,
B. Zhou, `A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 6, pp. 1452–1464, 2018
work page 2018
-
[59]
Rethinking the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826
work page 2016
-
[60]
Blockswap: Fisher-guided block substitution for network compression on a budget,
J. Turner, E. J. Crowley, M. O’Boyle, A. Storkey, and G. Gray, “Blockswap: Fisher-guided block substitution for network compression on a budget,” inInternational Conference on Learning Representations, 2020
work page 2020
-
[61]
Evaluating efficient performance estimators of neural architectures,
X. Ning, C. Tang, W. Li, Z. Zhou, S. Liang, H. Yang, and Y . Wang, “Evaluating efficient performance estimators of neural architectures,” Advances in Neural Information Processing Systems, vol. 34, pp. 12 265–12 277, 2021
work page 2021
-
[62]
Picking winning tickets before training by preserving gradient flow,
C. Wang, G. Zhang, and R. Grosse, “Picking winning tickets before training by preserving gradient flow,” inInternational Conference on Learning Representations
-
[63]
Snip: Single-shot network pruning based on connection sensitivity,
N. Lee, T. Ajanthan, and P. Torr, “Snip: Single-shot network pruning based on connection sensitivity,” inInternational Conference on Learn- ing Representations
-
[64]
Pruning neural networks without any data by iteratively conserving synaptic flow,
H. Tanaka, D. Kunin, D. L. Yamins, and S. Ganguli, “Pruning neural networks without any data by iteratively conserving synaptic flow,” Advances in neural information processing systems, vol. 33, pp. 6377– 6389, 2020. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 15
work page 2020
-
[65]
A. Gokaslan and V . Cohen, “Openwebtext corpus,” http://Skylion007. github.io/OpenWebTextCorpus, 2019
work page 2019
-
[66]
ELECTRA: Pre- training text encoders as discriminators rather than generators,
K. Clark, M.-T. Luong, Q. V . Le, and C. D. Manning, “ELECTRA: Pre- training text encoders as discriminators rather than generators,” inICLR,
-
[67]
Available: https://openreview.net/pdf?id=r1xMH1BtvB
[Online]. Available: https://openreview.net/pdf?id=r1xMH1BtvB
-
[68]
Neural network accept- ability judgments,
A. Warstadt, A. Singh, and S. R. Bowman, “Neural network accept- ability judgments,”Transactions of the Association for Computational Linguistics, vol. 7, pp. 625–641, 2019
work page 2019
-
[69]
A broad-coverage challenge corpus for sentence understanding through inference,
A. Williams, N. Nangia, and S. Bowman, “A broad-coverage challenge corpus for sentence understanding through inference,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2018, pp. 1112–1122
work page 2018
-
[70]
Automatically constructing a corpus of sen- tential paraphrases,
B. Dolan and C. Brockett, “Automatically constructing a corpus of sen- tential paraphrases,” inThird international workshop on paraphrasing (IWP2005), 2005
work page 2005
-
[71]
Squad: 100,000+ questions for machine comprehension of text,
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “Squad: 100,000+ questions for machine comprehension of text,” inProceedings of the 2016 Conference on Empirical Methods in Natural Language Process- ing. Association for Computational Linguistics, 2016
work page 2016
-
[72]
Recursive deep models for semantic compositionality over a sentiment treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Y . Ng, and C. Potts, “Recursive deep models for semantic compositionality over a sentiment treebank,” inProceedings of the 2013 conference on empirical methods in natural language processing, 2013, pp. 1631–1642
work page 2013
-
[73]
Semeval-2017 task 1: Semantic textual similarity multilingual and cross-lingual focused evaluation,
D. Cer, M. Diab, E. E. Agirre, I. Lopez-Gazpio, and L. Specia, “Semeval-2017 task 1: Semantic textual similarity multilingual and cross-lingual focused evaluation,” inThe 11th International Workshop on Semantic Evaluation (SemEval-2017), 2017, pp. 1–14
work page 2017
-
[74]
Exploring and predicting transferability across nlp tasks,
T. Vu, T. Wang, T. Munkhdalai, A. Sordoni, A. Trischler, A. Mattarella- Micke, S. Maji, and M. Iyyer, “Exploring and predicting transferability across nlp tasks,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 7882– 7926
work page 2020
-
[75]
Econas: Finding proxies for economical neural architecture search,
D. Zhou, X. Zhou, W. Zhang, C. C. Loy, S. Yi, X. Zhang, and W. Ouyang, “Econas: Finding proxies for economical neural architecture search,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 2020, pp. 11 393–11 401
work page 2020
-
[76]
Evolving neural architecture using one shot model,
N. Sinha and K. Chen, “Evolving neural architecture using one shot model,” inGECCO ’21: Genetic and Evolutionary Computation Con- ference, Lille, France, July 10-14, 2021, F. Chicano and K. Krawiec, Eds. ACM, 2021, pp. 910–918
work page 2021
-
[77]
Random search and reproducibility for neural architecture search,
L. Li and A. Talwalkar, “Random search and reproducibility for neural architecture search,” inProceedings of The 35th Uncertainty in Arti- ficial Intelligence Conference, ser. Proceedings of Machine Learning Research, vol. 115, 2020, pp. 367–377
work page 2020
-
[78]
EENA: efficient evolution of neural architecture,
H. Zhu, Z. An, C. Yang, K. Xu, E. Zhao, and Y . Xu, “EENA: efficient evolution of neural architecture,” in2019 IEEE/CVF International Conference on Computer Vision Workshops, ICCV Workshops 2019, Seoul, Korea (South), October 27-28, 2019. IEEE, 2019, pp. 1891– 1899
work page 2019
-
[79]
CARS: continuous evolution for efficient neural architecture search,
Z. Yang, Y . Wang, X. Chen, B. Shi, C. Xu, C. Xu, Q. Tian, and C. Xu, “CARS: continuous evolution for efficient neural architecture search,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 2020, pp. 1826–1835
work page 2020
-
[80]
X. Chen, L. Xie, J. Wu, and Q. Tian, “Progressive differentiable archi- tecture search: Bridging the depth gap between search and evaluation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.