Recognition: no theorem link
Emergent Symbolic Structure in Health Foundation Models: Extraction, Alignment, and Cross-Modal Transfer
Pith reviewed 2026-05-11 02:17 UTC · model grok-4.3
The pith
Health foundation model embeddings contain an interpretable symbolic organization shared across sensor modalities that supports cross-domain transfer without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
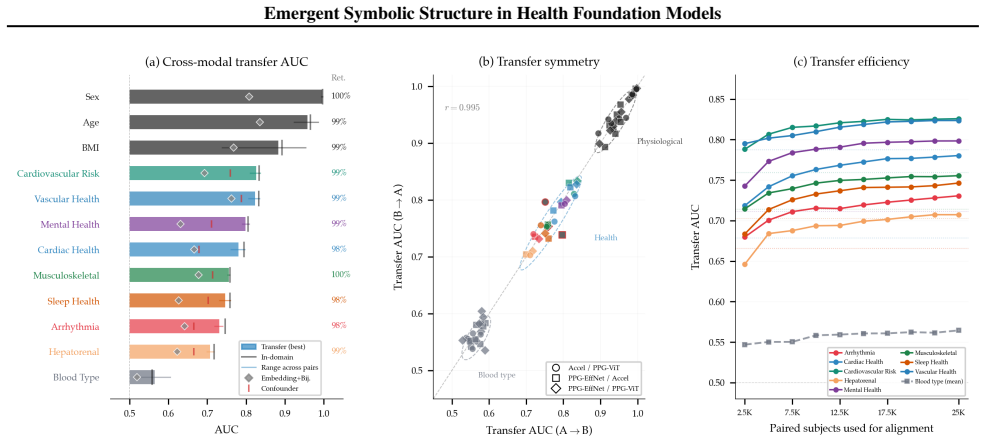
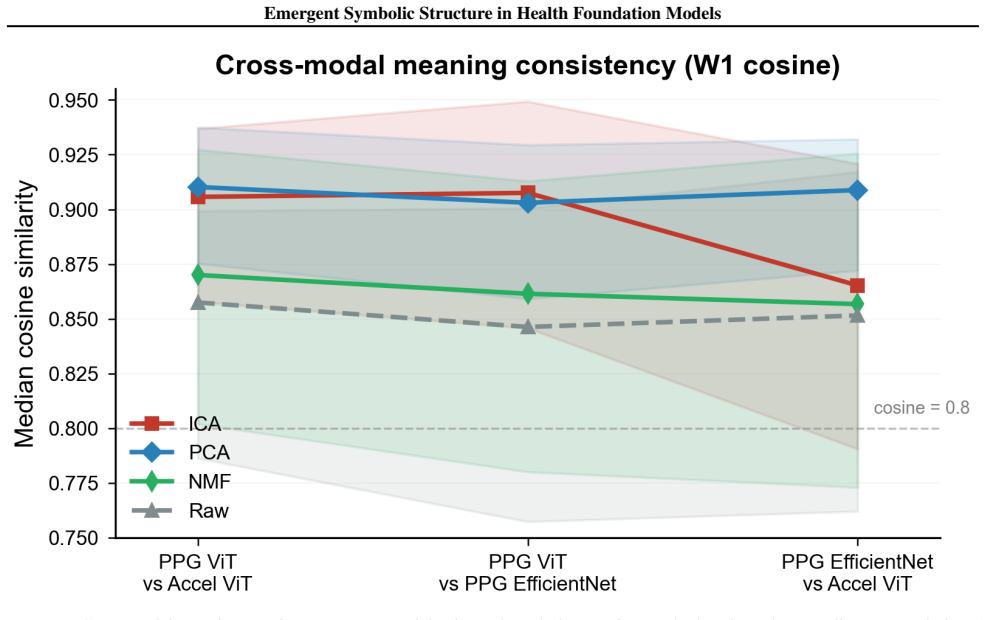
Health foundation models pretrained on large unlabeled wearable datasets produce embeddings that decompose into interpretable directions termed symbols. These symbols associate with specific health conditions and attributes. The associations are partially shared across modalities and architectures. Aligning spaces via the symbols produces cross-modal transfer that retains more than 95 percent of in-domain performance, remains nearly symmetric, and saturates with small amounts of paired data, recovering a shared physiological subspace.
What carries the argument
Post-training decomposition of frozen embeddings into interpretable directions (symbols) that are then used to align embedding spaces across modalities without any retraining.
If this is right
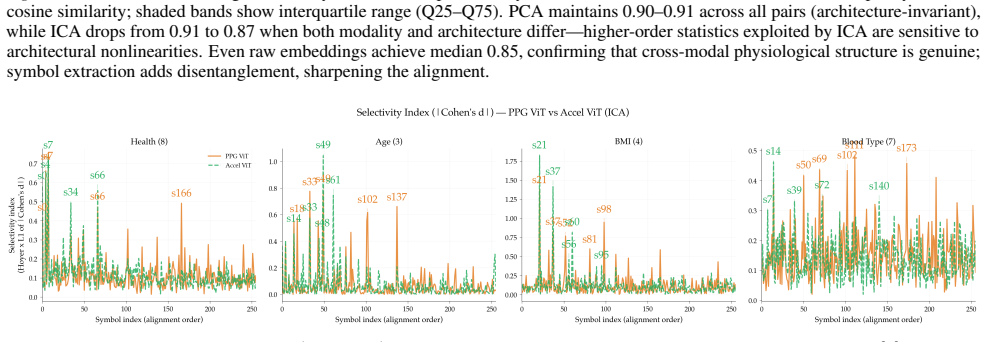
- Extracted symbols associate selectively with health conditions and physiological attributes.
- Symbol-attribute associations are partially shared across PPG and accelerometer modalities.
- Cross-modal transfer via symbols retains more than 95 percent of in-domain performance and is nearly symmetric.
- The alignment process saturates with limited paired data, indicating recovery of a low-dimensional shared subspace.
Where Pith is reading between the lines
- The approach could support modular reuse of health models across new sensor types without full retraining.
- If symbols prove stable, they might serve as building blocks for combining multiple foundation models in clinical pipelines.
- Testing symbol consistency on data from varied demographics would clarify whether the shared subspace generalizes beyond the study cohort.
- The framework might reveal whether similar symbolic structures emerge in non-wearable health models such as those trained on imaging or lab data.
Load-bearing premise
The extracted symbols capture genuine physiological information rather than spurious correlations or artifacts introduced by the decomposition process.
What would settle it
If the symbols show no selective correlation with independent physiological measurements such as heart rate variability or step counts on a new held-out cohort from a different population, the claim of a shared physiological subspace would be falsified.
Figures



read the original abstract
Health foundation models (FMs) learn useful representations from wearable sensors, but interpreting what they encode and transferring that knowledge across modalities after training remains difficult. We present a post-training framework that decomposes frozen embeddings into interpretable directions, referred to as symbols, and use these symbols to align the embedding spaces without retraining. We evaluate the framework on three FMs for photoplethysmography (PPG) and accelerometer data, independently pretrained on ~20M minutes of unlabeled data from ~172K participants, and analyzed on a held-out cohort of 30K subjects. We find that extracted symbols associate selectively with health conditions and physiological attributes, and these associations are partially shared across modalities and architectures. Cross-modal transfer via symbols retains more than 95% of in-domain performance, is nearly symmetric across domain directions, and saturates with limited paired data, together indicating that alignment recovers a shared low-dimensional subspace rich in physiological information. Overall, these results suggest that health FM embeddings contain an interpretable symbolic organization that is shared across modalities and supports cross-domain transfer without joint training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a post-training framework that decomposes frozen embeddings from health foundation models (pretrained on ~20M minutes of unlabeled PPG and accelerometer data from ~172K participants) into interpretable directions called symbols. These symbols are then used to align embedding spaces across modalities without retraining. On a held-out cohort of 30K subjects, the authors report that extracted symbols associate selectively with health conditions and physiological attributes, with partial sharing across modalities and architectures; cross-modal transfer via symbols retains >95% of in-domain performance, is nearly symmetric, and saturates with limited paired data, supporting the claim of an emergent shared low-dimensional symbolic organization rich in physiological information.
Significance. If the central claims hold after addressing validation concerns, the work would show that large-scale health FMs encode an interpretable, partially shared physiological subspace extractable post-hoc and alignable with minimal paired data. This could meaningfully advance interpretability and practical cross-sensor transfer in wearable health modeling without requiring joint retraining on massive datasets. The scale of pretraining and the quantitative saturation/transfer results are strengths that, if robust, would distinguish the contribution from purely post-hoc fitting exercises.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation protocol: All reported quantitative results—selective health-condition associations, partial cross-modal sharing, >95% transfer retention, symmetry, and saturation—are measured exclusively on the same 30K held-out cohort drawn from the original ~172K-participant pool. No external validation cohort, demographic shift, sensor variation, or distribution-shift test is described. This is load-bearing for the claim that symbols encode genuine physiological information rather than cohort-specific correlations or pretraining artifacts, as the symbol extraction, association analysis, and alignment all operate within the same data regime.
- [Abstract / Methods] Abstract and methods on symbol extraction: The procedure for decomposing embeddings into symbols, the statistical controls used to establish selective associations, and any error bars or significance testing are not quantified in the reported results. Without these details it is difficult to rule out that the observed associations and the recovered low-dimensional subspace are post-hoc fitting artifacts rather than robust physiological directions, directly affecting the interpretability and generalization claims.
minor comments (2)
- [Methods] The notation distinguishing 'symbols' from the original embedding dimensions and from the alignment transformation should be introduced with explicit equations early in the methods to improve readability.
- [Results] Figure captions and axis labels for the saturation and symmetry plots would benefit from explicit mention of the number of paired samples used at each point and the exact performance metric being plotted.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our evaluation protocol and methodological transparency. We address each major point below, clarifying the held-out nature of our analyses while acknowledging limitations, and commit to specific revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation protocol: All reported quantitative results—selective health-condition associations, partial cross-modal sharing, >95% transfer retention, symmetry, and saturation—are measured exclusively on the same 30K held-out cohort drawn from the original ~172K-participant pool. No external validation cohort, demographic shift, sensor variation, or distribution-shift test is described. This is load-bearing for the claim that symbols encode genuine physiological information rather than cohort-specific correlations or pretraining artifacts, as the symbol extraction, association analysis, and alignment all operate within the same data regime.
Authors: The 30K cohort is a strictly held-out partition from the original participant pool and was never used in foundation-model pretraining, allowing symbol extraction, association testing, and cross-modal alignment to be evaluated on data unseen during model training. This design directly tests whether interpretable symbolic structure emerges in embeddings of a large independent sample drawn from the same population. We agree that fully external cohorts with demographic or sensor shifts would provide stronger evidence against cohort-specific artifacts. In the revised manuscript we will add an explicit limitations paragraph discussing this point and outlining future validation plans, while retaining the current quantitative results as evidence within the studied regime. revision: partial
-
Referee: [Abstract / Methods] Abstract and methods on symbol extraction: The procedure for decomposing embeddings into symbols, the statistical controls used to establish selective associations, and any error bars or significance testing are not quantified in the reported results. Without these details it is difficult to rule out that the observed associations and the recovered low-dimensional subspace are post-hoc fitting artifacts rather than robust physiological directions, directly affecting the interpretability and generalization claims.
Authors: We will expand the Methods section with a complete, self-contained description of the decomposition procedure (including the exact optimization objective and hyper-parameters), the statistical controls (permutation testing and FDR correction for selective associations), and the reporting of error bars (bootstrap or analytic) together with p-values for all key quantitative claims. Revised figures and tables will include these quantities. These additions will allow readers to directly evaluate the robustness of the extracted symbols and the low-dimensional subspace. revision: yes
Circularity Check
No significant circularity in empirical framework
full rationale
The paper presents a post-training empirical procedure applied to frozen pretrained embeddings: symbol decomposition, limited-pair alignment, and evaluation of selective associations plus cross-modal transfer performance on held-out subjects. No derivation chain, first-principles result, or prediction is claimed that reduces by construction to fitted inputs, self-citations, or renamed quantities. All quantitative results (associations, saturation, symmetry, >95% retention) are measured on independent held-out data, providing external checks relative to the pretrained models. The framework therefore remains self-contained without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
arXiv preprint arXiv:2012.05876 , year=
Neurosymbolic Artificial Intelligence: The State of the Art , author=. arXiv preprint arXiv:2012.05876 , year=
-
[4]
Communications of the ACM , volume=
Computer Science as Empirical Inquiry: Symbols and Search , author=. Communications of the ACM , volume=. 1976 , publisher=
work page 1976
- [5]
-
[6]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[7]
Linear Representations: The Linear Representation Hypothesis , author=. 2024 , journal=
work page 2024
-
[8]
International Conference on Learning Representations (ICLR) , year=
Convergent Learning: Do Different Neural Networks Learn the Same Representations? , author=. International Conference on Learning Representations (ICLR) , year=
-
[9]
A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations , author=. arXiv preprint arXiv:2302.03025 , year=
-
[10]
The Platonic Representation Hypothesis
The Platonic Representation Hypothesis , author=. arXiv preprint arXiv:2405.07987 , year=
-
[11]
Progress Measures for Grokking via Mechanistic Interpretability , author=. 2023 , url=
work page 2023
- [12]
-
[13]
The Varimax Criterion for Analytic Rotation in Factor Analysis , author=. Psychometrika , volume=
-
[14]
Independent Component Analysis: Algorithms and Applications , author=. Neural Networks , volume=
-
[15]
Learning the Parts of Objects by Non-Negative Matrix Factorization , author=. Nature , volume=
- [16]
-
[17]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[18]
International Conference on Learning Representations (ICLR) , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[19]
Relations Between Two Sets of Variates , author=. Biometrika , volume=
-
[20]
A Penalized Matrix Decomposition, with Applications to Sparse Principal Components and Canonical Correlation Analysis , author=. Biostatistics , volume=. 2009 , doi=
work page 2009
-
[21]
International Conference on Learning Representations (ICLR) , year=
Understanding Latent Correlation-Based Multiview Learning and Self-Supervision: An Identifiability Perspective , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
Parallel Distributed Processing , year=
Distributed representations , author=. Parallel Distributed Processing , year=
-
[23]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Representation learning: A review and new perspectives , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
- [24]
-
[25]
Toy Models of Superposition , author=. Transformer Circuits , year=
-
[26]
and McDougall, Callum and MacDiarmid, Monte and Freeman, C
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and Cunningham, Hoagy and Turner, Nicholas L. and McDougall, Callum and MacDiarmid, Monte and Freeman, C. Daniel and Sumers, Theodore R. and Rees, Edward and Batson, Joshua and...
work page 2024
-
[27]
Scaling and evaluating sparse autoencoders
Scaling and Evaluating Sparse Autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=
work page internal anchor Pith review arXiv
-
[28]
arXiv preprint arXiv:2404.16014 , year=
Improving Dictionary Learning with Gated Sparse Autoencoders , author=. arXiv preprint arXiv:2404.16014 , year=
-
[29]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. arXiv preprint arXiv:2403.19647 , year=
work page internal anchor Pith review arXiv
-
[30]
International Conference on Learning Representations (ICLR) , year=
Not All Language Model Features Are Linear , author=. International Conference on Learning Representations (ICLR) , year=
-
[31]
Gurnee, Wes and Horsley, Theo and Guo, Zifan C. and Kheirkhah, Tara R. and Sun, Qinyi and Hathaway, Will and Nanda, Neel and Bertsimas, Dimitris , journal=. Universal Neurons in. 2024 , url=
work page 2024
-
[32]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. arXiv preprint arXiv:2311.03658 , year=
work page internal anchor Pith review arXiv
-
[33]
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page 2023
-
[34]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Revisiting Model Stitching to Compare Neural Representations , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[35]
International Conference on Machine Learning (ICML) , year=
Similarity of Neural Network Representations Revisited , author=. International Conference on Machine Learning (ICML) , year=
-
[36]
International Conference on Machine Learning (ICML) , year=
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning (ICML) , year=
-
[37]
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (
Kim, Been and Wattenberg, Martin and Gilmer, Justin and Cai, Carrie and Wexler, James and Viegas, Fernanda and Sayres, Rory , booktitle=. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (. 2018 , url=
work page 2018
-
[38]
International Conference on Machine Learning (ICML) , year=
Concept Bottleneck Models , author=. International Conference on Machine Learning (ICML) , year=
-
[39]
International Conference on Learning Representations (ICLR) , year=
Label-Free Concept Bottleneck Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[40]
and Spathis, Dimitris and Kawsar, Fahim and Malekzadeh, Mohammad , booktitle=
Pillai, Arvind S. and Spathis, Dimitris and Kawsar, Fahim and Malekzadeh, Mohammad , booktitle=. 2025 , url=
work page 2025
-
[41]
arXiv preprint arXiv:2507.01045 , year=
Sensing Cardiac Health Across Scenarios and Devices: A Multi-Modal Foundation Model Pretrained on 1.7 Million Individuals , author=. arXiv preprint arXiv:2507.01045 , year=
-
[42]
NeurIPS ML for Mobile Health Workshop , year=
Self-supervised Transfer Learning of Physiological Representations from Free-living Wearable Data , author=. NeurIPS ML for Mobile Health Workshop , year=
-
[43]
He, Meian and Wolpin, Brian and Rexrode, Kathryn and Manson, JoAnn E and Rimm, Eric and Hu, Frank B and Qi, Lu , journal=. 2012 , publisher=
work page 2012
-
[44]
Jenkins, Peter V and O'Donnell, James S , journal=. 2006 , publisher=
work page 2006
-
[45]
Dentali, Francesco and Sironi, Andrea P and Ageno, Walter and Turato, Sergio and Bonfanti, Corrado and Frattini, Francesca and Crestani, Sergio and Franchini, Massimo , journal=. Non-. 2012 , publisher=
work page 2012
-
[46]
Beyond immunohaematology: the role of the
Liumbruno, Giancarlo Maria and Franchini, Massimo , journal=. Beyond immunohaematology: the role of the. 2013 , publisher=
work page 2013
-
[47]
Journal of Machine Learning Research , volume=
Non-negative matrix factorization with sparseness constraints , author=. Journal of Machine Learning Research , volume=
-
[48]
Large-Scale Training of Foundation Models for Wearable Biosignals , author=. arXiv preprint arXiv:2312.05409 , year=
-
[49]
Wearable Accelerometer Foundation Models for Health via Knowledge Distillation , author=. arXiv preprint arXiv:2412.11276 , year=
-
[50]
International Conference on Learning Representations (ICLR) , year=
Relative Representations Enable Zero-Shot Latent Space Communication , author=. International Conference on Learning Representations (ICLR) , year=
-
[51]
arXiv preprint arXiv:2310.13018 , year=
Getting Aligned on Representational Alignment , author=. arXiv preprint arXiv:2310.13018 , year=
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[53]
International Conference on Machine Learning (ICML) , year=
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations , author=. International Conference on Machine Learning (ICML) , year=
-
[54]
and Monti, Ricardo Pio and Hyv
Khemakhem, Ilyes and Kingma, Diederik P. and Monti, Ricardo Pio and Hyv. Variational Autoencoders and Nonlinear. International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[55]
Scaling Wearable Foundation Models , author=. arXiv preprint arXiv:2410.13638 , year=
-
[56]
Discovering Universal Geometry in Embeddings with
Yamagiwa, Hiroaki and Oyama, Momose and Shimodaira, Hidetoshi , booktitle=. Discovering Universal Geometry in Embeddings with. 2023 , url=
work page 2023
-
[57]
Tigges, Curt and Hanna, Michael and Yu, Qinan and Biderman, Stella , journal=. 2024 , url=
work page 2024
-
[58]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review arXiv
-
[59]
Naval Research Logistics Quarterly , volume=
The Hungarian Method for the Assignment Problem , author=. Naval Research Logistics Quarterly , volume=
-
[60]
A Global Geometric Framework for Nonlinear Dimensionality Reduction , author=. Science , volume=. 2000 , publisher=
work page 2000
-
[61]
International Conference on Learning Representations (ICLR) , year=
Word Translation Without Parallel Data , author=. International Conference on Learning Representations (ICLR) , year=
-
[62]
arXiv preprint arXiv:2012.13255 , year=
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , author=. arXiv preprint arXiv:2012.13255 , year=
- [63]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.